👩🏻💻 nodeJS, express, mysql, sequelize 환경에서 개발하고 있습니다.
로직 이해
영화 관련 서비스를 위한 프로젝트 진행 중, 영화 검색 기능을 위해 opne API를 써야했다. open API 호출을 줄이기 위해 우선 DB에서 영화를 찾고 데이터가 없으면 open API에서 찾은 후 DB에 검색 데이터를 저장한다. 그 다음 DB에서 값을 찾아 리스폰스로 보내준다.
이렇게 되면 DB에 한 번 들어간 영화는 open API를 추가적으로 호출하지 않고도 데이터를 찾을 수 있다.
open API의 선택
처음에 Kobis -영화진흥위원회를 이용했지만 영화 검색할 때 여러모로 정확도가 떨어지는 느낌을 많이 받았다. 예를들면 findAll을 써서 title을 오름차순으로 했을 땐 A는 찾아지지만 B는 찾아지지 않고, 내림차순으로 바꾸면 B는 찾아지지만 A는 찾아지지 않는 등.. 프론트에서 처리를하는 게 아니고 서버에서 API를 호출하여 직접 DB에 데이터를 추가한 후 다시 DB에서 찾기 때문에, 애초에 정확한 데이터를 DB에 저장해야 했다.
다른 openAPI를 찾다가 KMDb - 한국영화데이터베이스라는 사이트를 찾게 됐다. 인증키 신청을 하고 1~2일 지나니까 승인처리가 됐다.
제공하는 요청인자도 많았고 무엇보다 장르 구분이 확실했다. 일례로, 코비스 데이터는 누가봐도 성인물인데(청불 영화를 말하는 게 아니다) 장르가 로맨스나 멜로인 것도 있었다. 때문에 성인물 영화를 완벽하게 걸러주지 못하고 검색창에 노골적인 제목이 그대로 노출되곤 했다.
KMDb open api 사용법
const { title } = req.params // 본인은 엔드포인트를 params로 설정했다
const url = `http://api.koreafilm.or.kr/openapi-data2/wisenut/search_api/search_json2.jsp?collection=kmdb_new2&detail=N&listCount=50&ServiceKey=${process.env.KMDB_API_KEY}&title=${title}`
// 여기서 각자 필요한 요청 인자를 &로 이어서 추가하면 된다
const urlData = await axios.get(url)
console.log(urlData)우선 코비스를 썼을 때 잘 나오지 않았던 '어스'나 '반지'(반지의 제왕) 등을 검색해보았다. 반지의 제왕은 그나마 4~5번째로 나오긴 했지만 어스는 찾지 못했다. 해결을 위해 요청 인자 중 하나인 listCount를 넉넉히 50으로 잡고 다시 찾으니 '어스'가 나왔다.
자비에 돌란의 '마미'같은 경우 한국어로 검색했을 땐 찾기가 힘들고 영어인 'mommy'로 검색했을 땐 검색값이 뒤에 있었지만 그래도 찾을 수 있었다. 영화 제목이 '어쩌구 mommy'인 경우에 밀려서 뒤에 있던 것이었다. 해결을 위해 시퀄라이즈 where문을 변경해주었다.
where: {
title_eng: {
[Op.like]: title + "%",
},
},[Op.like]가 뭔가요?
이해를 위해 Sequelize query 확인하기
검색 기능의 정확성
감독명으로도 검색할 수 있게 구현하고 싶었으나 title=?, director=?로 각각 엔드포인트가 달라져야 한다. 요청 인자인 query(통합 검색 기능)를 써보려고 했는데 배우의 이름, 줄거리에 검색값이 한 글자라도 포함되면 데이터를 반환해서 정확도가 자연스럽게 떨어질 수밖에 없다.
만약 내가 자비에 돌란이라는 감독명으로 검색을 하고 싶어서 '자비에'까지 쓰고 검색을 했다면 query문에서는 영화 소개에 '자비를 바랐던 어떤 소녀가 ...' 이런 영화까지 데이터에 담아 보내주는 것이다
할 수 없이 title로만 검색하되, 정확성을 높이려고 많이 생각했다.
DB에 담긴 데이터를 관찰했을 때 1. 감독 정보가 없거나 2. 장르 정보가 없으면 유저가 찾는 정보가 아닐 거라고 판단했다.
| id | title | genre | director | released | createdAt | updatedAt | title_eng
+------+-------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------
| 248 | 셔터 아일랜드+육혈포 강도단+이상한 나라의 앨리스 | 기타 | director-not-found | 2010 | 2021-11-05 06:06:02 | 2021-11-05 06:06:02 | Package Screening 우리는 '셔터 아일랜드'나 '이상한 나라의 앨리스'가 찾고 싶지 '셔터 아일랜드+육혈포 강도단+이상한 나라의 앨리스'를 찾고 싶진 않을 것이다.
물론 있을 수도 있지만 프로젝트의 규모를 생각했을 때 '주류'와 '비주류'를 나눠야하는 '선택'이 필요하다. 여기서 말하는 '비주류'는 유명하지 않거나 인기가 적은 영화가 아닌 '과연 사용자를 위해 검색창에 띄워줘야할까?'하는 영화이다.
따라서 성인물 뿐만 아니라 장르와 감독의 정보가 없는 영화도 필터링해주었다.
const filtedMovieList = movieList.filter((el) => {
return el.genre !== "에로" && el.director.length !== 0 && el.genre.length !== 0
})1. 정규 표현식을 이용한 영화 제목 필터링
적용 전
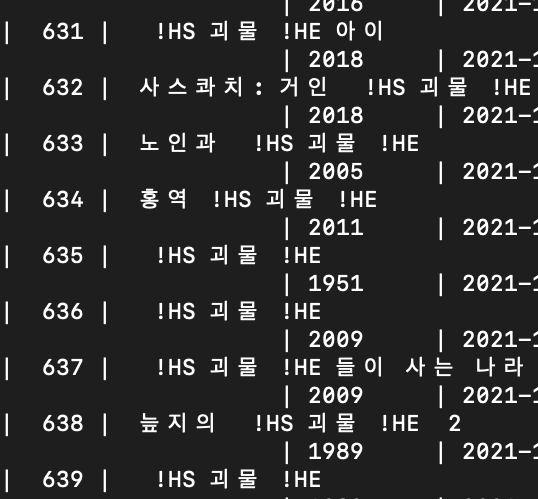
처음 DB를 확인했을 때 !HS와 !HE를 보고 진한 현기증을 느꼈다. 아마 유사 검색 기능 구현을 위해 쓰인 것 같은데 내 DB에도 그대로 저장되어 있었다.
선언을 const에서 let으로 바꾸고 정규표현식을 적용한 값으로 재할당해주었다.
let { title: title } = el
title = title.replace(/\!HS/g, "") : !HS를 빈문자열로 replace
title = title.replace(/\!HE/g, "") : !HE를 빈문자열로 replace
title = title.replace(/^\s+|\s+$/g, "") : 앞뒤 공백 제거
title = title.replace(/ +/g, " ") : 여러개의 공백 하나의 공백으로 바꾸기 적용 후
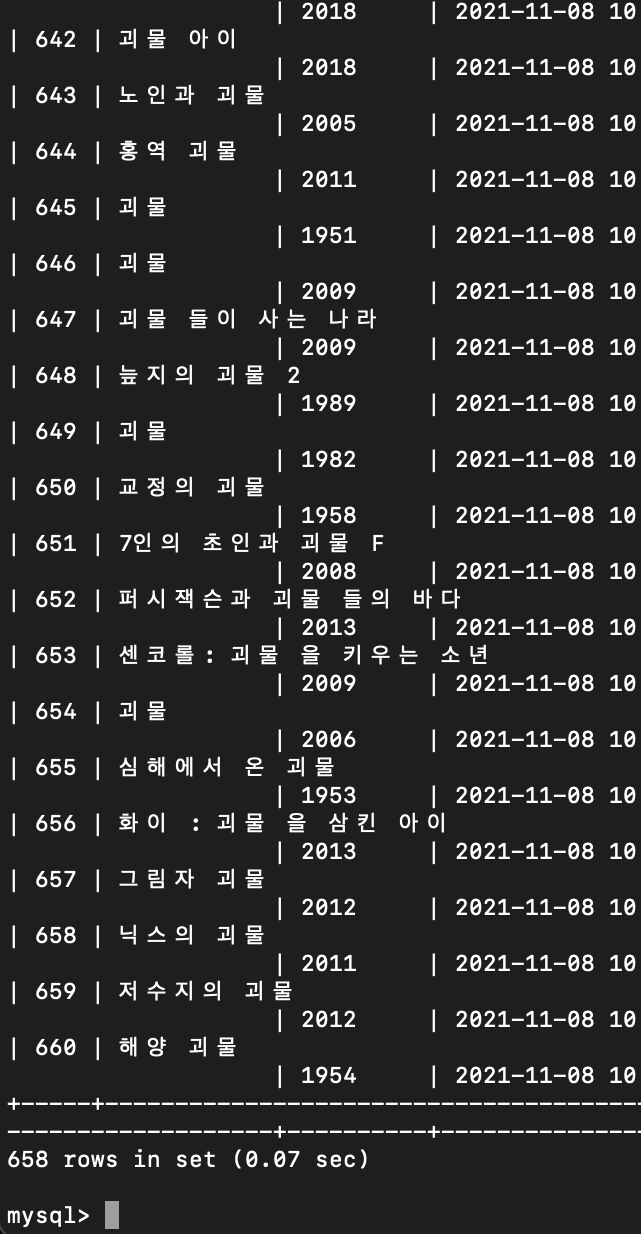
2. DB에서 찾기
여기까지 왔다면 DB에는 대개 근거있는 데이터들이 들어가있을 것이다. 이제 그 근거있는 데이터 중에서도 더욱 정확한 데이터만을 추려서 응답으로 보내줘야한다. 나는 프론트 분들과 5개를 보내주기로 얘기했다.
// 코드의 일부분만을 발췌했습니다
Description.findAll({
raw: true,
attributes: ["id", "title", "title_eng", "genre", "director", "released"],
order: [["title", "ASC"]],
where: {
title: {
[Op.like]: title + "%",
},
},
limit: 5,
}),1) [Op.like]: title + "%"
title값을 오름차순으로 정렬하여 [Op.like]: title + "%"를 썼다. [Op.substring]을 쓰지 않은 이유는 사용자가 검색한 값을 기준으로 정렬을 위해서다. '타짜'라는 영화를 찾고 싶으면 '타짜'로 입력했을 때, '여타짜'는 나오게 하고 싶지 않았다. '마더'를 검색했을 때 '굿바이 마더'나 여타 다른 단어가 사용자가 입력한 값 앞에 띄워 응답을 보내고 싶지 않았기 때문이다.
2) 장점과 단점
[Op.substring]이나 [Op.like]: "%"+title+"%"이 아니기 때문에 '오만과 편견'에서 '편견'만을 입력했을 때 값이 나오지 않고 '오만'으로 검색해야만 나온다. 하지만, 프론트로 보내줘야할 응답 개수가 5개로 한정되어 있는 상태에서 사용자가 찾는 영화를 보내주기 위해서는, 즉 정확도를 올리기 위해선 필요한 선택이었다고 생각한다.
3) 영어 제목 어떻게 찾나요?
해당 DB 테이블에 한글 제목과 영어 제목으로 컬럼 두 개를 만들고 각각 find해준다.
// 코드의 일부분만을 발췌했습니다
Description.findAll({
raw: true,
attributes: ["id", "title", "title_eng", "genre", "director", "released"],
order: [["title_eng", "ASC"]],
where: {
title_eng: {
[Op.like]: title + "%",
},
},
limit: 5,
}),결과
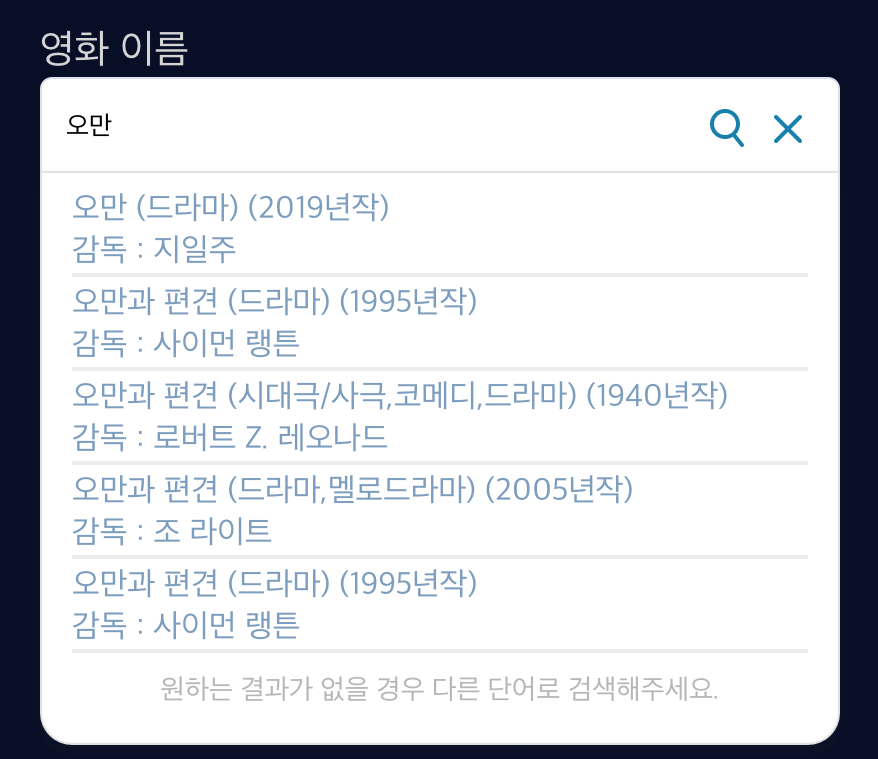
정보가 잘 나왔다. 오만으로 원하는 결과를 찾지 못했을 때에는 "오만과" 또는 "오만과 편견"으로 검색할 수 있도록 추가적으로 텍스트를 띄워주웠다.
구현이 생각보다 쉽지 않았다. "b"가 들어간 정보 다 찾아줘 같은 단순 검색은 substring으로 처리하면 되겠지만, "b"로 찾을 건데 "sweet like butter"나 "butter"말고 "black skirt"찾아줘 라는 건 어렵다. 또한 사용자가 어떤 데이터를 원하는지도 알 수 없기 때문에 응답 데이터를 가공하는 데 많은 시행착오를 거쳤다. 나중에는 유저가 검색한 영화를 기반으로 검색 기능을 좀 더 보완할 수 있을 것 같다. 현재로써 완벽하진 않지만 괜찮은 결과값을 나타낸 것 같아 만족스럽고 진행하며 많이 배웠기 때문에 값진 시간이었다.
