- 컨테이너 인프라 환경 : Linux OS의 커널 하나에서 여러 개의 컨테이너가 격리된 상태로(하나 이상의 목적을 위해 독립적으로) 실행되는 인프라 환경
사용자가 늘어나고 서버가 늘어나면 일관성을 유지하는 것이 중요 -> 눈송이서버 방지 (=여러 사람이 만져 설정의 일관성 떨어진 서버)
- In 가상화 환경 : 각각 VM들이 모두 독립적 OS 커널 가지고 있어 자원 소모 ↑ 성능 ↓
- In 컨테이너 인프라 환경 : OS 커널 하나에 컨테이너 여러 개가 격리된 형태로 실행 ==> 자원 효율적 사용 자원 소모 ↓ 성능↑
since : 구글이 쿠버네티스를 오픈소스로 공개한 2014년 이후로 부터 쿠버네티스의 생태계가 풍부해졌다.
3장에서 배울 내용
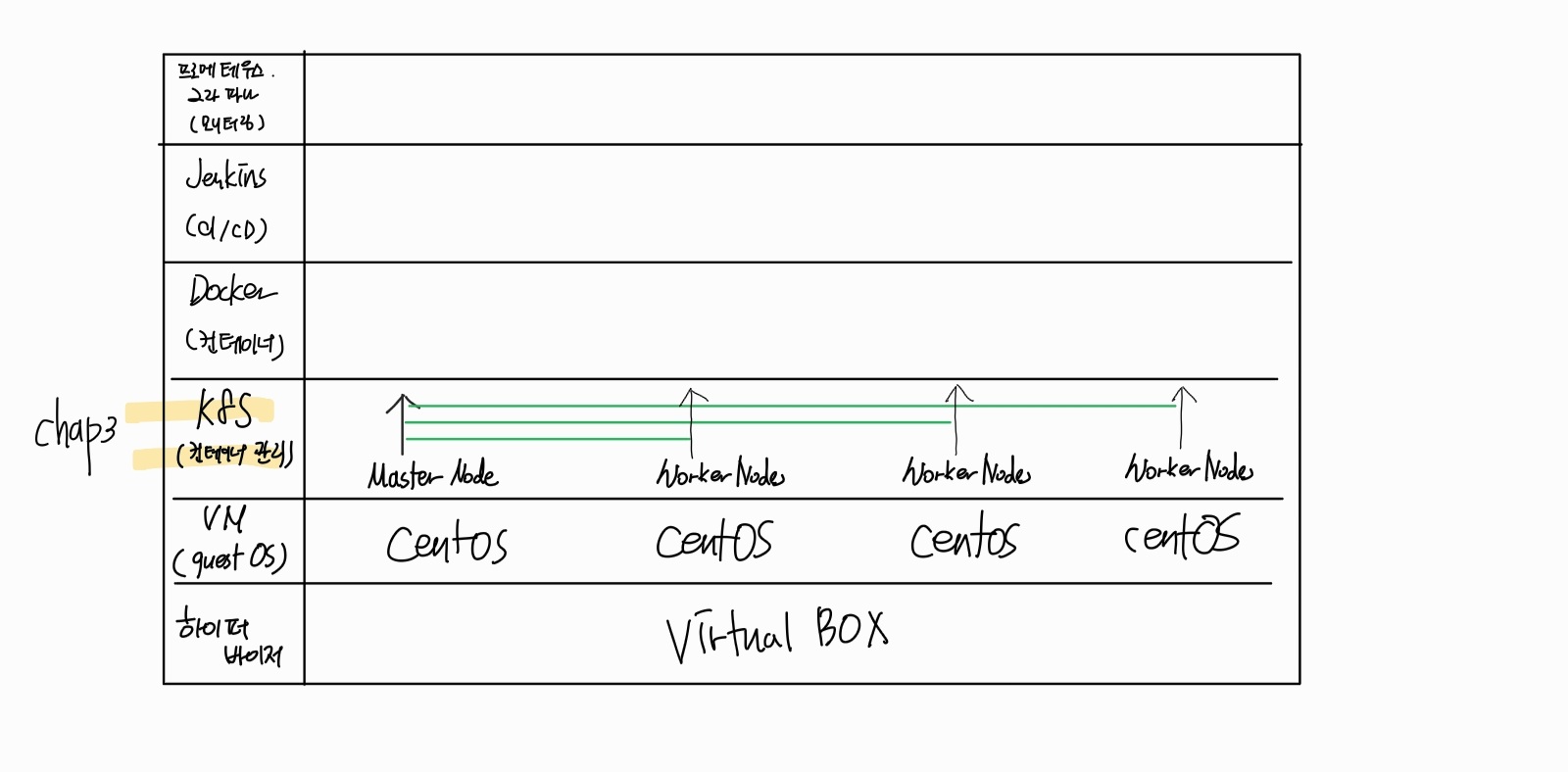
최종적으로 배우는 내용
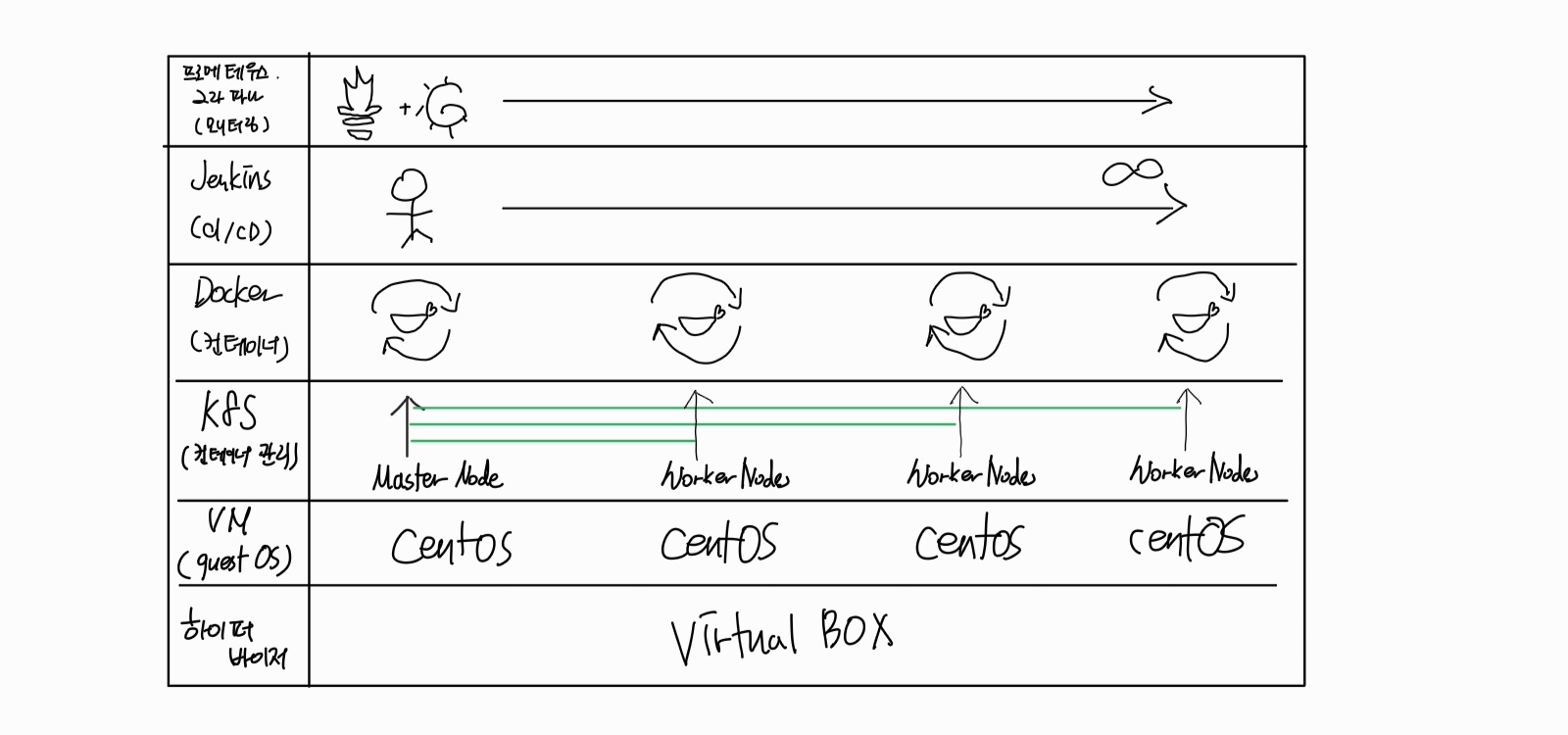
3.1 쿠버네티스 이해하기
❓쿠버네티스는
컨테이너 오케스트레이션을 위한 솔루션이다.
- 오케스트레이션 : Orchestration, 복잡한 단계를 관리하고 요소들의 유기적인 관계를 미리 정의해 손쉽게 사용하도록 서비스를 제공하는 것.
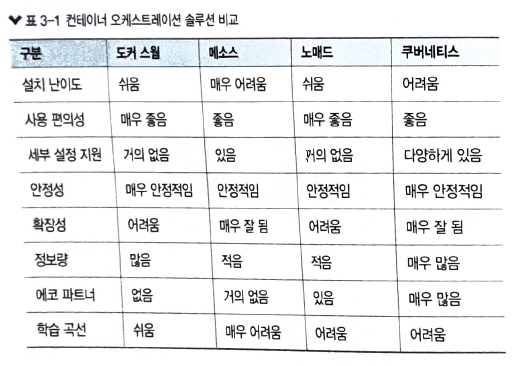
- 컨테이너 오케스트레이션 : 다수의 컨테이너를 유기적으로 연결, 실행, 종료할 뿐만 아니라 상태를 추적하고 보존하는 등 컨테이너를 안정적으로 사용할 수 있게 만들어주는 것. 쿠버네티스 이외에도 도커스윔, 메소스, 노마드 등이 있음
왜 쿠버네티스?
시작하는데 어려움이 있지만 (사용을 쉽게 해주는 도구들이 나오고있음) 다양한 형태의 쿠버네티스가 지속적으로 계속발전되고 있다.
거의 모든 벤터와 오픈 소스 진영에서 쿠버네티스를 지원하고 그에 맞게 통합개발한다. == 컨테이너 오케스트레이션에서 it 인프라 자체를 컨테이너화하고 컨테이너화된 인프라 제품군을 쿠버네티스에서 동작하게 만든다. ==> 컨테이너 오케스트레이션 학습 / 도입 목표라면 쿠버네티스 우선 고려
- k8s == 쿠버네티스
k8s 는 쿠버네티스의 약자
k8(ubernete, 8글자)s의 형식
쿠버네티스 구성 방법
1 퍼블릭 클라우드 업체에서 제공하는 관리형 쿠버네티스인 EKS. AKS, GKE 등 사용 but 구성이 이미 갖춰져있어 학습용으로 부적합
2 수세의 Rancher, 레드햇의 OpenShift와 같은 플랫폼에서 제공하는 설치형 쿠버네티스를 사용 but 유료
3 쿠버네티스 클러스터를 자동으로 구성해주는 솔루션을 사용 (kubeadm)
https://github.com/sysnet4admin/_Book_k8sInfra 에서 코드 다운 받고
- Vagrantfile : 베이그런트 프로비저닝을 위한 정보를 담고 있는 메인 파일
vagrant up: 현재 호스트 내부에 Vagrantfile에 정의된 가상 머신들을 생성하고 생성한 가상 머신에 쿠버네티스 클러스트를구성하기 위한 파일들을 호출해 쿠버네티스 클러스터를 자동으로 구성
- config.sh: kubeadm으로 쿠버네티스를 설치하기 위한 사전 조건을 설정하는 스크립트 파일
- Install_pkg.sh: 클러스터를 구성하기 위해서 가상 머신에 설치돼야 하는 의존성 패키지를 명시
- master_node.sh: 1개의 가상 머신(m-k8s)을 쿠버네티스 마스터 노드로 구성하는 스크립트
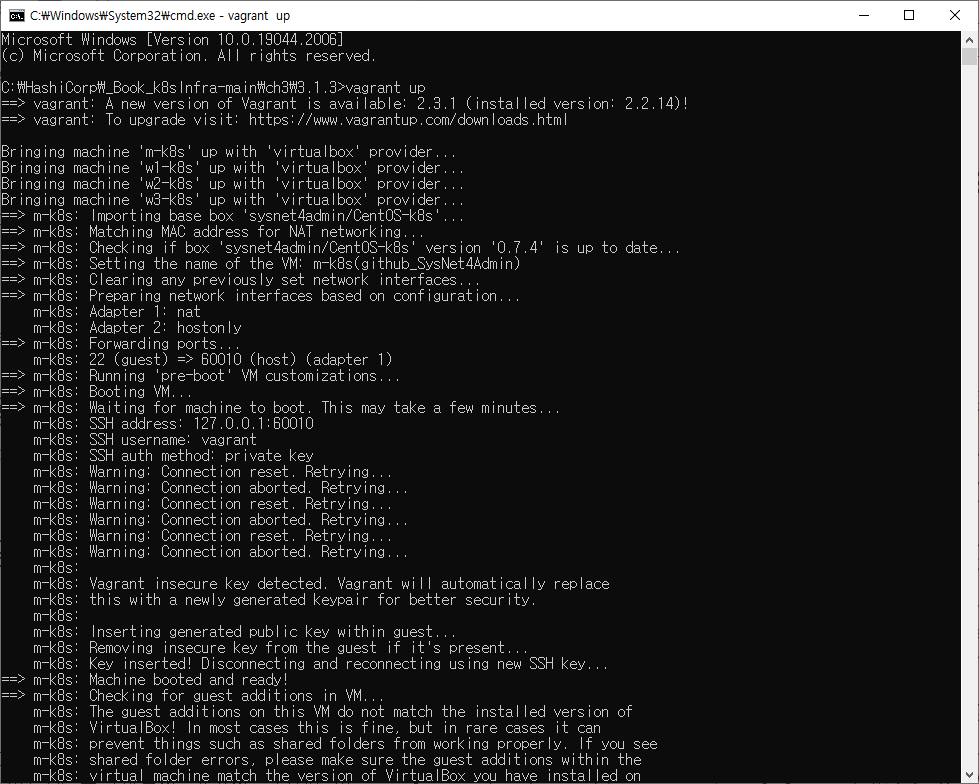
긴 시간이 지나 드디어 완료
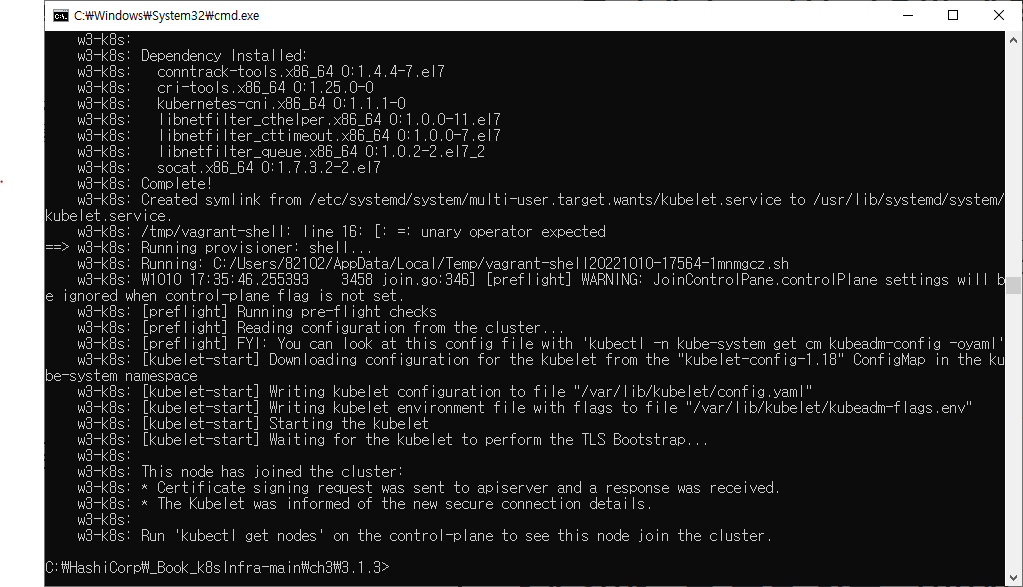
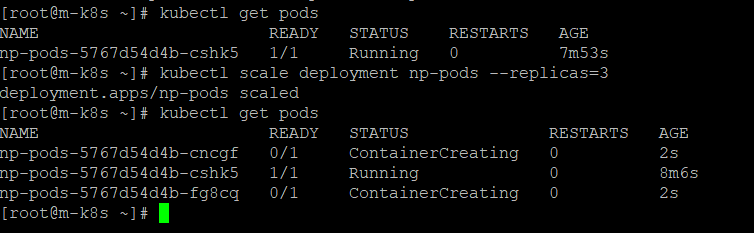
이렇게 클러스터 구성을 완료했음
슈퍼 푸티 로 확인
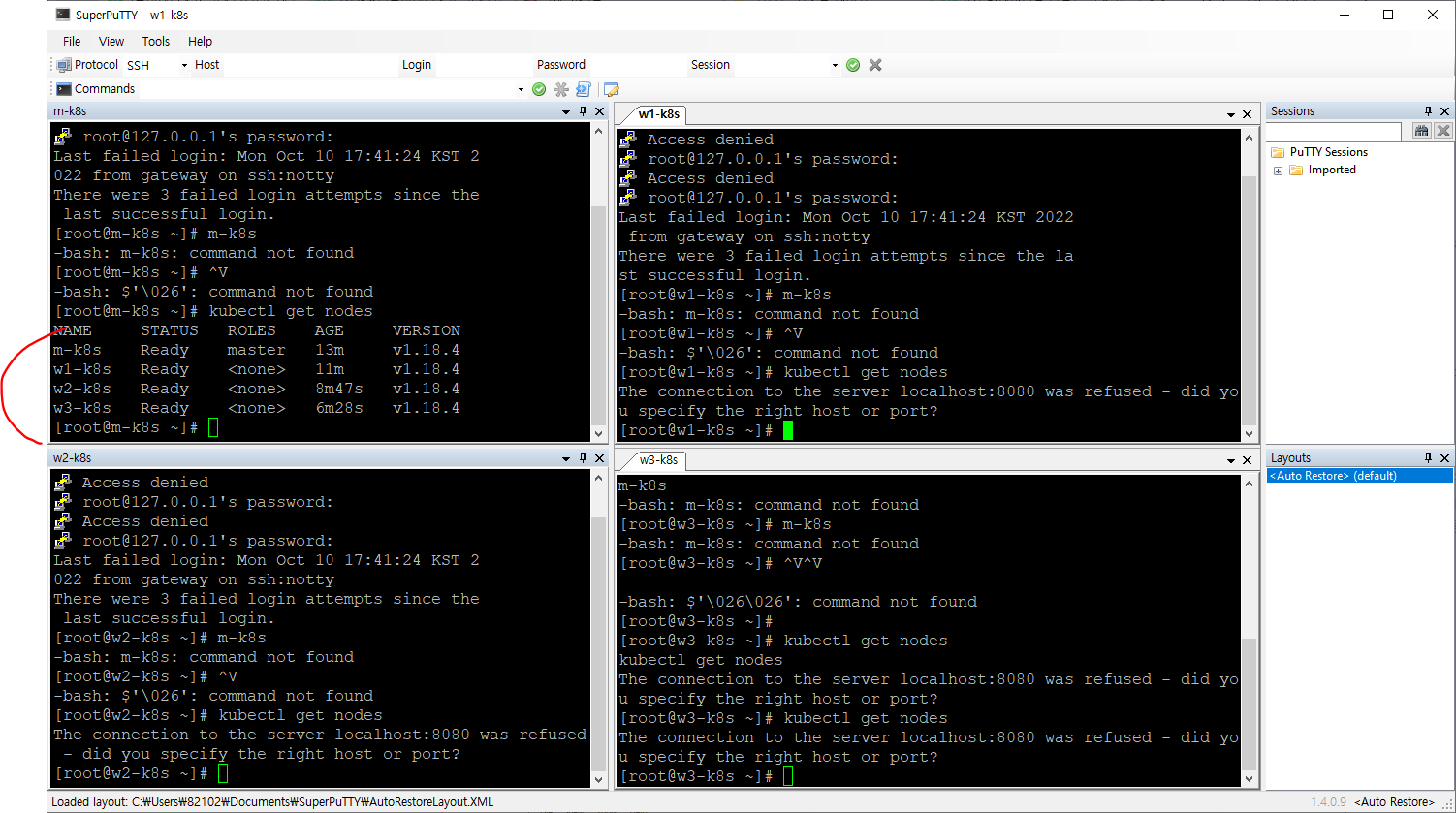
파드 배포 중심으로 쿠버네티스 구성요소 보기
앞에 나온 kubectl, kubelet, API 서버, 캘리코 등 + 그 외에도 etcd, 컨트롤러 매니저, 스케줄러, kube-proxy, 컨테이너 런타임, 파드등이 클러스터 구성요소다.
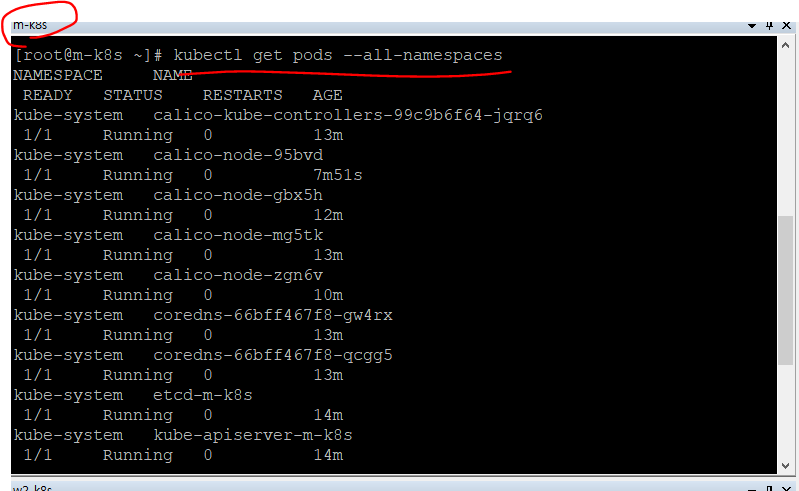
쿠버네티스 클러스터를 이루는 구성 요소들은 파드 형태로 이루어져 있음!
쿠버네티스 구성요소는 동시에 여러개 존재시 -> 뒤에 해쉬코드(무작위 문자열)를 삽입해서 이름을 생성함
관리자 또는 개발자가 파드를 배포시
쿠버네티스의 구성 요소의 유기적인 연결 관계
쿠버네티스의 구성 요소간 통신
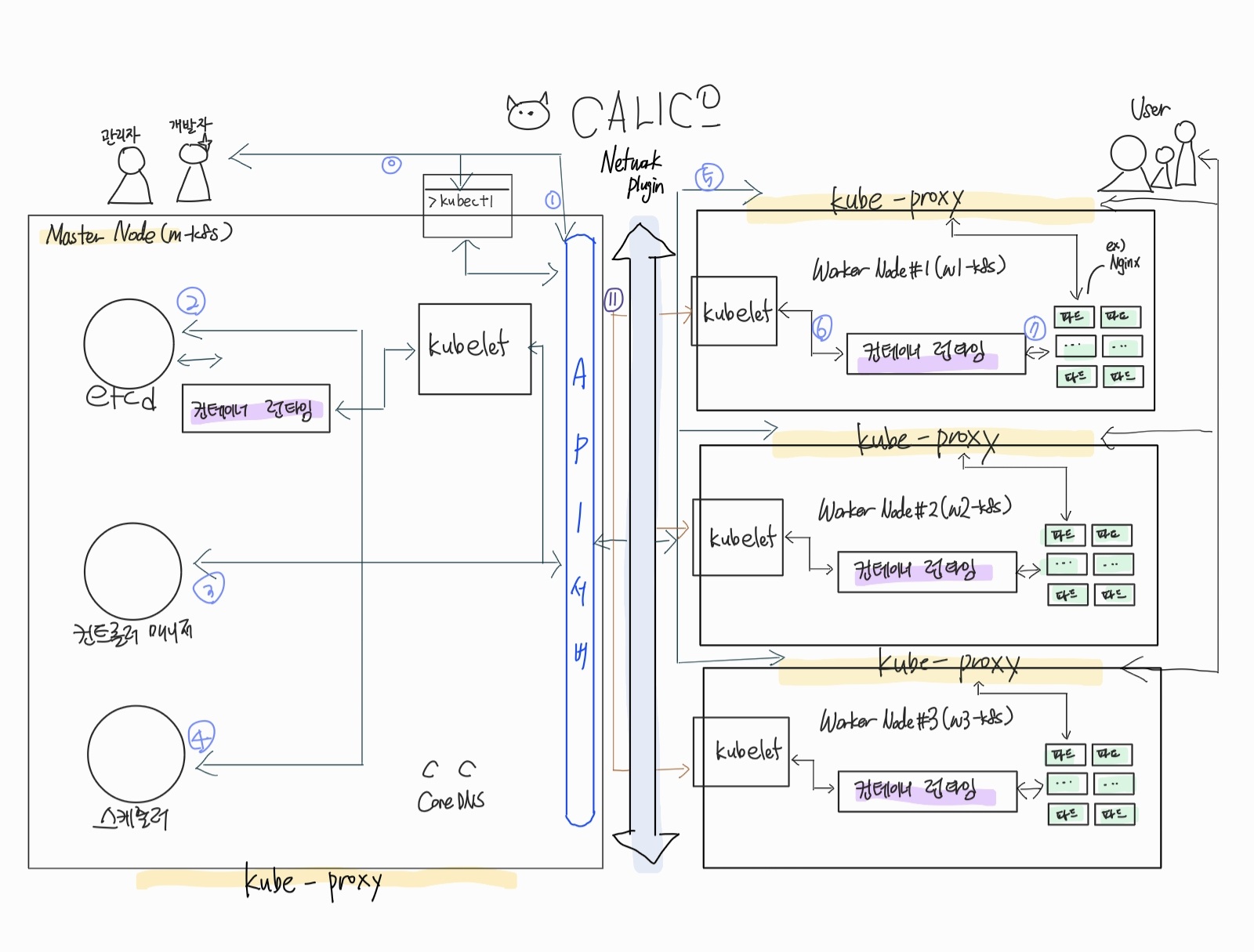
-
마스터 노드
0 kubectl: 쿠버네티스 클러스터에 명령을 내리는 역할
1 API 서버: 쿠버네티스 클러스터의 중심 역할을 하는 통로
2 etcd: 구성 요소들의 상태 값이 모두 저장되는 곳
3 컨트롤러 매니저: 컨트롤러 매니저는 쿠버네티스 클러스터의 오브젝트 상태를 관리
4 스케줄러: 노드의 상태와 자원, 레이블, 요구 조건 등을 고려해 파드를 어떤 워커 노드에 생성 할 것인지를 결정하고 할당etcd는 약어가 아님
etcd는 리눅스의 구성 정보를 주로 가지고 있는 etc 디렉터리와 distributed(퍼뜨렸다)의 합성어 -
워커 노드
5 kubelet: 파드의 구성 내용(PodSpec)을 받아서 컨테이너 런타임으로 전달하고, 파드 안의 컨테이너들이 정상적으로 작동하는지 모니터링
6 컨테이너 런타임(CRI, Container Runtime Interface): 파드를 이루는 컨테이너의 실행을 담당
7 파드(Pod): 한 개 이상의 컨테이너로 단일 목적의 일을 하기 위해서 모인 단위
== 웹 서버 역할을 할 수도 있고 로그나 데이터를 분석도 가능
파드는 언제라도 죽을 수 있는 존재!
가상 머신은 언제라도 죽을 수 있다고 가정하고 디자인하지 않지만, 파드는 언제라도 죽을 수 있다고 가정하고 설계됐기 때문에 쿠버네티스는 여러 대안을 디자인되어있음
(0-7은 쿠버네티스에서 이루어지는 통신 단계, 선택적 배포는 순서와 연관이 없어서 10번대로 구분해서 표시했다고 함)
- 선택 가능 구성요소
11 네트워크 플러그인 : 쿠버네티스 클러스터의 통신을 위한 구성
12 CoreDNS : 클라우드 네이티브 컴퓨팅 재단에서 보증하는 프로젝트로, 빠르고 유연한 DNS 서버
파드의 생명주기로 쿠버네티스 구성 요소 살펴보기
파드가 생성, 수정,삭제되는 과정을 나타낸 파드의 생명주기
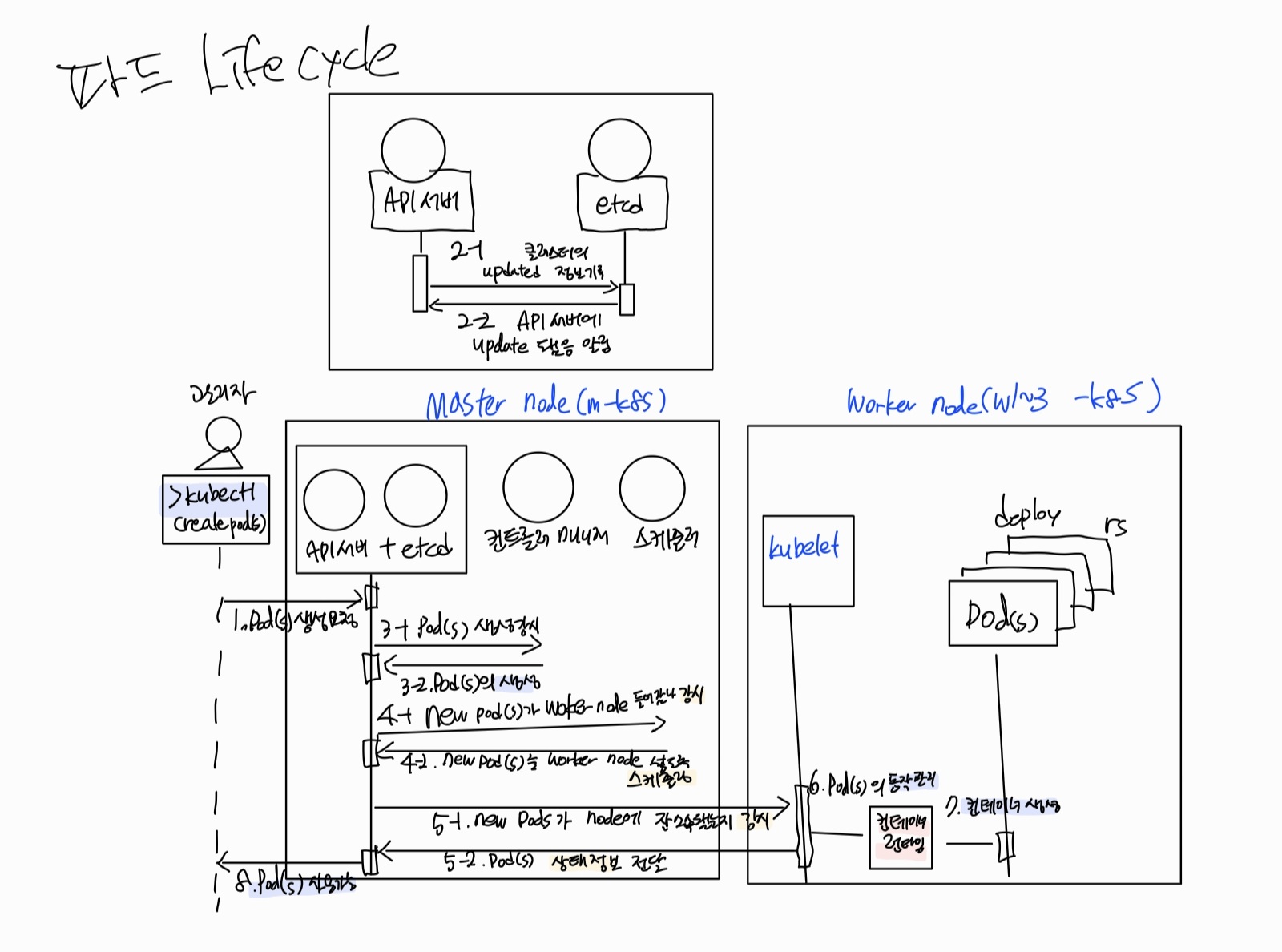
1 kubectl을 통해 API 서버에 파드 생성을 요청 ->2 (업데이트가 있을 때마다 매번) 각 요소가 상태를 업데이트할 때마다 모두 API 서버를 통해 etcd에 기록 -> 3. API 서버에 파드 생성이 요청된 것을 컨트롤러 매니저가 인지하면 -> 컨트롤러 매니저는 파드를 생성하고, 이 상태를 API 서버에 전달(어떤 워커 노드 적용할지 아직 미결정)-> 4. API 서버에 파드가 생성됐다는 정보를 스케줄러가 인지 -> 스케줄러는 파드를 어떤 워커 노드에 적용할지 결정->해당 워커 노드에 파드를 띄우도록 요청 -> 5. API 서버에 전달된 정보대로 지정한 워커 노드에 파드가 속해 있는지 스케줄러가 kubelet으로 확인 -> 6. kubelet에서 컨테이너 런타임으로 파드 생성을 요청 ->7. 파드가 생성 -> 8. 파드가 사용 가능한 상태
쿠버네티스 구성 요소의 기능 검증하기
kubectl
꼭 마스터 노드에 위치할 필요 없다
kubectl이 어디에 있더라도 API 서버의 접속 정보만 있다면 어느 곳에서든 쿠버네티스 클러스터에 명령을 내릴 수 있다!
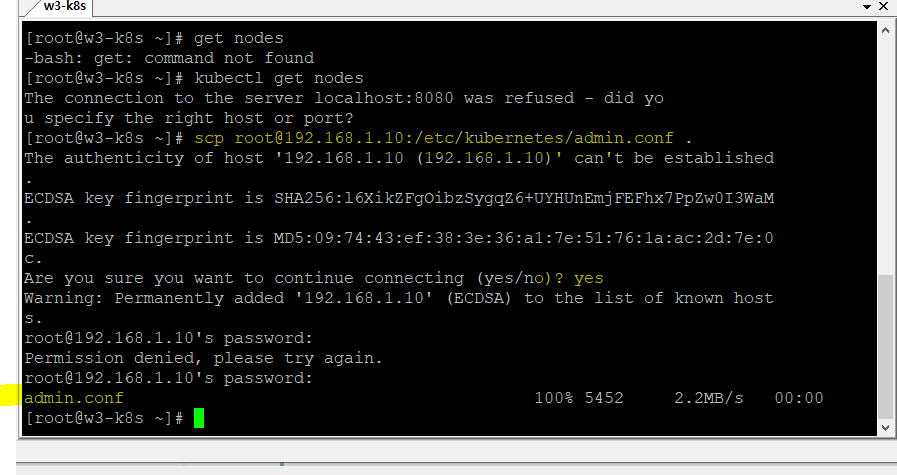
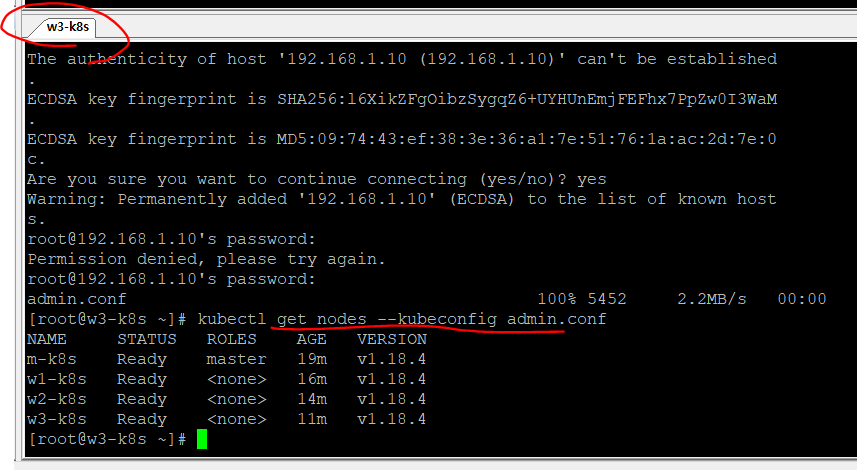
kubelet
kubelet은 쿠버네티스에서 파드의 생성과 상태 관리 및 복구 등을 담당
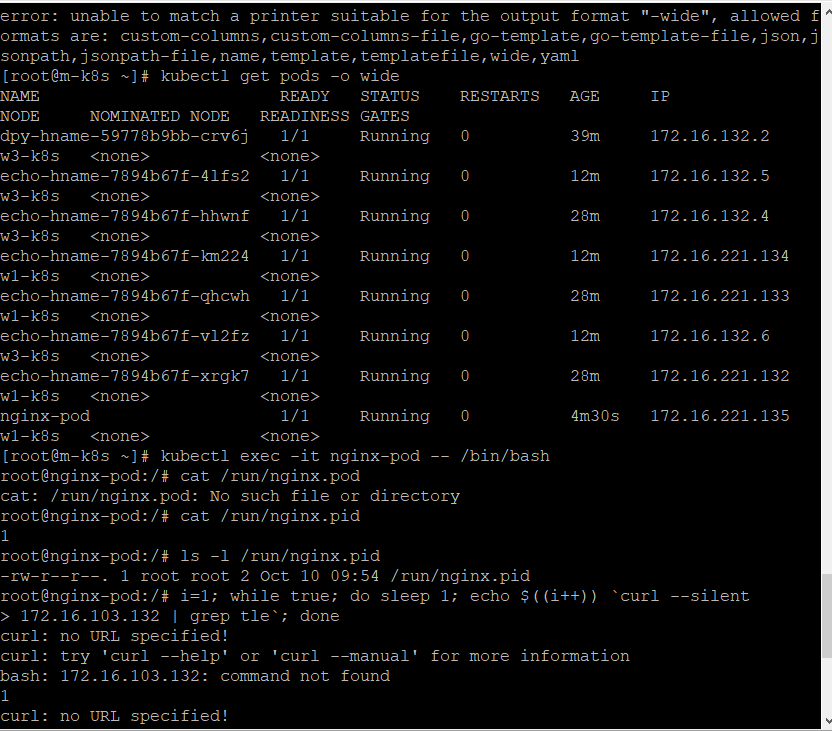
명령으로 nginx 웹 서버 파드를 배포
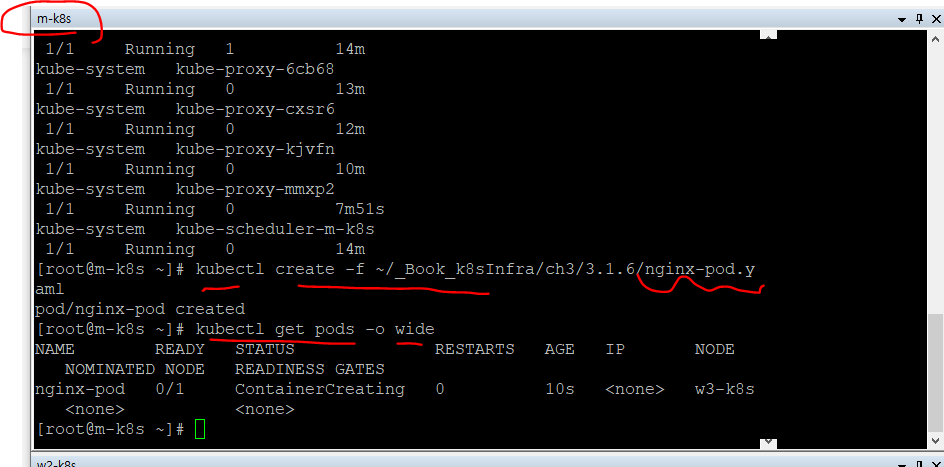
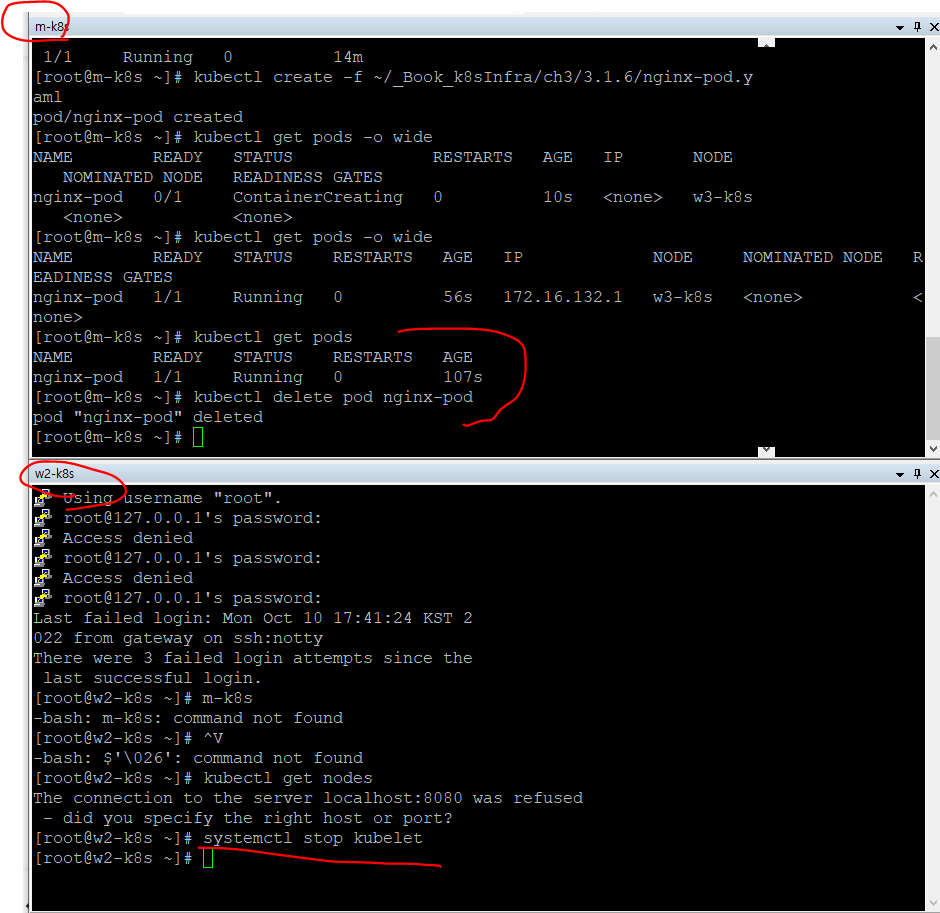
kubelet에 문제가 생기면 파드가 제대로 관리되지 않음
kube-proxy
kube-proxy는 파드의 통신을 담당
3.2 쿠버네티스 기본 사용법 배우기
파드를 생성하는 방법
kubectl run 명령을 실행하면 쉽게 파드를 생성가능
- run과 create로 파드 생성의 차이
- run으로 파드를 생성 : 단일 파드 1개만 생성되고 관리됨
- create deployment로 파드를 생성 : 디플로이먼트(Deployment)라는 관리 그룹 내에서 파드가 생성됨
오브젝트란
파드와 디플로이먼트는 스펙(spee)과 상태(status) 등의 값을 가지고 있다
이러한 값을 가지고 있는 파드와 디플로이먼트를 개별 속성을 포함해 부르는 단위를 오브젝트Object 라고 한다.
기본 오브젝트
- 파드(Pod): 쿠버네티스에서 실행되는 최소 단위 == 즉 웹 서비스를 구동하는 데 필요한 최소 단위
- 네임스페이스(Namespaces): 쿠버네티스 클러스터에서 사용되는 리소스들을 구분해 관리하는 그룹
- 볼륨(Volume): 파드가 생성될 때 파드에서 사용할 수 있는 디렉터리를 제공
(파드는 영속되는 개념이 아니라 제공되는 디렉터리도 임시로 사용) - 서비스(Service): 파드는 클러스터 내에서 유동적-> 접속 정보가 고정X -> 파드 접속을 안정적으로 유지하도록 서비스를 통해 내/외부로 연결
디플로이먼트
기본 오브젝트에서 효율적으로 작동을 위해 기능 조합 구현한 것
API 서버와 컨트롤러 매니저는 단순히 파드가 생성되는 것을 감시하는 것X, Deployment처럼 레플리카셋을 포함하는 오브젝트의 생성을 감시O
디플로이먼트는 이미지를 받아서 생성 가능
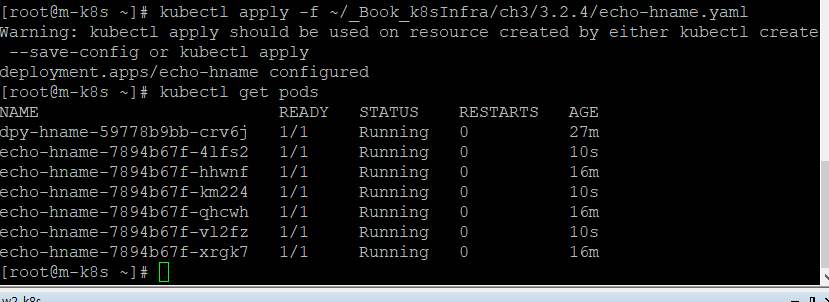
kubectl create deployment dpy-hname --image=sysnet4admin/echo-hname

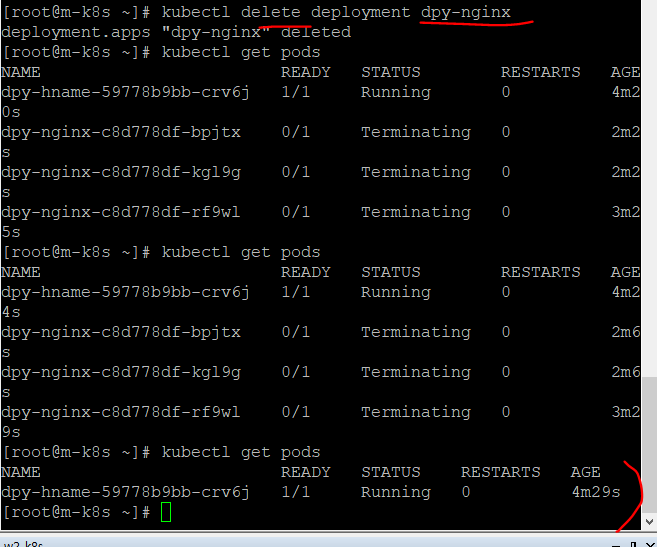
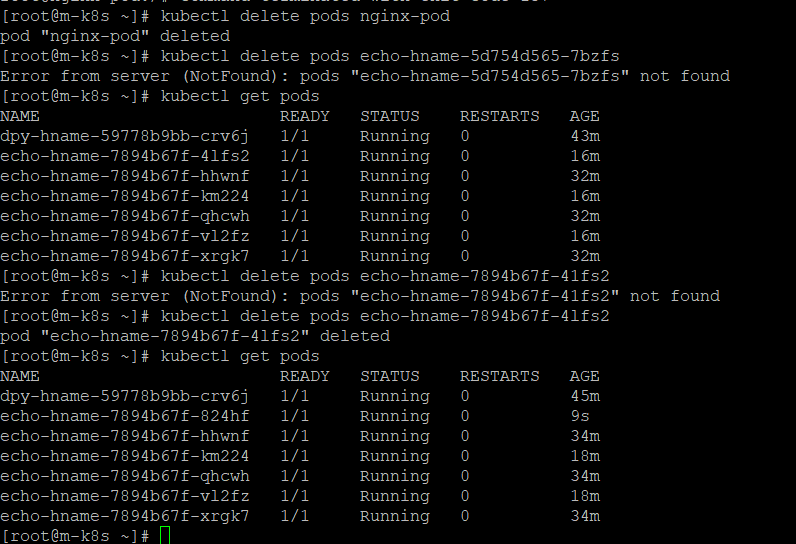
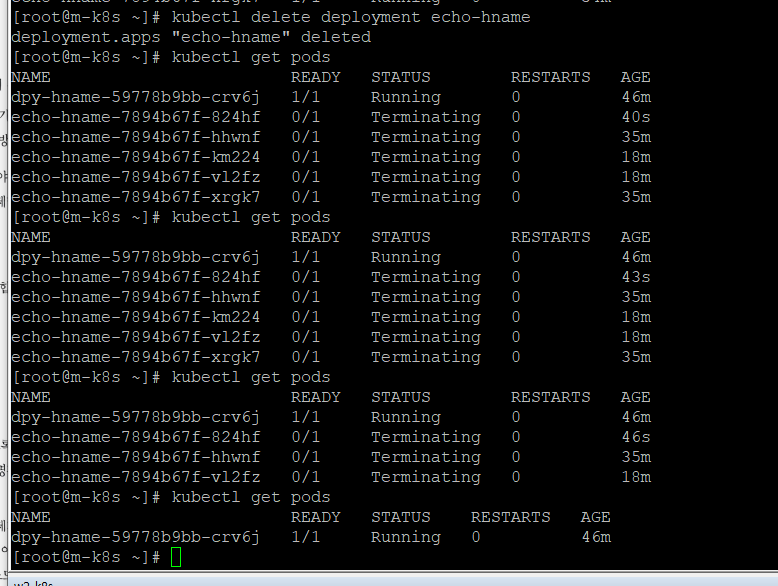
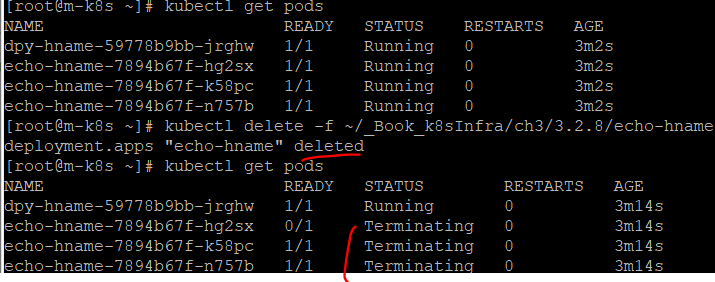
삭제는
kubectl delete deployment dpy-hname
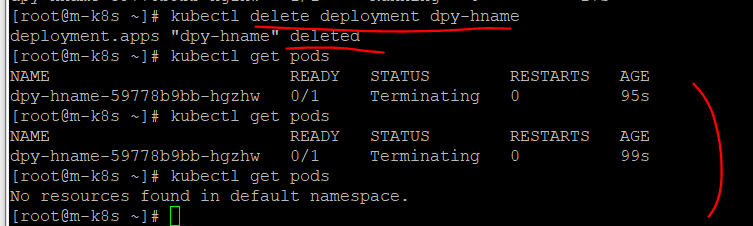
레플리카셋으로 파드 수 관리하기
많은 사용자를 대상으로 웹 서비스를 하려면 다수의 파드가 필요 -> 쿠버네티스에서는 다수의 파드를 만드는 레플리카셋 오브젝트를 제공
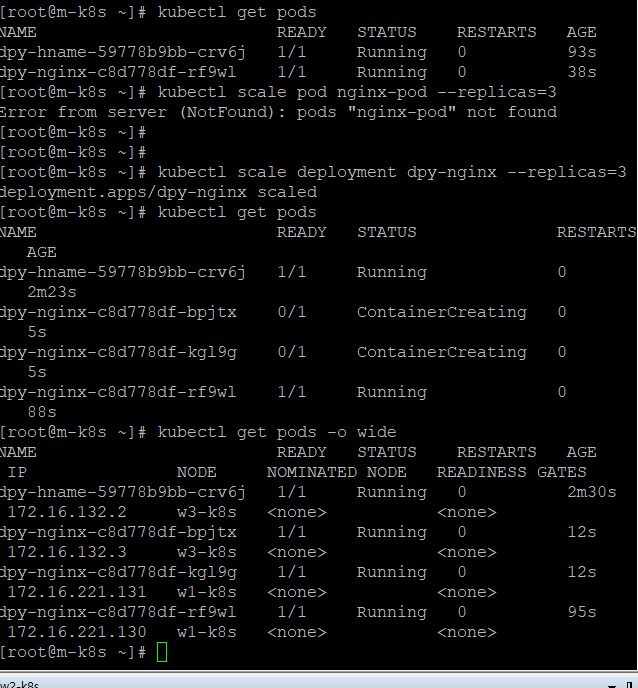
스펙을 지정해 오브젝트 생성하기
< 디플로이먼트를 생성하면서 한꺼번에 여러 개의 파드를 만들기 위해서 >
create - replicas 옵션을 사용불가 , scale은 이미 만들어진 디플로이먼트에서만 사용가능
=> 오브젝트 스펙 파일 작성해야함
설정을 적용을 위한 필요한 내용을 파일로 작성. 오브젝트 스펙은 일반적으로 YAML 문법으로 작성
사용 가능한 API 버전을 확인하려면 : kubectl api-versions 명령으로 확인 가능
쿠버네티스는 API 버전마다 포함되는 오브젝트(kind)도 다르고 요구하는 내용도 다름
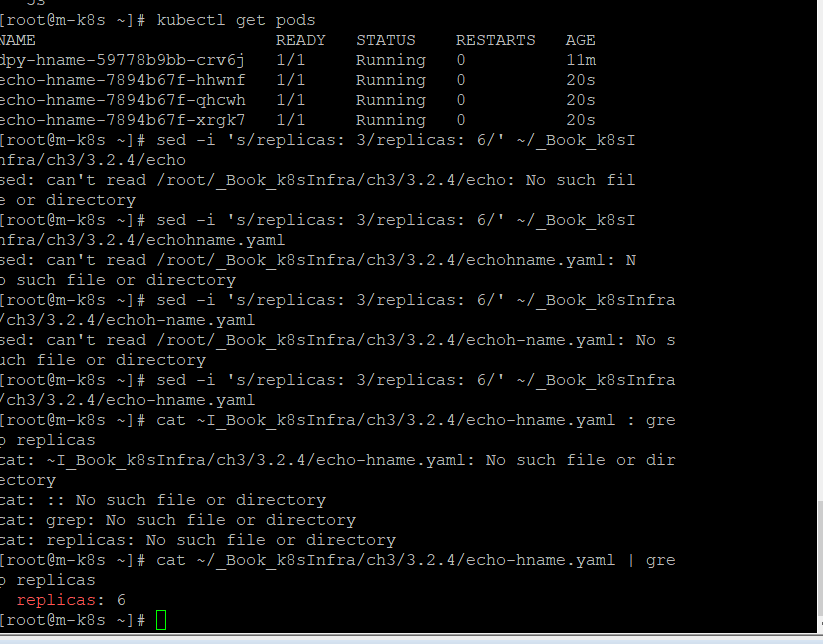

apply로 오브젝트 생성하고 관리하기
run : 단일 파드 생성
create :디플로이먼트를 생성 + 파일의 변경 사항을 바로 적용할 수 없다는 단점 존재
apply : 오브젝트 관리 +파일의 변경 사항도 쉽게 적용 가능
파드의 컨테이너 자동 복구 방법
쿠버네티스는 거의 모든 부분이 자동 복구되도록 설계되어있음 특히 파드의 자동 복구 기술 (=Self-Healing) 제대로 작동하지 않는 컨테이너를 다시 시작하거나 교체해 파드가 정상적으로 작동하게 함
파드의 동작 보증 기능
노드 자원 보호하기
노드는 쿠버네티스 스케줄러에서 파드를 할당받고 처리하는 역할
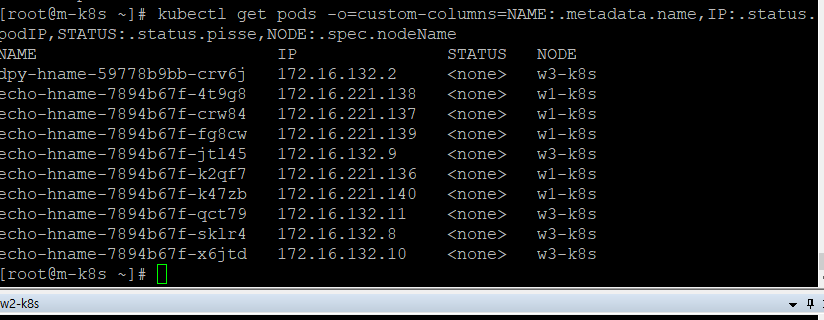
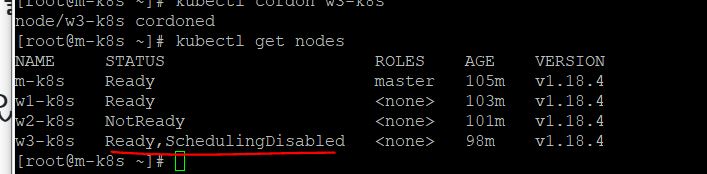
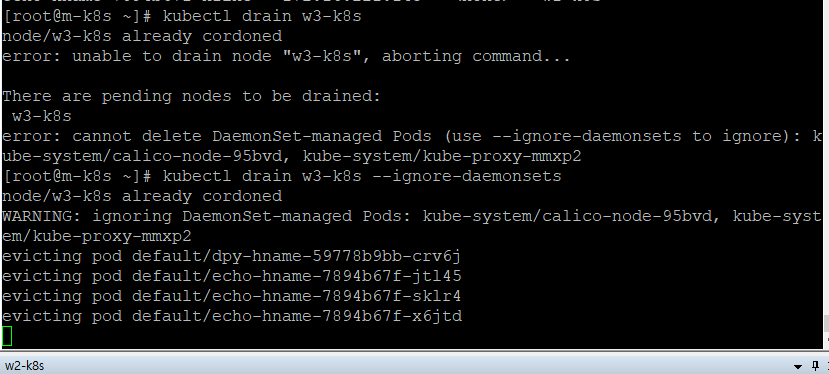
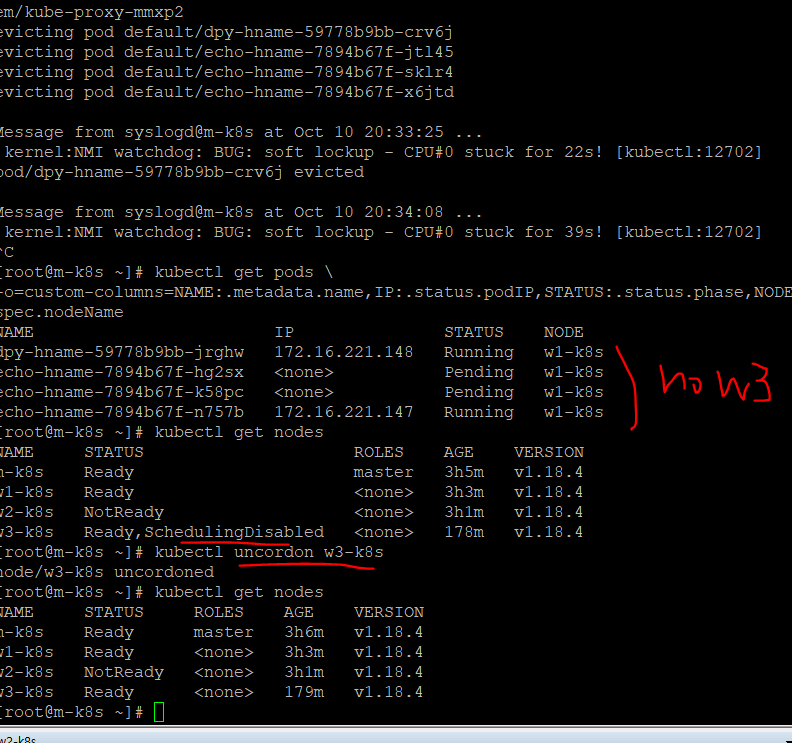
노드 유지보수하기
3.3 쿠버네티스 연결을 담당하는 서비스
3.2절에서는 쿠버네티스 클러스터 내부에서 파드를 사용
이번에는 외부 사용자가 파드를 이용하는 방법
쿠버네티스에서 서비스(service): 외부에서 쿠버네티스 클러스터에 접속하는 방법. 서비스를 '소비를 위한 도움을 제공한다'는 관점으로 바라본다면 쿠버네티스가 외부에서 쿠버네티스 클러스터에 접속하기 위한 '서비스'를 제공한다고 볼 수 있다
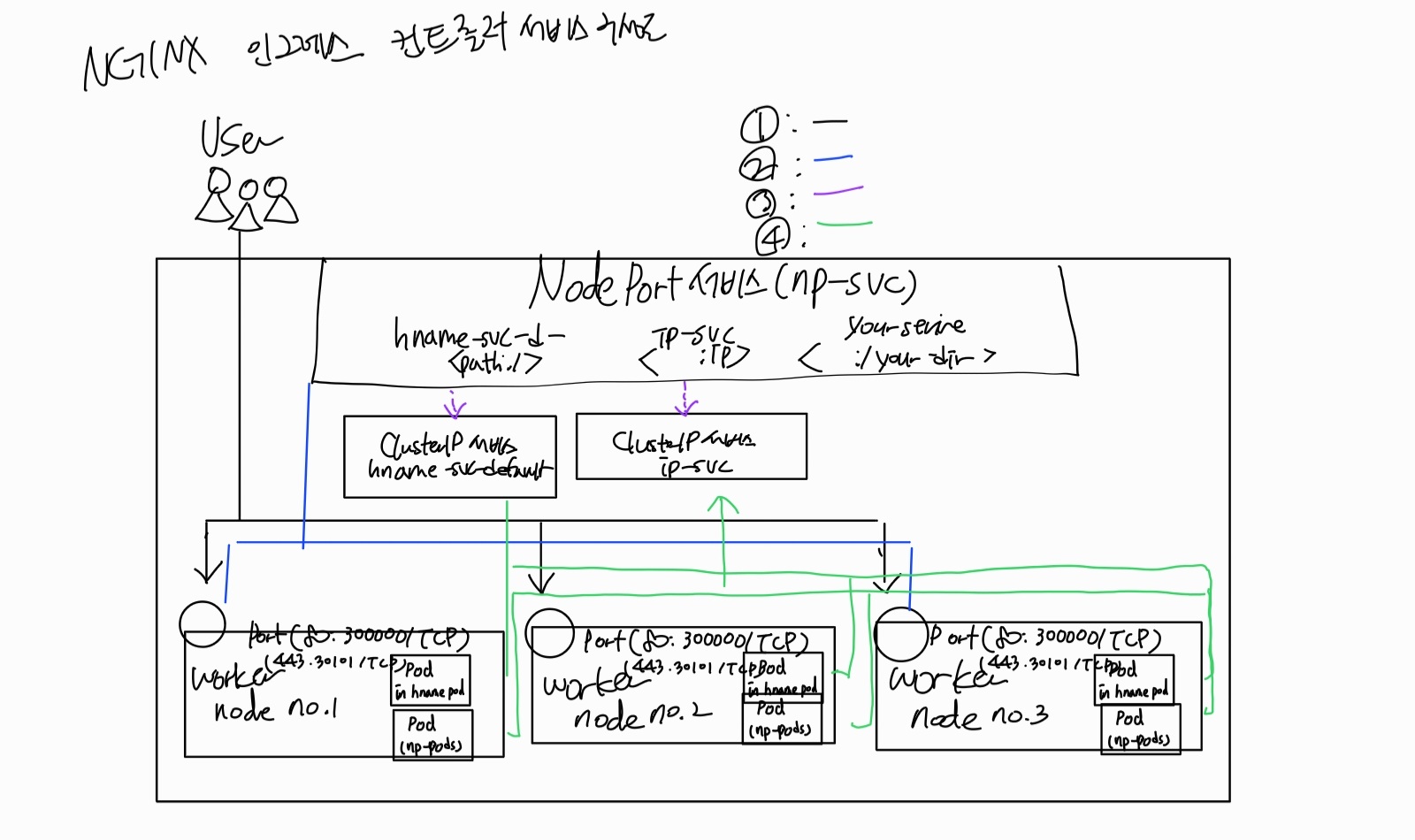
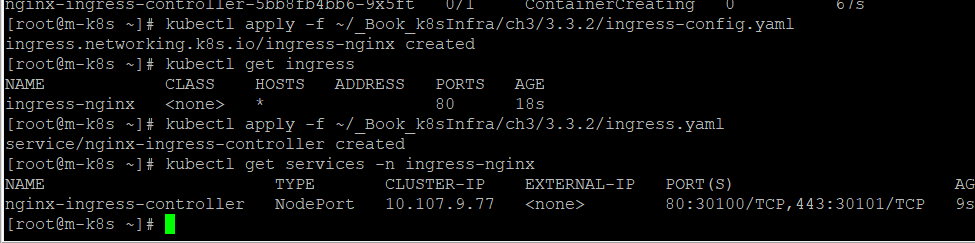
노드포트
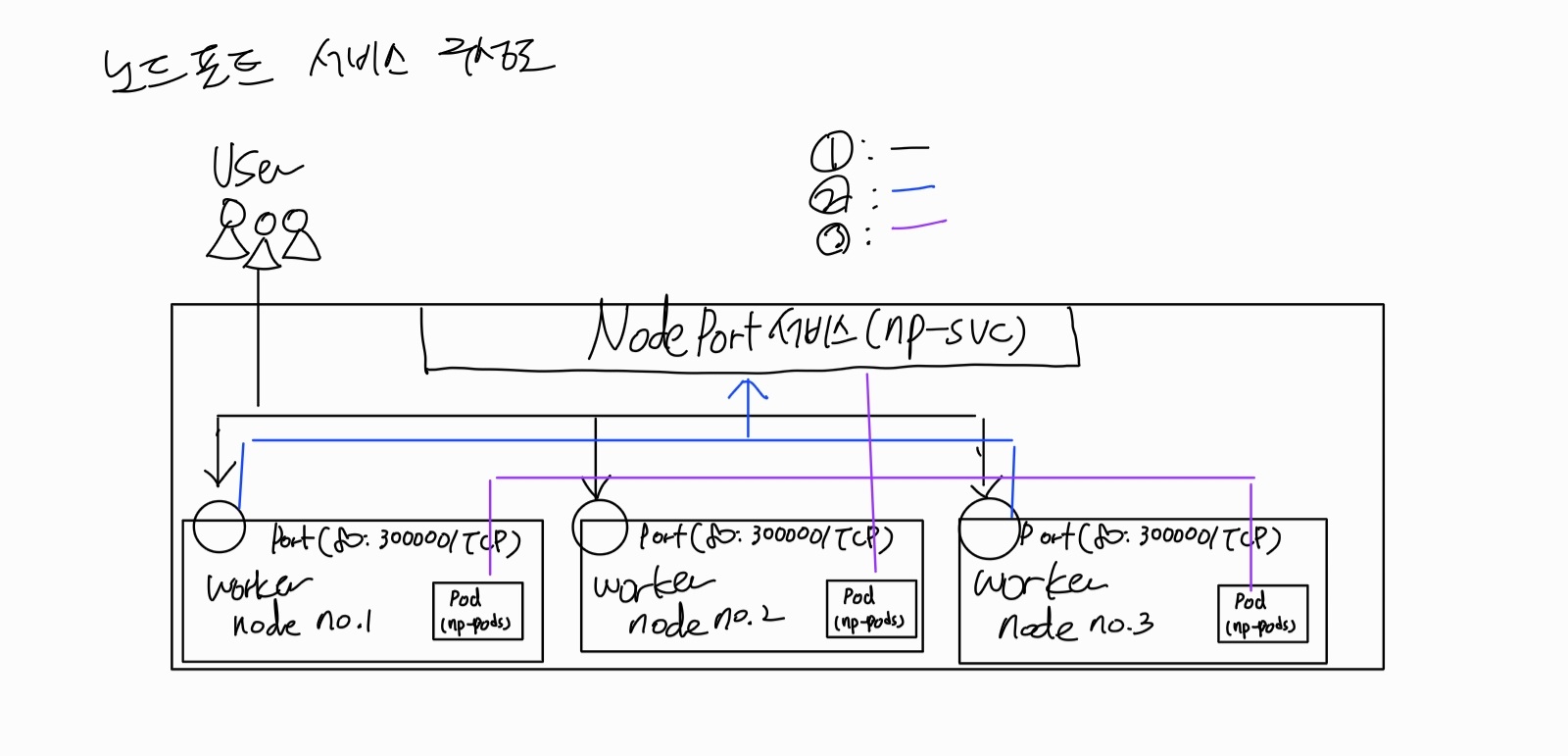
외부에서 쿠버네티스 클러스터의 내부에 접속하는 가장 쉬운 방법: 노드포트(NodePort) 서비스를 이용하는 것
노드포트 서비스를 설정-> 모든 워커 노드의 특정 포트(노드포트)를 열고 -> 오는 모든 요청을 노드포트 서비스로 전달-> 노드포트 서비스는 해당 업무를처리할 수 있는 파드로 요청을 전달
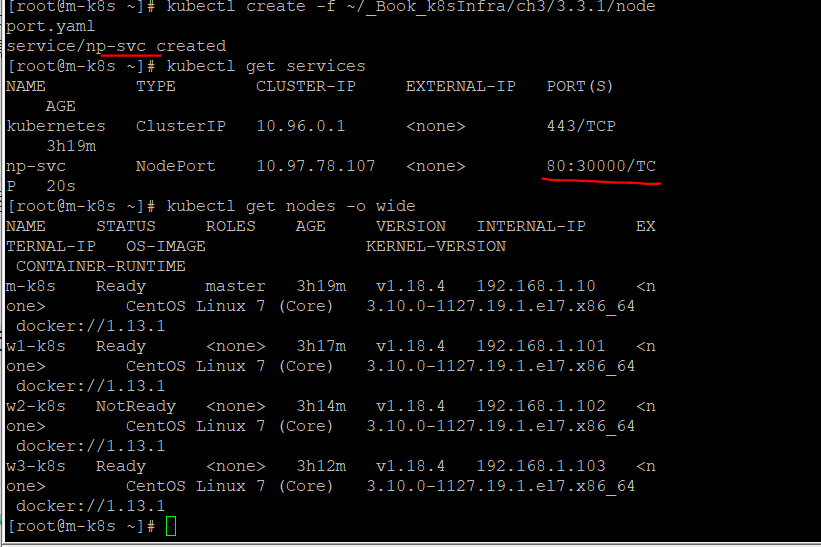
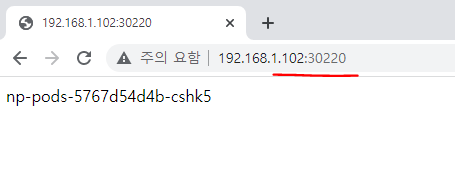
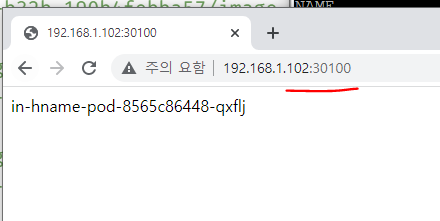
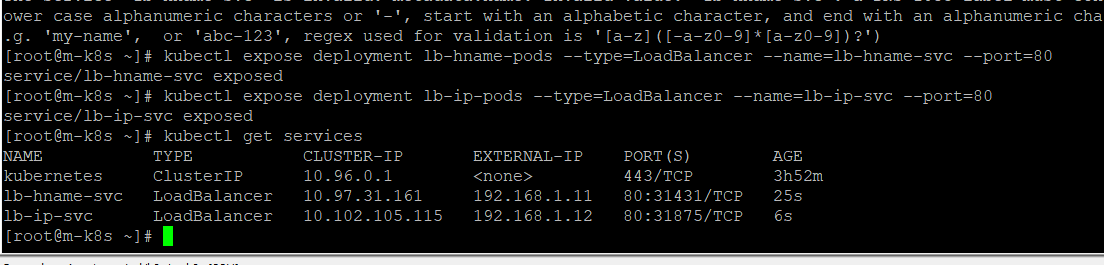
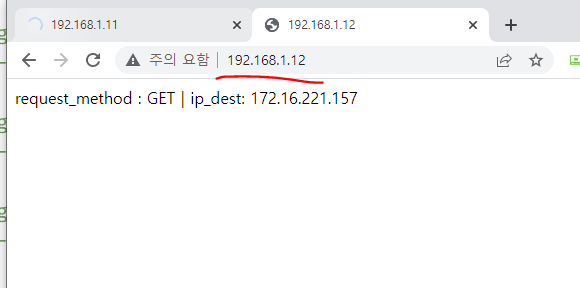
노트포드 서비스로 외부에서 접속

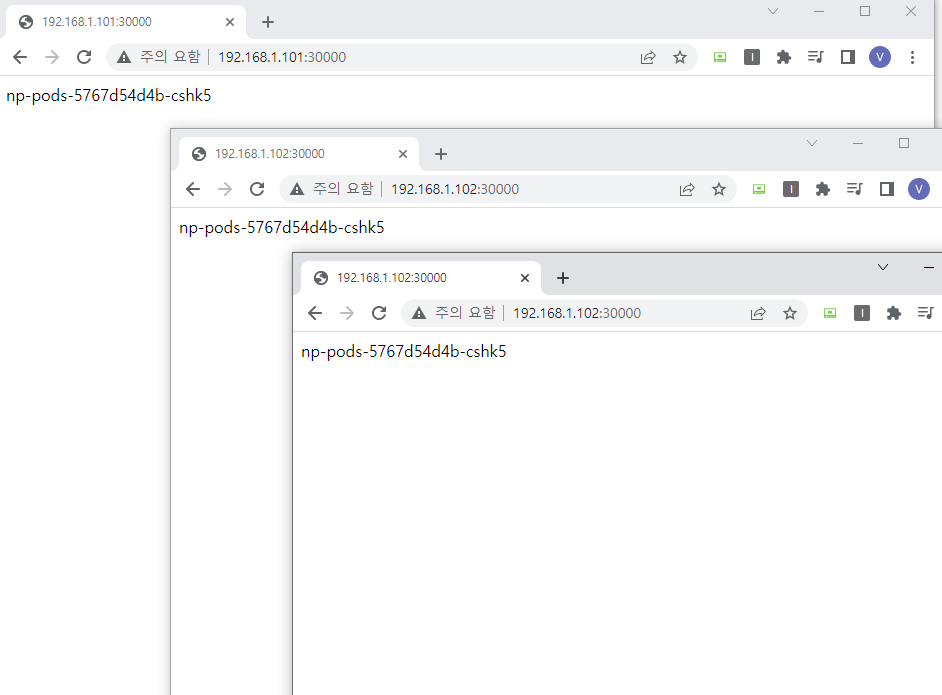
외부 웹브라우저에서 접속 확인
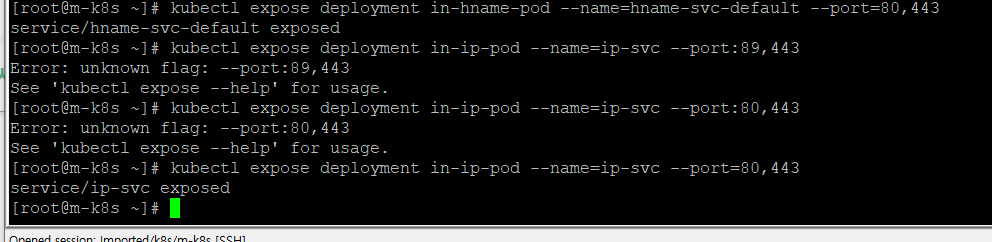
오브젝트 스펙 파일로만 노드포드를 생성하는게 아니라 expose로도 생성 가능


무작위 생성 포트번호에도 나온다
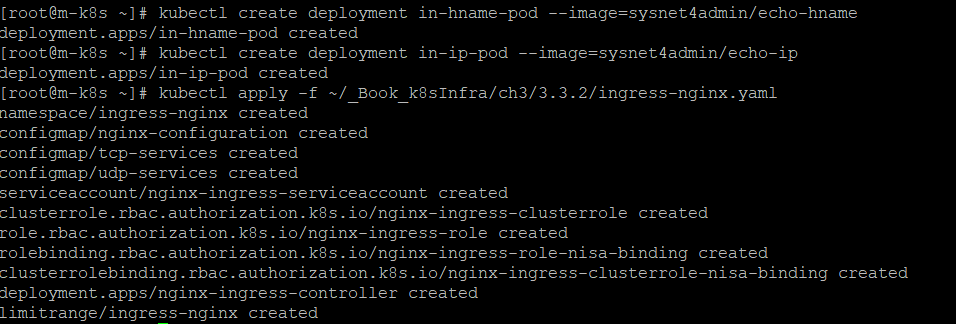
사용 목적별로 연결하는 인그레스
노드포트 서비스는 포트를 중복 사용할 수 없어서 1개의 노드포트에 1개의 디플로이먼트만 적용함
-> 여러개의 디플로이먼트 있을 때 노드포트 서비스를 그 수만큼 해야하나 ==> 인그레스 사용
- 인그레스(Ingress)
:고유한 주소를 제공+ 사용 목적에 따라 다른 응답을 제공가능 + 트래픽에 대한 L4/L7 로드밸런서와 보안 인증서를 처리하는 기능을 제공

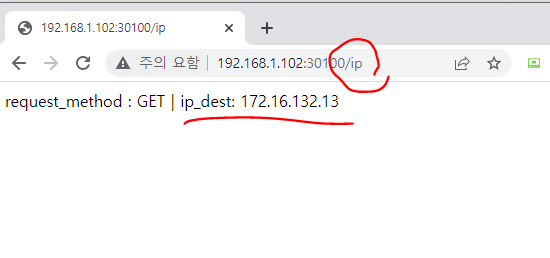
클라우드에서 쉽게 구성 가능한 로드밸런서
로드밸런서를 사용하려면 로드밸런서를 이미 구현해 둔 서비스업체의 도움을 받아 쿠버네티스 클러스터 외부에 구현해야 함
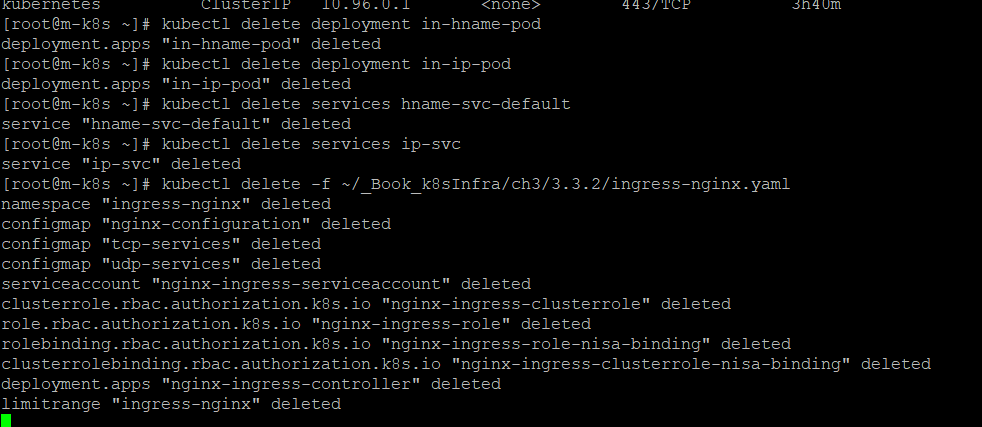
왜 안되나 봤드만
mk8s가 아니라 cloud_cmd에서 해야했었다
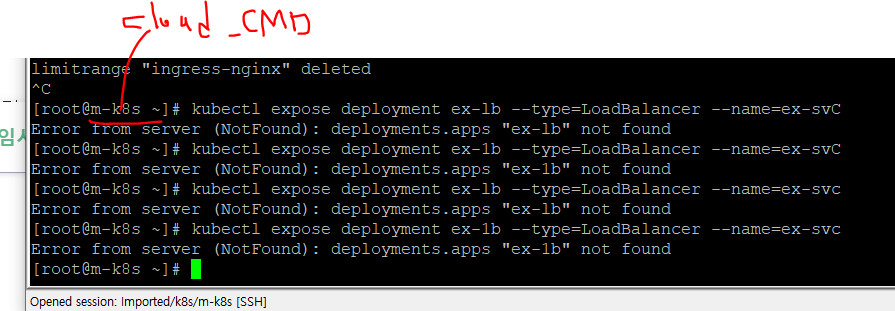
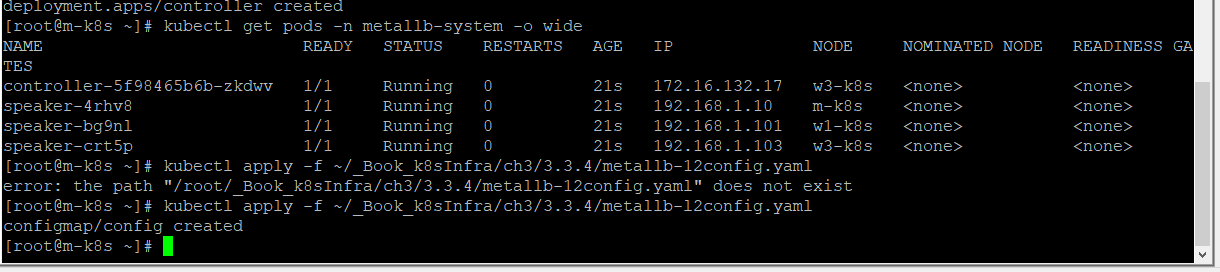
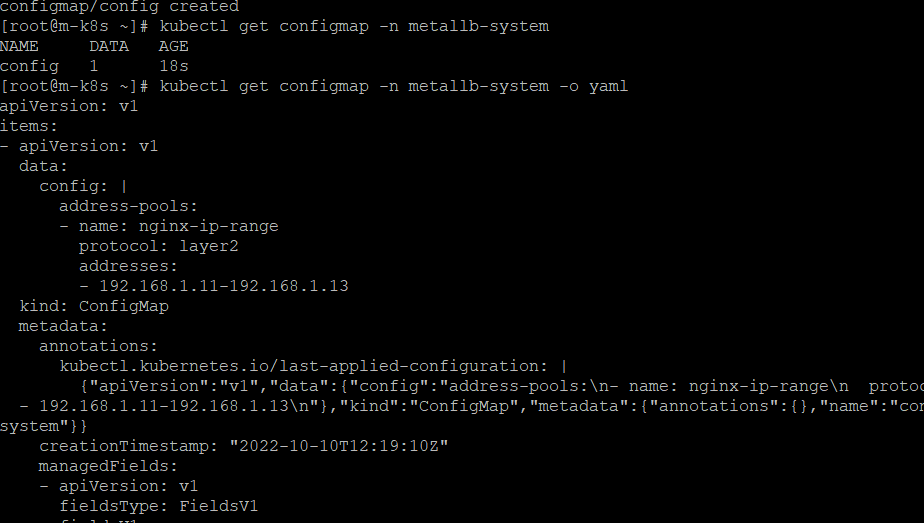
온프레미스에서 로드밸런서를 제공하는 MetalLB
MetalLB는 베어메탈(bare metal, 운영 체제가 설치되지 않은 하드웨어)로 구성된 쿠버네티스에서도 로드밸런서를 사용할 수 있게 고안된 프로젝트
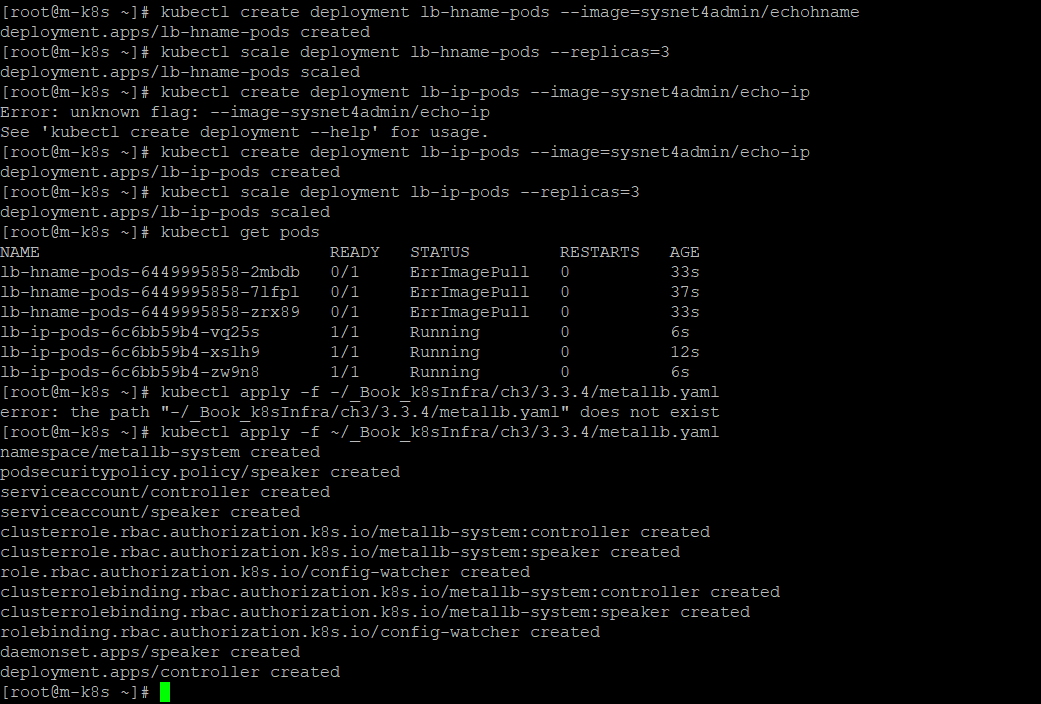
3.4 알아두면 쓸모 있는 쿠버네티스 오브젝트
이부분은 내용정리 중점으로 들어가겠음
디플로이먼트 외에도 용도에 따라 사용할 수 있는 다양한 오브젝트가 이미 정의되어있음 -> 쿠버네티스 활용하고 추가 개발하는 오브젝트에도 쉽게 적용 가능
종류와 목적, 작동 방식 중심으로 확인
데몬셋
- Daemonset
: 디플로이먼트의 replicas가 노드 수만큼 정해져 있는 형태이고, 노드 하나당 파드 한 개만을 생성 - 사용목적 : 노드의 단일 접속 지점으로 노드 외부와 통신할 때 == 파드가 1개 이상 필요x -> 노드를 관리하는 파드라면 데몬셋으로 만드는 게 가장 효율적
컨피그맵
- ConfigMap
: 설정(config)을 목적으로 사용하는 오브젝트 - 사용목적 : MetalLB처럼 프로젝트 타입으로 정해진 오브젝트가 없을때 -> 범용 설정으로 사용되는 컨피그맵을 지정)인그레스는 처럼 오브젝트가 인그레스로 지정되어 있을때는 X )
PV와 PVC
- 사용목적 : 파드에서 생성한 내용을 기록/ 보관 + 모든
파드가 동일한 설정 값을 유지 / 관리하기--> 공유된 볼륨으로부터 공통된 설정을 가지고 올 수 있도록 설계하는 목적 - 볼륨의 형태
- 임시: emptyDir
- 로컬: host Path, local
- 원격: PVC(persistentVolumeClaim), PV(PersistentVolume), cephfs, .. 등
- 특수 목적: downwardAPI, configMap,, 등
- 클라우드 : awsElasticBlockStore, azureDisk, gcePersistentDisk
쿠버네티스는 필요할 때 PVC(PersistentVolumeClaim= 지속적으로 사용 가능한 볼륨 요청)를 요청해 사용
PVC를 사용하려면--> PV( = PersistentVolume= 지속적으로 사용 가능한 볼륨)로 볼륨을 선언이 필요 .
스테이트풀셋
- 스테이트풀셋
:volumeClaimTemplates 기능을 사용해 PVC를 자동으로 생성+ 각 파드가 순서대로 생성되기 때문에 고정된 이름, 볼륨, 설정등을 가질 수 있음 ==> StatefulSet(이전 상태를 기억하는 세트)이라는 이름을 사용
파드가 만들 어지는 이름과 순서를 예측해야 할 때가 존재 (이제까지는 replicas에 선언된 만큼 무작위 생성)
-
사용목적 : 파드의 이름과 순서를 예측해야 할 때 + ex) Redis, Zookeeper, 카산드라(Cassandra), MongoDB 등의 마스터-슬레이브 구조 시스템에서 필요
-
단점 : 효율성 면에서 좋은 구조가 아니므로 요구 사항에 맞게 적절히 사용 필요
느낀점
지금 하고있는 마이크로서비스 스터디에서 젠킨스까지 다루는 내용이 있는데 쿠버네티스까지 해야하는지 아직은 의문이 든다!
물론 장점은 있는데 프로젝트의 기간내에 할 수 있을지...?
