-Ma, Qianli, et al. "Learning to dress 3d people in generative clothing." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.-
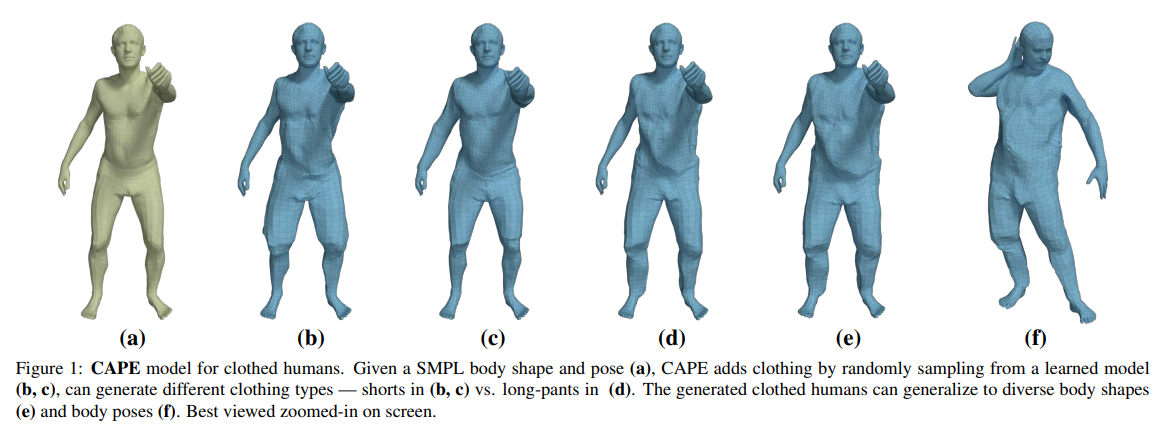
Abstract
기존 3차원 인체 모델은 최소복장인 상태에서 학습하므로 일반적인 이미지(옷을 입은)사람들에 대해 일반화 되어있지 않음
또한 기존의 모델은 자세 의존적인 옷의 변형을 표현하기 위한 표현력이 부족함
이를 해결하기 위해 옷으 입은 사람들의 다양한 포즈에 대한 3d 스캔을 활용해 3d mesh 모델을 학습시켰음
이를 우리는 MeshVAE-GAN 이라 함. SMPL body model에 의류의 변형을 학습시키기 위해 이를 사용하였음. 그리고 SMPL에 옷을 입히는 새로운 term을 추가하였음
우리 모델(MeshVAE-GAN)는 포즈와 의류 둘다 조건화시켰음.따라서 다양한 스타일과 포즈를 재현할 수 있음
Patchwise example

우리는 옷의 주름같은 디테일을 보존하기 위해 Mesh-VAE-GAN 은 patchwise discriminator를 사용함
3d 메시에 옷을 입히고 파라메터릭 시킨 첫번째 프레임워크
1. Introduction
기존의 모델들은 합성훈련데이터를 사용하였고 이에 따라 실제 사람의 이미지간에 많은 차이가 존재하였음
또한 기존의 딥러닝 방법들은 최소한의 복장을 한 인간 모델을 기반으로 사람의 모양을 재구성함
이 때문에 신체의 자세는 일치할지라도 옷을 입은 신체의 형상(shape)는 일치하지 않음
따라서 우리의 목표는 옷을 입은 사람 몸체의 생성 모델을 만드는건데 이는 저차원 임베딩 공간을 가지고 있고, 쉽게 포즈를 취할 수 있으며, 미분가능하고(훈련가능하고), 다양한 신체 형상과 다양한 신체 포즈에 대해 다양한 옷을 입은 그럴듯한 표현의 shape을 만들어 낼 수 있는 생성 모델임.
이를 달성하기 위해 우리는 SMPL을 확장하였고 옷을 입은 shape를 분해하여 옷을 입지 않은 표준 shape에 추가적인 변화로 처리함
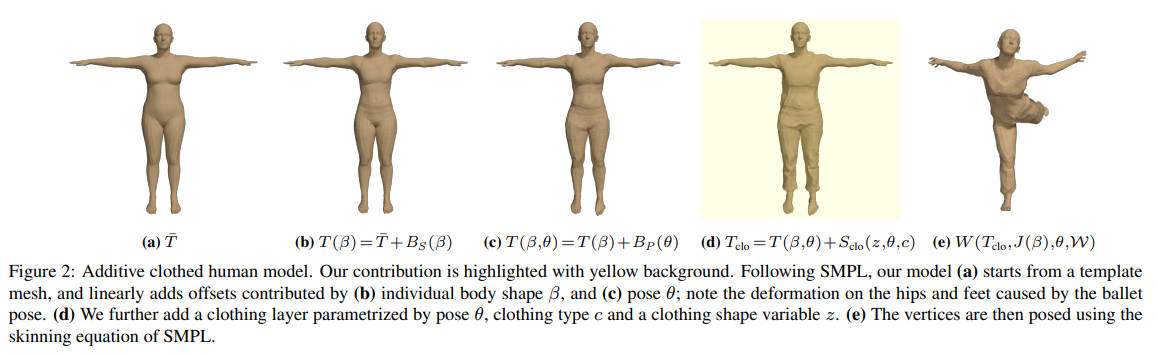
-> 즉 해당 논문은 포즈( )에 의해 변형되는 의류 레이어를 기존의 SMPL 모델 템플릿( )에 추가한것.
이렇게 학습된 레이어는 SMPL 모델과 호환되므로 쉽게 재포즈, 및 애니메이션이 가능해짐
-> 주워진 body shape에 대해 포즈와 옷의 모양은 일대다 관계임
따라서 우리의 모델 CAPE(“Clothed Auto Person Encoding”)은 옷의 타입과 몸의 포즈에 조건을 가지고 있음. 따라서 여러 타입의 옷을 포착할 수 있고 포즈에 의존적인 변형을 생성할 수 있음
-> SMPL체형이나 자세, 의류의 유형이 주워지면 CAPE는 학습된 잠재 공간을 사용해서 그럴듯한 의류 구조를 생성할 수 있음
Technical approach.
피봇(pivot) : 회전하는 물체의 중심을 잡아주는 중심점
오프셋 : 변화량
즉 오프셋 버텍스는 기존의 버텍스(기저메시)에 대해 기저메시가 얼마나 변했나 표현하는 버텍스임
SMPL의 토폴로지를 상속한 그래프(mesh)를 사용해서 옷을 변위 레이어로 표현함
그래프의 각각의 노드들은 기본적인 신체의 버텍스에 해당하는 오프셋 버텍스들임
이러한 그래프(옷)을 생성하는 생성 모델을 학습하기 위해 그래프컨볼루션+메시셈플링을 백본으로 사용하는 VAE GAN을 사용해 그래프 컨볼루션 신경망을 만듬
이를 사용해 기존의 생성모델이 가지고있던 '너무 깔끔한 매시를 만드는 문제'를 해결함
-> 즉 옷의 주름같은 디테일을 살림
즉 패치별 discriminator를 사용해 옷의 주름같은 디테일을 살리는 그래프를 생성하는 GAN 모델을 학습
Dataset.
다양한 유형의 의복을 입고 있고, 다양한 포즈를 수행하는 4D 캡처된 사람들의 데이터셋을 만들었음(CAPE dataset)
해당 데이터셋은 4D 스캐너를 사용한 80k 프레임으로 구성되어있고 이를 사용해서 네트워크를 훈련시켰음
Versatility.
CAPE는 SMPL을 기반으로 만들어져서 기존의 SMPL을 사용하는 작업에 쉽게 이식할 수 있음
이를 편하게 사용하기 위해 SMPLify를 확장하여 이미지에서 모델은 fit 함
key contribution
1) 옷을 모델링하는데 있어 확률론적 공식을 제안함
2) 이를 사용해 Mesh-VAE GAN을 학습시켰음(사람의 포즈와 옷의 타입에 대해 조건화되고 글로벌하고 로컬적인 디테일을 포착할 수 있는)
3) 학습된 모델은 포즈에 의존적인 옷의 변형을 생성할 수 있고 다양한 의류에 대해 일반화 되어져 있음
4) 기존의 SMPL 모델을 확장하여 Clothed-SMPL을 완성하였음
5) 다양한 포즈 시퀸스를 가진 옷을 입은 사람들의 4D 스캔 데이터셋을 만들었음
2. Related Work
나중에할게요 관련 연구
의류의 모델링은 예전부터 연구되어져 왔음
Table 1 shows recent methods categorized into two major classes: (1) reconstruction and capture methods, and (2) parametric models, detailed as follows.
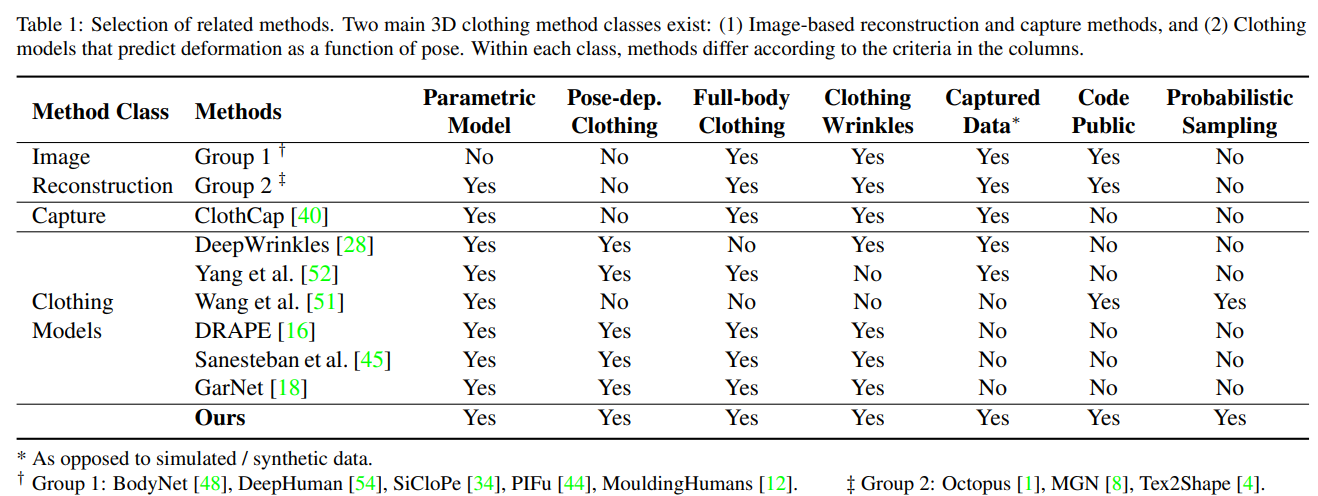
Reconstructing 3D humans.
Parametric models for 3D bodies and clothes.
Generative models on 3D meshes.
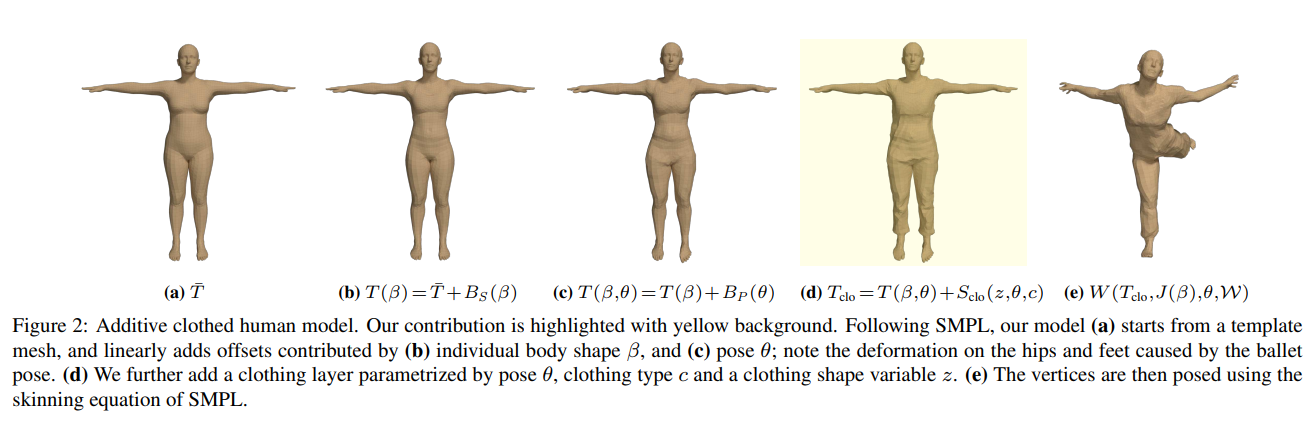
3. Additive Clothed Human Model
옷을 입은 사람의 몸을 모델링하기 위해
옷을 입지 않은(최소복장 모델)몸과 옷을 분리시킴(이때 옷은 몸의 변위로 표현됨)
이를 통해 의류를 추가적인 몸의 형상으로 표현함으로써 자연스럽게 SMPL을 확장할 수 있음
-> SMPL을 효과적으로 대체할 수 있음
3.1. Dressing SMPL
SMPL은 인체를 body parameter()와 pose parameter() 로 표현하는 인체 생성 모델임
-SMPL-
그림과 같이 SMPL은 템플릿화된 mesh 에서 시작함(6890 vertex)
shape와 pose 파라미터()가 주워지면 이에 따라 3D 오프셋은 템플릿을 변형시킴.(형상의 변형 , 포즈의 변형 )
변형이 완료된 메시는 표면 함수 에의해 포즈되어짐
the blend skinning function 는 3d 관절 J(를 통해 계산) 주위의 정점(T)들을 회전시킨 다음 블렌드 가중치 를 사용해 linearly smoothes 시키고 포즈를 취한 정점들 M 을 리턴함
는 이고 23개 관절에서의 상대적인 3d 회전과 축과 각도 표현에서의 회전 벡터로 표현됨
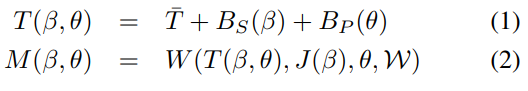
SMPL은 신체의 shape를 만들기 위해 linear deformation layers 라는 레이어를 추가하는데
이것을 활용하여 우리는 추가적인 clothing 오프셋 레이어를 정의함. 그리고 SMPL 메쉬 위에 추가함.
-> 포즈()와 의류의 타입()를 임베딩하는 잠재변수()를 통해 의류 레이어를 매개변수화 함
따라서 의류 변형 레이어 를 사용해 기존의 식 를 확장하여 옷을 입은 신체 템플릿으로 사용함

은 포즈에 의존적임
이를 사용하여 W함수를 사용하면 최종적으로 옷을 입고, 포즈된 mesh가 나옴

3.2. Clothing representation(구 방법과 비교)

기존의 방법들은 Vertex displacement를 사용해 의류를 표현하였는데 이러한 방법들은
displacement를 구현하기 어려움
The displacement layer 를 사용하여 옷을 표현하는데 이는 SMPL 토폴로지를 상속하는

라는 그래프임
-> 이 그래프를 구하기 위해 가 필요함(의류에 대한 변위만 등록된 버텍스 레이어)
: 본체 메시와 대응하는 버텍스에서 나오는 오프셋 버텍스
즉 SMPL의 엣지와 버텍스들을 가지고 의류를 표현하는 The displacement layer를 훈련시킴

이를 훈련시키기 위해 옷을 입은 사람들의 3D 모델들을 훈련시킴
-> 최소의류 모델의 버텍스와 옷을 입은 모델의 버텍스를 쌍으로 지어 훈련
-> 즉 피사체의 최소의류 스캔과 의류 스캔 둘다 스캔한 다음 옷을 포착할 수 있는 SMPL 모델을 사용해 스캔한 사람을 등록함
이 결과로써 SMPL(옷을 포착할 수 있으므로) 메시가 스캔들에 대한 기하학적인 정보(옷에 대한), 그리고 이 스캔에 대한 포즈 매개변수(), 각각에 대한 (옷을 입고, 안입은)버텍스를 얻을 수 있음
이런식으로 얻어지는 쌍에 대해 의류에 대한 오프셋 버텍스를 구할 수 있는데 임.
-> 는 옷을 입은 부위에 대해서만 0을 아닌 값을 가지게 됨
하지만 CAPE는 SMPL body 모델을 옷을 입은 body로 확장함
The displacement layer에 있어서
이전 방법들(volumetric representation)에 비해 우리의 방법(의류 레이어와 인체 모델을 혼합하는 )이 의류의 포착이나, 모델의 동작을 표현하는데 있어서 더 좋음.
이전 방법들은 body에 사용하는 블렌드 스킨을 옷에 사용하는것에 비하여(body 두개 분량)
우리의 방법은 최소의류를 입은 body의 형태에 옷들의 변위만 추가하여 사용
-> 즉 오프셋을 사용해 SMPL에 옷을 입히는 기존의 방법들과는 다르게 우리의 의류 레이어는 파라메트릭하고 잠재공간을 사용하면 포즈에 의존적임
4. CAPE
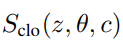
우리의 의류 term은 의류의 모양과 구조에 대한 잠재공간 z, pose , 의류 타입 에 대한 함수임.
이 레이어는 SMPL 토폴로지를 상속함
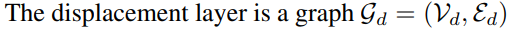
이 term은 The displacement layer 를 아웃풋으로 가짐
우리는 이 공식을 그래프 컨볼루션을 사용해서 VAE 프레임워크의 파라미터화 시켰음
4.1. Network architecture
(a) 의 결과가 VAE의 아웃풋이
조건 네트워크 C1 :
조건 네트워크 C2 :
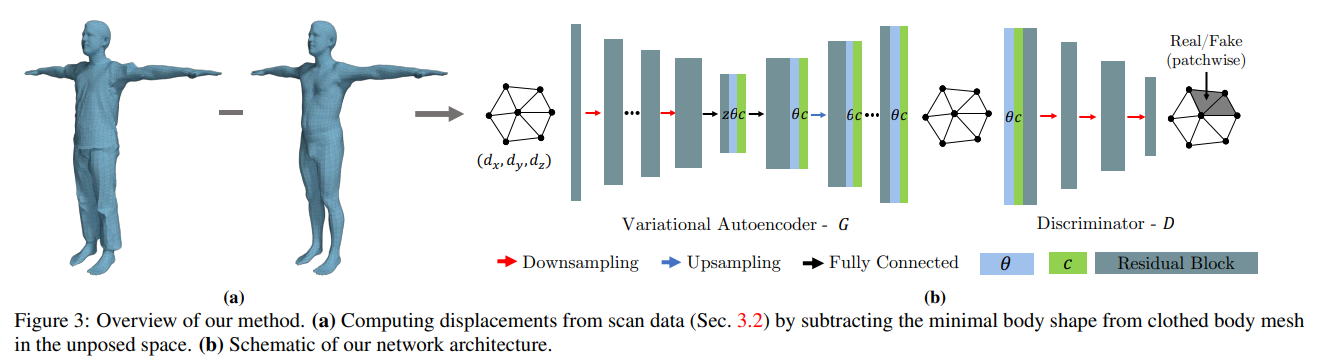

그린과같이 우리의 프레임워크는 VAE-GAN 패턴을 사용함
추가적으로 보조네트워크 C1,C2를 조건처리를 위해 사용함
또한 end-to-end임
간단하게 말하기 위해 다음의 주석을 사용함
: 의 버텍스들 ( : 변위 그래프 입력값)
: 재구성된 그래프의 버텍스들
: 포즈와 옷의 타입을 결정하는 벡터
: 잠재공간 백터
Graph generator.
인코더는 변위 버텍스들 를 입력으로 받아 그래프 컨볼루션을 통해 피쳐를 잠재공간 z에 매핑함
디코더는 잠재공간 z 로부터 를 재구성함.
residual connections
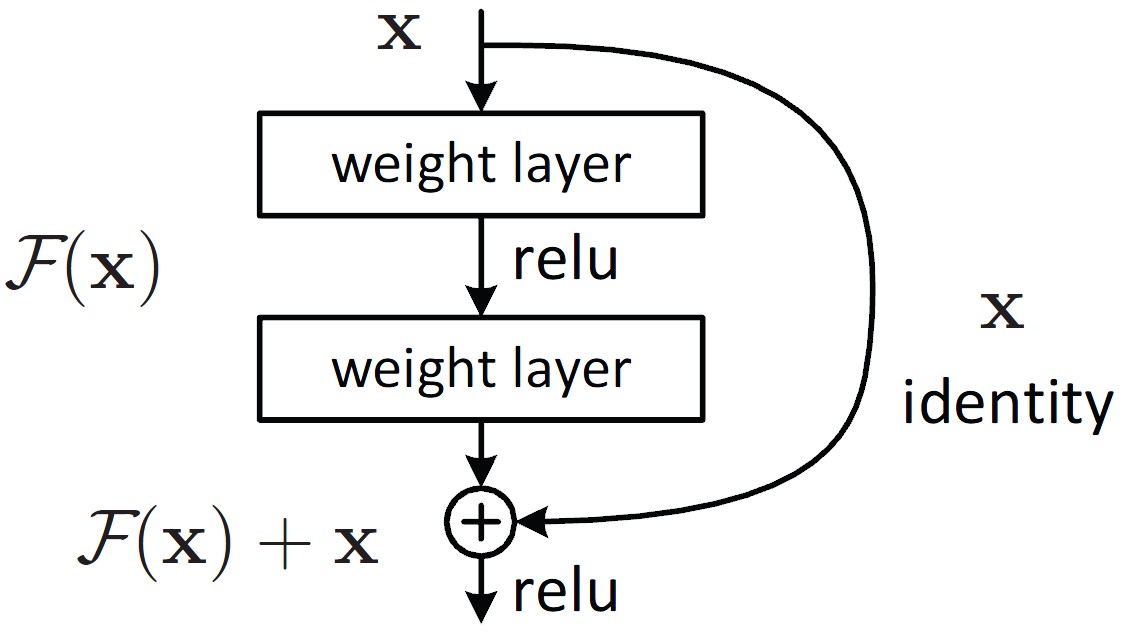
그래프 컨볼루션을 깊이 쌓을 경우 로컬 정보(옷의 주름같은 디테일)의 손실이 발생함
이를 방지하기 위해 우리는 표준적인 그래프 컨볼루션 레이어에 residual connections을 적용하여 개선하였음
테스트 시에는 인코더가 불필요함.
대신 z는 사전 정의된 분포로부터 샘플링되고, 디코더가 그래프 생성기 역활을 함
Patchwise discriminator.
매시를 제구성하는것에 있어 디테일한 정보를 살리기 위해 우리는 비전 영역에서 좋은 결과를 가지고 있는 patchwise discriminator를 도입하였음
생성된 전체 그래프를 통해 fake real을 판단하는것보다 일부분(patch)에 대해서 로컬적인 판단을 함
즉 discriminator 의 역활은 옷의 주름같은 미세한 부분에 대한 표현력에 초점을 맞추고 있는것
글로벌한 shape은 rec loss가 판단하도록 함
우리의 discriminator 는 4개의 그래프 컨볼루션 다운셈플 블록으로 구성되어 있음
이를 통해 출력 버텍스 들의 이웃 노드들에 대해 (patch)real/fake를 분류할 수 있음
Conditional model.
우리는 네트워크를 포즈벡터 와 의류타입 로 조건화함.
SMPL의 포즈는 축과 축이 이루는 각도로 표현되어있으며 이를 네트워크로 표현하기 어려움.
따라서 우리는 포즈 파라미터를 회전행렬로 바꿔서 사용함 (the Rodrigues equation)
옷의 타입을 구별하기 위해 우리는 원핫 라벨링을 사용하였음
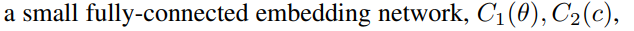
두가지의 조건 파라미터는 차원적 동일성(디코더 하는 과정에 합쳐지기 때문에)을 가지기 위해 FC레이어를 통과함
우리는 또한 이러한 조건 레이어를 잠재 공간에 추가하고 동시에 모든 디코더의 피쳐에 추가하는 방식이 더 좋은 결과를 가져오는것을 발견함.
4.2. Losses and learning
재구성 로스로써 입력과 출력 버텍스들에 대해 L1 norm을 적용하였음.
왜냐면 l2노름은 디테일을 뭉개버릴 가능성이 있기 때문
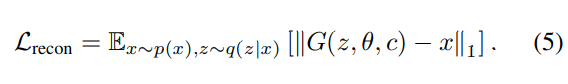
또한 옷의 디테일한 정보(주름)을 표현하기 위해 매시의 엣지에 loss를 적용함
엣지들의 집합 e (GT)에 대해서 e^은 생성된 엣지임

또한 KLloss를 사용해서 잠재공간을 잘 표현하는 분포를 근사시켰음(가우시안)

GAN도 역시 적대적 los를 사용해서 학습시킴
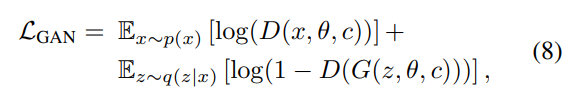
total loss
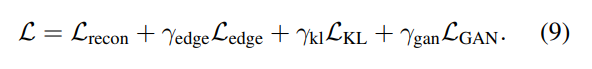
5. CAPE Dataset

좋은 기계를 써서 잘 스캔 했음
각각의 스캔에 대해 SMPL의 모델 토폴로지가 등록되어 있음
옷 안쪽의 몸에 대한 정보를 얻기 위해 최소의류복장 역시 스캔함
8가지 의류 타입이 있음
다양한 그래프 아키텍쳐의 정량적 평가에 사용될 수 있음
6. Experiments
우리 모델의 재구성 표현 능력을 보여줌
우리 모델의 생성 능력을 보여줌
포즈와 shape을 추정하는 어플리케이션도 보여줌
6.1. Representation power
3D mesh auto-encoding errors.
VAE 모델의 측정을 위해 컨볼루션 메시 인토더 CoMA와 PCA를 비교대상으로 함
다운샘플링이 디테일을 뭉개버리는 영향을 연구하기 위해 다운샘플링을 표현하여 비교함
모든 모델에 대해 동일한 잠재 공간과 동일한 파라미터 설정을 사용함
네트워크를 사용해 의류의 오프셋 그래프를 재구성할때의 유클리디안 오류를 보여줌
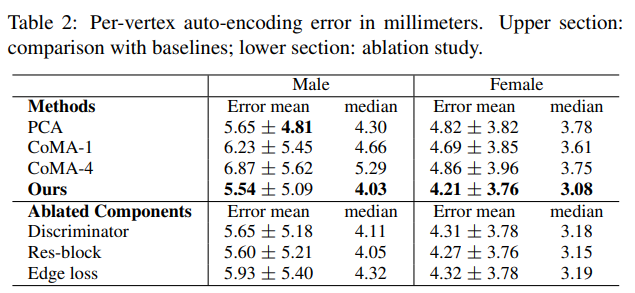
의복에 덮여있지 않은 부위는 평가에서 제외됨
우리 모델을 사용하여 재구성된 shape는 포즈에 의존적임 + 확률적임.
CoMA 는 리컨스트럭션 테스크에 초점을 맞추고 있음
PCA는 포즈 매개 변수를 활용할 수 없음 또한 의류의 복잡한 변형을 유지하지 못함
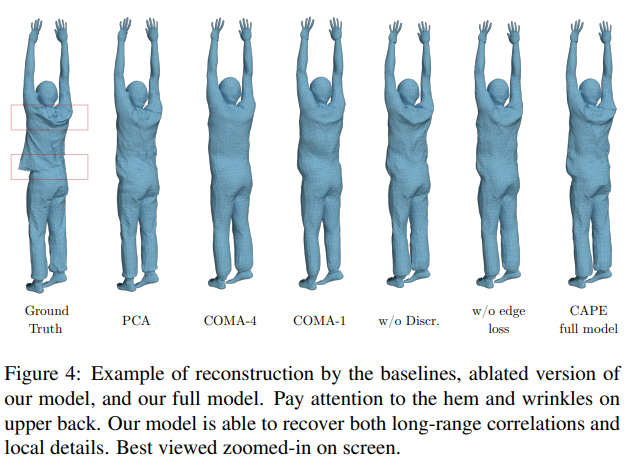
이러한 문제점들을 우리는 해결함
Ablation study.

주요한 구성 요소들을 제거하고 성능을 평가함으로써 이러한 모듈들이 성능에 주요한 영향을 미친다고 판단함
6.2. Conditional generation of clothing
조건에 따라 옷에 어떤 영향을 미치는지 확인함
Sampling.

훈련에서 사용되지 않은 포즈에 옷을 입힌 모습을 보여줌
포즈와 의류유형을 고정하고 z 를 샘플링하여 다양한 의류 형태를 생성함
Pose-dependent clothing deformation.
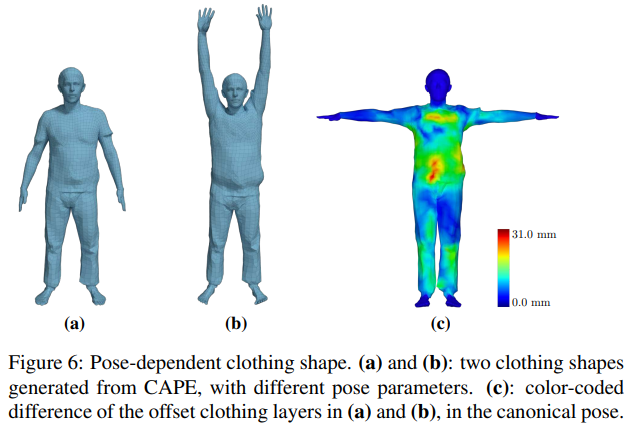
기존의 옷을 입은 몸을 애니메이팅 화 시킬 수 있음
표는 a와 b를 표준화 포즈로 바꾸었을 경우에 loss 를 보여줌
-> 포즈를 바꾸었음에도 옷의 표현에 대해 옷이 바뀌지 않고 잘 표현해줌
User study of generated examples.
생성된 결과를 평가하기 위해 Amazon Mechanical Turk (AMT)를 활용함
실제 3d 렌더링한 데이터와 모델에 의해 생성된 가짜 데이터를 비교하여 평가

6.3. Image fitting

SMPLify 를 사용해서 피팅함 CAPE 를 사용할 경우 기존 SMPL 보다 더 좋음(옷을 포착하므로)
우리의 모델은 z 또는 옷 유형 c를 재샘플링하여 피사체의 옷을 바꿀 수 있을 뿐만 아니라 휴식과 애니메이션을 할 수 있다. 이것은 여러 응용 프로그램의 가능성을 보여준다. 우리는 보충 비디오에서 예시를 보여준다.
7. Conclusions, Limitations, Future Work
First, CAPE inherits the limitation of the offset representation for clothing: (1) Garments such as skirts and open jackets differ from the body topology and cannot be trivially represented by offsets. Consequently, when fitting CAPE to images containing such garments, it could fail to explain the image evidence; see discussions on the skirt example in the supplementary material. (2) Mittens and shoes: they can technically be modeled by the offsets, but their geometry is sufficiently different from fingers and toes, making this impractical. A multi-layer model can potentially overcome these limitations. Second, the level of geometric details that CAPE can achieve is upper-bounded by the mesh resolution of SMPL. To produce finer wrinkles, one can resort to higher resolution meshes or bump maps. Third, while our generated clothing depends on pose, it does not depend on dynamics. This does not cause severe problem for most slow motions but does not generalize to faster motions. Future work will address modeling clothing deformation on temporal sequence and dynamics.
신발이나 장갑 모델링 x
스커트나 자켓 x
역학 고려 x (몸이 빠르게 움직일 경우 고려 x)
