Xu, Weipeng, et al. "Mo 2 cap 2: Real-time mobile 3d motion capture with a cap-mounted fisheye camera." IEEE transactions on visualization and computer graphics 25.5 (2019): 2093-2101.

1.INTRO
In the past,many works for outside-in 3D human pose estimation have been pro-posed, which use a single or multiple cameras placed statically around the user [13, 32, 33, 37, 40, 50]. However, daily real world situations make outside-in capture setups impractical, since they are immobile, can not be placed everywhere, require a recording space without occluders in front of the subject, and have only a small recording volume.
3d human pose를 측정하려는 시도는 많이 있었음.
하지만 이는 여러대의 카메라를 사용자 주변에 고정적으로 배치하여 영상을 얻어오는 작업이 필요했음.
(셋업이 비쌈, 사전준비가 많이 필요함)
이에 사용자가 자기 자신을 촬영 할 수 있는 환경(egocap)에서 사용자의 3d joint를 실시간(60Hz)으로 추정하는 프레임워크를 제안하고자 함.
2.RELATED WORK
Studio and Multi-view Motion Capture

기존의 모션캡쳐 방식(수트를 입고 실내에서 촬영, high cost)
Monocular Human Pose Estimation
Body-worn Motion Sensors
Mobile Motion Capture
3.APPROACH
일반적인 모자에 어안렌즈 카메라를 장착함
단일 뷰, 광각 왜곡, 근접 시점들은 자세 추정을 어렵게 함
3.1 Lightweight Hardware Setup
Since they mount each of the cameras approximately 25 cm away from the forehead, the weight of the two cameras translates into a large moment, making their helmet quite uncomfortable to wear. Furthermore, their large stereo baseline of 30-40 cm in combination with the large forehead-to-camera distance forces the actor to stay far away from walls and other objects, which limits usability of the approach in many everyday situations.

기존 연구는 두개의 카메라를 pair로 30-40cm의 거리에 장착하고 사용하여 자세를 추정했지만 이는 카메라의 중량과 크기 때문에 사용자의 불편함이 유발되었음

본 논문에서는 25cm거리에 단안 카메라를 장착하여 이를 해결함
3.2 Synthetic Training Corpus

다양한 전문적인 모션 캡쳐 시스템들이 존재함에도 불구하고 특정 시점(ego)의 실제 데이터셋을 얻는것은 힘듬(high cost) 이러한 문제점들을 해결하기 위해 가상 데이터를 사용하여 모델을 훈련시켰음.
3.3 Monocular Fisheye 3D Pose Estimation
다음의 3가지 모듈을 사용하였음
2D module
image에서 2d heatmap을 추정하는 모듈인데 광각 특유의 왜곡을 해결하기 위해 2분기로 나눠서 훈련함
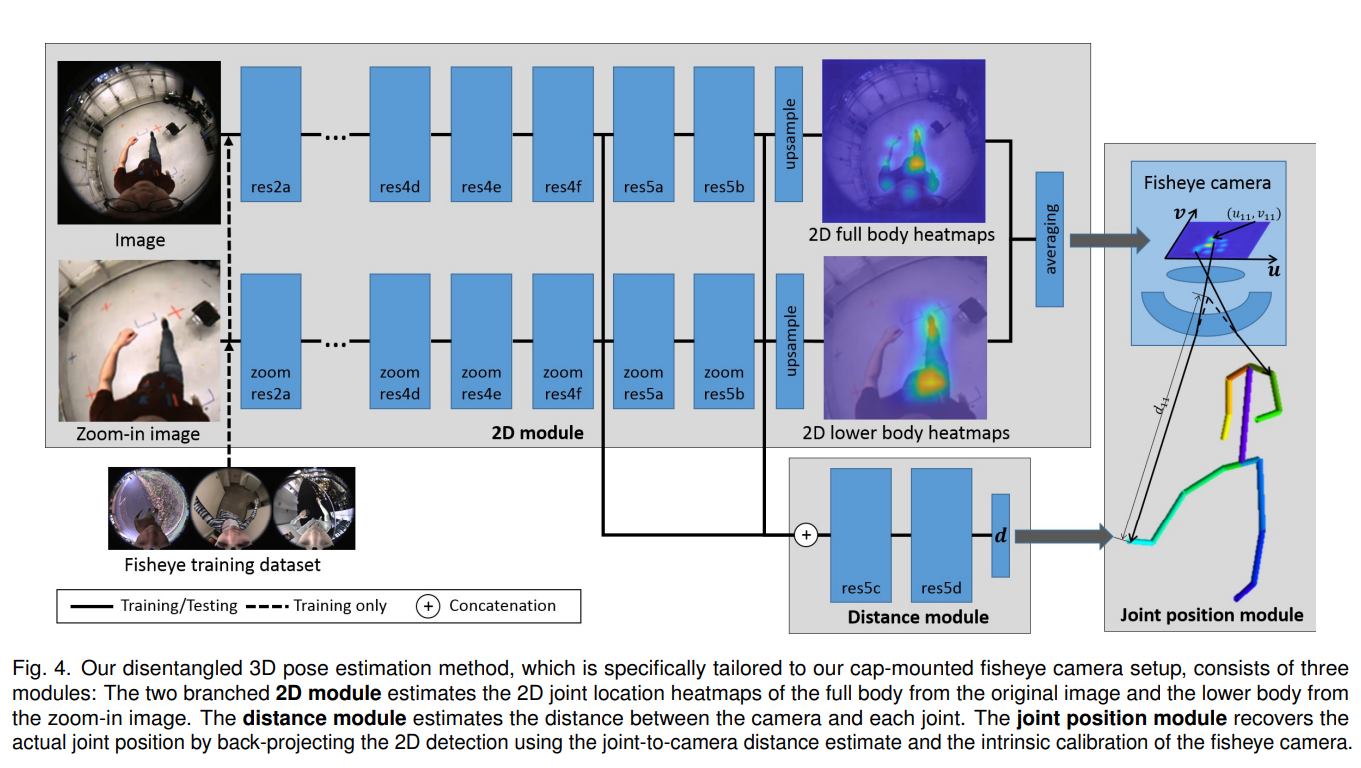
하나의 분기는 전체 joint(15)를 추정하고 다른 분기는 하체가 작아보이는 왜곡을 해결하기 위해 하체를 줌인한 사진에서 하체의 joint(8)를 추정함
그리고 이를 평균내어 전체적인 heatmap을 구성함
distance module
조인트별로 백터화된 depth를(카메라로부터 조인트까지의 거리) 회귀함.
2d 모듈에서 fully Conv 아키텍쳐를 사용한것과 대조적으로 FC레이어를 사용해서 이를 구현했음.
joint position module
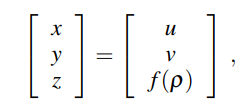
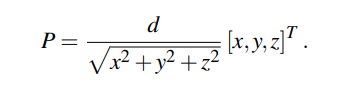
광각 카메라의 내부 파라미터를 사용하여 2d 조인트의 u,v를 인풋으로 하여 3차원 joint 좌표 P 를 매핑하는 모듈
Implementation of our network
2d 모듈은 각각 15개의 레스듀얼 블록으로 이루어져 있음.그리고 마지막에 업셈플링하여 32x32짜리 heatmap을 아웃풋으로 리턴(인풋은 256x256 이미지)
heatmap loss 는 L2norm 사용.
가중치 소실 문제와 모델 최적화를 위해 11번째와 14번째 레스듀얼 블록에서 지도학습 진행.

거리 모듈은 2개의 추가적인 레스듀얼 모듈과 2개의 컨볼루션 1개의 FC 레이어로 이루어져 있음.

13번째와 15번째의 레스듀얼 블록의 아웃풋을 컨캣하여 거리 모듈의 인풋으로 집어넣음.
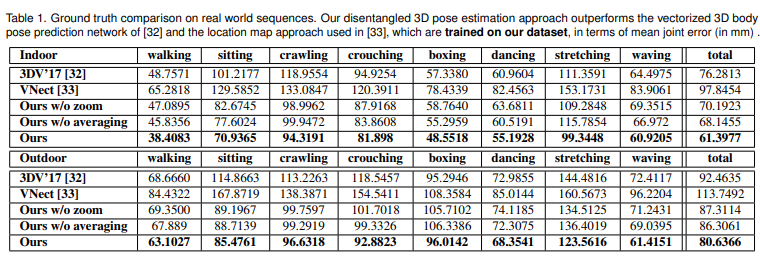
4.RESULTS
4.1 Qualitative Results

4.2 Quantitative Results