Sigmoid, ReLU
Activation Function
- Activation Function : 특정 값을 넘어가거나 도달하면, 그 값을 출력시켜주는 것.
Multi Layer Program
- Input Layer : 입력값을 전달해주는 Layer
- Hidden Layer: 숨겨진 Layer을 뜻하고 출력 Layer와 입력 Layer 사이의 모든 Layer을 의미한다.
- Output LAyer: 원하는 출력형태로 출력해주는 Layer
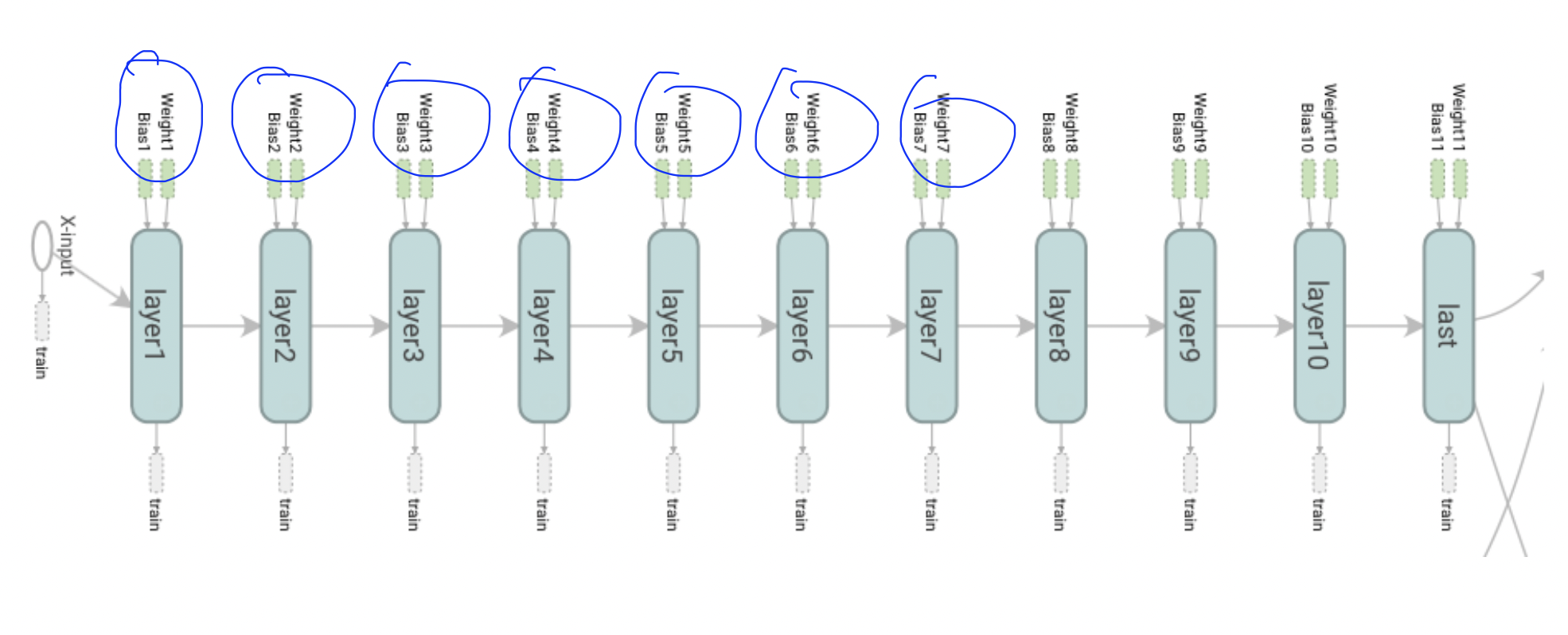
Vanishing Gradient Problem
- 문제점: 여러 Layer로 이루어진 모델이 Back Propagation을 진행하면서, 여러번 곱을 하게 됨. 그러나 Sigmoid 함수를 쓰게 되면서 0~1사이값으로 고정. 그래서 여러번 곱하게 되면 0에 수렴하는 값을 갖게 되서 Gradient값이 사라지는 현상 발생
- 해결 방안 : ReLU function, tanh, MaxOut Function, Leaky ReLU, ELU 와 같이 조금더 광범위한 확률함수를 Input Layer, Hidden Layer에 적용.
- 주의해야할 사항 : Output Layer에서는 확률함수인 Sigmoid를 써서 0~1사이의 값이 나오도록 설정
Weight 초기화
Vanishing Problem 해결 방법
1. ReLU function 활용
2. Weight initiallization 올바르게 : 만약 0으로 초기화를 하게 되면 기울기가 다 0 즉, Gradient 값이 다 0이 됨. 따라서 절대로 0으로 초기화를 하면 안됨. -> Restricted Boatman Machine(DBM)/현재는 많이 쓰지 않음
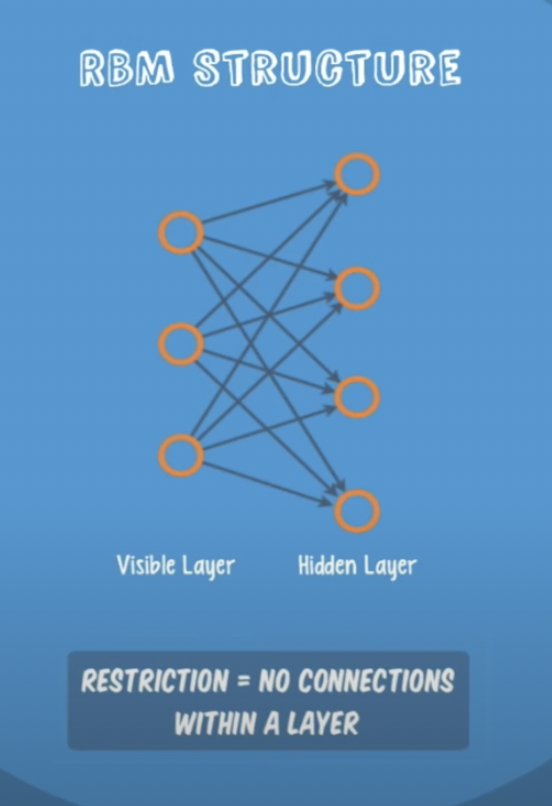
RBM이란
-
visible Layer과 Hiden Layer의 차이를 줄여주는 모델. 처음 두개의 Layer만 Focus On, Fine Tuning. Forward/Back Word값을 반복해서 최적화
-
대안 : Xavier/He's initialization : 간단한 수식으로 같은 효과를 냄
DropOut & Model Ensangble
Overfitting
많이 학습할 수록, 복잡한 방식으로 Layer을 깊게 만들수록 학습 데이터에 과적합됨.
예) 모의고사문제와 같은 문제가 나오면 문제를 맞추지만 응용문제는 맞출 수 없음
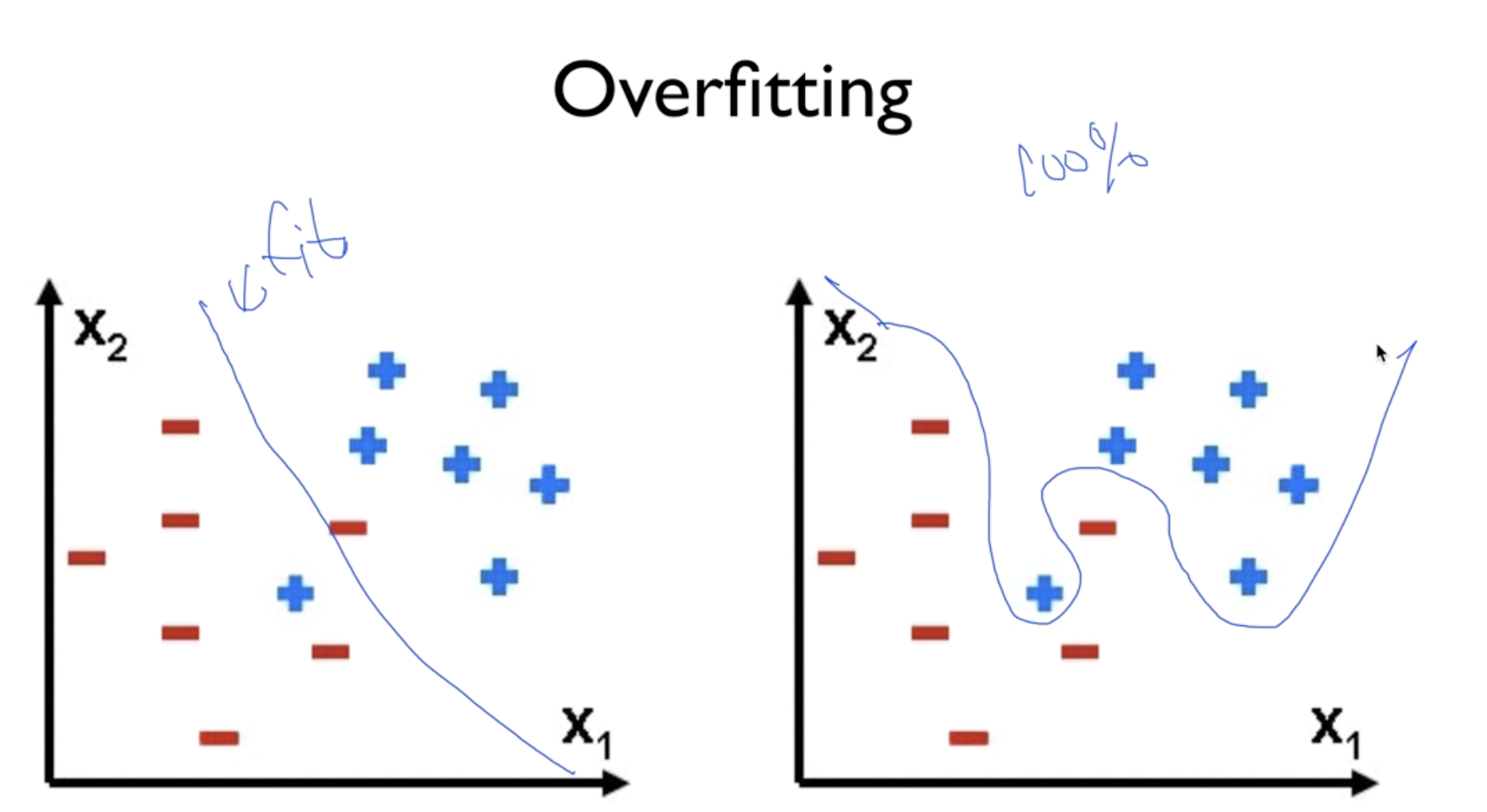
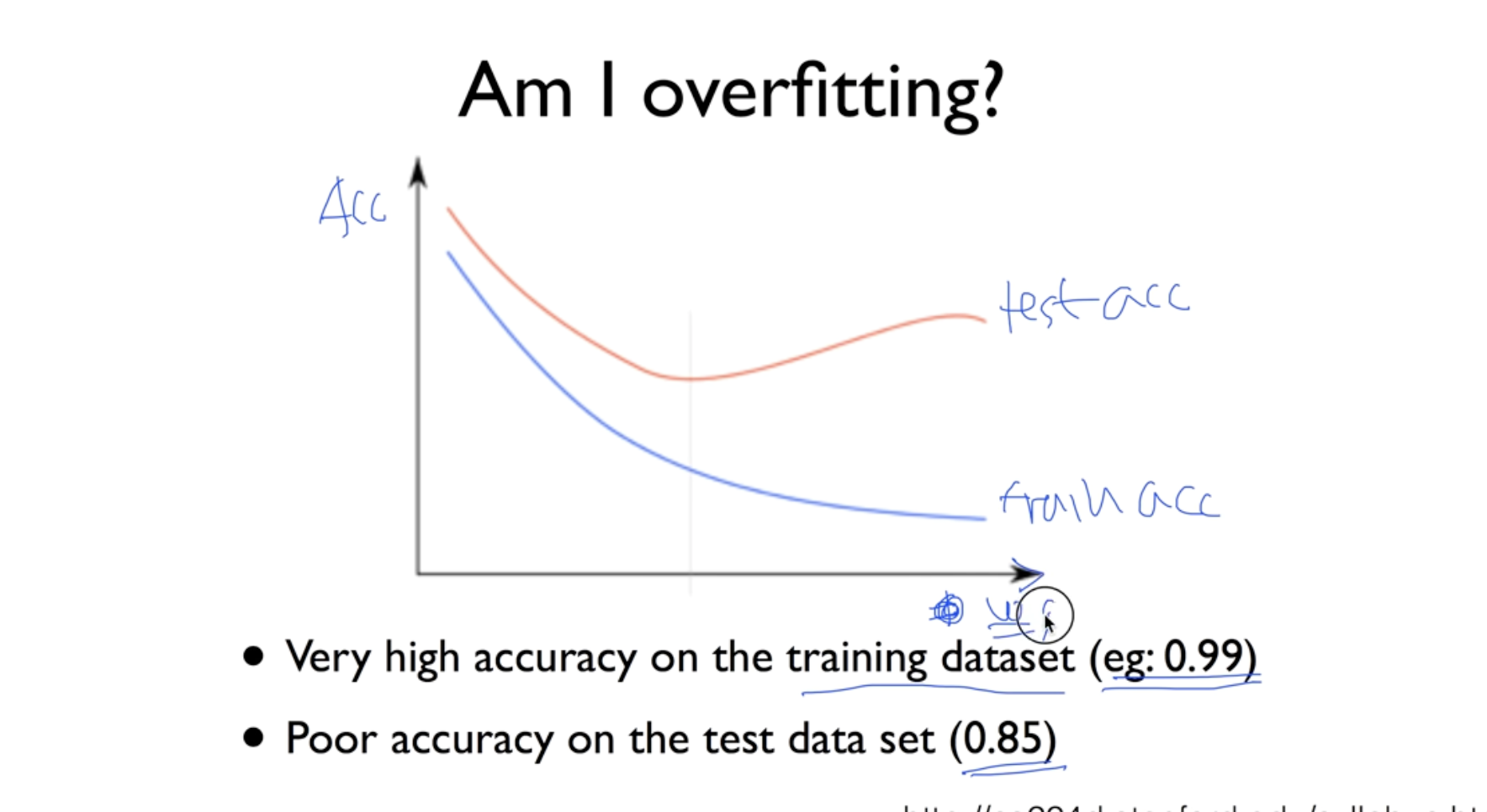
해결방안 : Regularization ( w가 너무 커지지 않도록 조절 / 특정 W값에 치우치지 않도록 )
DropOut
DropOut이란: 몇개의 선을 끊어서 랜덤하게 노드를 학습하는 방식으로 과적합을 방지해줌. 평가할때는 모든 노드를 사용
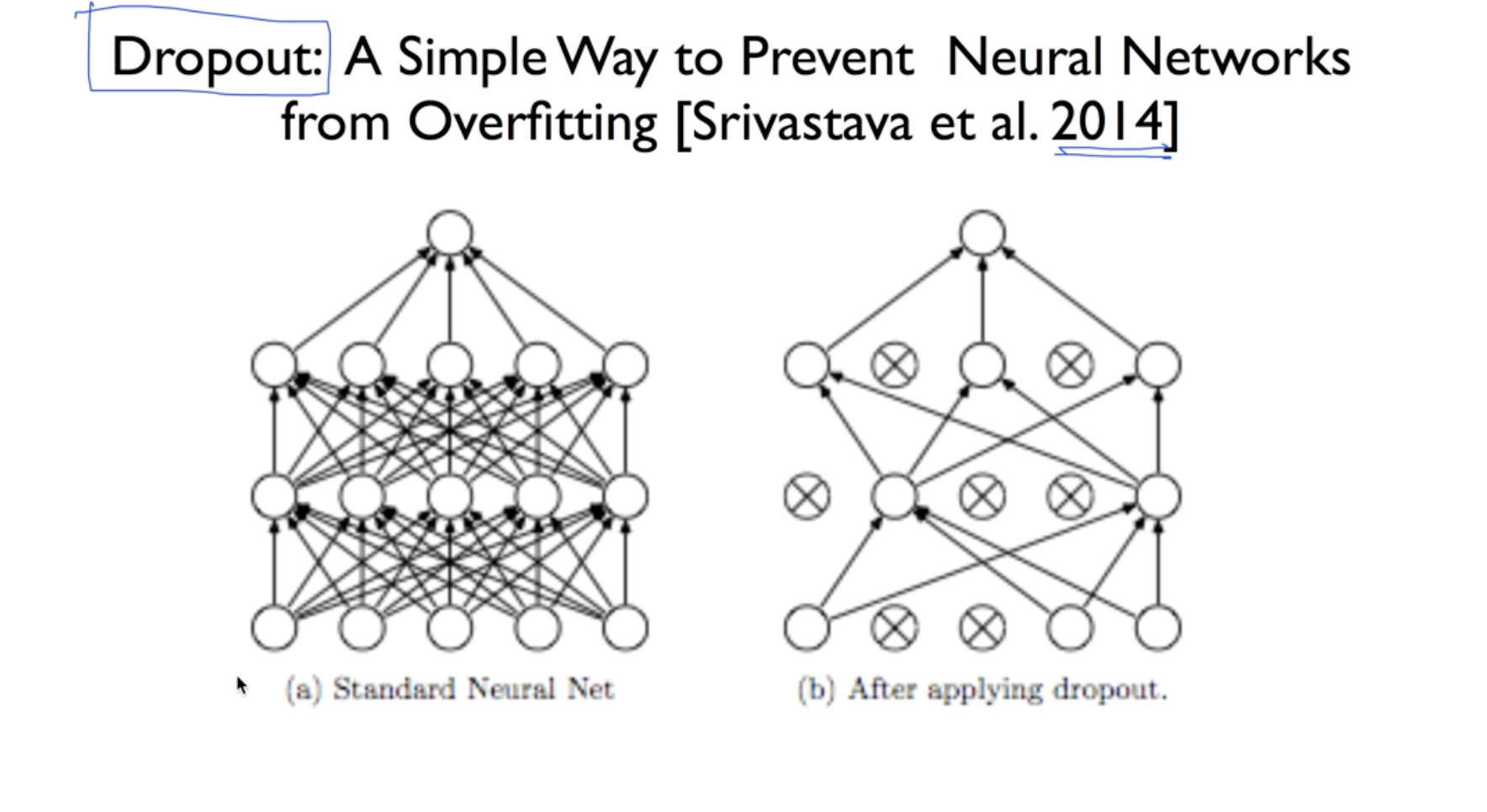
Ensemble 이란? 여러개의 모델링을 통해 성능을 향상 시킴.

NN LEGO
Feed Forward Network, Fast Forward Network, Split Merge, Recurrent Network(RNN) 등 다양한 방법으로 Network 모델을 만들 수 있음.

사회적 가치를 실현하는 프로그래머