
🤷♀️
일주일간의 짧은 프로젝트를 진행하고 나서 좀 더 보완할 부분이 있는지 찾아보던 중, 크롤링하고 CSV파일로 저장하고 DB에 적재하는 flow를 자동화해야겠다는 생각이 들었다.
Github Actions
GitHub Actions 는 GitHub에서 제공하는 지속적인 통합 및 배포(CI/CD) 서비스로, 코드 저장소(repository)에 대한 이벤트 발생 시점이나 crontab을 이용하여 스케줄을 설정하여 작업을 실행할 수 있다.
대표적인 예로 코드를 push하게 되면 GitHub Actions 을 통해 테스트 후 릴리스 작업을 자동화 할 수 있다.
아래와 같이 ~~.yml 파일 형식으로 작성되고, 각각의 작업은 job 이라고 불리는 단계로 이루어진다.
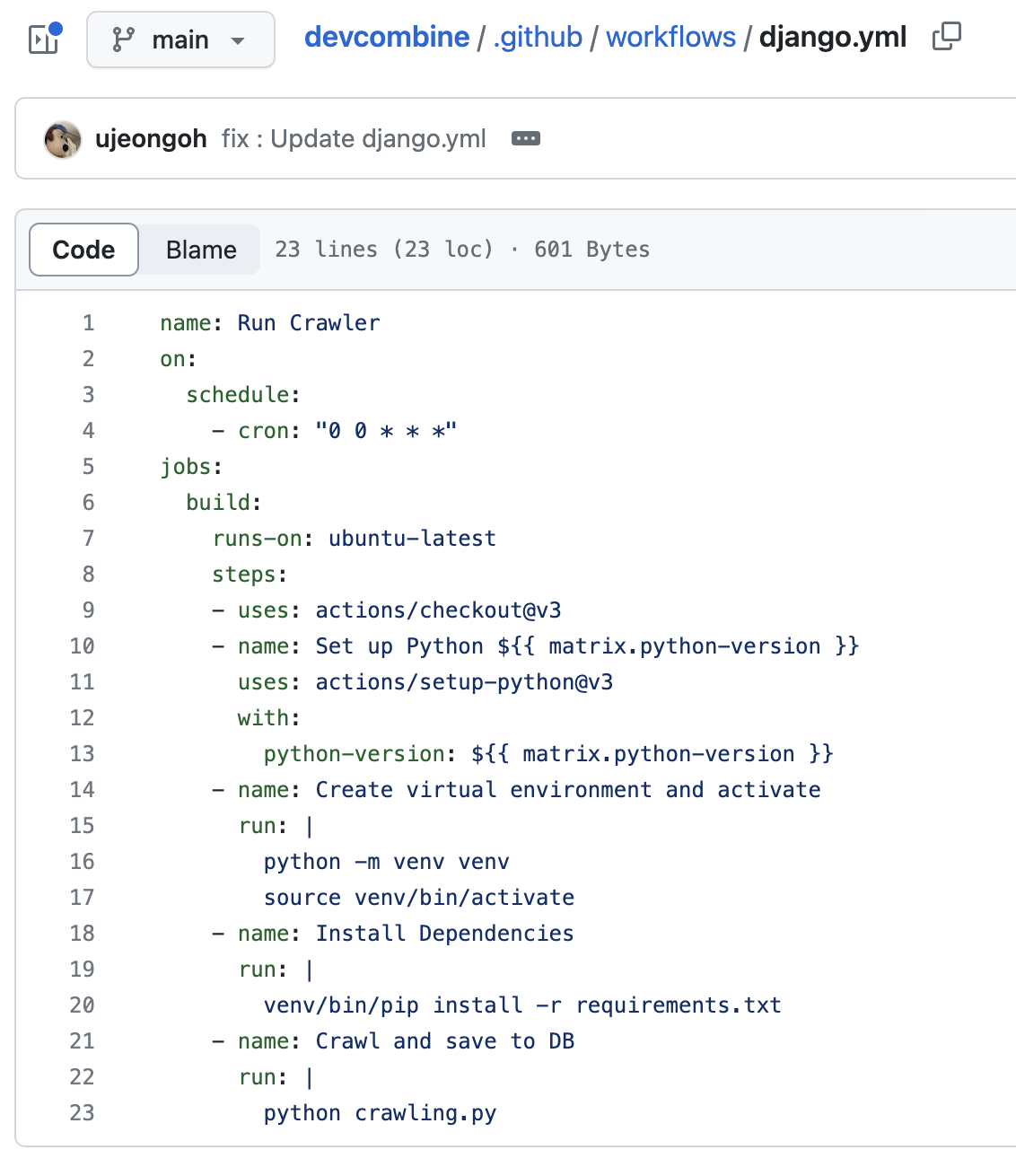
GitHub Actions 의 사용으로 다음과 같은 이점이 있다.
- 코드 저장소에서 모든 것을 관리한다.
- 별도의 CI/CD 서버나 인프라를 구축하지 않아도 된다. (CircleCI, Jenkins...)
- 무료로 사용이 가능하고, 많은 액션과 통합된 서비스가 제공된다.
- 작업 실행 결과를 확인할 수 있는 시각화된 대시보드를 제공한다.
1. 크롤링 & 데이터 저장을 실행할 수 있는 파일로 만들기
django 프로젝트의 root directory에 각 사이트 마다 크롤링 하고 DB로 저장하는 crawling.py 파일을 만들었다.
먼저 각 사이트에서 크롤링을 하는 함수에서는 result라는 폴더 안에 각각 CSV파일을 생성한다.
def goorm_crawl():
...
def programmers_crawl():
...
def inflearn_crawl():
...DB에 저장하기 위해 model을 불러온다.
import os
# Python이 실행될 때 DJANGO_SETTINGS_MODULE이라는 환경 변수에 현재 프로젝트의 settings.py파일 경로를 등록한다.
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "config.settings")
import django
# 이제 장고를 가져와 장고 프로젝트를 사용할 수 있도록 환경을 만든다.
django.setup()
from courses.models import Course, Tagmain() 에서 크롤링 함수들을 불러와 실행하고, 그 결과가 담긴 result 폴더에서 CSV파일을 하나하나씩 읽어서 pandas Dataframe에 담아주었다. 그리고 그 Dataframe객체를 DB에 저장하는 함수로 넘겨주어 DB에 최종적으로 저장될 수 있게 하였다.
def save_dataframe(df):
def get_newtag(tag):
if tag in tag_mapping:
return tag_mapping[tag]
else:
return tag
now = datetime.now().date()
for _, row in df.iterrows():
site = row['site']
title = row['title']
instructor = row['instructor']
description = row['description']
url = row['url']
try:
price = Decimal(row['price'])
except InvalidOperation:
price = Decimal('0.00')
tags = row['tags']
rating = row['rating']
try:
rating = round(Decimal(row['rating']), 3)
except InvalidOperation:
rating = Decimal('0.000')
thumbnail_url = row['thumbnail_url']
is_package = row['is_package']
is_free = row['is_free']
enrollment_count_str = row['enrollment_count']
if enrollment_count_str == "" or enrollment_count_str == "0.0":
enrollment_count = 0
else:
enrollment_count = int(float(enrollment_count_str))
# Course 모델에 데이터 저장
course = Course.objects.create(
title=title,
instructor=instructor,
description=description,
site=site,
url=url,
price=price,
rating=rating,
thumbnail_url=thumbnail_url,
is_package=is_package,
is_free=is_free,
enrollment_count=enrollment_count,
)
for tag_name in tags.split(','):
tag, _ = Tag.objects.get_or_create(name=get_newtag(tag_name.strip()))
course.tags.add(tag)
def main():
# 크롤링하여 result폴더에 결과파일 저장
goorm_crawl()
programmers_crawl()
inflearn_crawl()
# result 폴더에 있는 파일 가져오기
path = './result/*.csv'
data = []
files = glob.glob(path)
# 기존 강의 삭제
Course.objects.all().delete()
for file in files:
# 각 파일의 헤더 행을 지정하여 파일을 읽어옵니다.
df = pd.read_csv(file) # 헤더가 없는 경우
df.fillna('', inplace=True)
data.append(df)
# DB에 저장
save_dataframe(df)2. Github Actions 사용을 위한 workflow 선택하기
메뉴에서 Actions에 들어가게 되면 yml파일을 처음부터 작성할 필요없이 이미 만들어져 있는 CI 설정파일이 있다. 나는 django로 프로젝트를 만들었으니 일단 django를 선택하여 진행했다.
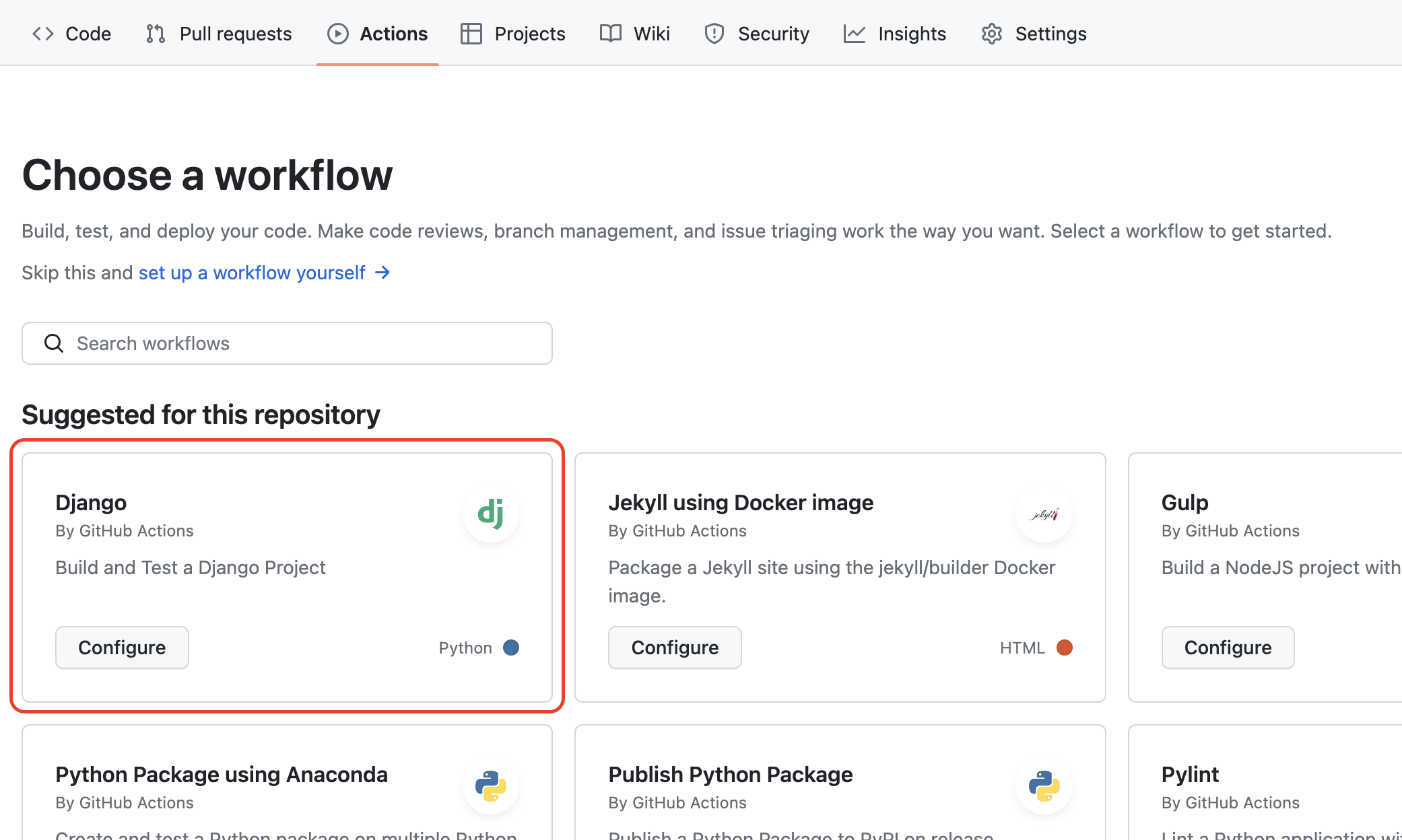
이렇게 기본적인 설정을 제공해준다.
name: Django CI
on:
push:
branches: [ "main" ]
pull_request:
branches: [ "main" ]
jobs:
build:
runs-on: ubuntu-latest
strategy:
max-parallel: 4
matrix:
python-version: [3.7, 3.8, 3.9]
steps:
- uses: actions/checkout@v3
- name: Set up Python ${{ matrix.python-version }}
uses: actions/setup-python@v3
with:
python-version: ${{ matrix.python-version }}
- name: Install Dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
- name: Run Tests
run: |
python manage.py teston: 어떤 이벤트가 있을 때 이 Action이 수행되는지 정의한다. 기본적으로는main브랜치로 push/pull 할 때 Action이 발생한다.jobs: 이 CI에서 실행할 작업을 정의한다. 이 코드에서는 "build"라는 하나의 작업을 정의한다.runs-on: 이 작업을 실행할 환경을 지정한다. 이 코드에서는 "ubuntu-latest"를 사용하여 최신 버전의 Ubuntu OS에서 작업을 실행한다.strategy: 항목은 이 작업을 병렬로 실행할 때 사용할 전략을 정의한다. 이 코드에서는 3.7, 3.8, 3.9 버전의 Python을 사용하는 3개의 작업을 최대 4개까지 병렬로 실행하도록 설정되어 있습니다.steps: 이 작업을 실행하는 단계를 정의한다.
3. Github secrets 사용하여 환경변수 저장하기
Action의 실행은 git repository에 있는 코드를 기반으로 하기 때문에 repository 에 올라가지 않은 환경변수를 yml파일에서는 읽지 못한다. 이 변수들을 Repository Settings - Secrets and variables - Actions 경로로 들어가 Repository secrets 에 key와 value를 저장하면 된다.
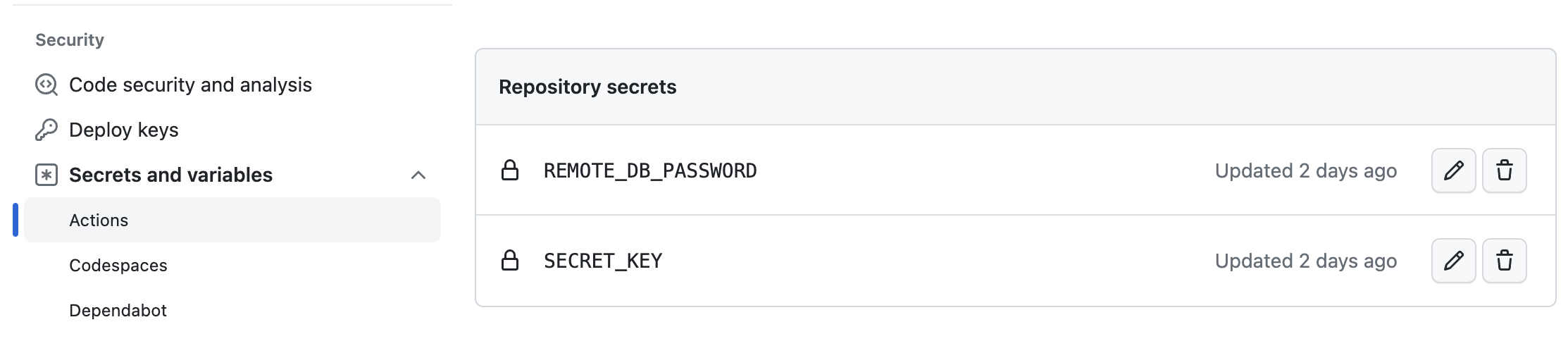
yml 파일에서는 이렇게 가져올 수 있다.
SECRET_KEY: ${{ secrets.SECRET_KEY }}
REMOTE_DB_PASSWORD: ${{ secrets.REMOTE_DB_PASSWORD }}4. yml 파일 수정하기
이 파일을 작성할 때는 strategy 가 뭔지 몰라 빼버렸었는데 이제 보니 이게 없어서 느린거같다...
먼저 가상환경을 설치하고 requirements.txt 에 있는 dependency들을 모두 설치해준다. 크롤링에 사용되는 selenium 사용을 위해서는 크롬 드라이버 설치가 필요하므로, 이미 존재하는 action을 불러다가 설치해준다.
-> uses: nanasess/setup-chromedriver@v2.0.0 로 존재하는 action 사용하기
그리고 env: 에 setting에서 repository secret으로 설정해 준 변수들을 ${{ secrets.키값 }} 형식으로 가져온다.
name: Run Crawler
on:
push:
branches: [ "main" ]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up Python ${{ matrix.python-version }}
uses: actions/setup-python@v3
with:
python-version: ${{ matrix.python-version }}
- name: Create virtual environment and activate
run: |
python -m venv venv
source venv/bin/activate
- name: Install Dependencies
run: |
venv/bin/pip install -r requirements.txt
- name: setup-chromedriver
uses: nanasess/setup-chromedriver@v2.0.0
- name: Crawl and save to DB
env:
SECRET_KEY: ${{ secrets.SECRET_KEY }}
REMOTE_DB_PASSWORD: ${{ secrets.REMOTE_DB_PASSWORD }}
run: |
venv/bin/python crawling.py여기서 어마어마하게 헤멘 부분이 있는데.. 바로 selenium사용이 좀 어렵다는 것이다. 왜인지 모르겠지만 별별 방법을 다 동원해봐도 xpath 경로를 통해 element를 못찾고 오류가 발생되면서 action이 끝나버렸다. 😭
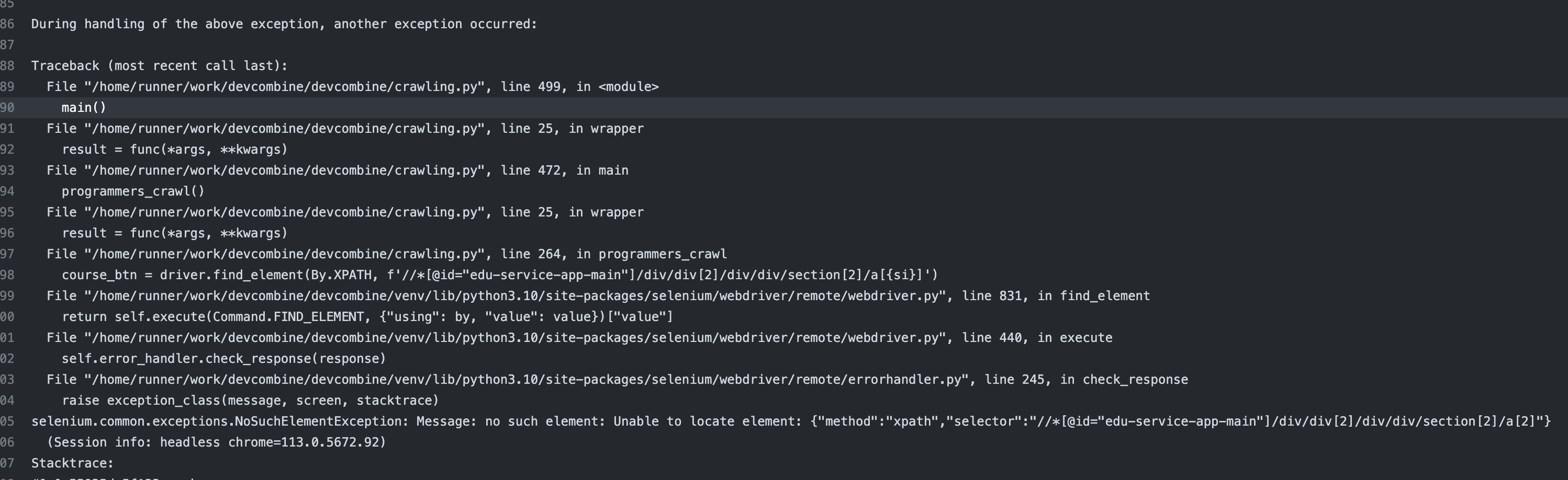
그냥 터미널로 파이썬 파일을 실행했을 때는 잘 되었는지라 정말 이해가 가지 않고 꼭 해결하고 싶었지만! 결국 못하고 코드 수정하는 것으로 타협했다...
마침
단계 하나하나 다 처음 해보는 것들이라 엄청나게 검색하고 삽질하면서 마무리를 지었다. 이번 기회를 통해서 github action과 yml파일을 어떻게 작성하는지 알 수 있어서 유익한 시간이었다 👍
