merge sort
quick sort
heap sort
동일한 전략을 사용하는 알고리즘
merge sort
분할 : 해결하고자 하는 문제를 작은 크기의 "동일한" 문제들로 분할
정복 : 각각 작은 문제를 순환적으로 해결
합병 : 작은 문제의 해를 합하여(merge) 원래 문제에 대한 해를 구함
ex) recursion 할 때 최대값을 찾을 때
1. 데이터를 반으로 나눠 (분할)
2. 전체중 최댓값을 찾기 위해 앞에서 최대값을 찾고 뒤쪽에서 최댓값을 찾고 (정복)
3. 둘중 더 큰값을 찾으면 (합병)
4. 그것이 최댓값이라는 것
유사하게 정렬을 한다.
- 데이터가 저장된 배열을 절반으로 나눈다.
- 각각을 순환적으로 정렬한다
- 정렬된 두 개의 배열을 합쳐 전체를 정렬한다.
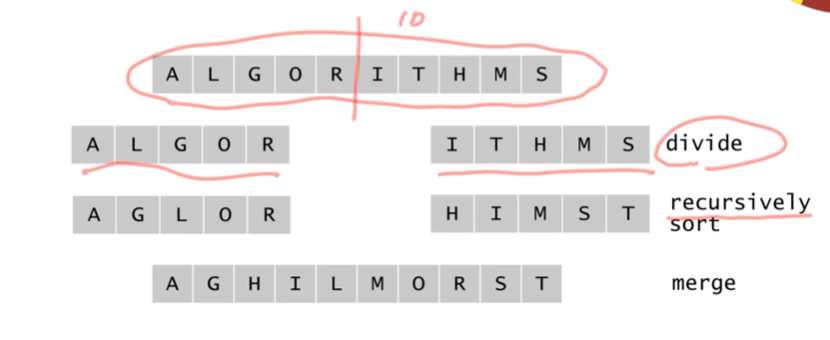
제일 밑쪽이 정렬할 데이터
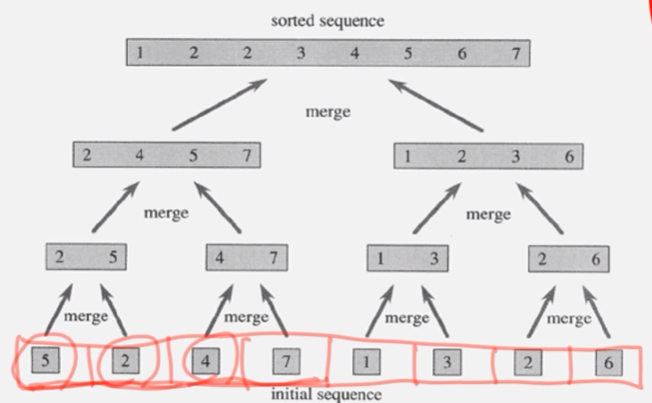
반의 반의 반의 계속 쪼개다보면 데이터가 1개로 다 나눠진다.
그 자체로 정렬된 리스트가 된다.
각각의 정렬된 8개의 list 가 있고 2개씩..4개..8개.. 합쳐진다.
나란히 재정렬된다.
mergoe 두개의 list를 합쳐서 하나의 list로 되어가는 과정
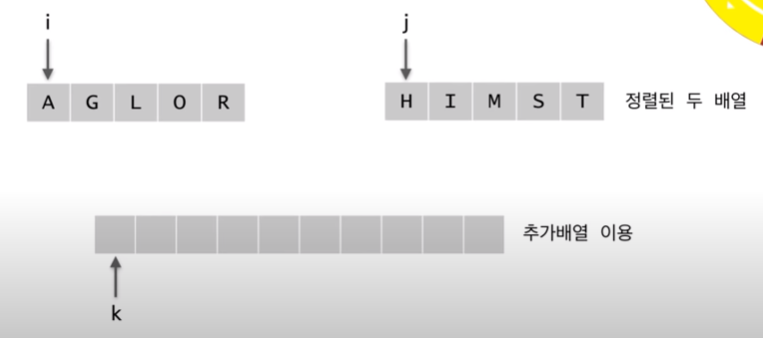
두개의 이미 정렬된 리스트가 있다고 가정하고
길이가 n인 추가배열을 만든 다음
합병한다.
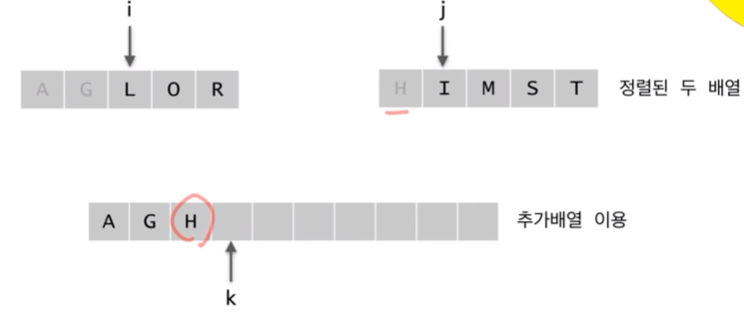
앞쪽에서 첫번째 값 뒤쪽에서 첫번째 값중 하나가 전체중에서 가장 작은값이 된다.
i = 1 list에서 가장 작은 값
j = 2 list에서 가장 작은 값
k = 합병한 list에서 가장 작은 값
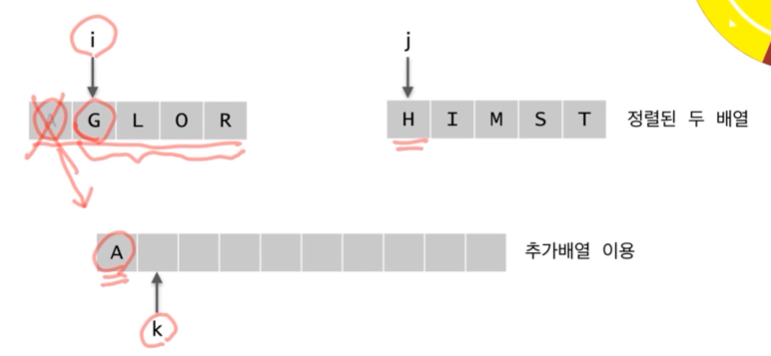
순차적으로 가장 작은값을 대조한 뒤 한개씩 내려온다.
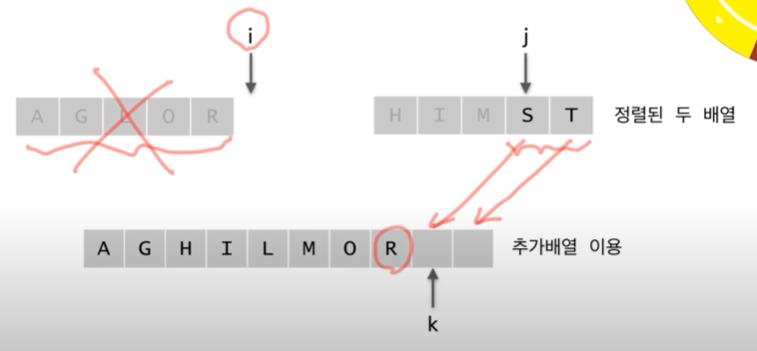
남아있는 값들은 순차적으로 내려온다. 이미 정렬되어 있는 값이기 때문에
merge sort
meargeSort(A[], p, r)
{
if(p < r) then {
q <= (p+q) /2 ; // p,q의 중간지점 계산
mergeSort(A, p, q); //전반부 정렬
mergeSort(A, q+1, r); //후반부 정렬
mergeSort(A, p, q, r); //합병
}
}
merge(A[], p, q, r)
{
정렬되어 있는 두 배열 A[p .. q]와 A[q+1...r]을 합하여
정렬된 하나의 배열 A[p..r]을 만든다.시간복잡도
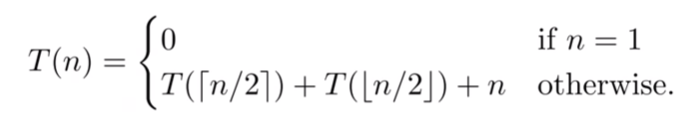
merge sort 정렬으로 걸리는 시간을 T(n)
n개의 데이터를 merge sort로 n개의 데이터를 나눠서
2/n개의 데이터로 merge sort로 2번 정렬 해야한다.
T([n/2]) 를 두번 한다.
merge를 할때 필요한 비교연산 수는 n개이다.
한번 비교를 할 때 마다, 하나의 데이터가 n개의 리스트 안으로 들어간다. 데이터의 총 갯수는 n개 1번 비교할 때마다 1개씩 들어온다..
list의 길이가 n인데 몇번 쪼개야 1개의 데이터로 쪼개어 지느냐 라는 것이다. logn층
log n x m = nlongm 이다~
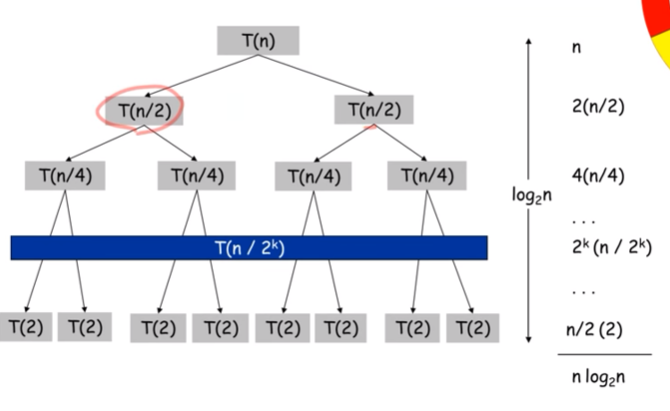
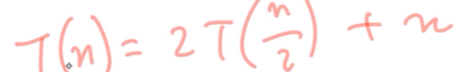
간단히 쓴다면 이렇게 된다.
만약 정렬갯수가 n=1이라면 0 이다.
