
📑 Summary
COVID-19의 확산으로 우리나라는 물론 전 세계 사람들은 경제적, 생산적인 활동에 많은 제약을 가지게 되었습니다. 우리나라는 COVID-19 확산 방지를 위해 사회적 거리 두기를 단계적으로 시행하는 등의 많은 노력을 하고 있습니다. 과거 높은 사망률을 가진 사스(SARS)나 에볼라(Ebola)와는 달리 COVID-19의 치사율은 오히려 비교적 낮은 편에 속합니다. 그럼에도 불구하고, 이렇게 오랜 기간 동안 우리를 괴롭히고 있는 근본적인 이유는 바로 COVID-19의 강력한 전염력 때문입니다.
감염자의 입, 호흡기로부터 나오는 비말, 침 등으로 인해 다른 사람에게 쉽게 전파가 될 수 있기 때문에 감염 확산 방지를 위해 무엇보다 중요한 것은 모든 사람이 마스크로 코와 입을 가려서 혹시 모를 감염자로부터의 전파 경로를 원천 차단하는 것입니다. 이를 위해 공공 장소에 있는 사람들은 반드시 마스크를 착용해야 할 필요가 있으며, 무엇 보다도 코와 입을 완전히 가릴 수 있도록 올바르게 착용하는 것이 중요합니다. 하지만 넓은 공공장소에서 모든 사람들의 올바른 마스크 착용 상태를 검사하기 위해서는 추가적인 인적자원이 필요할 것입니다.
따라서, 우리는 카메라로 비춰진 사람 얼굴 이미지 만으로 이 사람이 마스크를 쓰고 있는지, 쓰지 않았는지, 정확히 쓴 것이 맞는지 자동으로 가려낼 수 있는 시스템이 필요합니다. 이 시스템이 공공장소 입구에 갖춰져 있다면 적은 인적자원으로도 충분히 검사가 가능할 것입니다.
💾 Dataset
마스크를 착용하는 건 COIVD-19의 확산을 방지하는데 중요한 역할을 합니다. 제공되는 이 데이터셋은 사람이 마스크를 착용하였는지 판별하는 모델을 학습할 수 있게 해줍니다. 모든 데이터셋은 아시아인 남녀로 구성되어 있고 나이는 20대부터 70대까지 다양하게 분포하고 있습니다. 간략한 통계는 다음과 같습니다.
- 전체 사람 명 수 : 4,500
- 한 사람당 사진의 개수: 7 [마스크 착용 5장, 이상하게 착용(코스크, 턱스크) 1장, 미착용 1장]
- 이미지 크기: (384, 512)
전체 데이터셋 중에서 60%는 학습 데이터셋으로 활용됩니다.입력값. 마스크 착용 사진, 미착용 사진, 혹은 이상하게 착용한 사진(코스크, 턱스크)
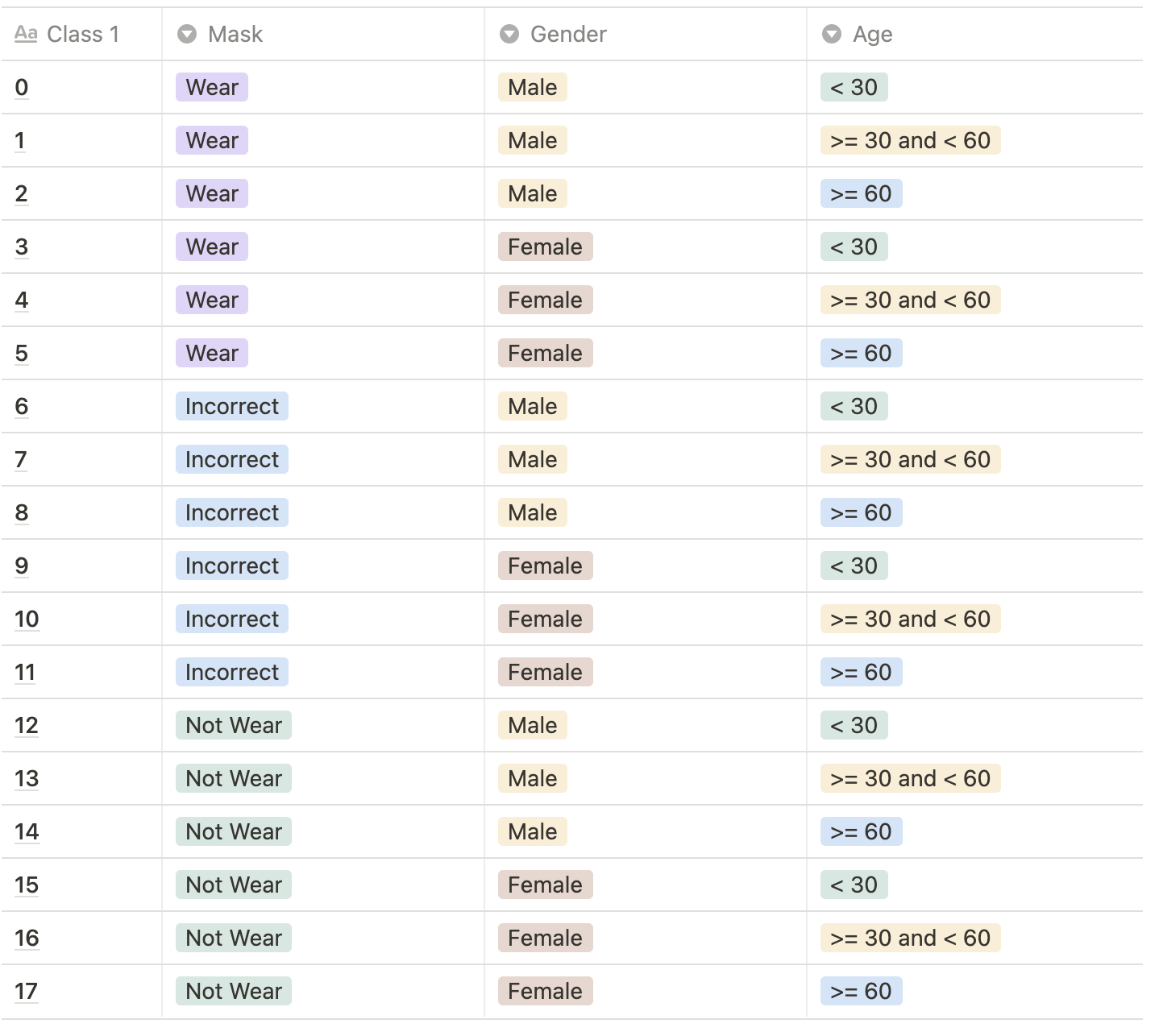
결과값. 총 18개의 class를 예측해야합니다. 결과값으로 0~17에 해당되는 숫자가 각 이미지 당 하나씩 나와야합니다.Class Description:
마스크 착용여부, 성별, 나이를 기준으로 총 18개의 클래스가 있습니다.
1️⃣ EDA
Data EDA
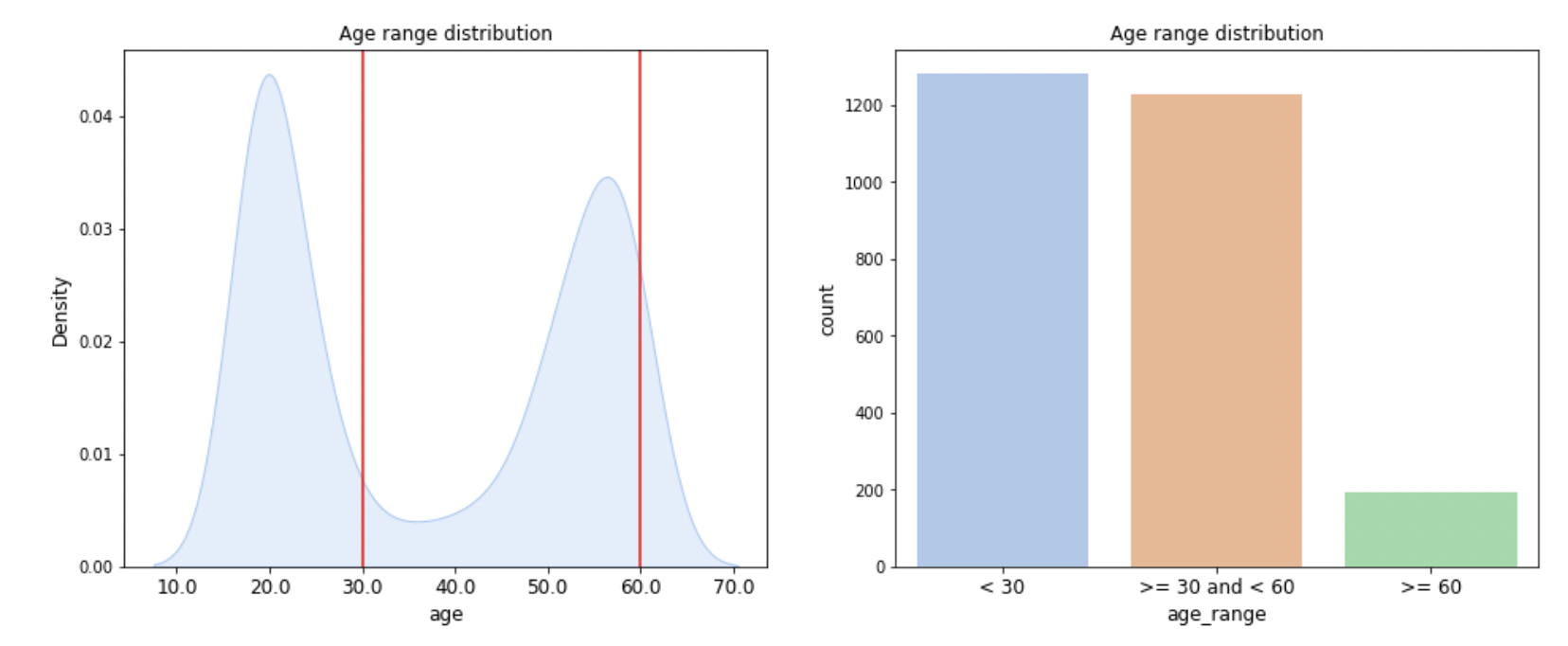
데이터셋의 분포가 불균형하다는것을 파악할 수 있다. 이러한 데이터 불균형을 해결하는것이 대회의 키포인트일 것이다.
🔧 Result improvement
1️⃣ Default value
Seed : 11
epochs : 10
val_ratio : 0.2
Dataset : MaskSplitByProfileDataset
2️⃣ Model & Data Augmentation
Resnet 18, resize [128,96]

pytorch에는 많은 수의 pretrained 된 모델이 존재하는데
이런식으로 pretrained 된 모델을 사용할 수 있다.
하지만 모델을 사용할때마다 이런식으로 객체로 선언하는것은 코드의 재사용성을 떨어뜨리는것은 물론 모델의 커스텀 역시 불편하게 되므로 가급적
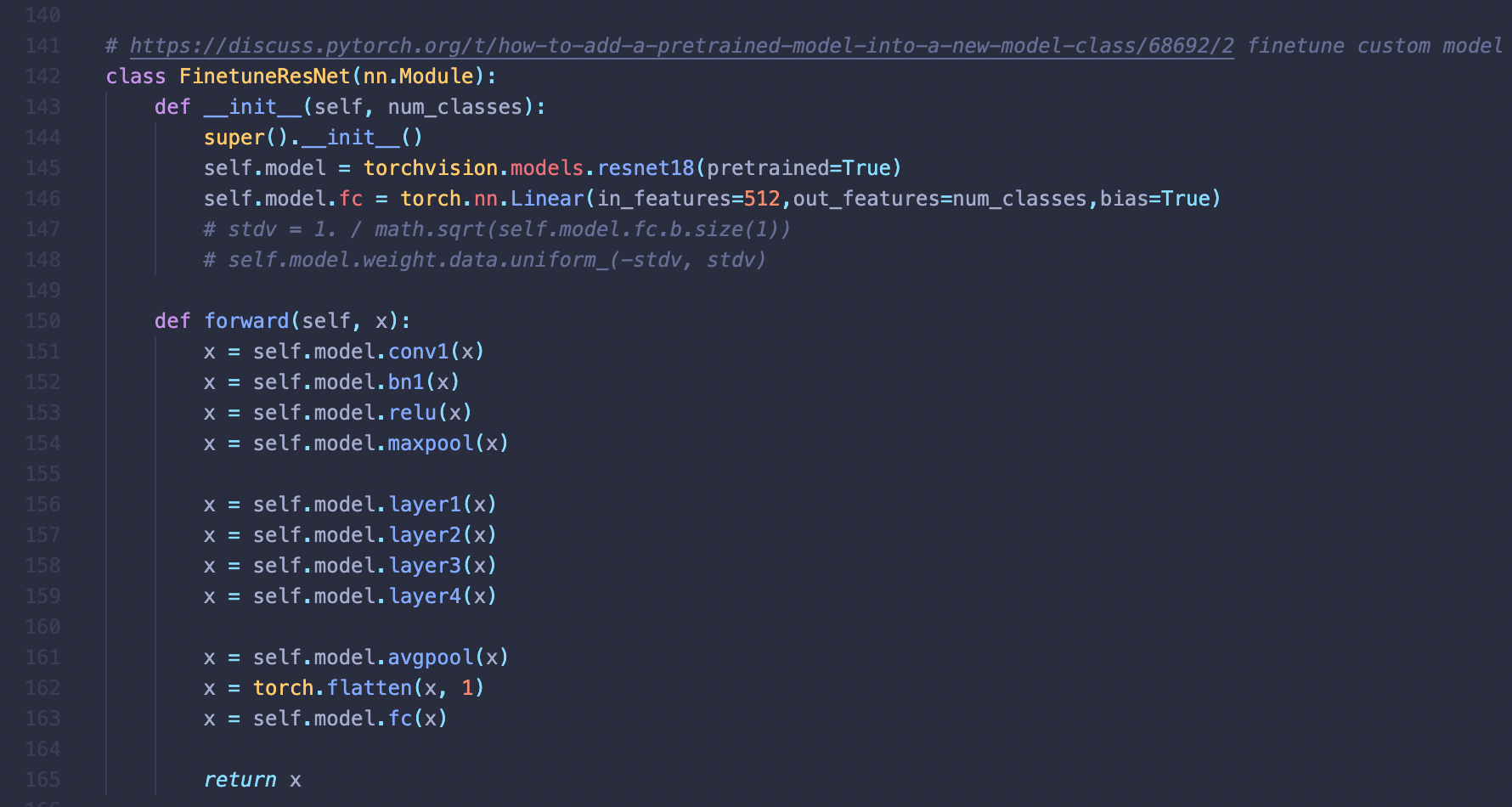
nn.Module을 상속한 클레스 안쪽에 모델을 선언하여 사용하는것이다. 이런식으로 pretrained 모델을 클래스로 선언할 경우

getattr를 활용해 사용할 수 있어서 코드의 재사용성 뿐 아니라 코드의 가독성 또한 높아지므로 꼭 모델을 class로 선언하여 사용하는 버릇을 들이는게 좋다.
config & result
{
"seed": 11,
"epochs": 10,
"dataset": "MaskBaseDataset",
"augmentation": "BaseAugmentation",
"resize": [
128,
96
],
"batch_size": 64,
"valid_batch_size": 1000,
"model": "ResNet18",
"optimizer": "SGD",
"lr": 0.001,
"val_ratio": 0.2,
"criterion": "cross_entropy",
"lr_decay_step": 20,
"log_interval": 20,
"name": "exp",
"data_dir": "/opt/ml/input/data/train/images",
"model_dir": "./model"
}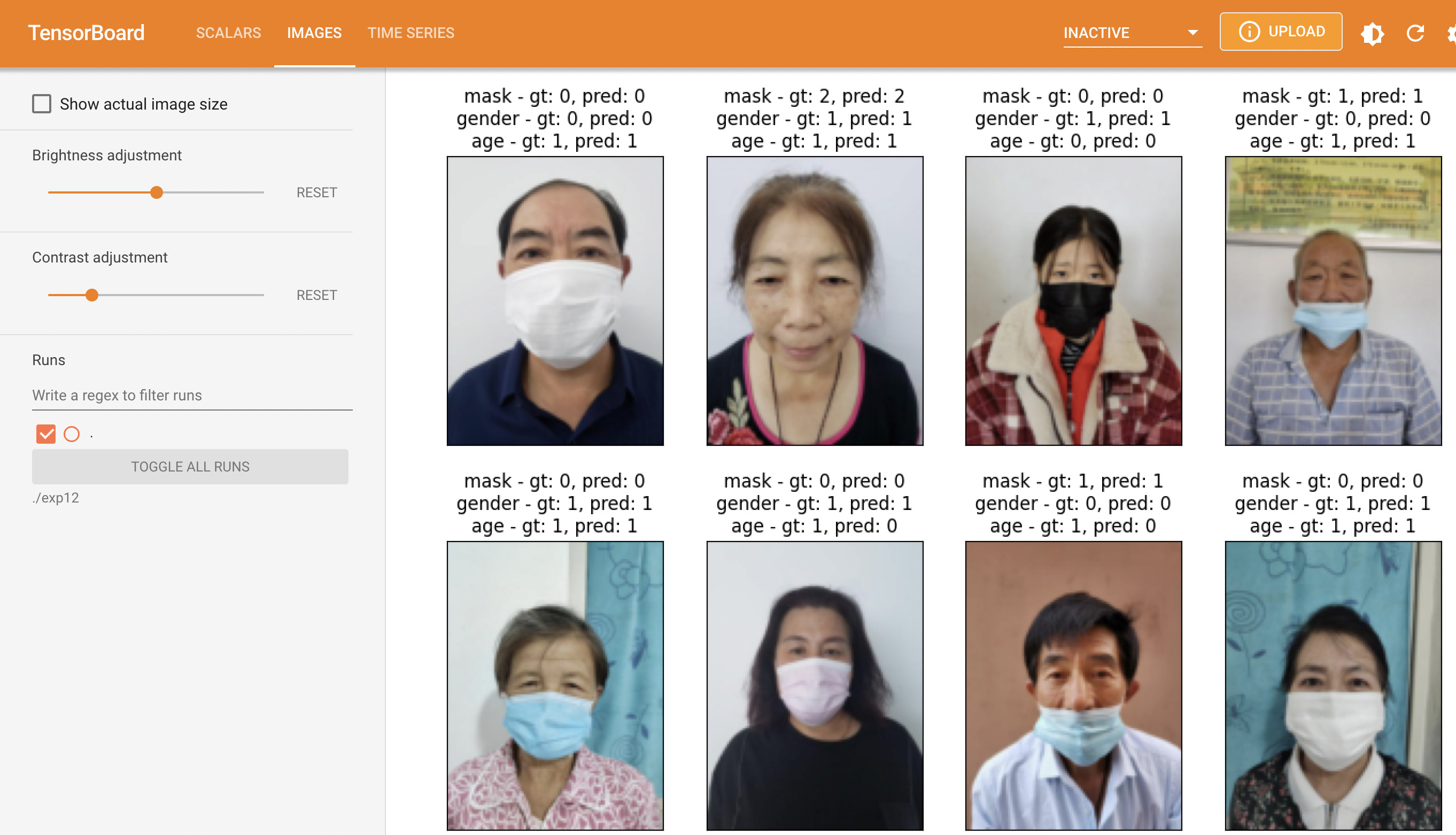
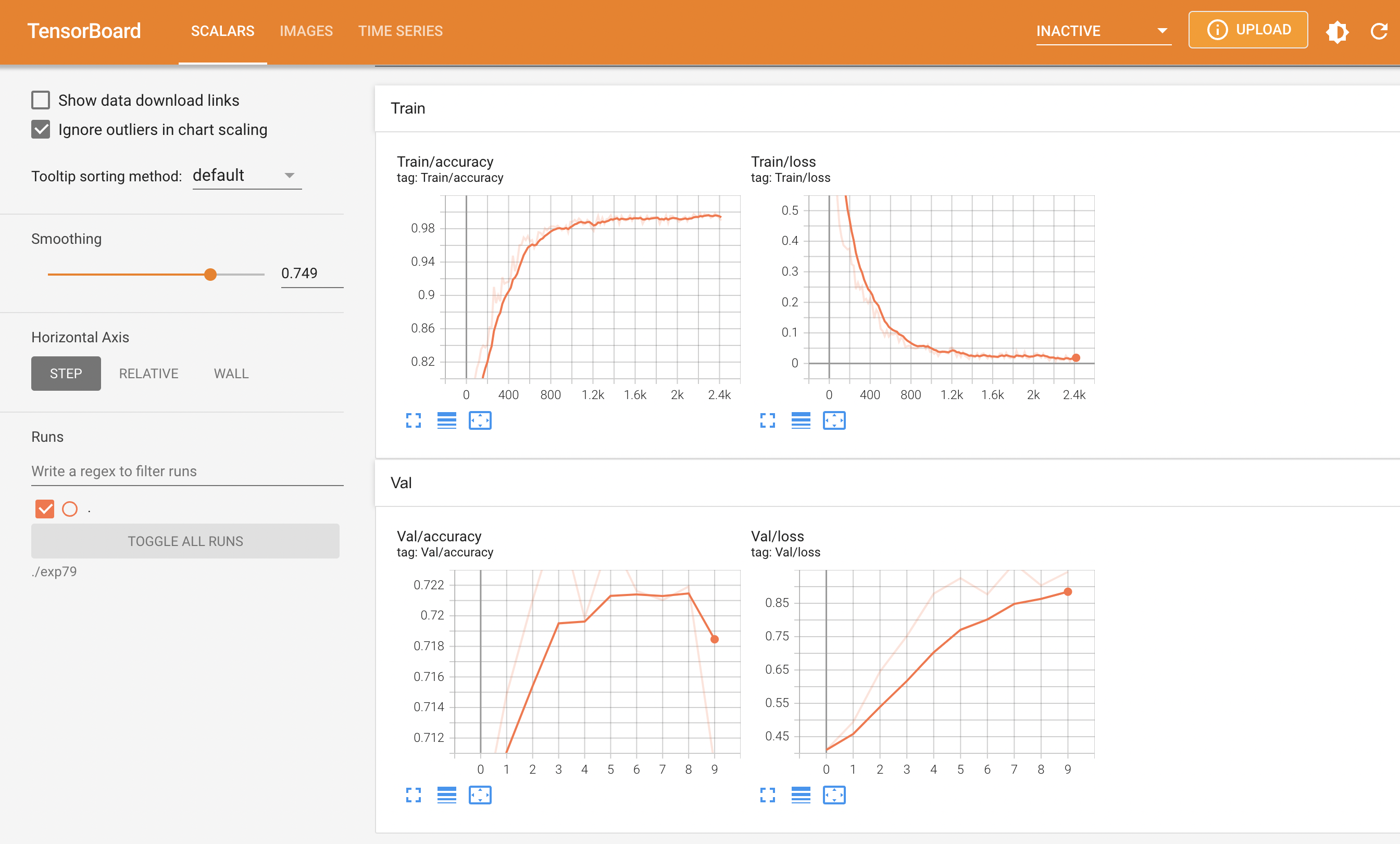
사실 대회중에 tensorboard를 사용하는 방법을 재대로 파악하지 못하고 이렇게 대회가 끝난 다음 정리하는 시간에야 사용하는 중인데 조금 더 일찍 텐서보드를 사용했더라면 다른 결과가 나오지 않았을까 하는 아쉬움이 남는다.
결과를 살펴보면 [128, 96] 으로 리사이즈가 들어가면서 얼굴의 주름같은 특징들이 많이 사라지면서 나이 판별을 재대로 하지 못하는 모습을 보여주고 있다.
Resnet 34, resize [400, 110], Adam
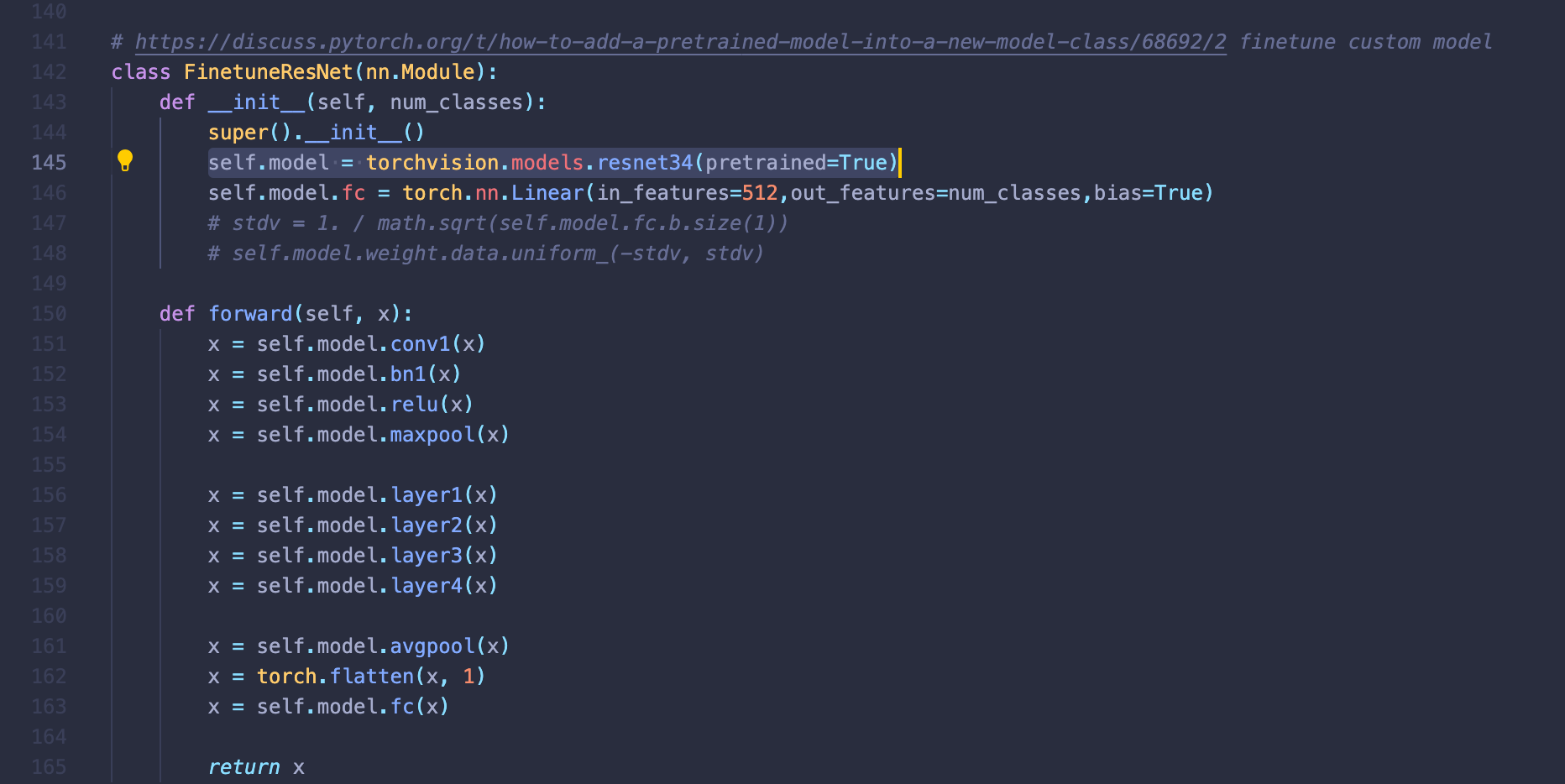
기존에 선언해둔 ResNet 클래스에서 145line만 변경하면 34모델을 사용할 수 있다.
config & result
{
"seed": 11,
"epochs": 40,
"dataset": "MaskSplitByProfileDataset",
"augmentation": "CustomAugmentation",
"resize": [
400,
110
],
"batch_size": 64,
"valid_batch_size": 1000,
"model": "ResNet",
"optimizer": "Adam",
"lr": 0.001,
"val_ratio": 0.2,
"criterion": "cross_entropy",
"lr_decay_step": 20,
"log_interval": 20,
"name": "exp",
"data_dir": "/opt/ml/input/data/train/images",
"model_dir": "./model"
}
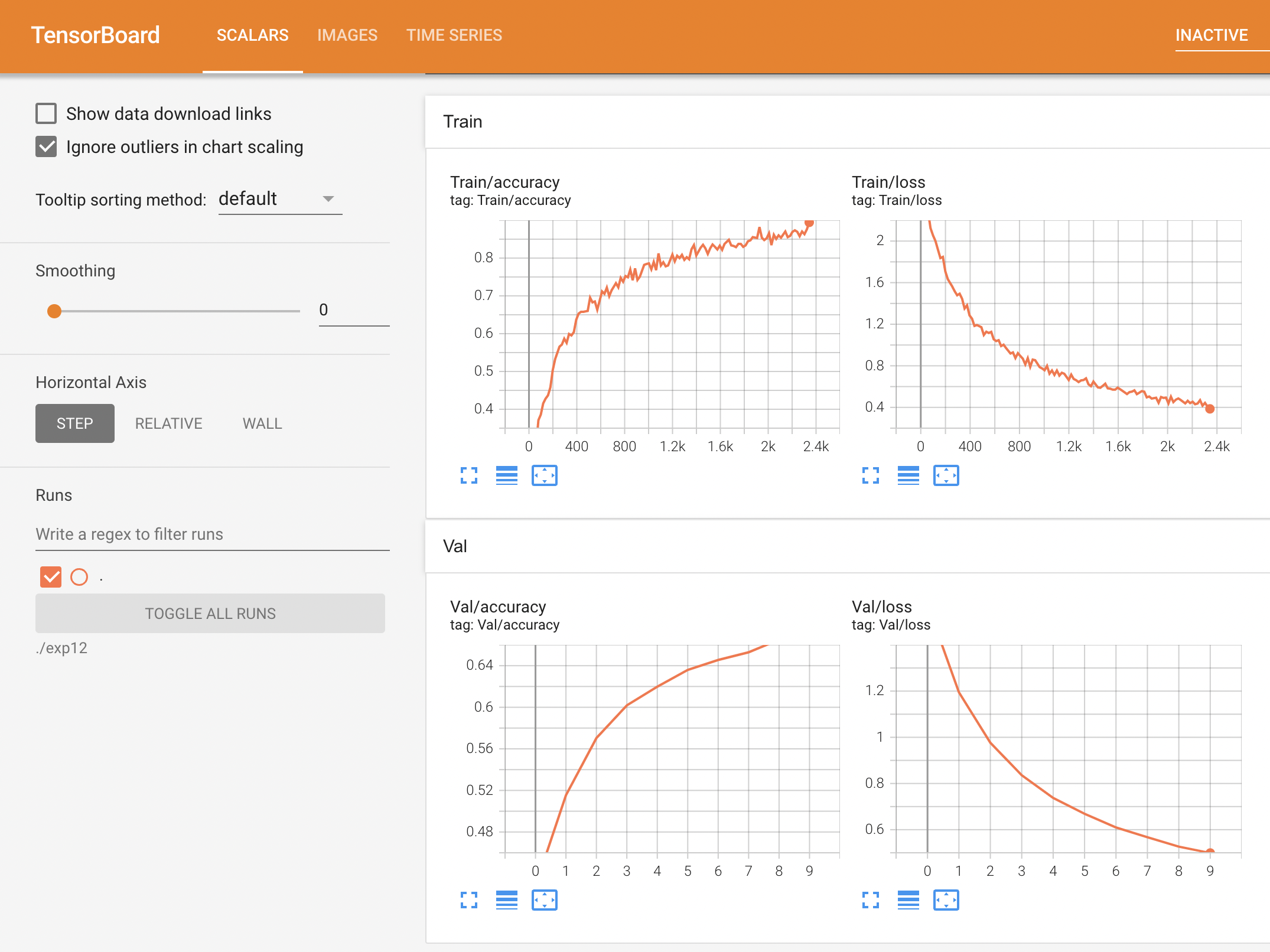
사진의 비율을 늘리면 마스크의 오착용 여부를 더 쉽게 알 수 있을까 라는 생각으로 접근하여 비율을 늘려보았지만 나이 부분을 정확하게 측정하지 못하였다. 그 이유로는 아마 사진이 가로로 축소되면서 주름같은 나이를 판별할 수 있는 특징들이 많이 사라져버린게 원인이라 생각한다.
Resnet 34, resize[400, 110], Adam, lr=1e-4
config & result
{
"seed": 11,
"epochs": 10,
"dataset": "CustomDataset",
"augmentation": "CustomAugmentation",
"resize": [
400,
110
],
"batch_size": 64,
"valid_batch_size": 500,
"model": "FinetuneResnet",
"optimizer": "Adam",
"lr": 0.0001,
"val_ratio": 0.2,
"criterion": "cross_entropy",
"lr_decay_step": 20,
"log_interval": 20,
"name": "exp",
"data_dir": "/opt/ml/input/data/train/images",
"model_dir": "./model"
}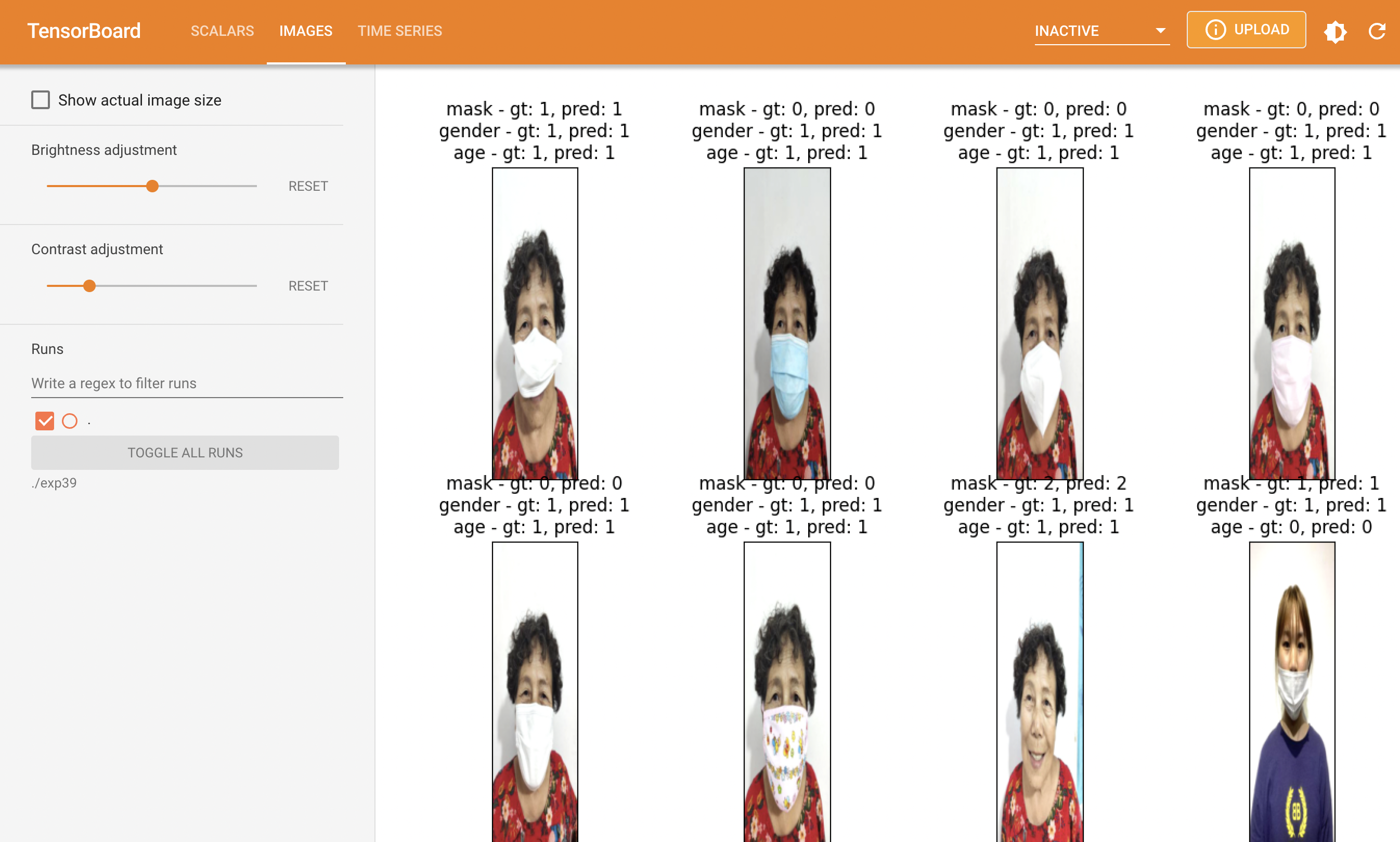
러닝레이트를 1e-4 로 낮추니 성능이 많이 좋아졌다. pretrained 모델은 건들지 않는게 더 좋은 성능을 보여주는것 처럼 보인다.
이후의 모델 학습들은 전부 1e-4로 진행하였다.
사실 이런 판단이 좋지 않았던것은 딥러닝에 무조건적인 정답이라는것이 없다는점이다. 오히려 러닝레이트가 높아서 더 좋은 결과가 나올수도 있기 때문에 이런 미스를 반복해서는 안된다.
EfficientNet, Contrast, resize[224, 224], Data split
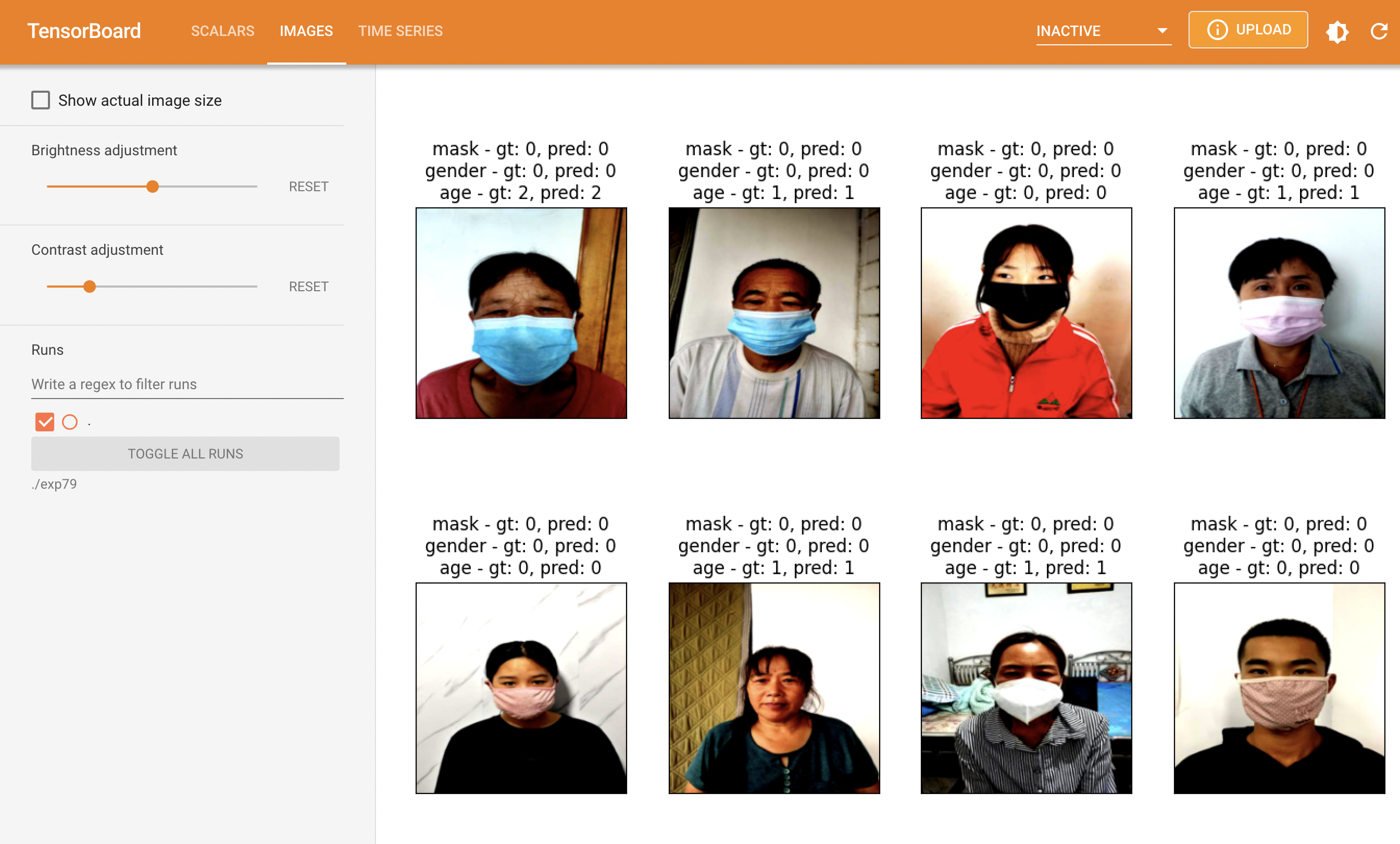
판단하여야 할 클래스가 총 3개(마스크,성별,나이) 이므로 모델을 각각 나눠서 모델을 훈련해보자는 의견이 나왔다. 훈련한 결과를 살펴보니 역시 나이를 훈련시킨 모델의 val결과가 가장 좋지 않은것을 파악하였다. 결론적으로 나이 모델을 어떻게 훈련시키는지에 따라서 결과가 달라질것이라는것을 파악하였다.
Face Crop
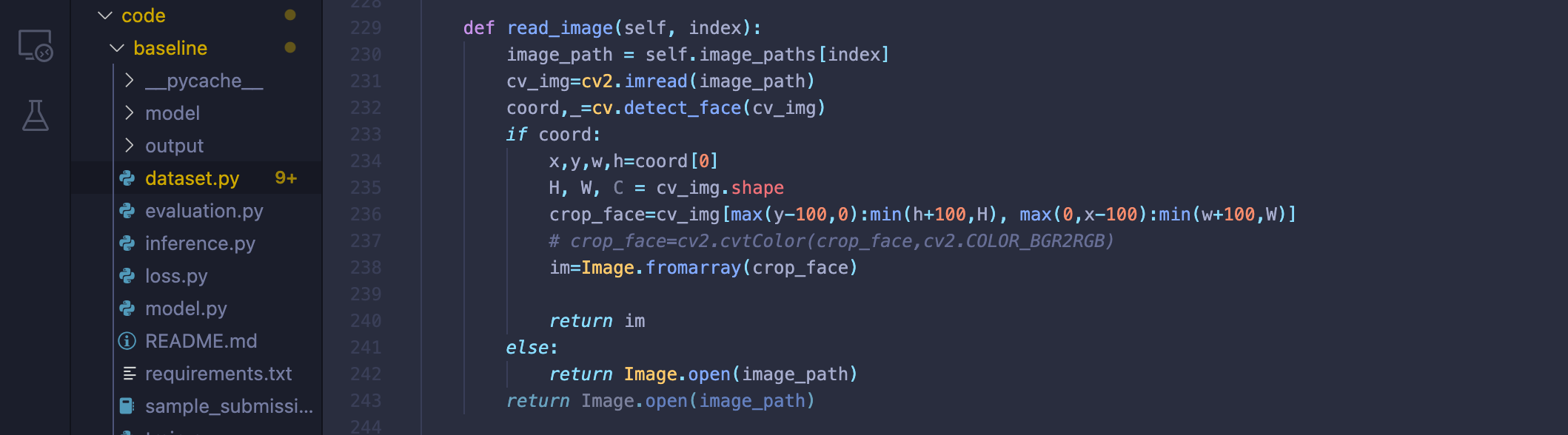
대회가 막바지에 이를때쯤 얼굴 이외의 배경사진을 지워보자는 의견이 나왔으나 시간이 부족하여 해당 전처리를 적용시킨 모델을 제출하지 못하였다.
데이터셋을 읽어들일때 얼굴만 찾아내는 모델을 먼저 적용하여 사진의 얼굴만 찾아내는 방식을 사용하였다.
대회가 끝난 이후 최상위권 팀들의 방법들을 살펴보니 얼굴을 크롭하여 다시 저장하는 방식을 사용해 데이터의 양을 늘리고, 데이터의 편차를 극복하기 위해
59살 이상을 60세 라벨링에 포함하거나, 59살의 데이터를 없에버리는 등의 방법을 사용하였다.
config & result
{
"seed": 11,
"epochs": 10,
"dataset": "CustomDataset",
"augmentation": "CustomAugmentation",
"resize": [
224,
224
],
"batch_size": 64,
"valid_batch_size": 500,
"model": "FinetuneResNet",
"optimizer": "Adam",
"lr": 0.001,
"val_ratio": 0.2,
"criterion": "cross_entropy",
"lr_decay_step": 20,
"log_interval": 20,
"name": "exp",
"data_dir": "/opt/ml/input/data/train/images",
"model_dir": "./model"
}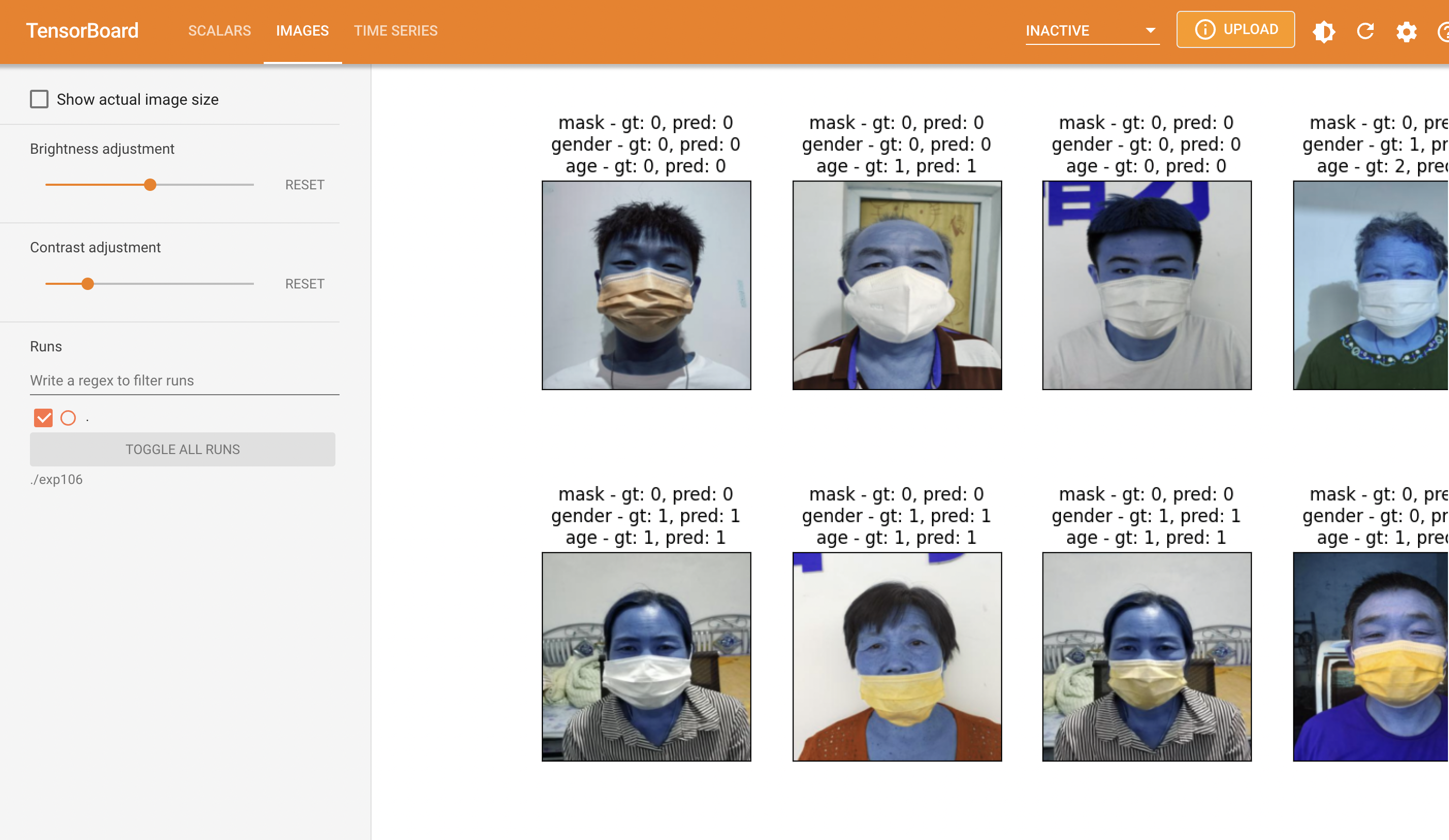
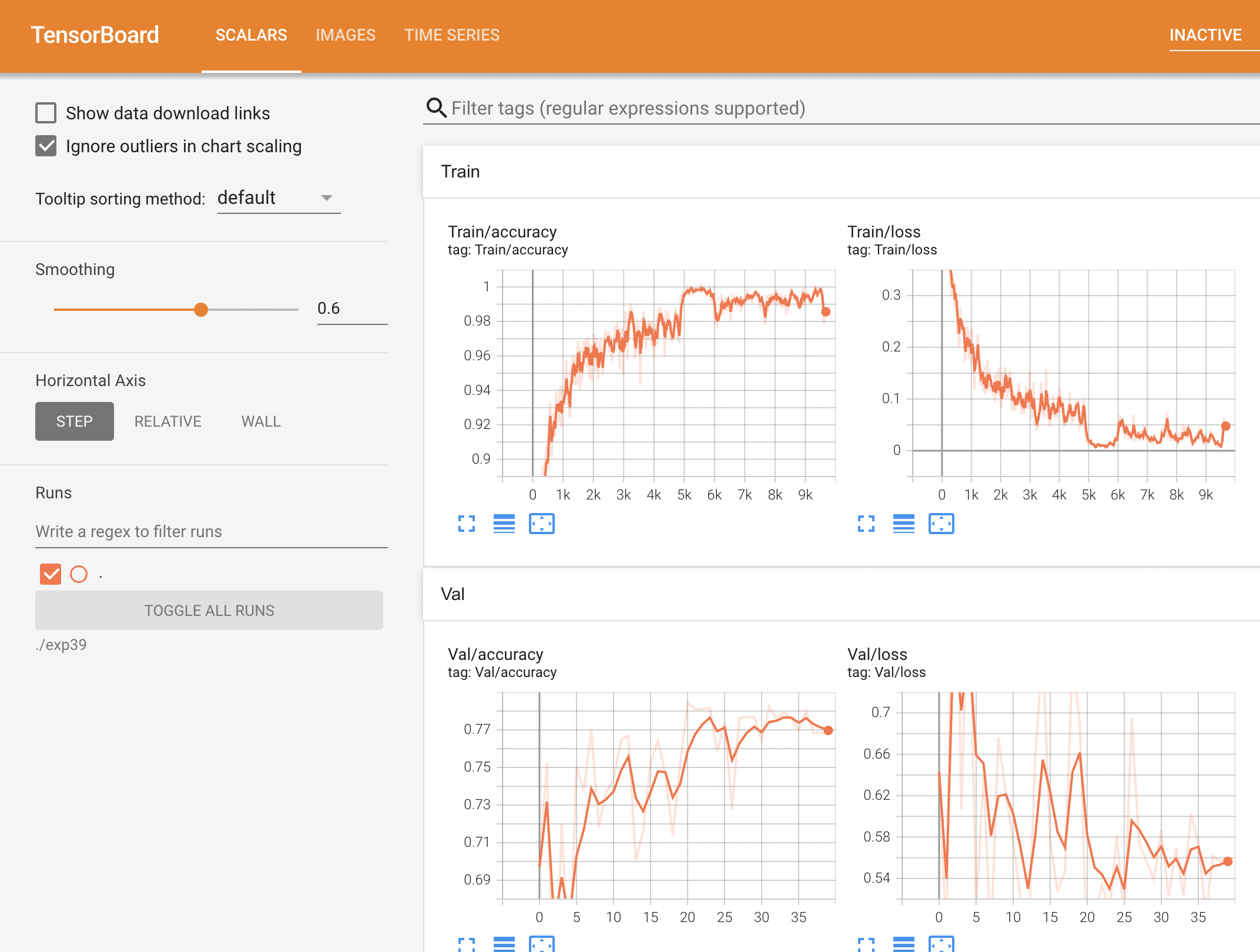
얼굴이 파란색인 부분은 cv는 이미지를 BGR로 읽어들이기 때문에 이걸 다시 RGB로 변환시켜야 하는데 이 부분을 잊어먹는 바람에 이런식의 결과가 나왔다.
또한 이미지의 크기를 y-100 처럼 얼굴 주변 부분 역시 일부분 포함되도록 크롭을 진행하였는데 이미지 크기 자체가 작기 때문에 리사이즈를 하지 않고 처음부터 그냥 얼굴 부분만 크롭하는게 더 나은 결과를 가져오지 않았을까 하는 아쉬움이 남는다.
✍Conclusion

Total : 48 teams
Our team : 42nd place
1️⃣ Public
- F1 Score : 0.7104
- Accuracy : 77.7302
2️⃣ Private
- F1 Score : 0.6614
- Accuracy : 74.9841
3️⃣ Retrospection

이번 P_Stage에서 진행한 마스크 착용 여부 경진대회에 참가한 회고를 작성하고자 합니다.
첫번째 딥러닝 경진대회에 참가하면서 이걸 도대체 어떻게 풀어나가야 하는지 막막한 기분이었지만, 다른 캠퍼분들이 작성해주신 리더보드와 마스터 님이 제공해주신 Baseline 코드를 따라가는 과정을 통해 많은 것들을 알아가는 시간이 되었습니다.
특히 경진대회 마지막날에 진행된 마스터클래스는 최상위 팀들이 경진대회를 어떻게 진행했는지를 발표하는 시간이 있어서 자신이 얼마나 삽질을 많이 했는지, 얼마나 부족한지 확인할 수 있는 좋은 기회가 되었습니다.
경진대회의 목표인 18개 클래스의 분류를 위해 다양한 모델(ResNet18, ResNet34, ResNet50, EfficientNet_b0, EfficientNet_b3)들을 테스트해보고 다양한 하이퍼파라미터(lr, input size, .. )에 변화를 주고 다양한 전처리 아이디어들(대비, 흑백화, 밝기조절, 크기조절, 잘라내기 등)을 적용해봤지만 주목할 만한 결과를 가져오지 못했습니다. 다른 팀들이 경진대회를 진행하면서 점점 스코어를 늘려나가는 와중에 같은 자리를 맴돌고 있는 우리 팀의 스코어를 보면서 정말 마음이 아팠습니다.
이번 경진대회에서 가장 아쉬웠던 점은 협업을 제대로 수행하지 못하였다는 점입니다. git을 사용하긴 했지만 원활 하게 사용하지 못했고 딥러닝 협업 툴(wandb, MLflow, ..) 역시 활용하지 못했습니다. 팀원들간에 대략적인 모델이나 경진대회의 진행상황은 공유하였지만 디테일한 부분(데이터 전처리방법, 모델, 하이퍼파라미터 등)을 공유하는 부분에서 많은 부족함을 느꼈고, 5명이서 각자 따로따로 경진대회에 참가하는 느낌을 받았습니다.
마스터클래스를 통해 최상위 팀들이 구글 시트와 wandb를 사용한 협업 진행방식을 보며 이러한 방법들이 상당히 효율적임을 알게 되었습니다. 또한 Tensorboard를 통하여 결과를 직접 눈으로 확인하는 것이 정말 중요하다는 것을 깨닳았습니다.
다음 P_Stage를 기다리며 이번 경진대회에서 얻은 경험과 데이터셋 그리고 Baseline 코드를 바탕으로 하여 미처 사용하지 못했던 wandb, MLflow를 적용시켜보고 Tensorboard에서 결과를 직접 시각화해볼 생각이다.
