[메모리 관리] 가상 메모리
이번에는 운영체제의 메모리 관리의 핵심인 가상메모리에 대해서 알아보겠다.
다음과 같은 상황을 상상해보자
8GB 메모리에 실행파일 하나의 크기가 1GB인 파일이 20개가 실행
1GB크기의 프로세스가 20개면 20GB인데 어떻게 8GB메모리에서 실행가능할까?
운영체제에서는 8GB의 물리메모리와 가상메모리를 분리하고 물리메모리로의 접근은 가상메모리를 통해서만 가능하게 한다.
논리주소
여기서 .c파일을 실행파일로 만드는 과정을 짧게 살펴보았다. 우선 어셈블러에 의해서 .s파일을 넣어서 나온 .o파일은 각각의 코드에 relocatable(나중에 실행파일 만들때 어차피 전부 바뀔 주소들이기 때문)한 주소를 할당 받는다. 그리고 링커에 의해서 여러개의 .o파일을 링킹 한 .out(실행파일)이 만들어진다.
실행파일에 있는 명령어(instruction)혹은 변수들은 메모리상의 물리적인 주소가 아닌 논리 주소(Logical Address)를 할당 받는다
페이지 테이블
실행파일이 메모리에 올라가서 프로세스가 되고 실제로 실행되기 위해서는 cpu가 실행파일의 논리주소를 물리주소로 접근할 수 있어야 한다. 여기서 프래임과 페이지 개념이 나온다
Frame
전체 메모리 공간을 매우 작은 단위로 나누고 그 한 단위를 프레임(Frame)이라 한다. 8GB메모리에서 프레임을 1KB단위로 나눈다면 총 100만개의 프래임이 생긴다.
Page
페이지는 프로세스를 나누는 단위이다. 가상메모리를 일정한 크기로 나눈 블록이고, 하나의 프로세스는 페이지를 단위로 나뉘며 페이지 테이블에 의해서 물리메모리인 프래임과 연결된다. 하나의 페이지 안에서는 오프셋을 통해서 특정 주소로 접근할 수 있다.
페이지 테이블은 이 페이지와 프래임을 논리적으로 연결해주는 맵이라고 보면 된다.
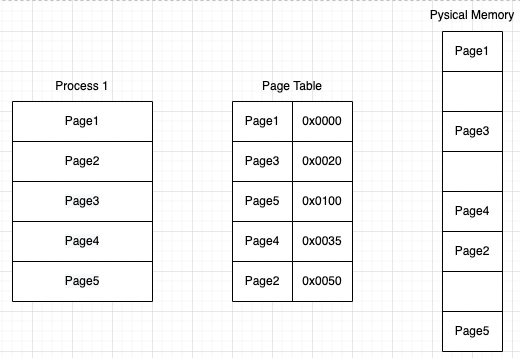
Process 1이 ADD 5 c(프로세스 상에서 page2, offset5에 위치)를 실행하는 상황을 가정해보자
- 우선 프로세스에서는 각 코드를 오프셋 만큼 더해가면서 명령어 fetch를 통해서 실행한다. 명령어
ADD 5 c를 물리메모리에서 가져오기 위해서 우선 물리메모리 주소를 알아야 한다. 물리메모리 주소를 알기 위해서는 메모리상에 존재하는 페이지 테이블에 가서 해당 페이지에 있는 물리메모리의 시작주소를 알아와야 한다. 페이지 테이블에 접근하기 위해서 PTBR(Page Table Base Register)를 통해서 페이지 테이블에 접근한다 - 페이지 테이블에 접근해서
0x0020주소를 알아왔다면 여기다가 오프셋 5만큼 더해서 물리메모리에 fetch를 해서ADD 5 c를 가져온다 ADD 5 c명령어를 가져왔는데 여기에 변수 c의 주소도 알아와야 하기 때문에 다시 메모리 테이블을 거쳐서 물리메모리에 접근해서 c의 주소를 알아온다.- 3에서
ADD 5 c를 실행하기 위해서c의 주소를 알아오는 과정 때문에 아직 명령어가 수행된게 아니다. 따라서c의 주소를 아는 상태에서ADD 5 c를 실행해서 연산을 끝마친다. - 이제
ADD 5 c명령어의 주소와 변수c의 주소는 TLB(Translation Look-aside Buffer)라는 캐시 레지스터에 저장된다.
TLB(Translation Look-aside Buffer)
cpu는 페이지 테이블에 접근하기 전에 TLB 캐시를 먼저 확인해서 실행하고자 하는 위치의 물리주소가 있는지 확인한다. 만약 캐시히트가 발생하지 않으면 PTBR을 통해 메모리상에 있는 페이지 테이블에 접근해서 물리주소를 알아 온 후에 다시 메모리로 접근해야하기 때문에 2번의 메모리 접근이 발생한다.
하지만 TLB 캐시히트가 발생하면 굳이 시스템 bus를 타고 물리메모리에 페이지 테이블을 읽으러 갈 필요가 없기 때문에 더 효율적이다
하지만 이런 페이지 테이블은 문제가 있다. 실제로 물리메모리의 프래임 갯수는 수백만개가 될 정도로 매우 많고, 이 많은 프래임을 전부 페이지 테이블에서 1 대 1 맵을 해주고 있는것은 페이지 테이블의 항목 또한 수백만개가 될 수 있다는 것이다. 물리메모리의 사용을 줄이기 위해서 페이지 테이블을 사용하는데, 물리메모리 사용을 추적하기 위해서 많은 양의 물리메모리를 소비하는 역설이 발생한다.
역페이지 테이블
역페이지 테이블은 프로세스마다 일정 크기의 프래임 갯수를 가지고, 실제로 메모리에 올라와있는 페이지만 페이지 테이블에 매핑해준다. 실제로 물리프레임에 대응되는 항목만 테이블에 저장하기 때문에 메모리에서 훨씬 작은 공간을 점유한다.
이제 페이지 테이블은 프로세스 아이디(PID)와 페이지 번호를 키(key)로 하고 물리메모리 주소를 value로 하는 맵형태로 저장된다.
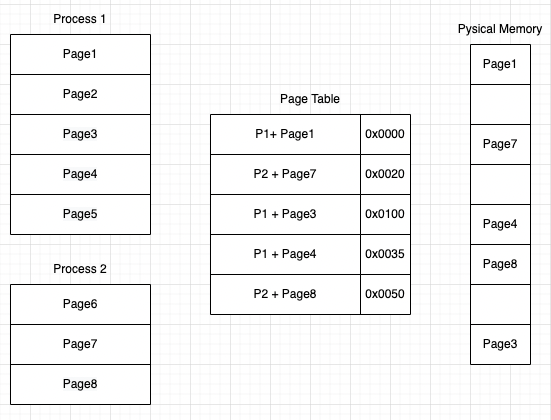
이제 위와같은 형태로 페이지 테이블이 구성된다.
가상메모리
위와같이 역페이지 테이블 형태를 가지고, 각 프로세스마다 일정 수의 물리메모리(프래임)만 할당하는 형태의 메모리 구조를 가상메모리(virtual memory)라고 한다.
위의 그림에서 프로세스 1의 경우 Page1, Page3, Page4만 물리메모리에 올라가있는 상태인데 만약 Page2에 cpu가 접근한다면 어떻게 될까?

페이지 테이블에 페이지 하나마다 더티체킹(dirty checking)비트가 하나 더 붙어서 해당 패이지가 실제로 메모리에 올라가있는지 확인한다. valid면 합법적으로 접근이 가능하고, invalid면 물리메모리에 프래임이 없기 때문에 요구패이징(demand paging)을 해야한다.
요구패이징이 발생하면 해당 프로그램이 저장되어있는 하드웨어 저장장치까지 io작업이 수행되어야 하기 때문에 해당 프로세스의 상태는 wait으로 바뀌고 wait queue로 들어간다.
페이지 폴트
프로세스1(P1)에서 Page2에 에 접근하는것을 생각해보자. Page2은 현재 메모리 테이블에서 invalid하고, 물리메모리 자체도 100퍼센트 사용중인 상태이다.
Page2를 물리메모리에 올리기 위해서는 사용중인 프래임 하나를 swap out 해야한다. 여기서 어떤 기준으로 swap out하는 프래임을 정할지가 중요한데 일단 FIFO형식으로 정한다고 가정하고 Page1이 victim으로 선택되어 swap out당하면서 더티비트는 invalid로 바뀐다. 이제 새로운 Page2를 하드웨어 저장장치에서 io를 통해 읽어오고, 해당 프로세스는 wait queue에 들어가는 과정을 통해서 Page2가 물리메모리에 올라고, 더티비트는 valid로 바뀔것이다.
페이지 교체 알고리즘
페이지 폴트가 발생했을 때 사용중인 프래임 하나를 victim으로 지정해서 물리메모리에서 제거해야하는데 victim을 고르는 기준은 크게 3가지가 있다.
FIFO
FIFO는 제일간단하게 구현가능한데, 말그대로 제일 일찍 들어온 순서로 victim을 정하는거다. 일반적으로 프레임의 공간이 커지면 페이지 폴트 횟수도 줄어드는 정비례관계가 성립하는데, FIFO의 경우는 물리메모리가 커져도 페이지폴트 횟수가 줄어드는 Belady 의 anormaly 가 발생한다.
OPT
OPT(optimal)은 이론상 가장 최적화된 페이지 폴트 알고리즘이다. 앞으로 실행될 페이지 중에서 가장 나중에 실행될 페이지를 1쉰위로 해서 page out을 시켜주는 것이다. 하지만 이게 가능하려면 페이지 폴트가 일어나는 시점에서 미래에 실행될 모든 페이지를 다 알고있어야하기 때문에 이론적으로 불가능하다.
그래서 OPT의 경우 최적의 알고리즘이라는 기준으로 다른 알고리즘이 OPT에 얼마나 근접하는지를 비교하는 척도가 된다.(OPT 98% 근접 등)
LRU
LRU 는 least recently used 한 페이지부터 page out 시키는 알고리즘이다. OPT가 불가능하기 때문에 괴거의 페이지 사용내역들을 확인해서 "가장 과거에 사용된 페이지는 미래에도 사용이 안될 가능성이 높기 때문에 페이지폴트가 나면 victim으로 선정한다"라는 논리의 알고리즘이다.
프로그램이 돌때 locality 때문에 한번사용된거는 자꾸 사용될확률이 높다. 반대로 위치상 떨어져있는것은 다시 사용안될 확률이 높기때문에 이런 판단이 가능하다.
LRU는 페이지에 시스템 clock을 기록할수있는 비트만큼의 공간을 더 확보해서 시스템 clock을 기록해주는거다. 결국은 system clock 값이제일 작은걸 victim으로 해주면 된다.
