
dbt (data build tool)
dbt(Data Build Tool)는 SQL로 작성된 데이터 변환 코드를 관리하고 실행하는 오픈 소스 툴이다. ELT(Extract, Load, Transform) 데이터 파이프라인의 'Transform' 단계를 담당한다.
dbt는 기본적으로 SQL을 사용하므로 데이터 분석가와 데이터 엔지니어 모두가 익숙하게 사용할 수 있고, 이를 통해 두 그룹이 함께 작업하기 용이하다.
dbt Labs라는 회사가 상용화하여 현재 $4.2B 가치를 가진 기업이 되었으며, Analytics Engineer 라는 직업이 생길 정도로 전문화되었다.
dbt의 필요성
데이터 복잡성의 증가
기업들은 다양한 출처에서 데이터를 수집하며, 이 데이터를 적절히 다루기 위해서는 복잡한 데이터 파이프라인이 필요하다. dbt는 이러한 복잡한 파이프라인을 구축하고 관리하는 데 필요한 여러 기능을 제공한다.
코드 기반의 데이터 변환
전통적으로 ETL (Extract, Transform, Load) 프로세스를 통해 데이터를 변환하고 저장했지만 최근에는 ELT (Extract, Load, Transform) 프로세스가 더 많이 사용된다. ELT는 먼저 데이터를 원시 형태로 저장한 후 필요에 따라 변환하는 방식이다.
dbt에서는 SQL로 작성된 변환 스크립트를 모델(model)이라고 부르고, 이는 SQL SELECT문을 기반으로 하며, dbt는 이 모델을 이용해 데이터를 변환하고 결과를 저장한다.
dbt의 모델(model)은 SQL을 이용해 스크립트 형태로 구현되고, 실행 시 테이블이나 뷰를 생성한다. 또한 코드 작성 시 Jinja 템플릿을 사용할 수 있고 yml 설정 파일을 통해 변환 유형을 설정할 수 있다. 이를 통해 더 강력하고 유연한 데이터 변환이 가능하다.
Jinja
Python의 텍스트 기반 템플릿 엔진으로
{{ }},{% %}괄호로 감싸서 사용하는 형태이다. HTML, XML 등의 텍스트를 출력하는 것에 사용되며, 동적 콘텐츠를 생성하는 데 사용할 수 있다. Flask와 같은 Python 웹 프레임워크에서 많이 사용되며, Django 템플릿 엔진과 비슷한 문법을 가지고 있다.
변수 치환, 조건문/반복문, 필터 기능을 제공한다.
- 변수
-- {{ }} 괄호 안에 변수명 입력 {{ variable_name }}
- 조건문
<!-- html --> {% if user.is_admin %} <p>Welcome, admin!</p> {% else %} <p>Welcome, {{ user.username }}!</p> {% endif %}
- 반복문
<!-- html --> <ul> {% for user in users %} <li>{{ user.username }}</li> {% endfor %} </ul>
- 필터
<!-- lower 필터로 HELLO를 소문자로 필터링 --> <p>{{ "HELLO"|lower }}</p>
dbt가 지원하는 데이터베이스
아래의 여러 데이터베이스 엔진을 지원한다.
- AlloyDB
- Azure Synapse
- BigQuery
- Databricks
- Dremino
- Postgres
- Redshift
- Snowflake
- Spark
- Startburst & Trino
dbt 구성 요소
dbt_project/
├── dbt_project.yml
├── models/
│ ├── dbt_model.sql
│ └── ...
├── tests/
│ └── ...
├── snapshots/
│ └── ...
├── macros/
│ └── ...
├── analysis/
│ └── ...
├── data/
│ └── ...
└── docs/
└── ...dbt의 구성 요소들은 위와 같은 디렉토리 구조를 따른다.
dbt_project.yml
dbt 프로젝트의 설정 파일로, 프로젝트에 대한 전반적인 설정, 모델의 구성, 패키지 의존성 등을 정의한다.
models
models 디렉토리는 DBT 모델(SQL 파일)을 포함한다. 각 모델은 SQL SELECT 문으로 이루어져 있으며, DBT는 이 SQL을 실행해 데이터를 변환하고 결과가 새로운 테이블이나 뷰로 생성된다. 이 때 생성방식은 사용자가 dbt_project.yml 파일에서 설정한 *materialization 설정에 따라 달라진다.
materialization
dbt에서
materialization은 SQL 쿼리의 결과를 어떻게 데이터 웨어하우스에 저장할지 결정하는 방법을 의미한다. dbt는 다음 네 가지 유형의 materialization을 지원한다.
View: SQL 쿼리의 결과가 데이터 웨어하우스에서 view로 생성된다. View는 실제 데이터를 복사하지 않고 원본 데이터에 대한 참조만 유지하므로, 데이터의 최신 상태를 반영한다. 그러나 매번 쿼리가 실행될 때마다 연산이 필요하기 때문에, 복잡한 쿼리에는 부적합할 수 있다.Table: SQL 쿼리의 결과가 데이터 웨어하우스에서 실제 테이블로 생성된다. 테이블은 원본 데이터를 복사하므로, 데이터의 상태를 그 시점에 고정시킨다. 쿼리 결과를 재사용하거나 대용량 데이터를 처리해야 할 때 유용하다.Ephemeral: 이 유형의 모델은 직접 생성되지 않는다. 대신, 이 모델의 SQL이 참조하는 다른 모델의 SQL에 inline으로 삽입된다. 이렇게 하면 중복 계산을 피하거나, 복잡한 변환 로직을 더 작은 단위로 분리하는 데 유용하다.Incremental: 이 유형의 모델은 이전에 생성된 테이블에 새로운 데이터를 추가한다. 즉, 각 dbt 실행에서 새로운 데이터만을 처리하므로 대용량 데이터를 효율적으로 처리할 수 있다.설정 예시
전체 또는 폴더별로
materialization유형을 설정한다.# dbt_project.yml models: learn_dbt: +materialized: view # 이 프로젝트의 테이블들은 기본적으로 view로 빌드 dim: +materialized: table # dim 폴더 밑에 있는 테이블들은 모두 table로 빌드 src: +materialized: ephemeral # src 폴더 밑에 있는 테이블들은 모두 inline으로 빌드 (임시) analytics: +materialized: table이렇게 설정파일에서 설정할 수도 있고 각 model 파일에 설정할 수도 있다.
이럴 경우 model 파일에 작성된 설정이 우선한다.# model/my_model.sql {{ config(materialized='table') }} WITH src_user_event AS ( SELECT * FROM raw_data.user_event ) SELECT user_id, datestamp, item_id, clicked, purchased, paidamount FROM src_user_event
tests
tests 디렉토리는 데이터 테스트를 위한 SQL 파일을 포함한다.
snapshots
snapshots 디렉토리는 *snapshot을 정의하는 SQL 파일을 포함한다. 스냅샷은 시간이 지남에 따라 변화하는 데이터를 추적하는 데 사용된다.
snapshot
- snapshot을 사용하면 주어진 시간대에서 데이터의 상태를 snapshot을 찍어 데이터의 변화를 관찰할 수 있어 시계열 데이터 분석, 데이터 검증, 또는 데이터의 이력을 추적해야 하는 다른 경우에 유용하다. 예를 들어, 고객 데이터에서 특정 고객의 연락처 정보가 시간이 지남에 따라 어떻게 변화했는지를 알고 싶다면 snapshot을 사용할 수 있다.
- snapshot을 생성하면 dbt는 정해진 스케줄에 따라 snapshot 테이블을 업데이트하며, 각 업데이트는 테이블의 새로운 버전을 기록한다.
- snapshot은 DBT 프로젝트의 snapshots 디렉토리에 SQL 파일로 정의되며, 이 파일에는 snapshot 대상 테이블과 snapshot 방식을 정의한다. snapshot 방식에는
timestamp방식과check방식이 있으며, 각각 시간 기반과 데이터 값 기반의 스냅샷을 제공한다.snapshot 파일 예시
check방식 사용 :check_cols에phone이 포함되어 있으므로, 이 두 필드 중 하나가 변할 때마다 새로운 snapshot이 생성된다.{% snapshot customer_snapshot %} {% strategy 'check' %} target_schema: my_schema target_table: customer_snapshot unique_key: customer_id check_cols: - email - phone {% endstrategy %} SELECT customer_id, email, phone, created_at FROM raw.customers {% endsnapshot %}
macros
macros 디렉토리는 재사용 가능한 SQL *snippet을 포함한다. 매크로는 복잡한 SQL 로직을 캡슐화하거나, 반복적인 코드를 줄이는 데 사용된다.
snippet
- dbt에서 snippet은 매크로(macro)라고 불리며, 재사용 가능한 SQL 코드 조각이다. 매크로는 복잡한 SQL 로직을 캡슐화하거나, 반복적인 코드를 줄이는 데 사용된다.
- 매크로는 DBT 프로젝트의 macros 디렉토리에 저장되며, Jinja 템플릿 언어를 사용해 정의된다. 매크로는 다른 SQL 파일에서
{% macro_name %}형식으로 호출할 수 있다.공백 제거를 수행하는 snippet 파일 예시
-- macros/clean_whitespace.sql {% macro clean_whitespace(column_name) %} TRIM(BOTH ' ' FROM {{ column_name }}) {% endmacro %}이 매크로는 TRIM 함수를 사용해 지정된 컬럼의 앞뒤 공백을 제거한다.
다른 SQL 파일에서 사용하려면 다음과 같이 호출하면 된다.-- models/my_model.sql SELECT customer_id, {{ clean_whitespace('first_name') }} AS first_name, {{ clean_whitespace('last_name') }} AS last_name FROM raw.customers
analysis
analysis 디렉토리는 데이터 분석에 사용되는 SQL 스크립트를 포함한다. 이 SQL 스크립트는 DBT 프로젝트의 일부로 유지되지만, dbt 실행 도중에는 사용되지 않는다.
data
data 디렉토리는 dbt Seed 기능을 사용해 데이터 웨어하우스에 로드되는 데이터 파일(csv, yaml 등)을 포함한다.
docs
docs 디렉토리는 dbt 프로젝트의 문서화를 위한 파일을 포함한다. dbt는 이 파일을 이용해 데이터 웨어하우스의 스키마, 테이블, 컬럼 등에 대한 문서를 생성할 수 있다.
dbt는 어떻게 작동할까?
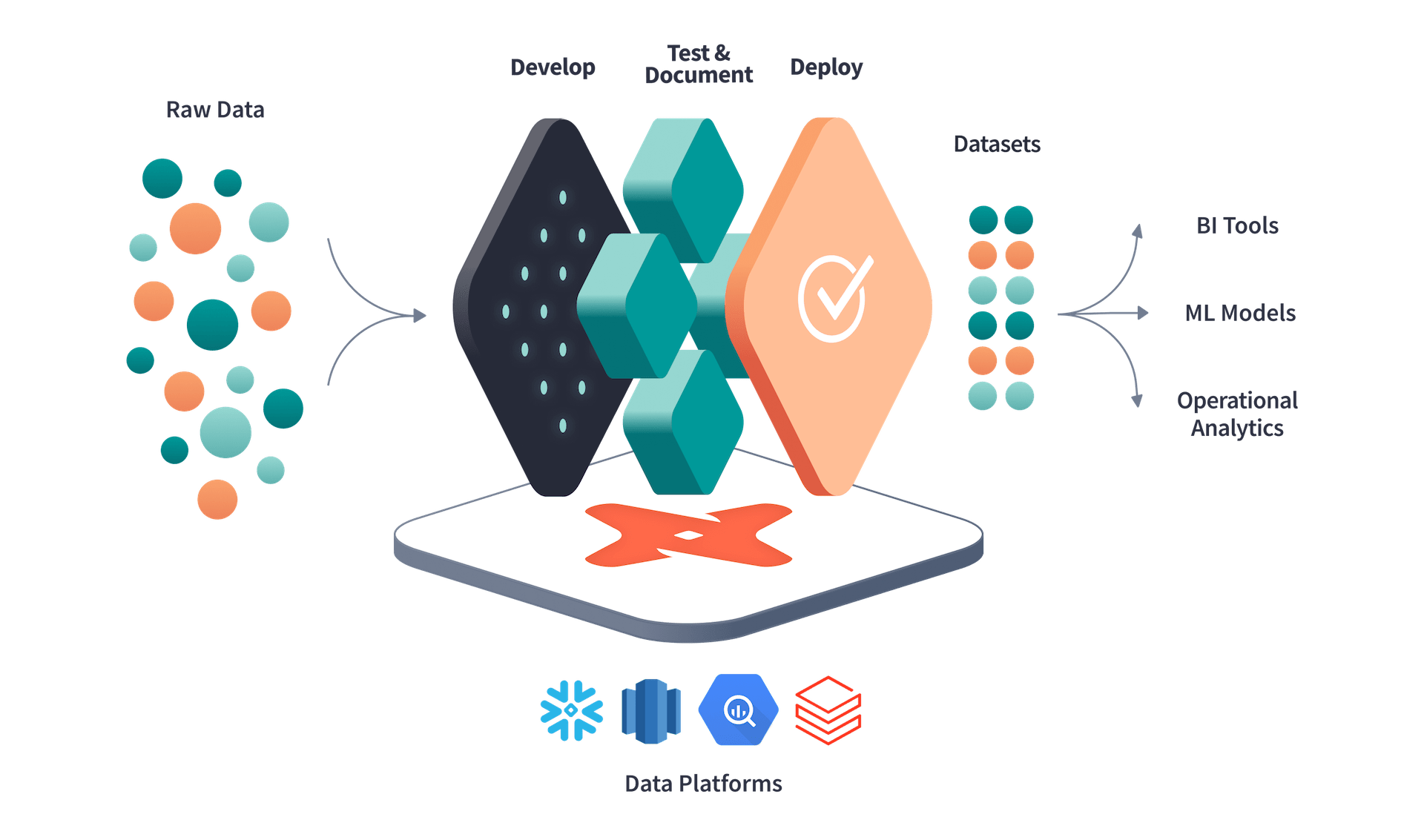
1. SQL 스크립트와 설정 파일 작성
사용자는 SQL로 데이터 변환 작업을 작성하고, YAML로 dbt 프로젝트의 설정을 정의한다. SQL 파일들은models 디렉토리에 저장되며, 각 파일은 하나의 dbt 모델을 정의한다.
2. Jinja 템플릿 처리
dbt가 각 SQL 파일을 Jinja 템플릿 엔진을 통해 처리한다. 이 과정에서 모델 파일에 포함된 매크로, 변수, 조건문, 반복문 등이 실행되어 최종 SQL 쿼리가 생성된다.
3. dbt 실행
사용자가 터미널에서 dbt 명령을 실행한다. 가장 일반적인 명령은 dbt run 과 dbt test 이다.
dbt run : 모델을 실행하여 웨어하우스에 결과를 저장
dbt test : 데이터 테스트 실행
4. Materialization 적용
dbt는 설정에 따라 각 모델의 결과를 적절히 물리화한다. 예를 들어, 모델이 view로 설정된 경우, SQL 쿼리의 결과는 데이터 웨어하우스의 view로 생성된다.
5. 데이터 웨어하우스에서 쿼리 실행
dbt가 최종 SQL 쿼리를 데이터 웨어하우스로 보내 실행한다. 이로 인해 생성된 테이블이나 뷰는 후속 쿼리에 사용될 수 있다.
6. 테스트 실행
dbt test 명령어를 통해 데이터 품질 테스트를 수행한다. 테스트 정의는 YAML 파일을 따른다.
7. 문서화
dbt docs generate 명령어를 통해 dbt는 프로젝트의 문서화를 자동으로 생성한다. 이는 모델, 테스트, 소스 데이터 등에 대한 설명과, 이들 간의 관계를 시각적으로 표현하는 DAG(Directed Acyclic Graph)를 포함한다.
dbt는 이런 단계들을 거치면서 SQL 스크립트와 설정 파일을 기반으로 데이터 파이프라인의 전체 수명 주기를 관리하는 역할을 한다.
