[Android] Coroutine 이해하기 (4) : Channel & Flow

코루틴끼리 서로 값을 주고받을 수 있다.
Producer & Consumer
-
작업을 생성해내는 주체와 (producer)가 큐에 작업을 쌓아두면 작업을 처리하는 주체 (consumer)가 작업을 처리하는 구조
-
producer와 consumer가 서로를 신경쓰지 않아도 된다.
Channel
- Producer & Consumer 구조에서는 작업이 큐에 꽉 찼는데 producer가 큐에 put하려고 하거나 Consumer가 큐가 비었는데 작업을 처리하려고 하면 큐를 Block하는 BlockingQueue를 사용
- channel도 비슷하게 동작하는데 Queue를 block하는게 아니라 suspend한다는 차이가 있다.
- 한 Channel에 대해 여러 코루틴이 value를 send하고 receive할 수 있다.
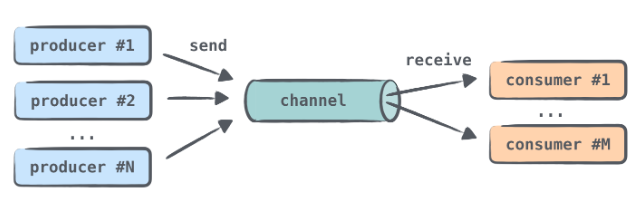
Channel의 종류
-
UNLIMITED

- 채널의 크기가 무한한다.
- out of memory가 발생하기 전까지 절대 suspend하지 않는다. -
BUFFERED

- 채널의 사이즈가 정해져 있다.
- 채널가 다 찼는데 send하려고 하거나 비어있는데 receive하려고 하면 suspend된다. -
RENDEZVOU (랑데뷰)

- 버퍼가 없는 채널
- 버퍼가 없기 때문에 하나의 값이 send되면 receive될 때까지 suspend된다.
- 기본값
- CONFLATED

- conflated (합쳐진) 이름처럼 기존의 값이 계속 overwrite된다.
- send 메서드는 절대 suspend 되지 않는다.Channel의 한계
- 버퍼는 FIFO 구조이므로 만약 두개의 코루틴이 서로 번갈아가면서 Channel에 send하도록 구현한다면 Fair하게 번갈아가며 값이 출력되어야 한다.
- 하지만 코루틴의 스케줄링에 따라서 값이 들어가는 순서가 번갈아서 들어가지 않아 Channel이 unfair하게 작동하는 것처럼 보일 수 있다.
- 버퍼의 크기를 잘 설정해야 한다.
Flow
- emit으로 값을 생성하고 collect로 값을 소비한다.
- flow { } builder로 생성하거나 컬렉션 확장함수인 .asFlow()로 생성할 수 있다.
(1..3).asFlow().collect { value -> println(value) }Sequence
-
지연 연산을 제공
-
자바의 stream과 동일하다
-
컬렉션의 함수형 API가 연속으로 호출되었을 때 중간과정의 전체 컬렉션을 계속 생성하면 메모리를 많이 써야 한다.
-
sequence는 값을 요구하는 최종 연산이 호출되기 전까지는 메서드를 실행하지 않다가 최종 연산이 실행되면 컬렉션이 요소 하나씩 모든 함수형 API들을 실행해서 값을 만든다.
-
하지만 값이 오랜시간 걸쳐서 생성된다면 비동기적으로 실행해야 함
-
flow는 비동기적 sequence인 것
Cold vs Hot
- cold
- collect해서 consumer가 생기기 전까지는 Produce하지 않는다.- 시퀀스가 최종 연산이 호출되기 전까지는 연산을 안 하는 것과 비슷
- hot
- consumer가 존재하든 안하든 값을 produce한다.- Channel이 hot stream
flowOn
- Flow도 코루틴이기 때문에 context가 있고 Flow가 동작하는 Dispatcher가 존재
- 만약 produce하는 Dispather와 consume하는 Dispatcher가 다르다면?
- ex. Default 스레드에서 열심히 계산해서 emit하고 Main 스레드가 이를 consume해서 UI를 업데이트하고 싶을 때 - flowOn이 upstream의 context를 바꿔줌
fun simple(): Flow<Int> = flow {
// The WRONG way to change context for CPU-consuming code in flow builder
kotlinx.coroutines.withContext(Dispatchers.Default) {
for (i in 1..3) {
Thread.sleep(100) // pretend we are computing it in CPU-consuming way
emit(i) // emit next value
}
}
}
fun main() = runBlocking<Unit> {
simple().collect { value -> println(value) }
} - 이렇게 실행하면 Flow invariant is violated 에러가 발생한다.
fun simple(): Flow<Int> = flow {
for (i in 1..3) {
Thread.sleep(100) // pretend we are computing it in CPU-consuming way
log("Emitting $i")
emit(i) // emit next value
}
}.flowOn(Dispatchers.Default) // RIGHT way to change context for CPU-consuming code in flow builder
fun main() = runBlocking<Unit> {
simple().collect { value ->
log("Collected $value")
}
} - flowOn으로 context를 변경해줌으로써 에러가 나지 않게 된다.
Flow Operators
소비하는 속도 (collect) 보다 생산하는 속도 (emit)이 더 빠른 경우에는 어떻게 대처해야 할까?
- buffering
- flow.buffer()로 값들을 모아두었다가 하나씩 collect한다. - conflation
- Channel의 Conflated처럼 값이 계속 덮어씌워진다. 값을 collect하기 전에 새로운 값이 emit되면 collect되지 못한 값은 없어진다. - collectLatest
- XXLatest operator들은 emit이 되면 기존 collect를 취소하고 다시 시작해서 바로바로 값을 collect한다.
여러 flow들이 emit하는 값들을 같이 사용하고 싶을 때는? (composing)
- zip
val nums = (1..3).asFlow() // numbers 1..3
val strs = flowOf("one", "two", "three") // strings
nums.zip(strs) { a, b -> "$a -> $b" } // compose a single string
.collect { println(it) } // collect and print
// results
1 -> one
2 -> two
3 -> three- combine
val nums = (1..3).asFlow().onEach { delay(300) } // numbers 1..3 every 300 ms
val strs = flowOf("one", "two", "three").onEach { delay(400) } // strings every 400 ms
val startTime = System.currentTimeMillis() // remember the start time
nums.combine(strs) { a, b -> "$a -> $b" } // compose a single string with "combine"
.collect { value -> // collect and print
println("$value at ${System.currentTimeMillis() - startTime} ms from start")
}
//results
1 -> one at 452 ms from start
2 -> one at 651 ms from start
2 -> two at 854 ms from start
3 -> two at 952 ms from start
3 -> three at 1256 ms from start- 두 flow가 다 값을 emit한 순간부터 둘 중 하나가 emit할 때마다 collect
Flow 안에 Flow가 있는 경우는? (flattening)
- flatMapConcat
- 두 flow의 값들을 1:1 대응 - flatMapMerge
- flatMapLatest
- XXLatest니까 emit될 때마다 새로 collect한다.
val startTime = System.currentTimeMillis() // remember the start time
(1..3).asFlow().onEach { delay(100) } // a number every 100 ms
.flatMapLatest { requestFlow(it) }
.collect { value -> // collect and print
println("$value at ${System.currentTimeMillis() - startTime} ms from start")
}
//results
1: First at 142 ms from start
2: First at 322 ms from start
3: First at 425 ms from start
3: Second at 931 ms from start
- 계속 새로 collect하다보니 Second가 호출이 못 되다가 마지막은 새로 collect를 하지 않으니 Second까지 호출이 되었다.
Flow Exception
- try ~ catch 문으로 에러를 잡아도 되고
- transparent catch를 통해 에러를 잡을 수도 있다
fun main() = runBlocking<Unit> {
simple()
.catch { e -> println("Caught $e") } // does not catch downstream exceptions
.collect { value ->
check(value <= 1) { "Collected $value" }
println(value)
}
} Flow Completion
-
flow collection이 종료되었을 때의 작업을 설정할 수도 있다.
-
명령형 (imperative)
fun simple(): Flow<Int> = (1..3).asFlow()
fun main() = runBlocking<Unit> {
try {
simple().collect { value -> println(value) }
} finally {
println("Done")
}
}
//results
1
2
3
Done- 선언형 (declarative)
simple()
.onCompletion { println("Done") }
.collect { value -> println(value) }성공적으로 종료된 건지 예외상황으로 종료된 건지 확인할 때 좋다.
- onCompletion이 받는 인자가 Null이면 성공적으로 끝난 것이고 Null이 아니면 예외로 끝난 것이다.
SharedFlow, StateFlow
-
둘 다 hot stream이다.
-
하나의 값을 여러 collector들에게 전해줄 수 있음
- 여러 collector에게 동일한 값을 주기 위해 동일한 flow를 여러개 만들지 않아도 된다. -
SharedFlow
- SharedFlow는 StateFlow의 유연한 구성 일반화- collect하는 모든 소비자에게 값을 보냄
- 마지막 emit된 값을 새로운 collector가 생길 때마다 replay함
- collect하는 모든 소비자에게 값을 보냄
val locations: Flow<Location> =
locationDataSource.locationsSource.shareIn(externalScope, WhileSubscribed())WhileSubscribed()는 collector가 더이상 없을 때는 upstream을 cancel하는 옵션이다.
하지만, WhileSubscribed(5000)으로 collector가 없어도 5초동안은 upstream이 살아있도록 하는 게 좋은데 그 이유는 configuration change 같이 잠깐 뷰만 다시 그리는 경우에 upstream이 취소되었다가 다시 생성하는 것보다는 이전 것을 계속 사용하는 게 낫기 때문이다.
- replay 옵션
- last emit된 값 몇 개를 저장하고 있다가 새로운 collector가 생길 때마다 저장한 값들을 다시 emit해준다.- stateFlow
- 현재 state를 공유할 수 있는 SharedFlow- last emit한 값을 cache하고 새로운 collector가 생길 때마다 replay 할 수 있다.
- 항상 값이 있어야 하는 UI state를 저장할 때 유용
- LiveData랑 다른 점
- LiveData와 달리 StateFlow는 초기값이 필요 (cache해야 하는 값이 있어야 한다)
- LiveData는 뷰가 stop 되면 자동으로 종료하지만, StateFlow는 repeatOnLifecycle를 통해서 멈춰줘야 함
- LiveData와 달리 StateFlow는 초기값이 필요 (cache해야 하는 값이 있어야 한다)
- last emit한 값을 cache하고 새로운 collector가 생길 때마다 replay 할 수 있다.
- flow에 input값이 있다면?
- sharedFlow/stateFlow는 기존 flow를 재사용하지 못한다. 매번 새로운 flow를 생성해 줘야 한다.
Channel vs Flow
-
Channel은 Consumer가 take를 하든 말든 난 일단 큐에 넣어놓겠다. (hot)
-
Flow는 Consumer가 take를 할 때까지 기다렸다가 데이터를 생산하겠다. (cold)
Flow는 연속된 값을 비동기적으로 생성하고, 특히 비동기 호출이나 타임아웃과 같은 연산을 조합하고 처리하기 용이합니다.
Channel은 두 코루틴 간에 안전하게 데이터를 교환하는 데 사용되며, 채널을 통해 양방향 통신이 가능합니다.
참고
https://kotlinlang.org/docs/coroutines-and-channels.html#channels
https://kotlinlang.org/docs/flow.html
https://medium.com/androiddevelopers/things-to-know-about-flows-sharein-and-statein-operators-20e6ccb2bc74
