
포스팅 목적
클라이언트로부터 수령한 데이터를 처리하기 위하여 사용된 코드를 분석하고 함수 사용에 대한 적절성을 판단해보자.
데이터 처리 조건
⚡️ 기본조건
- 데이터 형식 : String(48Bytes)
- 기본적으로 1개의 행을 데이터 전달
- 0.2초 간격 통신을 통한 데이터 전달
- 데이터 형태 : '발생시각,기준값,테스트값1,테스트값2,테스트값3,테스트값4\n'
⚡️ 세부조건
- 데이터의 형태 3가지 : 종료 값(NONE), 결과 값, 농도 값
- 다이어그램
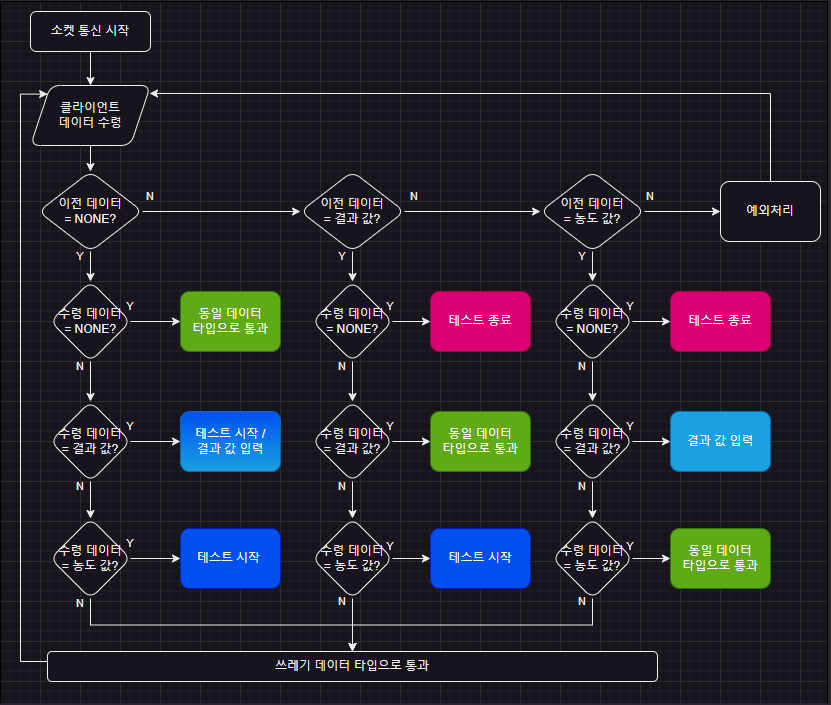
- 예외상황
- 연결의 지연 또는 버퍼의 예기치 못한 지연으로 인한 데이터 뭉침 현상 발생
- 데이터가 중간에 누락되거나 다음 데이터에 포함되어 오는 경우
- 공백데이터가 들어오는 경우
- 데이터 형식이 지정된 형식이 아닌 경우
- 문자열 내부에 공백문자가 포함된 경우
위의 조건들을 고려하여 코드를 작성해보겠다.
🫡 (포스팅을 보시면서 더 효율적이거나 개선해야 할 사항들이 있다면 댓글로 알려주시면 감사드리겠습니다.)🫡
실습
⚡️ 처리 흐름 및 메소드 설명
데이터 수령 -> 데이터 유효성 검증 -> 원본데이터 DB 추가 -> 데이터 가공(배열로 치환) ->
테스트 값별 기존 데이터와 비교 -> 조건별 DB 추가 및 갱신
🖥️ 메소드
# socket_server로부터 데이터를 수령 및 유효성 검증
def save_client_data(self):
# 유효성 검증이 완료된 데이터 분리(문자열 -> 배열)
def _separate_row(self):
# 유효성 검증 간 식별된 불량 데이터 처리
def _handle_bad_row(self):
# 배열로 분리된 각각의 테스트 값 처리
def _handle_test_slot(self):
# 기존 데이터와 현재 데이터 타입별 처리
def _handle_none(self):
def _handle_result(self):
def _handle_number(self):
# DB 처리
def _start_test(self):
def _end_test(self):
def _update_result(self):
def _regist_result(self):
# 비대상 데이터 처리
def _pass_same_data(self):
def _pass_etc_data(self):
# 기존 데이터 세팅
def _set_predata(self):
# 불량 데이터 초기화
def _reset_bad_row(self):작성하고보니 메소드가 상당히 많다. DataHandler 클래스를 하나의 클래스 보다는 2개 이상의 클래스로 분할하고 싶었지만 프로젝트 규모가 작다보니 하나의 클래스에만 작성하게 되었다.
메소드를 작성하며 고려했던 사항들은 다음과 같다.
- 기능 단위 메소드 분할 : 메소드별로 최대한 하나의 기능만을 수행하도록 구성
- 클라이언트 데이터를 수령하는 단계(입구)에서 유효성 검증을 통한 null 또는 불량 데이터 식별
- 최대한 직관적인 메소드명 사용
- 메소드 간의 결합도 최소화
고려사항들을 모두 충족하지는 못했겠지만 그래도 나름대로는 만족하며 테스트를 마무리했기에 각 메소드별 코드를 아래에 공개해 보도록 하겠다.
⚡️ 데이터 수령 및 유효성 검증
🖥️ save_client_data()
def save_client_data(self, client_data):
# 기준 슬롯을 포함한 슬롯의 총 갯수
SLOT_COUNT = 5
# 개행문자를 기준으로 분리 후 결측데이터(공백) 요소 제거
rows = client_data.split('\n')
rows = list(filter(bool, rows))
# 정규 표현식 선언
pattern = fr'^{self._time_pattern},{",".join([self._value_pattern] * SLOT_COUNT)}$'
# rows가 0일 경우 공백 데이터로 판단하여 로그 기록
# rows가 0이면 반복문 미수행
if len(rows) == 0:
socket_logger.info('공백 데이터 통과')
# 식별된 rows만큼 반복문 수행
for row in rows:
# 문자열 내 공백문자 제거
cleaned_row = row.replace(' ', '')
# 대문자 전환
uppercase_row = cleaned_row.upper()
# 정규표현식 검사
is_correct_row = re.match(pattern, uppercase_row)
data_logger.debug(uppercase_row)
if is_correct_row:
# 불량 데이터 발생 후 정상 데이터가 들어올 경우 보유중인 불량데이터 초기화
if len(self._bad_row) != 0:
self._reset_bad_row()
# 각 슬롯별 테스트 값 분리
test_slot_list = self._separate_row(uppercase_row)
self._handle_test_slot(test_slot_list)
# 불량 데이터일 경우
else:
result = self._handle_bad_row(pattern, uppercase_row)
if result != DataHandler.SAVE_BAD_DATA:
test_slot_list = self._separate_row(result)
self._handle_test_slot(test_slot_list)
else:
socket_logger.info('불량데이터 저장 후 통과')
pass해당 메소드는 클라이언트 데이터 최초로 진입하는 입구이다. 개발을 하면서 가장 예외가 많은 상황은 데이터가 null값으로 들어오거나 유효성 검증이 되지 않는 경우들이 많았던 것 같다. 그래서 이러한 상황을 입구에서 확인하고 검증한다면 이후로 메소드별로 분기되어 로직이 수행될 때 발생하는 예외가 줄어들 것이라 판단이 들었다.
유효성 검증 결과를 통해 정상적인 데이터는 다음 로직을 수행하여주고, 불량 데이터는 별도로 처리한 뒤 정상 데이터로 조합이 가능하다면 처리하는 방식으로 진행하였다.
⚡️ 데이터 분리 후 반환
🖥️ _separate_row()
def _separate_row(self, row):
# 구분자를 기준으로 분리
separated_value = row.split(',')
self._excute_time = separated_value[0]
self._excute_time = self._excute_time.replace('T', ' ')
reference_slot = separated_value[1]
test_slot_list = separated_value[2:]
test_slot_list = "{" + ",".join(test_slot_list) + "}"
# 데이터 저장
row = f"'{self._equip_id}', '{self._excute_time}', '{reference_slot}', '{test_slot_list}'"
self._query_handler.insert_row(row)
return separated_value[2:] # 배열에서 감지기 값만 반환여기서 데이터를 한번 저장하는 이유는 Stream의 문제 등 예기치 않은 오류가 발생하여 데이터를 온전히
DB에 저장할 수 없는 경우가 있다. 그런 경우를 대비하여 우선 전체 테스트 값을 저장해주는 것이다. debug를 통해 log를 쌓는 것도 그런 이유에서 수행하는 것이다.
혹시라도 제때 DB 작업을 수행하지 못하여 전달받은 데이터가 증발되는 경우를 방지하는 것도 중요하다.
⚡️ 불량 데이터 처리
🖥️ _handle_bad_row()
def _handle_bad_row(self, pattern, bad_row):
# 인스턴스 변수로 임시보관
if not self._bad_row:
socket_logger.info(f'불량데이터 식별 - {bad_row}')
self._bad_row = bad_row
# 이미 보관중인 불량 데이터가 있는 경우
else:
combined_row = self._bad_row + bad_row
is_row = re.match(pattern, combined_row)
if is_row:
socket_logger.info(f'불일치 데이터 조합 성공 - {combined_row}')
# 불량데이터 초기화 및 행 반환
self._reset_bad_row()
return combined_row
else:
socket_logger.info(f'불일치 데이터 조합 실패 - {combined_row}')
# 불량데이터 누적
self._bad_row = self._bad_row + bad_row
return DataHandler.SAVE_BAD_DATA
return DataHandler.SAVE_BAD_DATA해당 메소드에서는 불량 데이터가 최초로 들어온 경우에는 인스턴스로 보관하고, 그렇지 않은 경우에는 기존 인스턴스 변수에 보관중인 불량데이터와 조합하여 정상적인 데이터로 조합이 된다면 다음 로직을 수행하도록 하였다.
그리고 조합에 실패한 데이터는 한번 더 누적하여 그 다음으로 들어오는 행과 다시 조합하도록 로직을 구성하였다. 최초에는 2번만 누적하도록 하였는데 실제 데이터를 통해 테스트해보니 4~5번까지도 데이터가 나누어지는 경우들이 발생하였다.
항상 개발을 할 때에는 최악의 상황을 가정하는 것이 더욱 유연한 코드를 작성 할 수 있도록 도움을 주는 것 같다.
마지막으로 불량 데이터를 보유하고 있는데 정상적인 데이터가 들어온다면 불량 데이터를 버리는 형태로 처리를 해주었다.
⚡️ 데이터 형태별 처리
🖥️ _handle_test_slot()
def _handle_test_slot(self, test_slot_list):
socket_logger.debug(f'test slot list - {test_slot_list}')
slot_length = len(test_slot_list)
for index in range(slot_length):
pre_slot_value = self._pre_slot_list[index]
new_slot_value = test_slot_list[index].upper()
if pre_slot_value == 'NONE':
self._handle_none(new_slot_value, index)
elif pre_slot_value == 'PASS' or pre_slot_value == 'FAIL':
self._handle_result(new_slot_value, index)
elif re.match(self._number_pattern, pre_slot_value):
self._handle_number(new_slot_value, index)
else:
socket_logger.debug(f'slot{index} 기존 값 오류로 현재 값 대입 - {pre_slot_value} -> {new_slot_value}')
self._pre_slot_list[index] = new_slot_value🖥️ _handle_none()
def _handle_none(self, new_value, index):
if new_value == 'NONE':
self._pass_same_data(new_value, index)
elif new_value == 'PASS' or new_value == 'FAIL':
self._regist_result(new_value, index)
elif re.match(self._number_pattern, new_value):
self._start_test(new_value, index)
else:
self._pass_etc_data(new_value, index)🖥️ _handle_result()
def _handle_result(self, new_value, index):
if new_value == 'NONE':
self._end_test(new_value, index)
elif new_value == 'PASS' or new_value == 'FAIL':
self._pass_same_data(new_value, index)
elif re.match(self._number_pattern, new_value):
self._end_test(new_value, index)
self._start_test(new_value, index)
else:
self._pass_etc_data(new_value, index)🖥️ _handle_number()
def _handle_number(self, new_value, index):
if new_value == 'NONE':
self._end_test(new_value, index)
elif new_value == 'PASS' or new_value == 'FAIL':
self._update_result(new_value, index)
elif re.match(self._number_pattern, new_value):
self._pass_same_data(new_value, index)
else:
self._pass_etc_data(new_value, index)이 부분의 코드는 _handle_test_slot() 메소드 하나에서 작성해도 무방했다. 하지만 가독성을 고려했을 때 이렇게 나누는 것이 조금은 더 직관적이지 않을까하는 생각에 이렇게 작성을 했다.
마무리
여기까지가 이번 포스팅의 내용이다. 뒤에 짜잘한 메소드들은 상황에 따라 달라지고 DB를 처리하는 내용들이기에 생략했다. 혹시 궁금하다면 댓글에 남겨주면 된다!
코드를 작성하며 느낀 부분은 다음과 같다.
- 학원에서 프로젝트를 실습 할 때에는 정규 표현식의 사용을 거의 하지 않고 데이터의 길이를 이용해서 판단했던 것 같다. 정규 표현식은 길이와 형태, 지정한 문자까지 판단 할 수 있어 정확도가 올라간다.
- 메소드를 각 기능별로 분할하고나니 특정 부분을 수정할 경우 해당 메소드의 내용만을 수정하면 된다.
- 하나의 메소드에 코드를 모두 작성해도 되지만 코드를 읽는 사람 입장에서의 가독성을 고려하면 차후 유지보수가 편해진다.
- 변수, 메소드 등에 대한 네이밍이 중요하다. 직관적이면 이해가 빠르다.
이러한 부분들을 앞으로도 계속 생각하는 습관을 가진다면 코드가 더욱 간결하고 깔끔해질 것이라 생각한다.
그럼 이만.
