Redshift에서 데이터를 가져와서 Superset으로 대시보드 만들기

🤷♀️
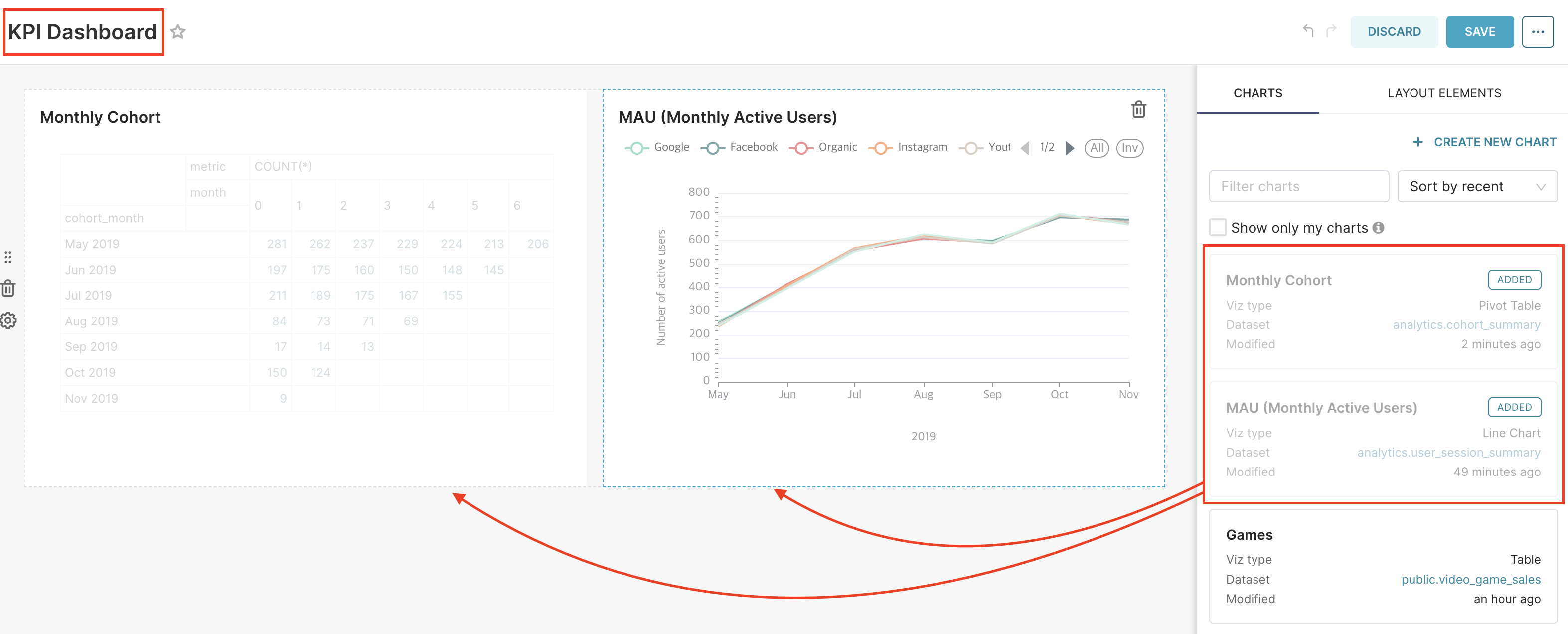
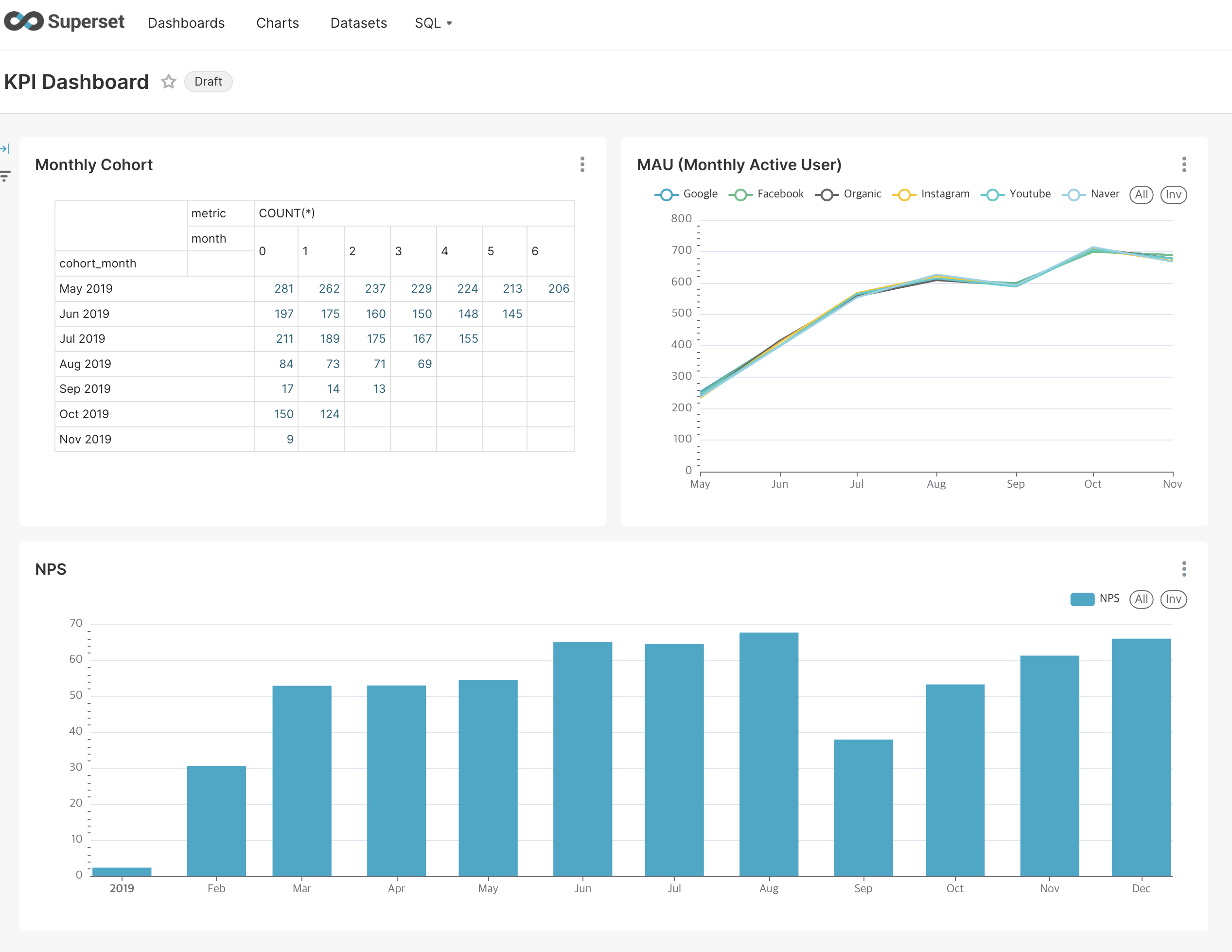
Redshift를 데이터베이스로 사용하고 Superset에서 Redshift를 연결하여 데이터를 가져와 그 데이터를 바탕으로 차트(pivot table, line chart, column chart)를 생성하고 아래와 같은 대시보드를 만들어본다.
Docker를 기반으로 Superset을 설치하여 진행하기 때문에 Docker를 설치가 되어있어야 한다.
Docker 설치
Docker desktop을 설치해야한다.
https://www.docker.com/
홈페이지에 바로 OS별로 설치파일이 있어 각 컴퓨터 사양별로 고르면 된다. Mac은 인텔칩, 애플칩으로 나뉜다.Docker 기반 Superset 설치
적당한 위치에 Superset의 Github repository를 clone한다.
git clone https://github.com/apache/superset.git생성된
superset폴더로 진입힌다.cd superset
docker-compose로 superset을 launch한다.
Docker가 background에서 실행되고 있는 상태여야한다.docker-compose -f docker-compose-non-dev.yml pull docker-compose -f docker-compose-non-dev.yml up컨테이너가 모두 실행되고 나면
http://localhost:8088로 Superset을 사용할 수 있다.참고
https://superset.apache.org/docs/installation/installing-superset-using-docker-compose/
Superset 알아보기

Airbnb에서 시작된 오픈소스로, Aiflow(이것도 Airbnb에서 개발함..)를 개발한 Maxim이란 개발자가 시작하였다.
현재 Airbnb의 전사 Dashboard로 사용되고 있으며 Preset이라는 서비스명으로 상용화 서비스도 시작되었다. (Maxim이 직접 창업하였다.)
특징
- 다양한 형태의 Visualization와 손쉬운 인터페이스 지원
- Dashboard 공유 지원
- 엔터프라이즈 수준의 보안과 권한 제어 기능 제공
- SQLAlchemy와 연동
- 다양한 데이터베이스 지원
- Druid.io와 연동하여 실시간 데이터의 시각화도 가능
- API와 플러그인 아키텍처 제공으로 인한 확장성이 좋음
구조
Flask와 React JS로 구성되어 있고 sqlite를 메타데이터 DB로 사용한다. Redis를 캐싱 레이어로 사용하며 SqlAlchemy가 백엔드 DB 접근에 사용되어 SqlAlchemy URI로 DB 연결이 가능하다.
Database / Dataset
Database 는 데이터를 가져올 관계형 데이터베이스, 즉 이 실습에서는 Redshift를 의미하고 Dataset 은 테이블을 의미한다.
Dashboard / Chart
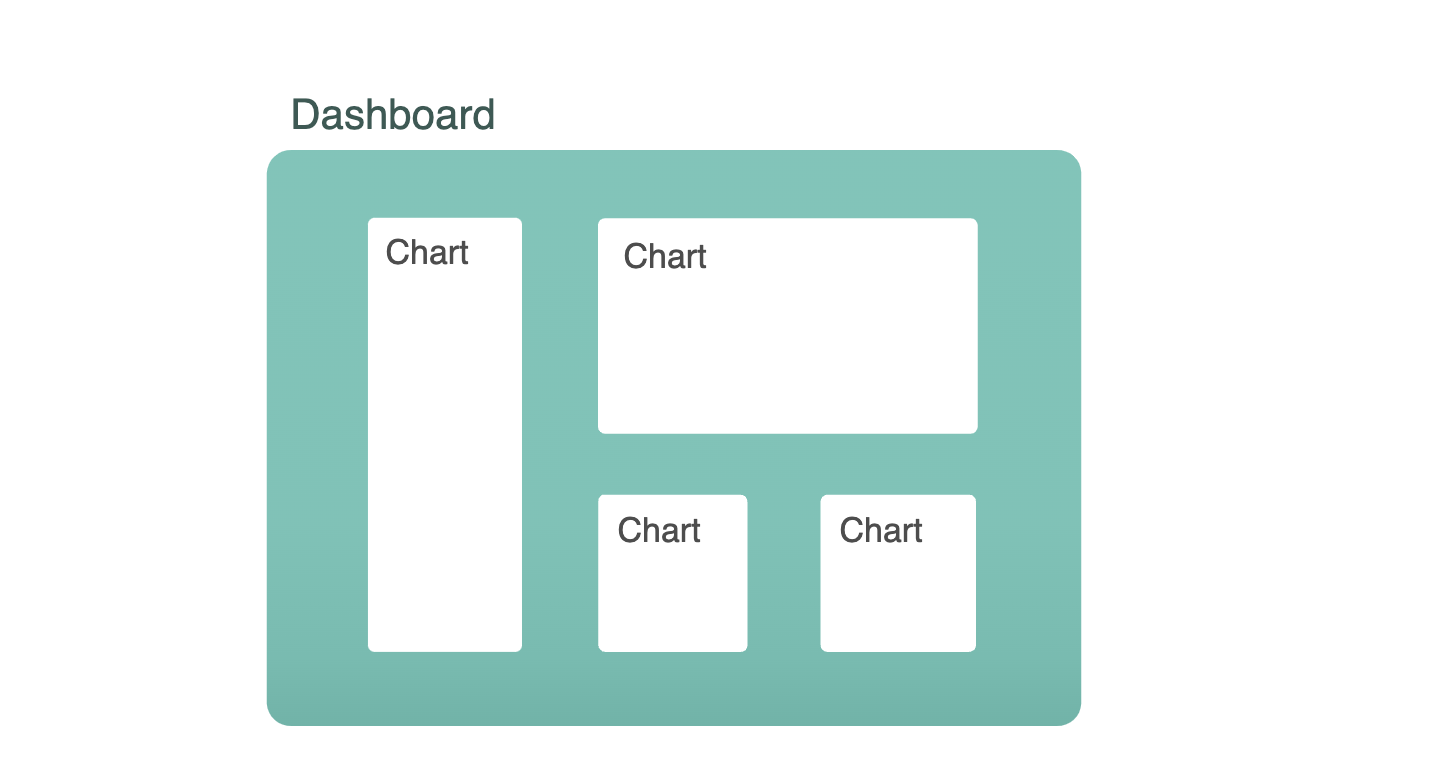
Dashboard 는 하나 이상의 Chart 로 구성되어 있으며, Chart 는 Dataset 으로부터 데이터를 가져와 생성된다.
1. 데이터베이스 연결
Superset의 초기 계정 정보는 ID와 PW모두 admin이다.
ID : admin
PW : admin
로그인 후 데이터베이스 연결을 위해 Settings 메뉴에서 Database Connections 에 진입한다.
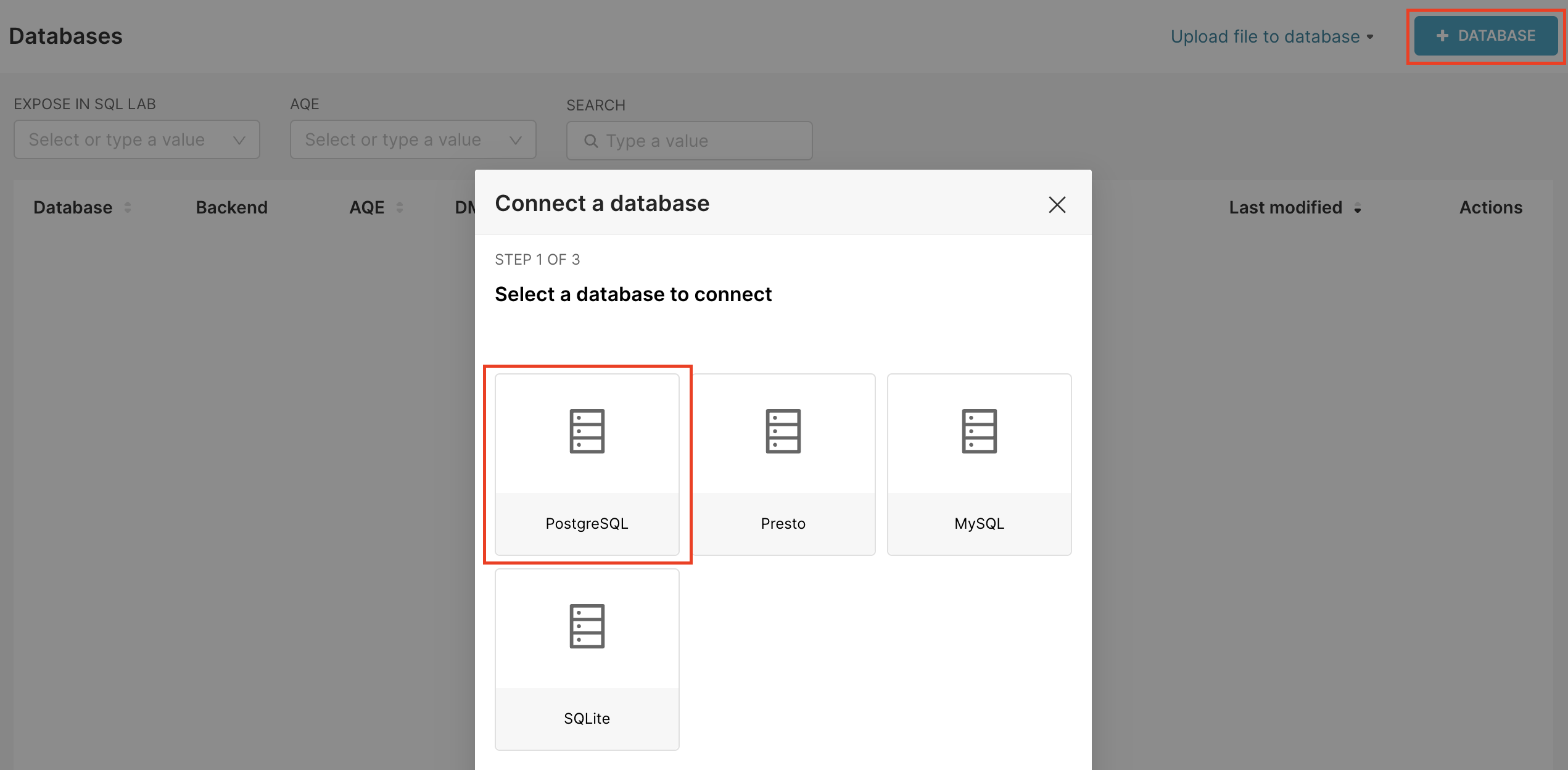
Superset은 따로 Redshift라고 데이터베이스 선택에서 명시되어 있지 않으므로 호환이 되는 Postgresql을 선택한다.
연결정보를 입력한다.
HOST : AWS Redshift의 Workgroup에 있는 Endpoint를 복사해온다.
PORT : 기본 Redshift의 포트인 5439를 입력한다.
DATABASE NAME : AWS Redshift의 Namespace에 있는 Database name을 가져온다.
USERNAME : 사용할 DB계정 사용자명을 입력한다.
DISPLAY NAME : Superset에서 보여질 데이터베이스 별명이다.
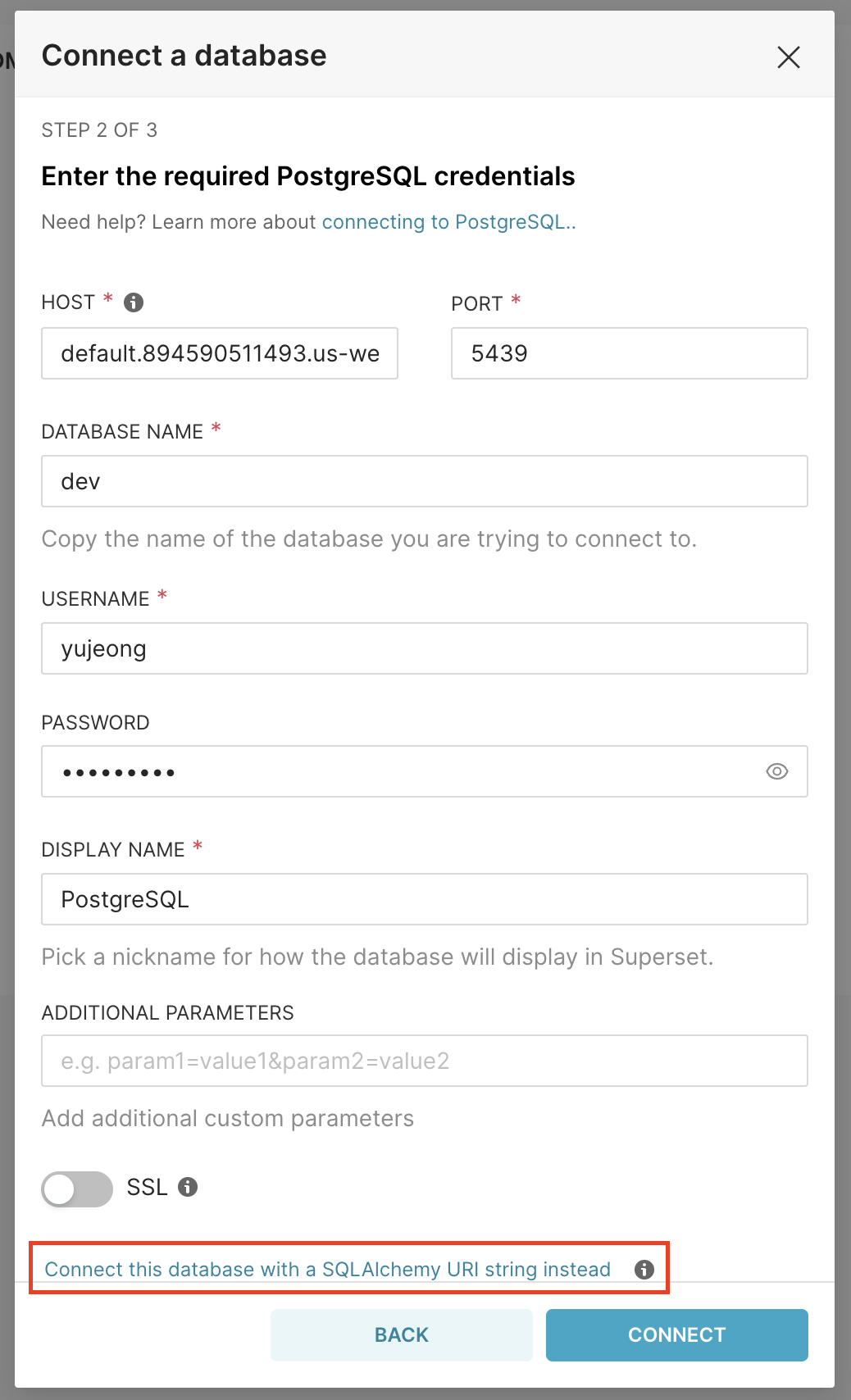
이렇게 연결 정보를 나누어서 입력할 수도있고 표시된 링크를 타고 들어가 SQLAlchemy URI로 입력하여 연결할 수도 있다. Display name은 알아보기 쉽도록 Redshift로 변경하자. TEST CONNECTION 으로 연결을 확인한다.
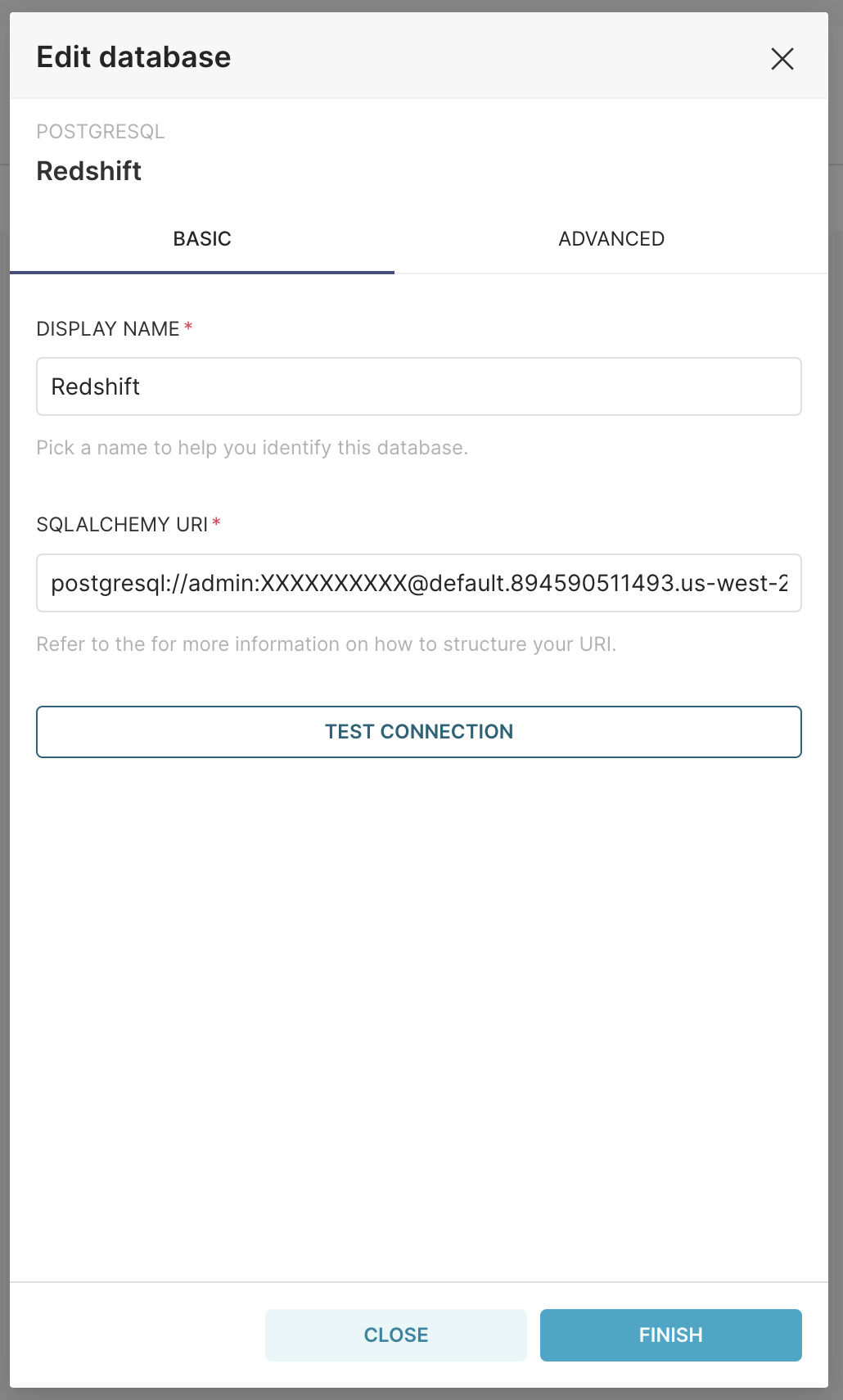
연결정보 입력을 완료하면 데이터베이스 연결이 이루어진 것을 확인할 수 있다.

2. Dataset 생성
Dataset 탭을 선택하여 dataset을 생성한다.
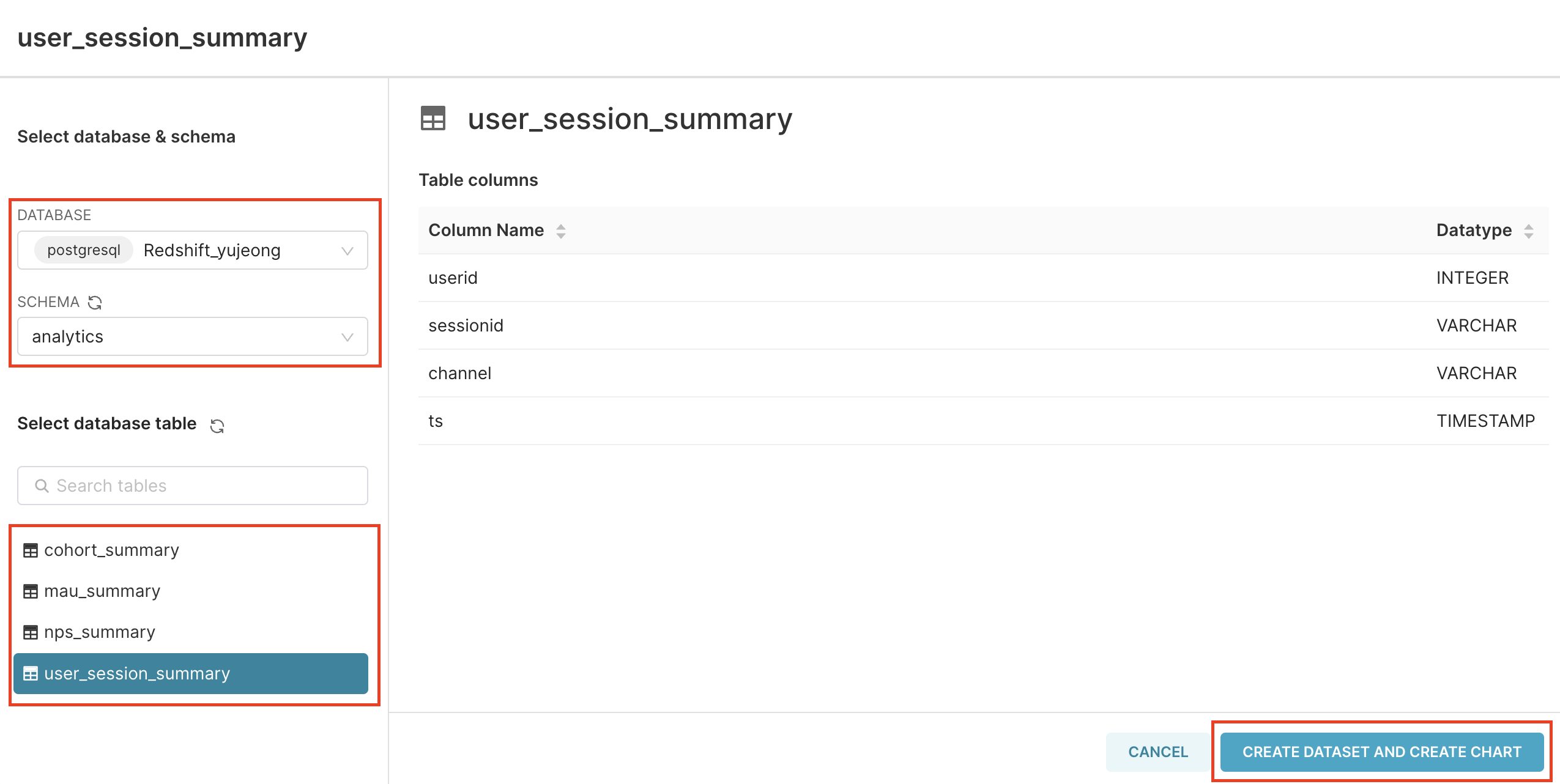
전에 연결한 Database를 찾아 선택하면 Schema를 불러와준다.
차트를 생성할 때 사용할 테이블을 선택하여 dataset을 생성하고 chart를 생성하는 화면으로 이동한다.
이 부분에서 좀 의아했던 것은 superuser인 admin계정으로 연결했을 때는 후에 Dataset을 만들 때 schema를 불러오는 부분에서 에러가 발생했다.
그래서 계정 정보를 일반 User로 변경하고 나서 시도해보니 Schema가 정상적으로 불러와졌다. 🤔 왜지,,?
3. Chart 생성
chart의 종류를 선택하고 생성한다.
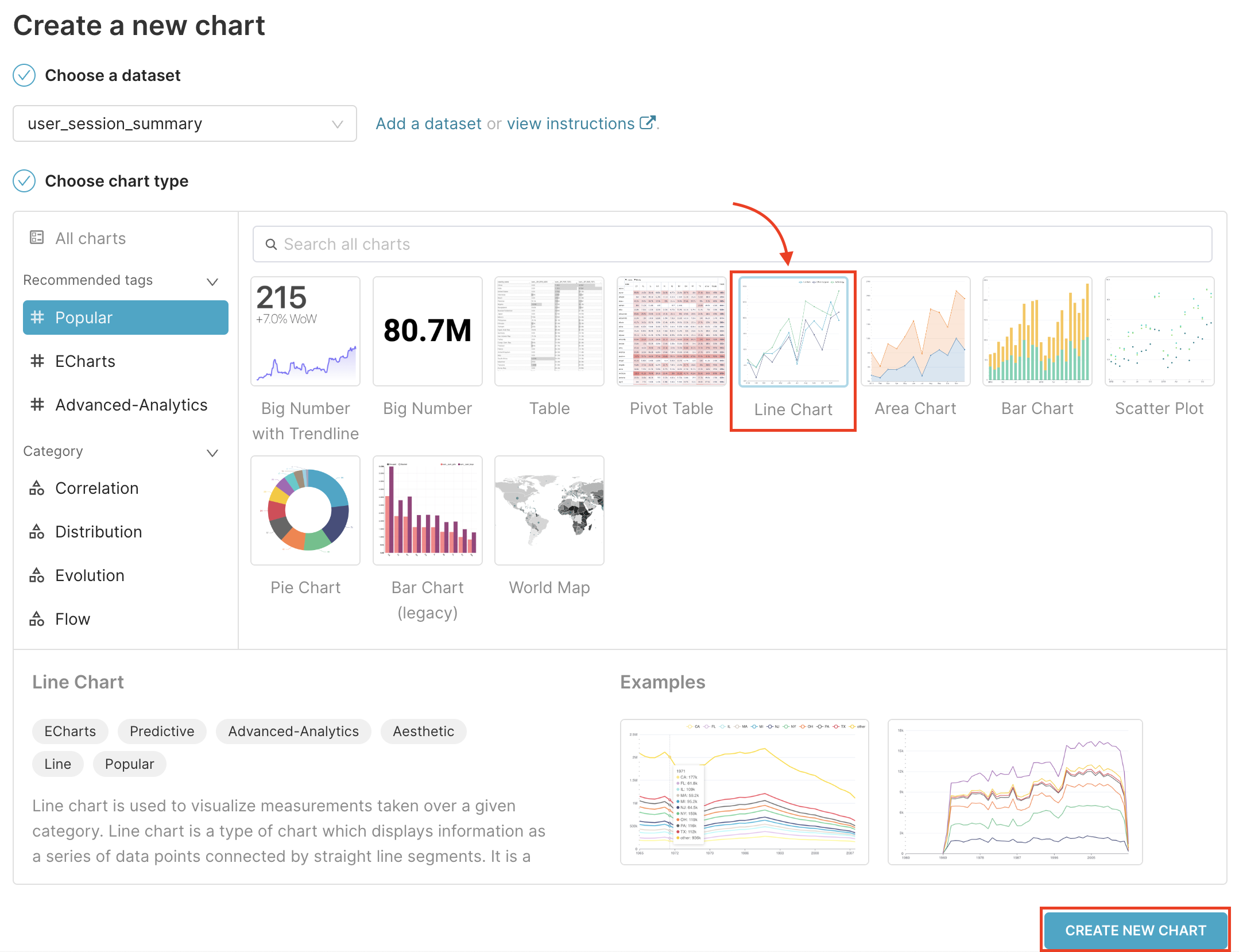
Line Chart
chart의 제목을 설정하고 x축과 y축 등 chart의 세부 정보를 설정한다.
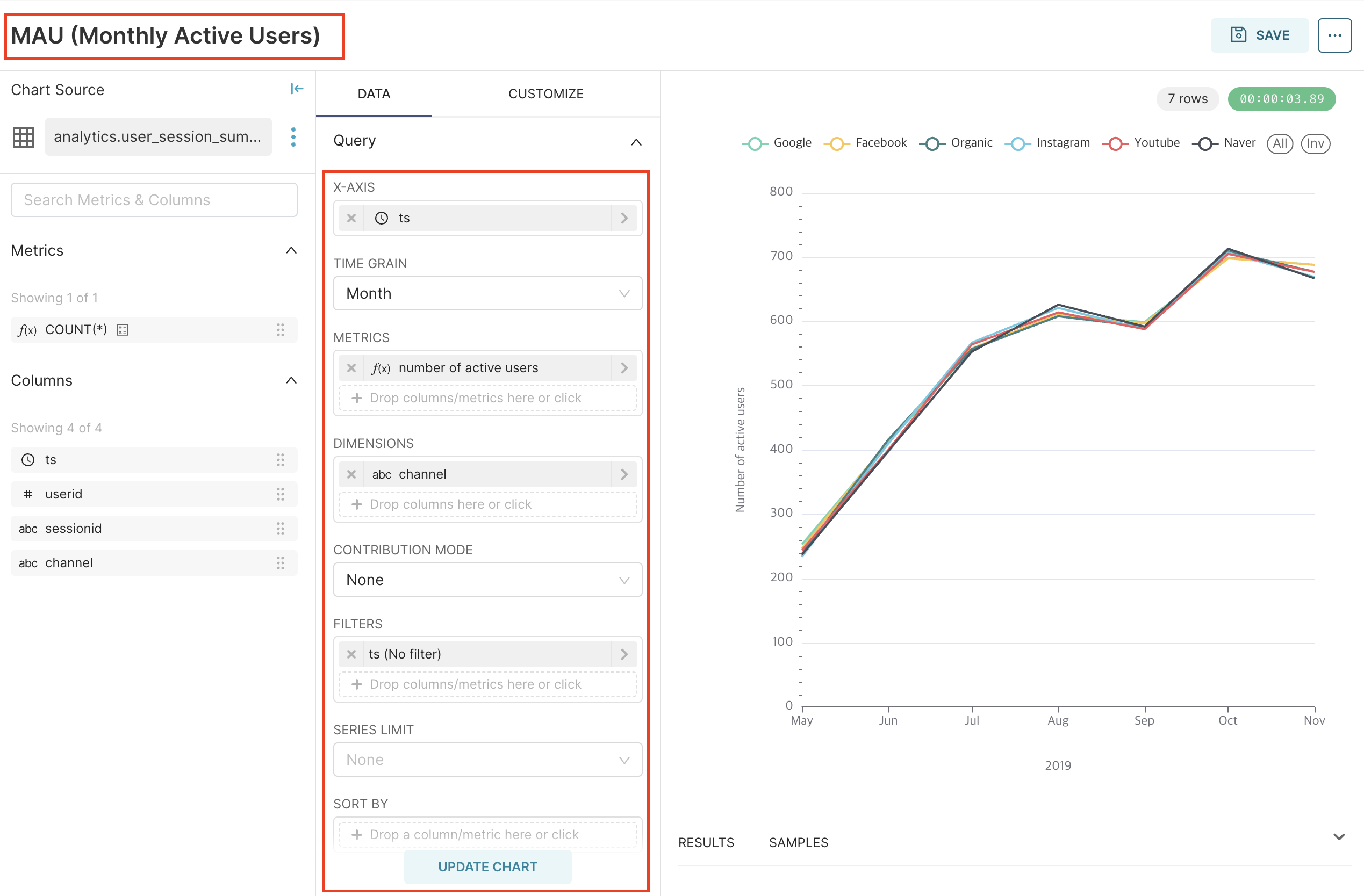
X-AXIS : x축을 어떤 컬럼값으로 할 것인지 선택한다.
TIME GRAIN : 어떤 시간별로 데이터를 묶을지 선택한다.
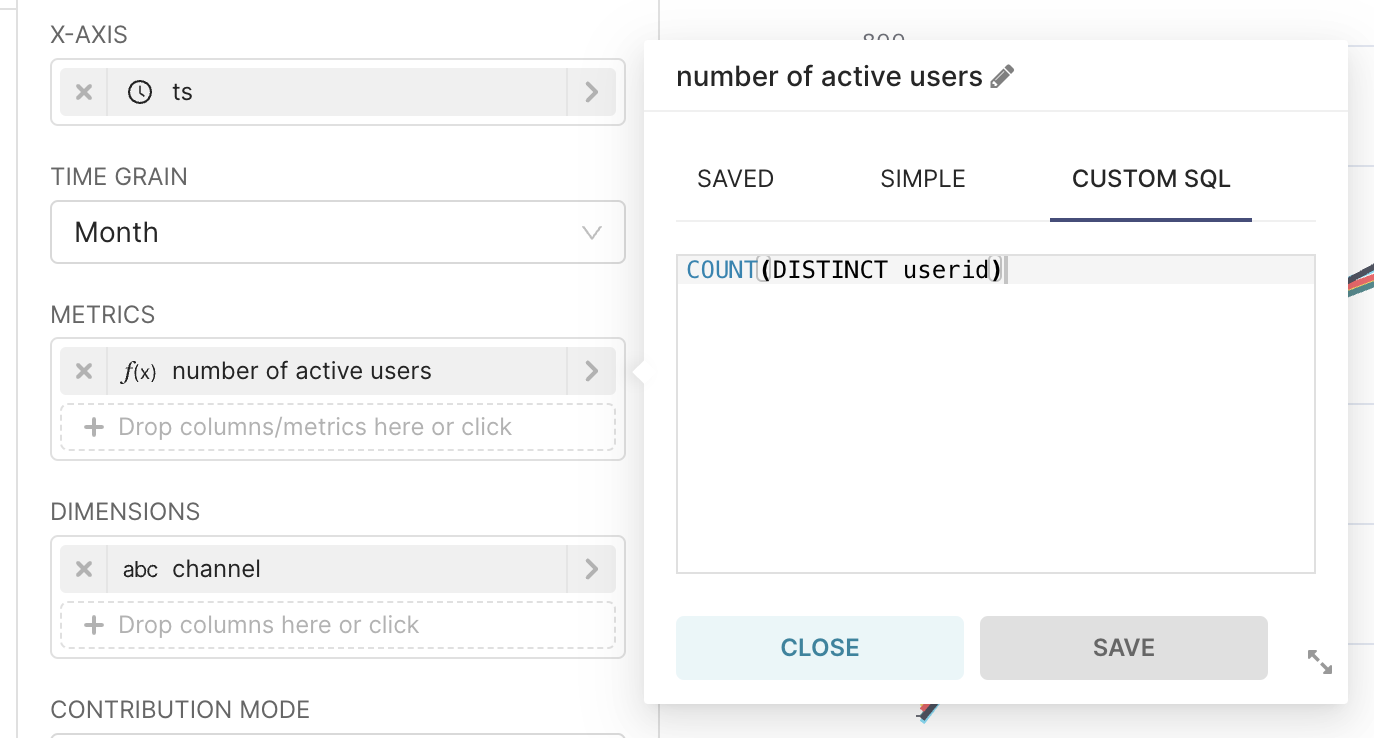
METRICS : y축에 표시될 데이터를 설정한다. 사용자의 수를 가져와야 하는데 현재 사용하고 있는 테이블의 경우 사용자의 수를 가져올 때 사용하는 userid 컬럼값이 중복되어 아래와 같이 CUSTOM SQL 로 별도 처리를 해주어야 한다.
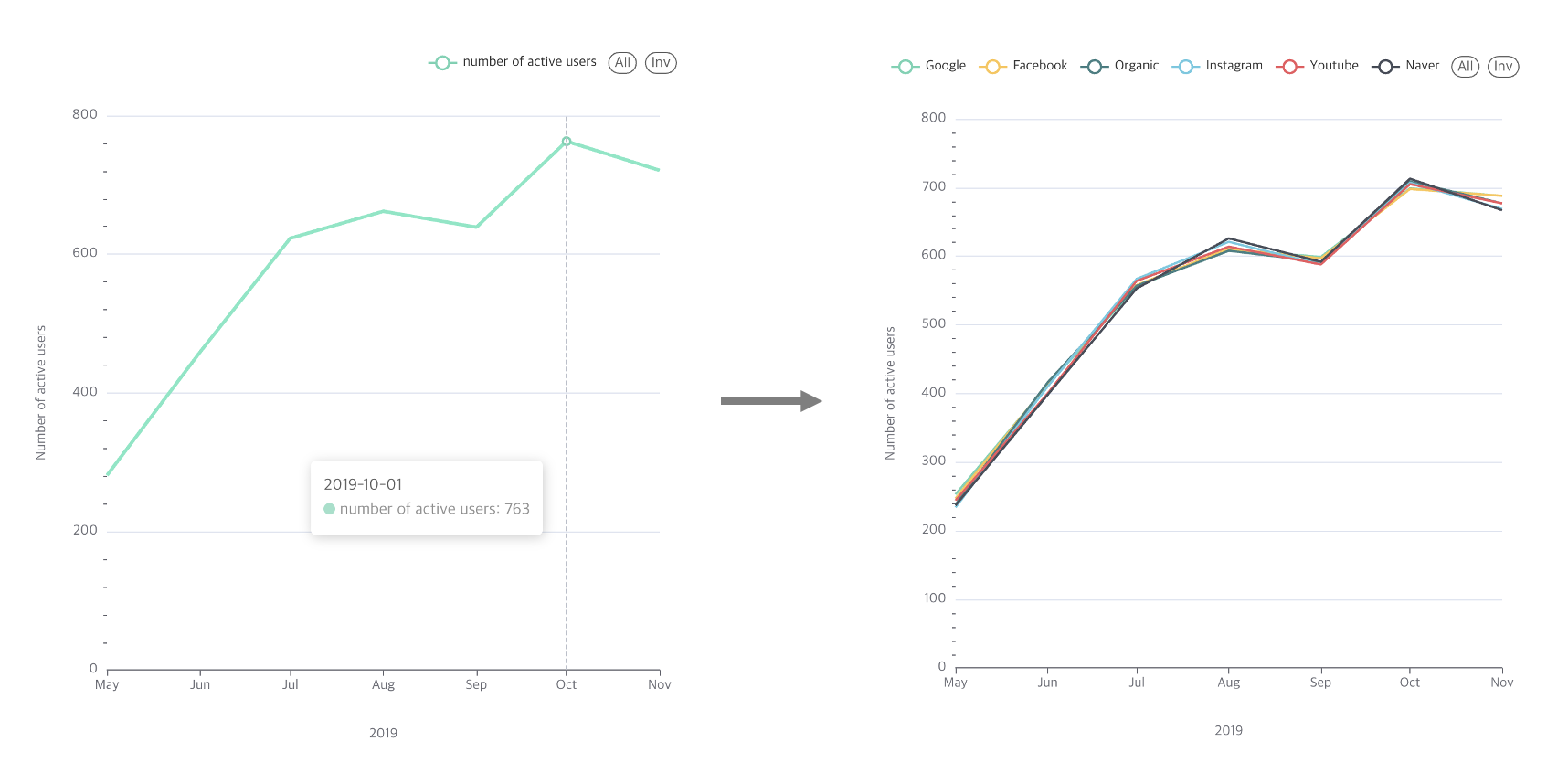
DIMENSIONS : 기준을 하나 더 추가하여 chart에 보여준다. channel 을 선택하였으므로 기존 '월별 User 수' -> '월별 채널별 User 수'를 표시할 수 있게 된다.
Pivot Chart
이번에는 cohort 데이터로 Pivot table을 만들어보자
Cohort란?
특정 속성을 바탕으로 나뉘어진 사용자 그룹이다.
보통 이 특정 속성을 사용자의 서비스 등록 월로 지정한다.
이렇게 했을 때 Cohort는 '해당 월의 서비스 신규 등록 회원 그룹'이다.Cohort 분석이란?
Cohort를 기반으로 기간이 지남에 따라 어떻게 수치가 달라지는지 계산한다.
예) Cohort 기반 사용자 잔존률 분석
Pivot 테이블을 선택한다.
Line chart와 마찬가지로 pivot table에 들어갈 데이터를 세팅한다.
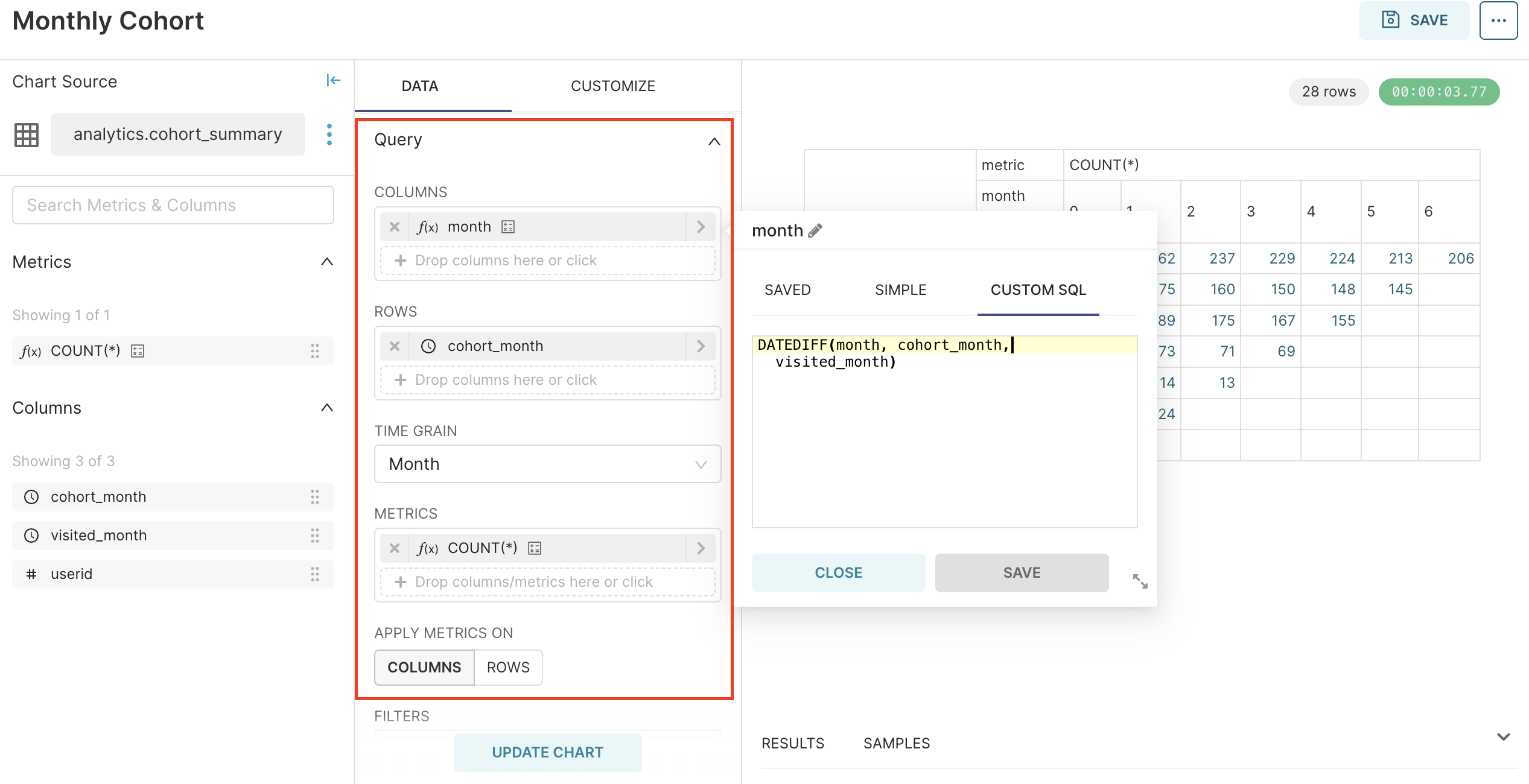
COLUMNS : 기준 월(cohort_month)로부터 한 달씩 멀어지면서 변화하는 사용자 수를 나타내기 위해 DATEDIFF 함수로 컬럼값을 처리해준다.
ROWS : 기준 월이 되는 cohort_month를 지정한다.
METRICS : 각 월별 사용자 수를 계산한다.
4. Dashboard 생성
이제 생성한 chart와 테이블을 Dashboard에 넣어보자.
Dashboard 메뉴로 들어가 Dashboard를 생성한다.
생성 화면에서 Dashboard의 제목을 입력하고, 생성해놓았던 chart를 우측에서 드래그하여 빈 Dashboard로 넣고 저장하면 Dashboard가 완성된다.