본 정리내용은 코드잇 강의를 공부하며 함께 정리한 내용입니다! 더 정확하고 자세한 내용을 공부하기 위해서는 "코드잇 머신러닝 실전 강의를 참고해주세요!"
협업 필터링
- 협업필터링이란? 협업필터링이란 유저들의 데이터가 유사하다는 전제하에 하는 학습 방식입니다. 따라서 A,B,C ... 등 여러 의 유저가 있을 때 A의 유저만의 데이터가 아니라 A와 유사한 패턴을 보이는 B, C 등의 데이터도 사용하여 추천알고리즘을 만드는 것입니다!
- 데이터 표현 : 유저별로 데이터를 벡터화 하여 표현하여 하나의 유저를 하나의 벡터로 표현하여 데이터를 정리합니다.
비슷한 유저 :: 유클리드 거리 활용(Euclidean distance)
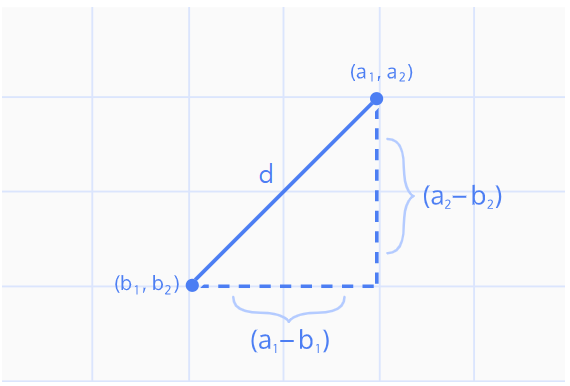
- 각 벡터의 요소들을 빼서 제곱해서 더하는 방식으로 가까운 유저를 파악할 수 있음!
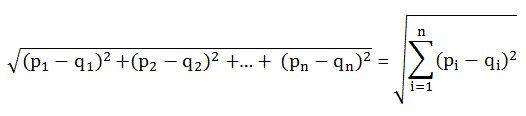
- 유클리드 거리를 이용하여 유저들이 얼마나 비슷한지 표현할 수 있게됨.
Ex) (1,1)과 (0,0) 그리고 (5,5)과(0,0)사이의 길이를 구하면 각각 1과 5가 된다. 따라서 (1,1)이 (5,5)보다 (0,0)과 비슷하다고 할 수 있다.
결론 : 가까이 있는점이 비슷한 점이다! 값이 작을수록 같은점이다!
비슷한 유저 :: 코사인 유사도(Euclidean distance)
- 두점을 원점부터 선을 그어 두 사이의 각도를 통해서 유사하다고 판단한다. 따라서 방향의 유사도를 구할 수 있다.
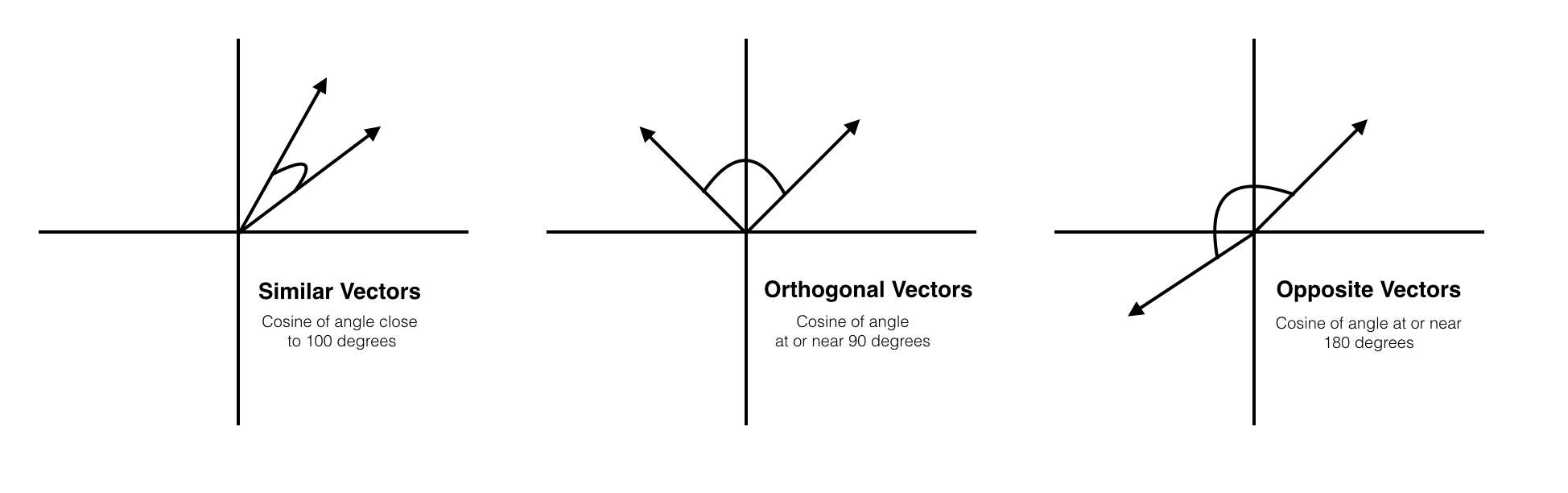
- 1에 가까울수록 : 방향일치
- 0에 가까울수록 : 서로 수진
- -1에 가까울수록 : 서로 반대
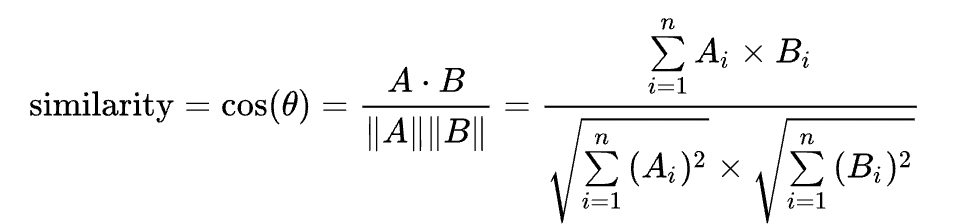
결론 : 값이 클수록, 유사하다!
데이터 전처리
- 0으로 값 채우기
- 이러한 데이터를 받을 때 해당 데이터가 비어있는 경우가 있을 수 있는데 이는 비워두거나 0으로 채워 계산할 수 있다. 따라서 0으로 채워 빈 값을 전처리 할 수도 있다.
- 평균 값 채우기
- 데이터의 유저별 평균값을 적용하여 전처리 해줄 수 있다.
- Mean Normalization
- 평균으로 빈값을 채우고, 모든 값을 평균을 빼주기.
이와 같이 빈 값에 대한 값을 처리하여 error 핸들링을 통해 전체적인 값을 구할 수 있게 된다.
이와 같은 방식을이용해서 상품기간, 혹은 유저 기반 방식의 협업 필터링 알고리즘을 구현해줄 수 있다!
이론상 유저/상품 기반 협업 필터링에는 큰 차이가 없으나 유저가 고려하는 경우가 복잡한 경우 상품 기반 협업 필터링이 더 좋은 성능을 보일 때도 있다!
협업 필터링의 장단점
- 장점 :
- 속성을 정할 필요가 없다
- 좀 더 폭넓은 상품을 추천할 수 있다.
- 내용 기반 필터링보다 성능이 좋은 경우가 많다.
단점 :
- 데이터가 많아야 한다.
- 인기가 많은 소수의 상품이 시스템을 장악할 수 있다.
- 어떤 상품이 왜 추천되는지 알기 힘들다.
따라서 다양항 알고리즘을 적용하여 추천시스템을 만드는 것이 효과적이다.
참고 : 코드잇 머신러닝 실전 강의

사회적 가치를 실현하는 프로그래머