Stanford University CS231n - Lecture 3 :: Loss Functions and Optimization
0
Stanford University CS231n
목록 보기
3/4
Loss function and Optimization
- 강의를 들어가기 전에
- Assignment #1: https://cs231n.github.io/assignments2017/assignment1/
본강의의 숙제를 확인해볼 수 있음. 채점은 불가능하나 어떤 부분을 중점적으로 점수를 매기는지에 대해서 체크가능 - Piazza에서 프로젝트 진행가능
- Google Cloud credit : 학교 구글 클라우드 계정 활용해서 과제를 해보기
- Assignment #1: https://cs231n.github.io/assignments2017/assignment1/
지난 강의 내용
- 접근방식을 Data- driven 방식으로 전환하게 된 계기에 대해 배움.
- Challenges of Recognition : Semantic Gap, Clutter 등등 실제로 우리가 보는 의미론적 비전과 컴퓨터가 보는 그리드 값에는 상당한 차이 존재
- K-nn : 간단히 데이터를 학습하고 분류할 수 있는 방법, CIFAR 10 , cross Validation, hyper parameter
- Linear Classifier: paramatic classifier, image -> Long vector, image pixel converts to 10 categories - CIFAR 10
이번 시간
- 강의를 통해서 어떤 W를 선택해야하는지, W의 선택방법에 대해서 배움
- Optimization, Loss function
Loss Function & Optimzation Pre
- 고양이를 보면 고양이라고 체크되어있는 부분이 2.9의 점수를 받은 것으로 분류하는 것이 옳고, automobile은 6.04로 가장 높은 점수를 받은 것으로 분류하는 것이 옳다. 또한 개구리는 -4.34로 제일 낮은 점수를 받은것으로 분류하는 것이 옳다. 이러한 방식은 눈으로 확인해서 분류하는 방식이며, 실질적으로 W를 선택해야 할 때에는 기계가 스스로 올바른 선택을 내려야한다. 이런 것을 구할 수 있도록 하는 것이 오차 점수를 만드는 것이 Loss function이며, 이 Loss function의 오차 점수가 최소화하여 올바른 파라미터를 찾아가는 과정을 Optimization이라고 한다.

- 가정) 다음과같이 세개의 고양이, 자동차, 개구리를 세개로 분류하는 작업
- 아래에서 발생하는 문제점 : Score가 높은 값이 해당하는 카테고리로 분류를 한다면, 고양이는 제대로 분류되지 않을 가능성이 존재하고, 개구리는 잘못된 결과가 나올 것이 분명
- 해결방안 : Loss function을 이용
- Loss function에서 Xi는 훈련데이터 Yi는 라벨을 넣어주어 해당하는 샘플마다 각 카테고리의 Loss function의 값이 얼마나 되는지 계산한다. Optimization을 통해 Loss 값을 줄여주고 점수에 따라 올바른 카테고리로 분류할 수 있도록 해준다.

- Loss function의 값을 이용해서 값을 구해주는 방식은 하나의 클래스에 대한 값이 다른 클래스에 해당하는 값이 크면(마진보다 크면) 0이라는 Loss를 출력해주고, 제대로 구분히 안간다면(마진에 해당하는 범위를 제대로 출력하지 못한다면) 1과 같이 우리가 설정해준 Loss값을 출력해준다. 그리고 모든 훈련데이터의 샘플값의 평균을 구하는 방식으로 Loss function이 주어지며 해당하는 값을 감소하는 방식으로 optimization을 해주게 된다.

- Hinge Loss : SVM의 Loss function
x축 : s_yi 해당하는 클래스의 점수
y축 : 마진과 비교로 발생하는 Loss function의 값.

- 계산방식예시 : 최종적으로 5.3이라는 오류를 출력





- 계산방식예시 : 최종적으로 5.3이라는 오류를 출력
- 수업시간 질문
- Q1 What happens to loss if car changes a little bit?(차의 오류 값이 조금 달라진다면 어떤 일이 일어나는가?
정답: 손실값은 변하지 않는다. car값이 cat과 frog보다 작아지지 않는 한, 계속 올바른 카테고리로 분류하게 되고, 여전히 월등히 높은 score을 가지기 때문에 loss 값 0이 바뀌지 않는다. - Q2 What is the min/max possible loss?(가능한 최소/최대 오차 값이 어떻게 되는가?)
정답:최대는 이론적으로 모두가 틀리고, SVM함수에서 보듯 무한한 값을 더할 수 있으므로 무한대가 최대 값이고, 최소 값은 모든 loss가 0이 될 수 있으므로 0이다. - Q3 At initialization W is small so as s ≈ 0. what is loss?(S값이 0에 가까이 측정된다면 loss 값이 어떻게 될 것인가?)
정답: class에서 1을 뺀 값
해설: 모든 값은 하나의 정확하게 계산된 값을 제외하고 남은 값들을 빼고 1을 더해주기 때문에 올바르게 예측한 class하나 에서는 Loss 값이 0, 나머지 클래스에서는 1이라는 값이 나오게 된다. 이 말은 즉, 클래스 갯수에서 하나만 0, 나머지는 1이라는 의미이므로 갯수에서 1을 뺀 것과 같다. 따라서 이와 같은 오류가 나왔을 때에서는 W의 초깃값을 추측할 수 있으므로 Loss function값을 예상하고 다루는 것이 필요하다. - Q4. What if the sum was over all classes?(including j= yj )
정답: 손실이 1이 증가 - Q5 What if we used mean instead of sum?(합대신 평균을 사용하면?):
정답: mean사용 가능
해설 : 값이 의미하는 바가 달라지지 않기 때문. - Q6 What if we use Square?(제곱을 사용하면 값의 의미가 달라지는가?)
정답: 값의 의미가 달라진다.(different)- 왜 제곱을 사용하는가? 제곱을 사용하게 되면 편차가 커질수록 증가하는 값이 제곱이 되므로 제곱을 사용하지 않는 Loss function 보다 값이 훨씬 더 커진다. 즉, 제곱을 이용하면 오류에 민감하게 반응하다는 것을 의미한다. 따라서 만약 오류가 작은 모델을 만들고 싶으면 Loss function으로 square을 이용하고, 오류가 작아도 상관없는 모델을 만들고 싶으면 일반 loss function을 이용하면 된다. 본인이 만들고 싶은 모델의 특징을 생각해서 올바른 function을 사용해야한다.
- Q1 What happens to loss if car changes a little bit?(차의 오류 값이 조금 달라진다면 어떤 일이 일어나는가?
- Example Class :
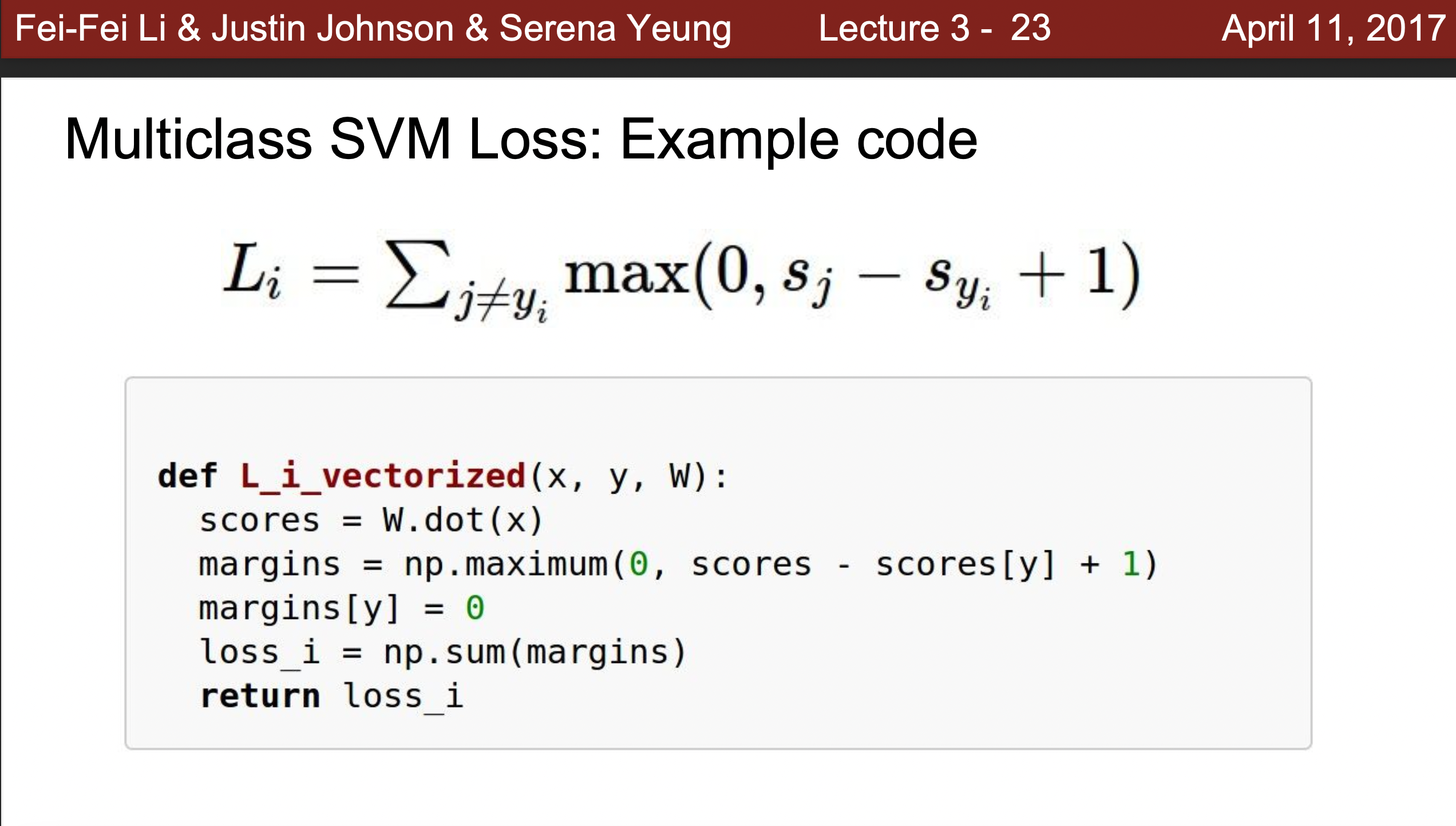
- 따라서 Loss가 0이되는 W를 찾았다고 가정한다면 이는 유일한가?
아니다. 이 값은 유일하지 않으며 2개, 3개 등 다양할 수 있다.
예) 아래의 값에서 2배로 늘린다면 결국 Loss가 각각 2배가 되지만 여전히 0의 손실 값을 갖게 됨으로 다른 W가 존재함을 알 수 있다.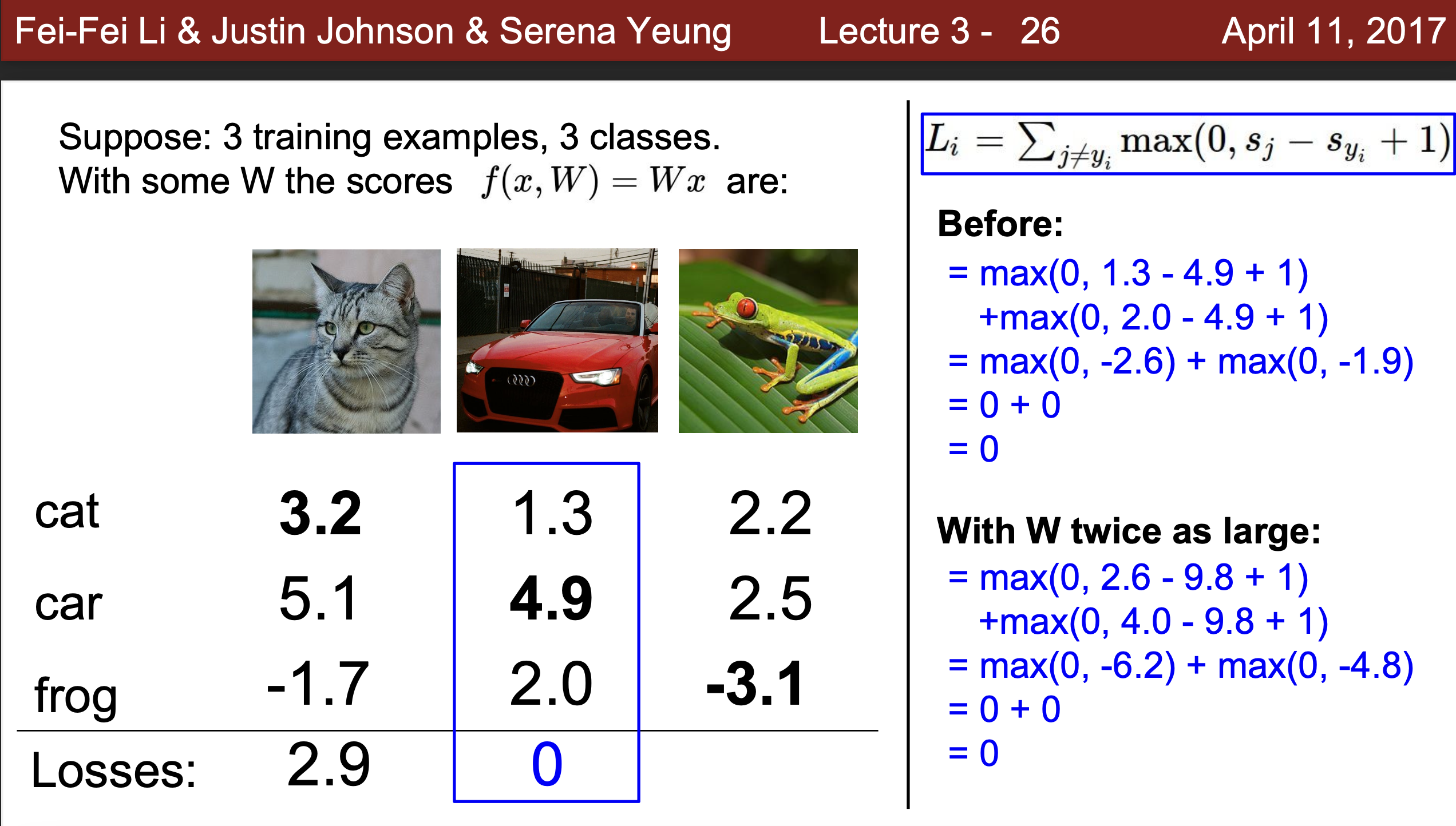
- 따라서 Loss가 0이되는 W를 찾았다고 가정한다면 이는 유일한가?
올바른 W값을 선택하는 방법
- 아래와 같이 W가 다양하기 때문에 Train데이터에 많은 훈련을 투자하다 보면 선형 경계가 다음과 같이 불균일하게 나타날 수 있고, 이렇게 훈련데이터에 Overfitting이 된 데이터는 test데이터에 좋은 성능을 보여주지 못한다. 하지만 우리가 모델을 만드는 목적은 일반적인(테스트) 데이터에 뛰어난 성능을 보여주는 것을 만드는 것이 목적이 됨으로 이 부분에 대해서 조정이 필요하다.
- 문제 해결방법 : Regularization
이 방법은 R(W)라는 항을 두고 람다를 이용해 Data Loss와 Regularization을 Trade off를 해주는데 이를 통해 조금 더 simple한 W를 찾도록 도와준다 . - 왜 Simple 한 W를 찾아야하는가?Occam's Razor에 따르면 가장 간단한 예시가 일반화 하는데 최고의 방법이라고 이야기하며, 이는 가장 간단한 Parameter인 W를 찾을 때 효과가 배가 되기 때문이다.

- 정규화 방식 : L1 Regularization, L2 Regularization, Elastic L1-L2 Regularization, Max norm regularization, (Deep Leargning : Drop out, Fancier: Batch regularization, stochastic Regularization )
- Penalty를 주는 것이라고 이해하면 됨.
- Normalization은 문제나, 모델, 데이터에 따라 적합한 것을 적용해야함.
Softmax Classifier ( Multinomial Logistic Regression)
- 딥러닝에 더 적합한 방식
- SVM Loss function 은 스코어 이상의 정보를 제공하지 않으나, Softmax Classifier의 Loss function은 해당하는 값이 얼마나 잘못된 값을 가지고 있는지 올바른 결과를 보여준다.

- Softmax Loss function 특징
- 값의 연산을 통해 함수를 통해 확률값으로 바꾸어준다.
- 실제 확률의 정확도는 0~1사이로 설정이 되는데 이는 기존 함수의 값을 최대로 하는 것보다 1로 수렴하는 것이 더 구하기 쉽기 때문에 이용한 기법이다.
- Loss function은 이 값을 -를 취한 값으로 이 값이 음수이기에 -log값을 최소화하는 파라미터를 찾게 된다.

- Q1.What is the min/max possible Loss?(손실함수의 최대최소는 어떻게 되는가
정답 : 최소 0, 최대 infinite(무한) 이론적으로 도달하기 쉽지 않음
이유 : 최소가 0이 된다는 것은 모든 클래스에 올바르게 할당되는 것에 동시에 분모가 무한히 커지는 것을 의미한다. 이렇게 무한히 커지는 값을 갖기에는 이론적으로 힘들기 때문에, 0으로 도달 할 수 있으나 대부분의 경우 0을 보는 것은 쉽지 않을 것이다. 또한 log는 -무한대까지 갈 수 있으므로 이론적으로 무한대까지 커질 수 있다. 하지만 컴퓨터는 무한이라는 숫자를 다루기 힘들어 함으로 다루기 어려워 함으로 실제로 볼 확률은 0에 가깝다. - Q2 At initialization W is small so as s ≈ 0. what is loss?(S값이 0에 가까이 측정된다면 loss 값이 어떻게 될 것인가?)
정답:-logC
이러한 값이 나오면 올바르게 초기값이 설정되어 있는지 확인할 필요가 있다.
- Q1.What is the min/max possible Loss?(손실함수의 최대최소는 어떻게 되는가
Summary
- Softmax Regression함수는 다음과 같이 f함수를 찾아가는 과정인데, Loss function을 이용해서 올바른 파라미터인 W를 구하고 동시에 Regularization값을 구하는 과정을 포함한다. 이는 딥러닝 혹은 머신러닝의 전형적인 방법이기도 하다. 그리고 이제 문제는 어떻게 올바른 W값을 구해주냐인데 이는 Optimization을 통해 알 수 있다.

Optimization
- Optimization은 우리가 큰 협곡을 거닐며, 어떠한 부분이 제일 낮은 부분인지 찾는 것과 같다. 찾는 방식은 두가지가 있다.
- 1.Random Search : 랜덤하게 발을 디딪는 방법으로 매우 비효율적이며, 쓰지 않는다. 랜덤하게 값을 변화시켜 해당하는 값을 확인하는 방식으로 정확도가 낮다.
아래 예시는 15퍼센트의 정확도가 나왔다고 하는데, 완전 랜덤하게 선택하는 정확도보다 높은 것은 사실이나 요즘 모델이 95퍼센트 이상의 정확도를 가지므로 효율적인 모델이라고 볼수 없다.

- 2.Follow the scope : 발을 디디면서 기하학적으로 이 기울기가 어떻게 되는지 지형적으로 올라가는지 내려가는지 체크하면서 발을 디딪는 방식이다. 우리가 도함수를 구하는 방식으로 생각해주면 되는데, 값을 변화시키면서 해당하는 도함수를 체크해주면서 내려가는 방식이다.
실제 구현에서 : 실제 구현을 하는 동안 만약 값의 변화량을 체크한다면, 실제로는 매우 많은 데이터의 값과 많은 양의 W를 구하게 되므로 매우 느리게 움직일 것이다. 따라서 이러한 방식은 실질적으로 쓰이지 않고, 조금은 변형시켜 미분을 통해 도함수를 구해주는 방식으로 식을 계산해주고 값을 대입하는 방식으로 구해준다.


- 하지만 여전히 값의 변화를 보는 것은 좋은 디버깅의 한 방법이며, 구현한 함수가 올바르게 만들어졌는지 체크할 때 좋은 방식이다.
- 1.Random Search : 랜덤하게 발을 디딪는 방법으로 매우 비효율적이며, 쓰지 않는다. 랜덤하게 값을 변화시켜 해당하는 값을 확인하는 방식으로 정확도가 낮다.
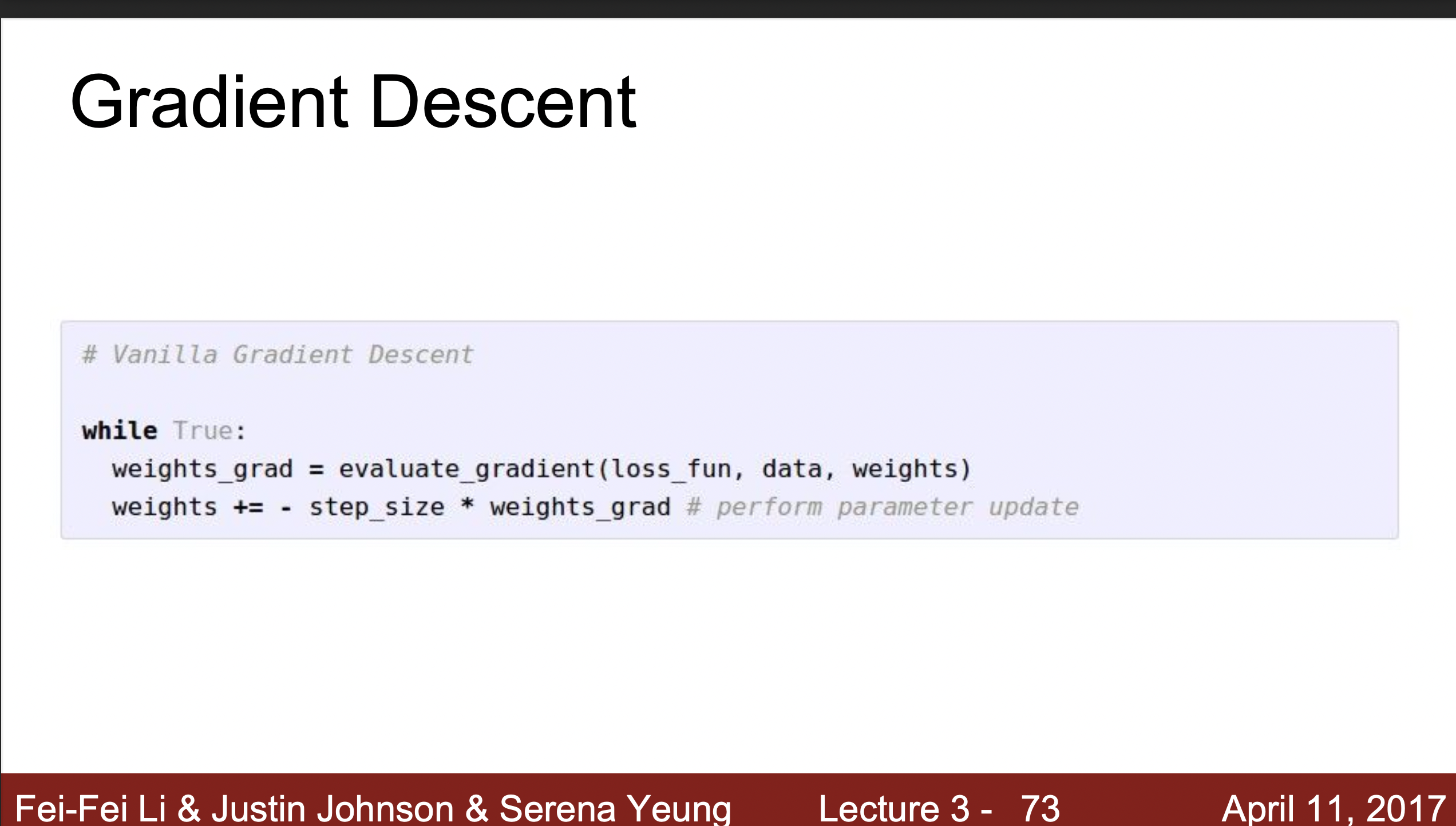
Gradient Descent
- Loss의 Minimum을 구해주는, Optimization을 구해주는 가장 효과적인 Gradient를 구해주는 방식이다. 3줄정도의 간단한 코드를 통해 이 값이 얼마나 내려가야하는지 음수의 값으로 알려준다. 그리고 Learning Rate, Step size 값과 함께 이용해서 올바른 Mimimum값을 찾아준다. Learning Rate은 학습률이라고 부르며 얼마나 내려가야할지 정해주는 부분이다.
Stochastic Gradient Descent
- Stochastic Gradient Descent라는 것은 확률적 경사하강법을 의미하는데 사용되는 이유는 다음과 같다. 실제로 학습을 하게 되면 몇만개의 데이터와 몇 백, 몇 천개의 W값을 계산하게 된다. 하지만 모든 값의 W를 계산하게 되면 시간이 오래걸리고 선형모델을 만드는데 어려움을 겪게 된다. 따라서 일부(mini-batch)를 확률적으로 랜덤하게 선택하여 W값을 구해주고 선형모델을 하는 방식으로 훨씬 더 빠른 속도를 보장한다.

- interactive web Demo를 통해 Gradient의 의미를 찾아보기
Image Feature
-
이미지 Feature는 다음과 같이 다르게 분포된 데이터 값을 학습을 통해 하나의 벡터로 합치게 되고 이 벡터를 이용하여 값을 구하고 분류를 해주게 된다.

-
비선형적으로 분포된데이터도 수식을 통해서 선형적으로 분리를 할 수 잇다.
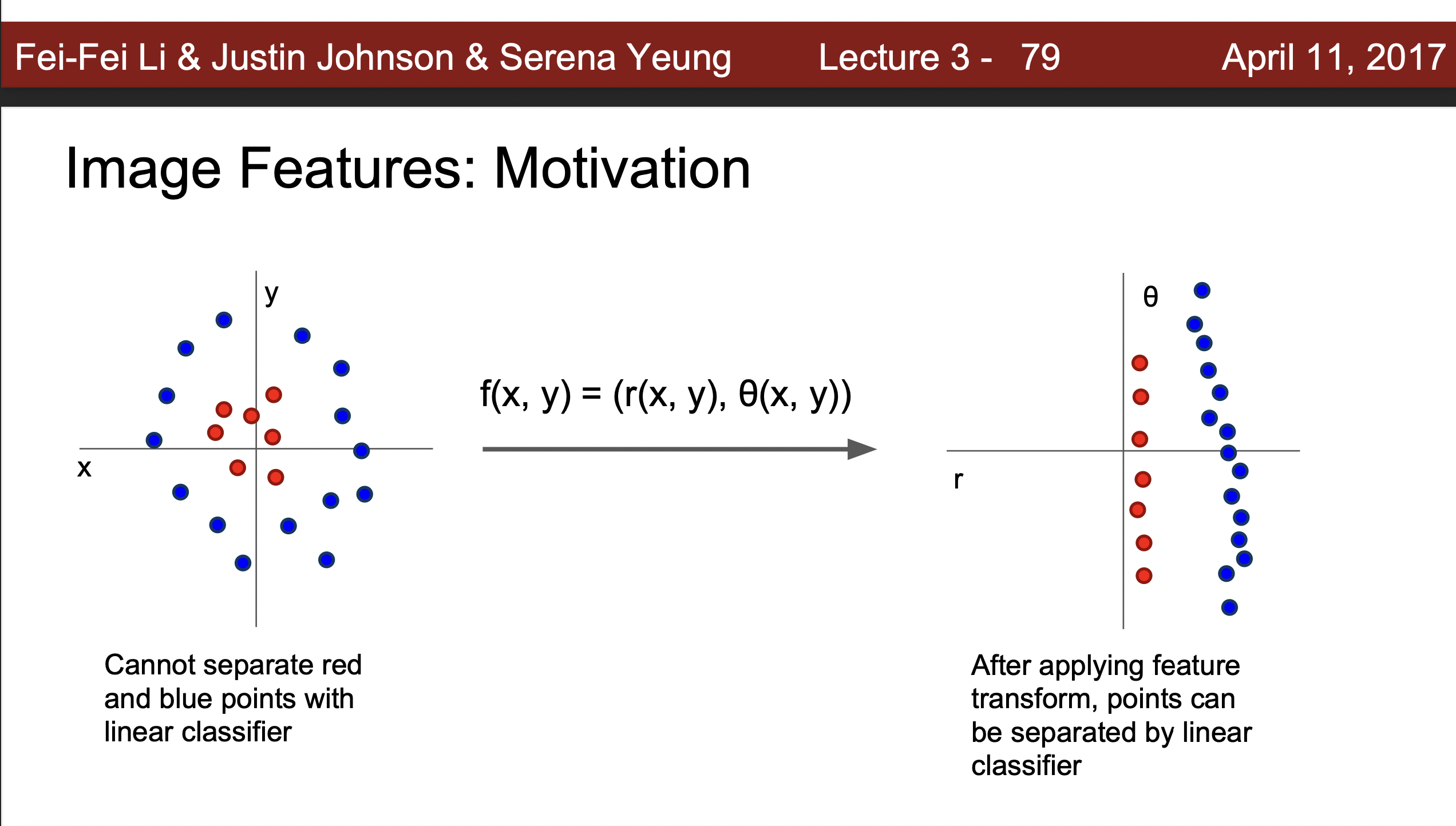
-
Color Histogram이라는 것을 통해서 색상의 특징을 나타내줄 수 있다.
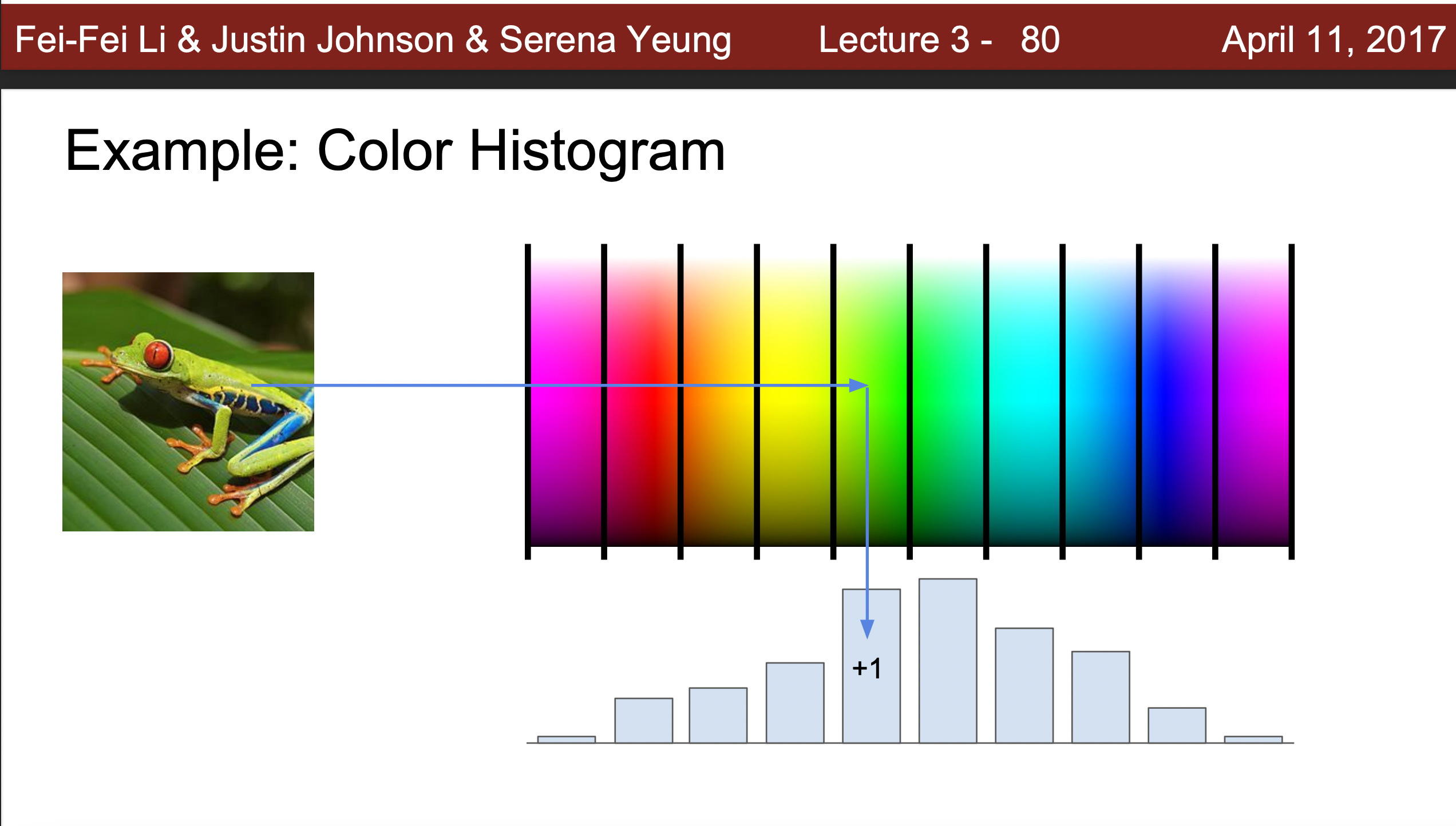
-
Histogram of Oriented Gradient라는 가장자리의 특징을 Gradient를 이용해서 방향을 알아내는 방식으로 사진을 구분해주었고, 딥러닝이전에 만힝 사용하는 방식이었다.

-
Bag of Words : 사진을 조각내고 군집화하여 해당하는 분류군의 코드 북을 만든다. 그리고 이미지를 인코딩을 하면서 그 사진이 얼마나 해당하는 분류와 일치하는지 체크하는 방식을 이용하였다.

-
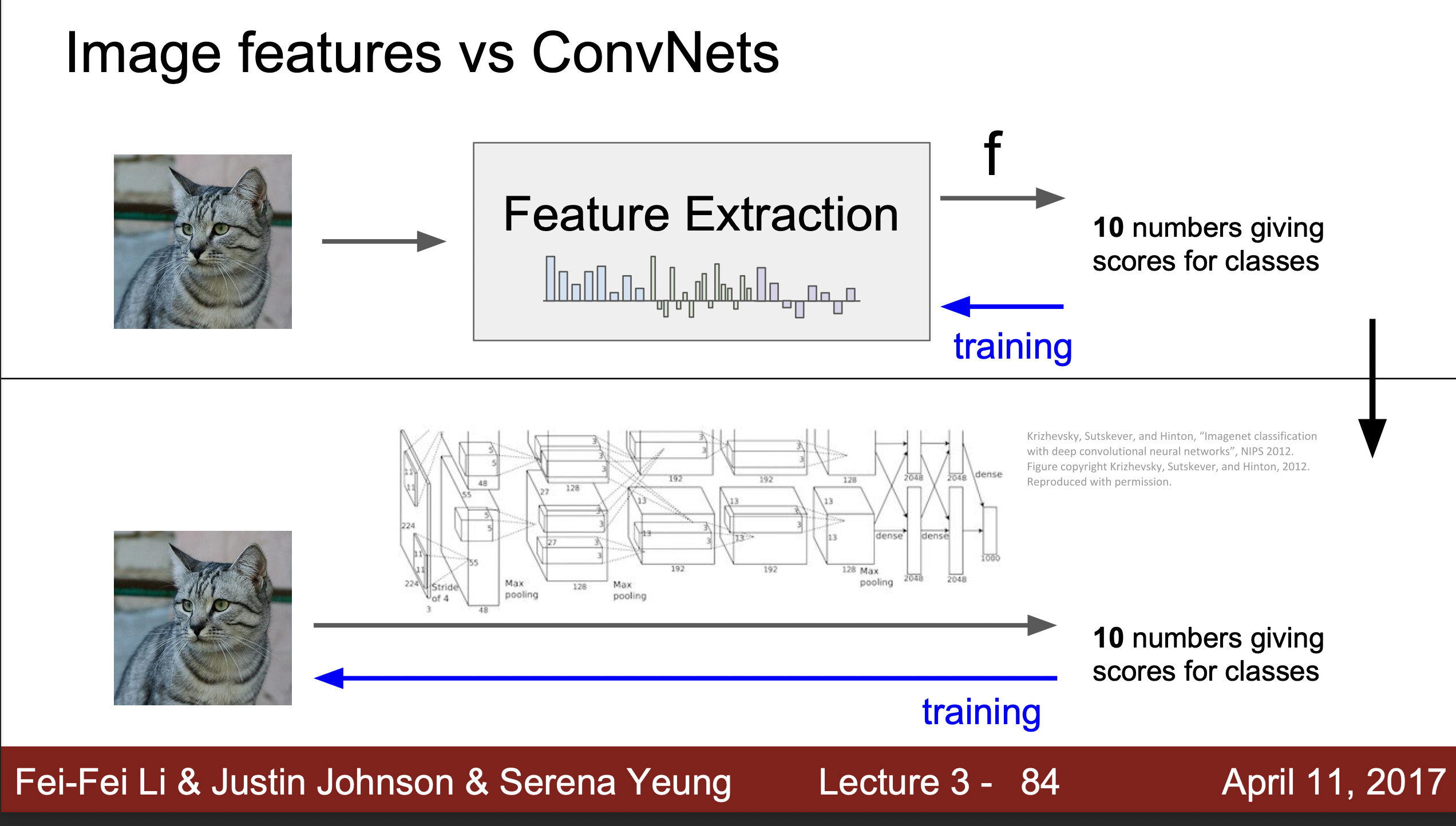
과거에는 이렇게 여러 특징들을 연결하는 방식, 즉 사진의 특징을 미리 추출하고 학습하는 방식을 이용했다면 이제는 사진에 데이터를 학습하며 특징 또한 같이 추출해준다는 것이 특징이다.

사회적 가치를 실현하는 프로그래머