시간복잡도란?
알고리즘이 입력 크기 n에 따라 얼마나 많은 시간을 소요하는지를 나타내는 척도, 주로 Big O 표기법을 사용하며 최악의 경우 수행 시간을 나타낸다.
즉, 시간복잡도(Time Complexity)는 알고리즘이 실행되는데 필요한 기본 연산의 횟수를 입력 크기 n에 대한 함수로 나타낸 것이며, Big O 표기법은 가장 높은 차수의 항만을 고려하여 알고리즘의 성능을 표현하는데 사용되는 점근적 표기법으로 입력 크기가 매우 클 때의 동작을 집중적으로 분석한 결과이다.
종류
[!info]
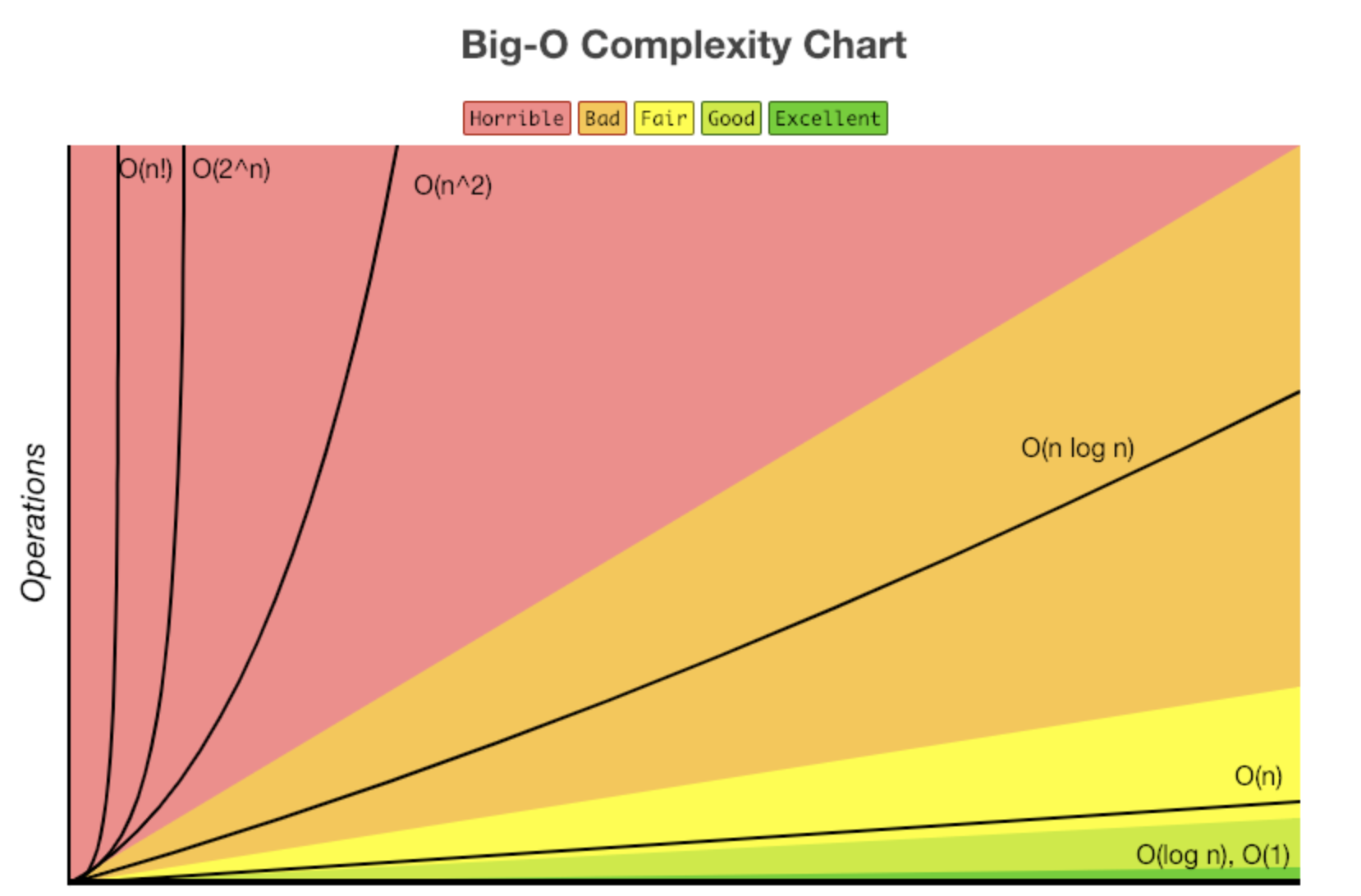
Fast O(1) < O(log n) < O(n) < O(n log n) < O(n^2) < O(n!) Slow
O(1)
상수 시간 복잡도라고 하며, 입력 크기와 무관하게 항상 일정한 시간이 소요 된다. 대표하는 알고리즘으로는 해시 테이블 삽입/삭제/검색 등이 있다.
예제
int sum = (N + 1) * N / 2;괄호의 N+1 연산, * N 연산, /2 연산, = 연산으로 총 4번의 연산을 수행한다. 이를 Big O 표기법으로 표현하면 4 = O(1)이다.
O(log n)
로그 시간 복잡도라고 하며, 입력 크기가 커질수록 시간 증가율이 로그 함수에 따라 증가한다. 통상적으로 log2 n 을 일반적으로 나타내지만 Big O 표기법에서 log의 밑은 크게 영향을 주지 않으므로 신경쓰지 않아도 무방하다. n을 밑으로 몇번 나눠야 1을 만들 수 있을까?와 동일한 개념으로 생각하면 되며, 조금 더 쉽게 설명하자면 n을 로그의 밑으로 하는 지수만큼 나누어서 연산하는데 소요되는 시간이라고 이해하자. 대표 알고리즘으로는 이진탐색 등이 있다.
예제
public void function() {
int i = 1;
while(i < n) { // log2 n
System.out.println(i);
i = i * 2;
}
}1부터 시작하여 거듭제곱으로 숫자가 늘어나기 때문에 log2 n만큼 반복된다.
O(n)
선형 시간 복잡도라고 하며, 입력 크기에 비례하여 선형적으로 시간이 소요된다. 대표 알고리즘으로는 선형 탐색, DFS(V + E), BFS(V + E) 등이 있으며, DFS와 BFS의 V + E = N을 의미한다.
예제
int sum = 0;
for (int i = 0; i <= N; i++) {
sum += i;
}상수를 무시하고 1씩 증가하며 입력된 크기와 동일해질때까지 연산을 수행한다.
O(n log n)
선형 로그 시간 복잡도라고 하며, 선형 시간과 로그 시간을 결합한 시간 복잡도이다.
먼저 로그 시간 측면에서 생각해보자. 입력의 절반 또는 일부로 나눌때마다 각 부분을 독립적으로 처리한다. 예를 들어 병합 정렬을 위해 배열을 1개의 요소가 남을 때까지 n/2로 나누어 주는 것을 생각 할 수 있다.
이후 선형 시간 측면에서 배열이 1개의 요소가 남을때까지 분할한 후 정렬을 수행하며 원상태의 배열과 동일한 형태를 형성하기 위해 수행되는 연산이 n번이기 때문에 선형 시간 복잡도를 가진다.
대표하는 알고리즘으로는 퀵 정렬, 병합 정렬, 힙 정렬 등이 있다.
예제
public class MergeSortExample {
public static void main(String[] args) {
int[] arr = {1, 9, 5, 3, 2, 4, 7, 6};
System.out.println("정렬 전 :");
printArray(arr);
mergeSort(arr, 0, arr.length -1);
System.out.println("정렬 후 :");
printArray(arr);
}
// 재귀적으로 배열 분할을 먼저 수행 후 병합 함수 호출
public static void mergeSort(int[] arr, int left, int right) {
if (left < right) {
// n /2 계산
int middle = (left + right) / 2;
// 나누어진 부분으로 재귀적 호출
mergeSort(arr, left, middle);
mergeSort(arr, middle + 1, right);
// 정렬된 절반들을 병합
merge(arr, left, middle, right);
}
}
// 병합 함수
public static void merge(int[] arr, int left, int middle, int right) {
// 두 서브 배열의 크기 계산
int n1 = middle - left + 1;
int n2 = right - middle;
// 임시 배열 생성
int[] leftArray = new int[n1];
int[] rightArray = new int[n2];
// 데이터 복사
for (int i = 0; i < n1; i++)
leftArray[i] = arr[left + i];
for (int j = 0; j < n2; j++)
rightArray[j] = arr[middle + 1 + j];
// 병합 과정
int i = 0, j = 0;
int k = left; // 실제 배열의 인덱스
while (i < n1 && j < n2) {
if (leftArray[i] <= rightArray[j]) {
arr[k] = leftArray[i];
i++;
} else {
arr[k] = rightArray[j];
j++;
}
k++;
}
// 남은 요소들 복사
while (i < n1) {
arr[k] = leftArray[i];
i++;
k++;
}
while (j < n2) {
arr[k] = rightArray[j];
j++;
k++;
}
}
// 배열 출력 함수
public static void printArray(int[] arr) {
for (int num : arr)
System.out.print(num + " ");
System.out.println();
}
}위 코드는 병합 정렬에 대한 코드이다. 먼저 배열을 반으로 나누어 가면서 log2 n의 연산을 수행하여 요소가 1개 남을때까지 배열을 분할한다. 배열 당 요소가 1개가 되면, 배열의 크기 n만큼 다시 병합하며 요소를 정렬한다.
위와 같은 이유로 병합 정렬은 배열을 분할하는 log n번의 연산을 수행하고, 각 단계에서 병합을 위한 n의 시간이 소요되므로 전체 시간 복잡도가 O(n log n)이 된다.
O(n²)
제곱 시간 복잡도라고 하며, 입력 크기의 제곱에 비례하여 시간 소요되기 때문에 데이터가 많아질수록 소요되는 시간이 수직 상승하게된다.
대표적인 알고리즘으로는 버블 정렬, 선택 정렬, 삽입 정렬 등이 있다.
예제
for(int i = 0; i < N; i++) {
for(int j = 0; j < N; j++) {
System.out.println(N[i][j]);
}
}위처럼 이중 반복문을 사용하는 경우 각 원소와 모든 원소를 비교하기 때문에 시간복잡도는 O(n²)이 된다. 하지만 이는 일반적인 상황에서의 시간 복잡도이며, 만약 이중 반복문 내부에 또 다른 시간복잡도를 가진 메서드 또는 함수를 호출한다면 포함하여 계산해야한다.
O(2^n)
지수 시간 복잡도라고 하며, 입력 크기가 증가할 때 실행 시간이 2^n에 비례하여 증가하게 된다. 대표적으로 부분 집합을 모두 생성하는 것과 피보나치 수열 등이 있다.
예제1(부분 집합 생성)
public class SubsetGenerator {
public static void generateSubsets(int[] set, List<Integer> subset, int index) {
if (index == set.length) {
System.out.println(subset);
return;
}
// 현재 원소를 포함하지 않는 경우
generateSubsets(set, subset, index + 1);
// 현재 원소를 포함하는 경우
subset.add(set[index]);
generateSubsets(set, subset, index + 1);
subset.remove(subset.size() - 1);
}
public static void main(String[] args) {
int[] set = {1, 2, 3};
generateSubsets(set, new ArrayList<>(), 0);
}
}크기 n의 집합인 모든 부분집합을 생성해야 하기 때문에 2^n개의 부분집합을 생성해야하므로 O(2^n)이 된다.
예제2(피보나치 수열)
public int fibonacci(int n, int[] r) {
if (n <= 0) return 0;
else if (n == 1) return 1;
else return fibonacci(n - 1, r) + fibonacci(n - 2, r);
}위 함수를 예시로 피보나치의 수열 트리 구조를 보면 다음과 같다.
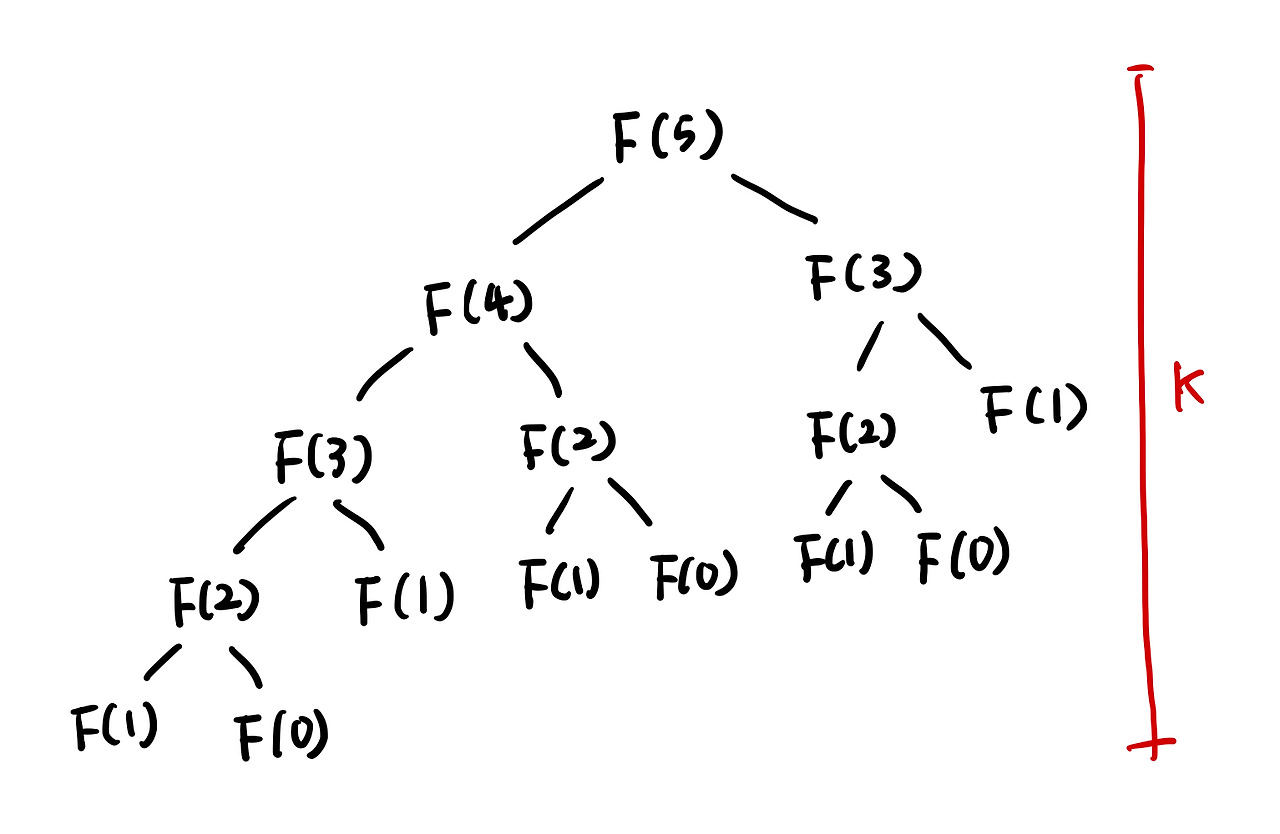
함수 호출 시 2번씩 재귀호출을 한다. 호출은 트리의 높이만큼 반복되기 떄문에 O(2^n의 시간 복잡도를 가지게 된다. 즉 2의 5제곱 만큼 호출을 수행하는 것이다.
지수시간 발생 이유
조합 폭발(Combinatorial Explosion)로 입력 크기에 따라 모든 경우를 탐색하는 데 시간이 지수적으로 늘어나며, 피보나치 수열처럼 재귀 호출을 통한 중복 계산이 이루어지기 때문이다.
지수 시간 복잡도 다루기
- 동적 프로그래밍(Dynamic Programming)
- 중복되는 하위 문제의 결과를 저장 및 재사용하여 시간 복잡도 단축 - 백트래킹(Backtracking)과 가지치기(Pruning)
- 해가 될 수 없는 경로를 조기에 제거하여 탐색 공간 축소 - 근사 알고리즘 및 휴리스틱
- 최적해 대신 근사해를 빠르게 구하는 방법, 지수 시간을 다항시간으로 축소 - 제한된 입력 크기
O(n!)
팩토리얼 시간 복잡도라고 하며, 매우 높은 시간 복잡도로, 일반적으로 비효율적이라고 판단하지만 사용하는 특정 알고리즘이 있다. 예를 들어 순열을 모두 생성하고 분석하는 알고리즘 등에 사용된다.
예제
public class PermutationGenerator {
// 순열 생성 메서드
public static void permute(int[] nums, int l, int r) {
// 좌우가 같으면 완전한 순열이 만들어졌으니 반환
if (l == r) {
System.out.println(Arrays.toString(nums));
} else {
// 좌우가 같아질때까지 반복문 수행
for (int i = l; i <= r; i++) {
swap(nums, l, i);
permute(nums, l + 1, r);
swap(nums, l, i);
}
}
}
// 배열에서 인덱스 i와 j의 요소 교환
public static void swap(int[] nums, int i, int j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
public static void main(String[] args) {
int[] nums = {1, 2, 3}; // 순열 생성을 위한 데이터
permute(nums, 0, nums.length - 1);
}
}위 코드는 순서와 상관없이 조합가능한 순열을 모두 생성하는 알고리즘이다.
재귀와 교환을 통한 순열을 생성하는데 permute()는 현재 위치 1에서부터 끝까지의 요소를 교환하여 모든 가능한 조합을 만들고, 좌우의 인덱스가 같으면 하나의 순열이 완성되어있으니 이를 출력한다.
요소를 교환하여 새로운 순열을 만들 준비를 하고, 재귀 호출 이후에는 교환을 되돌려서 원래 배열 상태로 복구하는 방식으로 동작한다. 여기서 왜 교환을 배열 상태를 복구하는지 궁금할 수 있다.
만약 재귀 호출 이후에 교환을 되돌리지 않는 다면 배열이 변경된 상태로 남아 이후의 순열 생성에 영향을 미치게된다. 이를 방지하기 위해 재귀 호출 전후로 교환을 수행한다.
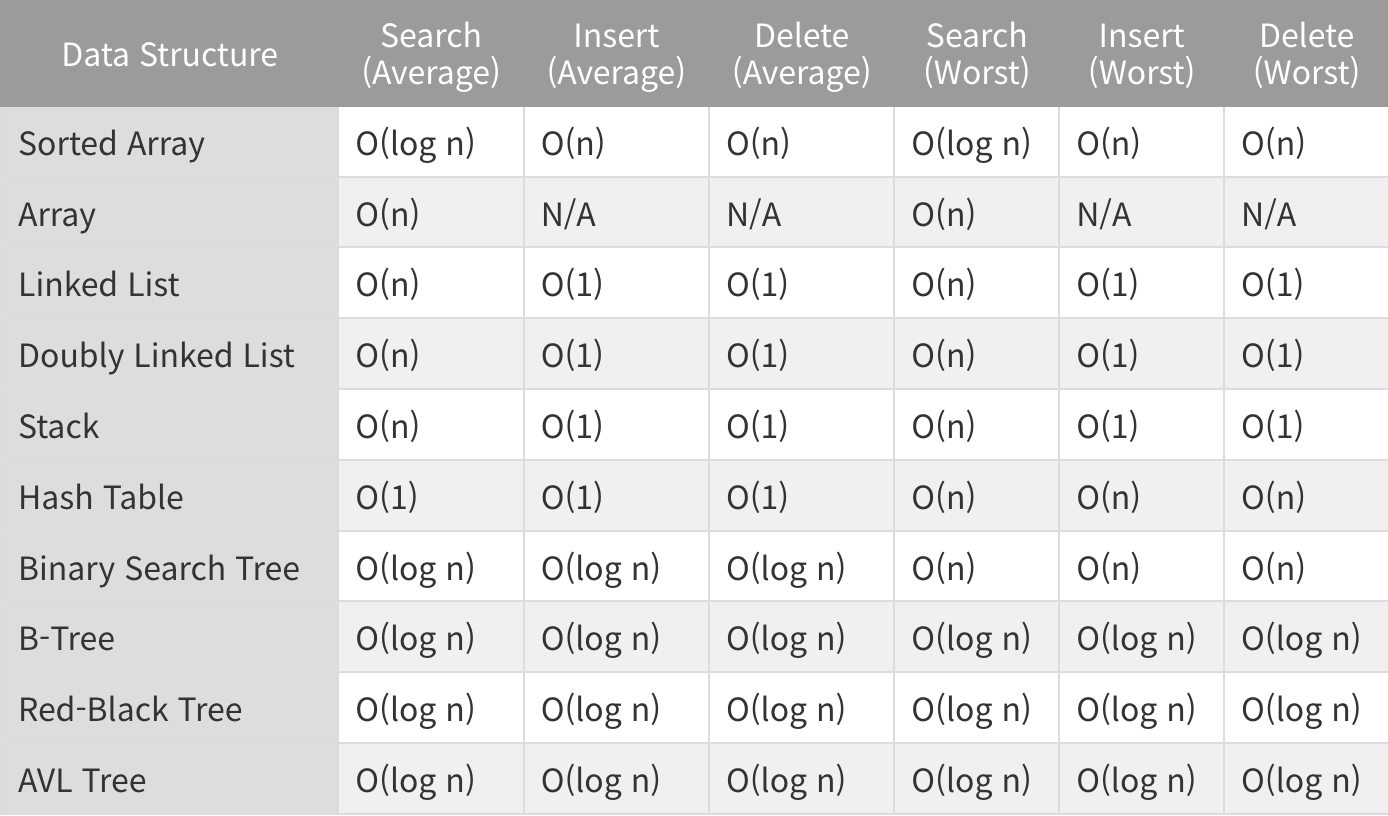
자료 구조별 시간복잡도
자주 사용하는 자료구조에 대한 각 기능의 시간복잡도를 표현한 표이다. 공부할 때 참고하면서 알고리즘 문제를 풀어보도록 하면 좋을 것 같다.