
🧐
Spotify API로 데이터를 가져와 K-POP 인기를 분석하고 데이터를 시각화하는 프로젝트를 진행하고 있었는데, API로는 우리가 원하는 시점의 데이터를 가져올 수 없었다.(못찾은 걸수도?ㅎㅎ)
그래서 어떻게 해야할지 찾아보던 중, Spotify chart 페이지에서 국가별로 주간/일별 Top 200 데이터를 csv 파일로 제공해준다는 것을 알게되었다! (아티스트나 앨범 차트는 csv파일 다운로드 지원이 되지 않는다.)
대륙별로 총 11개 국가를 선정해서 3년간의 차트 데이터를 Selenium을 사용해서 csv파일로 다운받을 수 있었다.
Spotify Charts
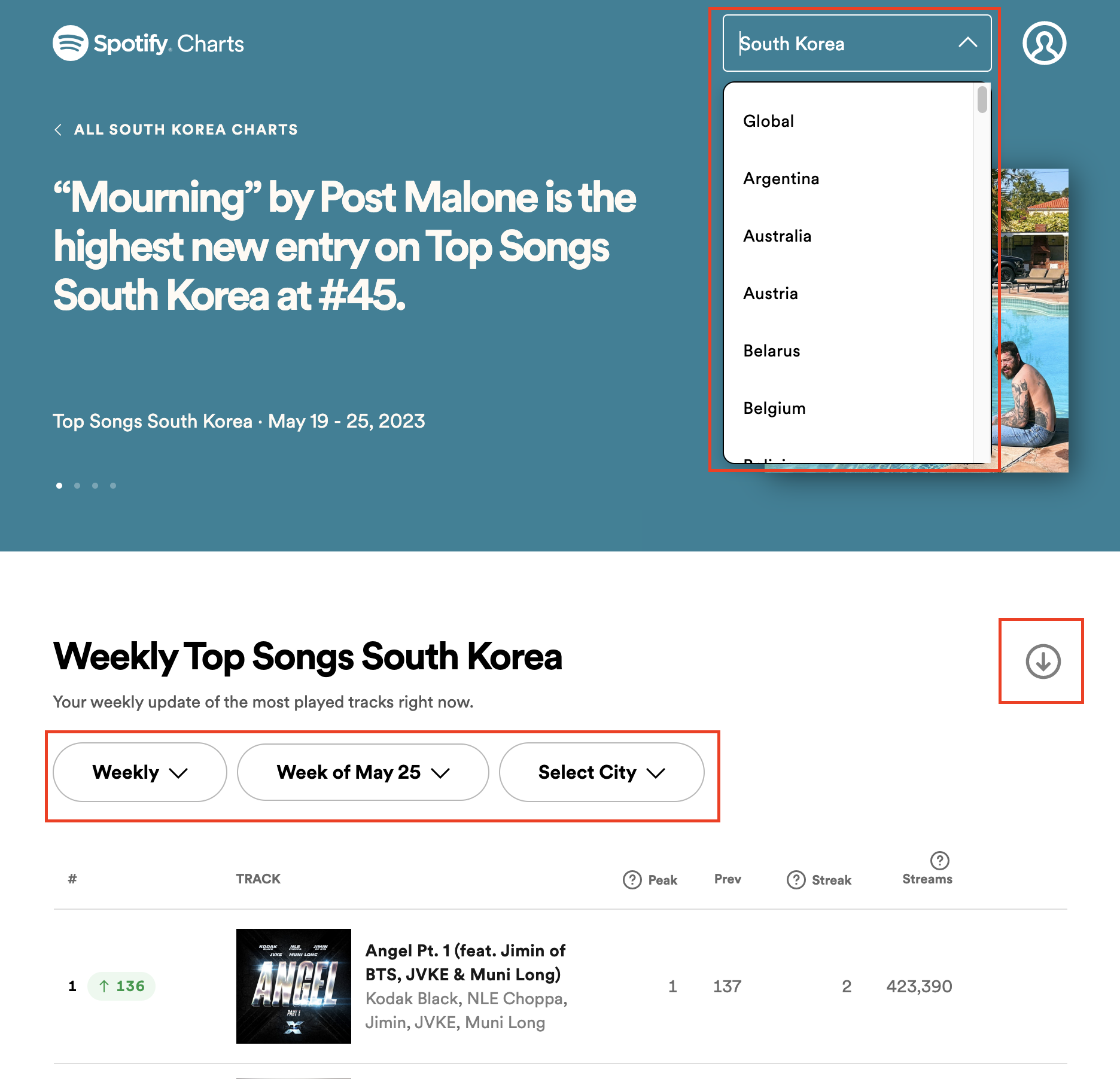
Spotify chart 는 로그인을 해야 사용이 가능하다.
오른쪽 상단 콤보박스에서 국가를 선택할 수 있고 주/일별 어떤 날짜의 차트를 가져올 지 선택할 수 있다. 도시별로도 가능한 게 굉장히 디테일하다고 느꼈다.
그리고 저 조그마한 버튼이 csv 파일 다운로드 버튼이다. UI가 바뀌기 전에는 좀 더 직관적이었는데 너무 미니멀해져서 알아보기 어려워졌다..
URL
Weekly Top 200 차트의 URL은 다음과 같이 깔끔하게 국가코드와 일자를 포함하고 있어 URL을 적절히 변경해주면서 Selenium으로 csv 파일을 다운로드하면 되겠다고 생각했다.
https://charts.spotify.com/charts/view/regional-{국가코드}-weekly/{일자}
Selenium으로 크롤링
Jupyter notebook을 사용하여 진행했다.
국가별 3년간의 weekly top 200 차트 데이터 csv파일 다운로드
파일 다운로드를 위해서는 chrome webdriver option에 다운로드 할 디렉토리를 설정해야한다.
국가 코드와 일자들을 리스트에 넣고 순환문을 돌려 csv파일을 각 조건에 맞게 모두 다운로드했다.
중간에 2번정도 NoSuchElementException 이 났는데, 화면이 전환되고 대기시간을 충분히 주지 않아 발생한 것이라 더 늘려주어 해결했다.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
import time
from datetime import datetime, timedelta
options = webdriver.ChromeOptions() ;
prefs = {"download.default_directory" : "/Users/ohyujeong/Downloads/spotify_files/"};
options.add_experimental_option("prefs",prefs);
# 미국, 호주, 태국, 베트남, 인도, 프랑스, 독일, 일본, 대만, 덴마크, 스위스
countries = ['us','au','th','vn','in', 'fr','de','jp','tw','dk','ch']
dates = []
# (오늘일자-5일)로부터 3년간 weekly 날짜 가져오기
current_date = datetime.now() - timedelta(days=5)
end_date = current_date - timedelta(days=(3 * 365))
while current_date >= end_date:
date_string = current_date.strftime("%Y-%m-%d")
dates.append(date_string)
current_date -= timedelta(weeks=1)
with webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options) as driver:
driver.get("https://charts.spotify.com/charts/view/regional-global-weekly/latest")
time.sleep(2)
# 로그인 필요함
login_button = driver.find_element(By.XPATH, '//*[@id="__next"]/div/div/main/div[2]/div/header/div/div[2]/a[3]/div[1]')
login_button.click()
# 로그인 화면 진입
id_input = driver.find_element(By.XPATH, '//*[@id="login-username"]').send_keys('아이디')
password_input = driver.find_element(By.XPATH, '//*[@id="login-password"]').send_keys('비밀번호')
login_button = driver.find_element(By.XPATH, '//*[@id="login-button"]')
login_button.click()
time.sleep(5)
# CSV 파일 다운로드
for country in countries:
for date in dates:
driver.get(f"https://charts.spotify.com/charts/view/regional-{country}-weekly/{date}")
time.sleep(2)
csv_download_button = driver.find_element(By.XPATH, '//*[@id="__next"]/div/div/main/div[2]/div[3]/div/div/a/button')
csv_download_button.click()다운로드한 csv파일들을 통합
다운로드 받은 데이터의 uri 값에 track_id 가 포함되어 있어 track_id만을 가져오고자 pandas로 변환하였다. 그리고 파일명에 국가와 일자정보가 있어 파일명을 기반으로 국가명과 일자 정보를 추출하여 데이터에 추가하였다.
파일이 많아서 엄청 오래걸릴줄 알았는데 생각보다 빨리 끝났다.
통합된 데이터를 확인해보니 3만개 정도 들어있었다.
import pandas as pd
import os
# 통합 csv dataframe 생성
header = ['rank','track_id','artist_names','track_name','source','peak_rank','previous_rank','weeks_on_chart','streams', 'country_code','date']
combined_df = pd.DataFrame(columns=header)
# 파일명을 기반으로 국가명과 일자 정보를 추출하여 데이터에 추가
directory = '/Users/ohyujeong/Downloads/spotify_files/'
for filename in os.listdir(directory):
if filename.endswith('.csv'):
file_path = os.path.join(directory, filename)
_, country, _, year, month, day = filename.split('-')
print(country, year, month, day.split('.')[0])
# 기존 데이터 로드
df = pd.read_csv(file_path)
# uri에서 track_id만 추출하여 컬럼명 변경하여 저장
df['uri'] = df['uri'].str.split(':').str[-1]
df.rename(columns={'uri': 'track_id'}, inplace=True)
# 국가명과 일자 정보 추가
df['country_code'] = country
df['date'] = datetime(int(year), int(month), int(day.split('.')[0]))
# DataFrame을 통합
combined_df = pd.concat([combined_df, df], ignore_index=True)
print(filename)
# 수정된 데이터를 새로운 파일로 저장
directory = '/Users/ohyujeong/Downloads/spotify_result/'
new_filename = "weekly_top200_combined.csv"
new_file_path = os.path.join(directory, new_filename)
combined_df.to_csv(new_file_path, index=False)