
📖 오늘의 학습
- SQL : GROUP BY, CTAS
GROUP BY 와 AGGREATE 함수
테이블의 레코드를 그룹핑하여 그룹별로 다양한 정보를 계산한다.
GROUP BY로 그룹핑을 할 필드를 결정 (하나 이상의 필드가 될 수 있음)- 그룹별로 계산할 내용을 결정하고
AGGREATE함수 사용
COUNT, SUM, AVG, MIN, MAX, LISTAGG…
예시 - 월별 세션수를 계산하는 SQL
SELECT
LEFT(ts, 7) AS mon,
COUNT(1) AS session_count
FROM raw_data.session_timestamp
GROUP BY mon
ORDER BY 1
;문제 풀어보기
1. 가장 많이 사용된 채널은 무엇인가?
이렇게 정확하지 않은 질문에 대해서는 가장 많이 사용되었다는 정의는 무엇인지 확인해야한다. 사용자기반인지, 아니면 세션기반인지 알아보고 그 기준에 맞추어 SQL을 작성한다.
SELECT
channel,
COUNT(1) AS channel_count
FROM raw_data.user_session_channel
GROUP BY 1
ORDER BY 2 DESC
LIMIT 12. 가장 많은 세션을 만들어낸 사용자 ID는 무엇인가?
1번과 마찬가지로 조회하고자 하는 항목으로 그룹핑을 하고 각 항목의 COUNT를 내림차순으로 정렬하여 그 중 제일 위에 있는 레코드만 가져온다.
SELECT
userId,
COUNT(1) AS user_count
FROM raw_data.user_session_channel
GROUP BY 1
ORDER BY 2 DESC
LIMIT 13. 월별 유니크한 사용자 수 (MAU - Monthly Active User)
raw_data.user_session_channel 테이블과 raw_data.session_timestamp 테이블을 inner join해준다.
월별로 그룹핑을 하고 DISTINCT 를 사용하여 중복된 사용자를 없애준 다음에 count 한다.
SELECT
LEFT(B.ts, 7) AS month,
COUNT(DISTINCT A.userId) AS mau
FROM raw_data.user_session_channel A
JOIN raw_data.session_timestamp B
ON A.sessionId= B.sessionId
WHERE a.sessionId = b.sessionId
GROUP BY 1
ORDER BY 1 DESC
;LEFT(B.ts, 7) 의 경우 아래와 같이 작성할 수도 있다.
TO_CHAR(B.ts, ‘YYYY-MM’)DATE_TRUNC(‘month’, B.ts): 이 경우 '2023-05-01' 와 같이 해당 월의 1일이 표시된다.SUBSTRING(B.ts, 1, 7)
4. 월별 채널별 유니크한 사용자 수 (MAU - Monthly Active User)
3번의 쿼리에서 channel 로 한번 더 그룹핑을 하면 된다.
SELECT
LEFT(B.ts, 7) AS month,
A.channel AS channel,
COUNT(DISTINCT A.userId) AS count
FROM raw_data.user_session_channel A
JOIN raw_data.session_timestamp B
ON A.sessionId= B.sessionId
GROUP BY 1, 2
ORDER BY 1 DESC, 2CTAS
- SELECT를 가지고 테이블 생성한다.
- 데이터 분석의 근간이 되는 테이블들을 조인하여 사용이 유용한 새로운 테이블을 만든다.
- 자주 조인하는 테이블들이 있다면 이를 CTAS를 사용해서 조인해두면 편리하다.
항상 시도해봐야하는 데이터 품질 확인 방법들
중복된 레코드 체크하기
아래 쿼리들의 카운트가 같으면 된다
-- CTAS로 생성한 테이블의 전체 레코드 수를 체크한다.
SELECT
COUNT(1)
FROM adhoc.yujeong_session_summary
;
-- userId의 중복이 없는지 확인한다.
SELECT
COUNT(1)
FROM (SELECT
DISTINCT userId,
sessionId,
ts,
channel
FROM adhoc.yujeong_session_summary)
;
-- 위의 쿼리를 WITH절을 사용하여 작성할 수도 있다.
WITH ds AS (
SELECT
DISTINCT userId,
sessionId,
ts,
channel
FROM adhoc.yujeong_session_summary
)
SELECT
COUNT(1)
FROM ds
;최근 데이터의 존재여부 체크 (freshness)
MAX 함수로 가장 최근의 레코드의 시간을 가져온다.
SELECT
MIN(ts),
MAX(ts)
FROM adhoc.yujeong_session_summary
;Primary key uniqueness 체크
쿼리를 통해 가져온 레코드의 COUNT 값이 1임을 확인하는 것으로 Primary key uniqueness가 지켜지는지 체크한다.
SELECT
sessionId,
COUNT(1)
FROM adhoc.keeyong_session_summary
GROUP BY 1
ORDER BY 2 DESC
LIMIT 1
;값이 비어있는 컬럼들이 있는지 체크
COUNT 함수 안에서 CASE 문을 사용하여 조건(NULL 이면 카운트)에 따라 카운트한다.
SELECT
COUNT(CASE WHEN sessionId is NULL THEN 1 END) sessionid_null_count,
COUNT(CASE WHEN userId is NULL THEN 1 END) sessionid_null_count,
COUNT(CASE WHEN ts is NULL THEN 1 END) sessionid_null_count,
COUNT(CASE WHEN channel is NULL THEN 1 END) sessionid_null_count,
FROM adhoc.yujeong_session_summary채널별 월별 매출액 테이블 만들기
오늘 배운 GROUP BY, CTAS 를 활용하여 채널별 월별 매출액 테이블 만들어보자.
1. CTAS 구문에 사용될 SELECT 문을 작성한다.
SELECT
TO_CHAR(B.ts, 'YYYY-MM') AS month,
A.channel,
-- 총방문 사용지
COUNT(DISTINCT A.userId) AS uniqueUsers,
-- 구매 사용자 : refund한 경우도 판매로 고려
COUNT(CASE WHEN C.amount IS NOT NULL THEN 1 END) AS paidUsers,
-- 구매사용자 / 총방문사용자
CAST(CAST(COUNT(CASE WHEN C.amount IS NOT NULL THEN 1 END) AS DECIMAL(7,3)) / CAST(COUNT(DISTINCT A.userId) AS DECIMAL(7,3)) AS DECIMAL(7,3)) AS conversionRate,
-- refund 포함 amount
SUM(CASE WHEN C.amount IS NOT NULL THEN C.amount END) AS grossRevenue,
-- refund 제외 amount
SUM(CASE WHEN C.amount IS NOT NULL AND NOT C.refunded THEN C.amount END) AS netRevenue
FROM
raw_data.user_session_channel A
JOIN raw_data.session_timestamp B ON A.sessionid = B.sessionid
LEFT OUTER JOIN raw_data.session_transaction C ON A.sessionid = C.sessionid
GROUP BY 1,2
ORDER BY 1,2테이블 JOIN
user_session_channel 과 session_timestamp 는 세션마다 timestamp가 있는것이 확실하기 때문에 inner join 해주고, session_transaction 은 구매한 세션에만 있기 때문에 outer join 해준다.
GROUP BY
월별, 채널별이기 때문에 month , channel 을 그룹핑 해준다.
구매 사용자
session_transaction 테이블에 데이터가 없는 경우 구매를 하지 않은 사용자이기 때문에 NULL 값이면 카운트에서 제외한다.
구매사용자 / 총방문사용자
각 항목을 먼저 double의 형태로 CAST 함수를 사용하여 변환해야 정확한 나눗셈이 가능하다. 이렇게 하게 되면 결과값의 소숫점 자리수가 너무 많이 나오기 때문에 결과값을 한번 더 변환해주어야 원하는 값을 얻을 수 있다.
Revenue
refund 포함/제외 조건을 SUM 함수의 인자로 넣어서 각 조건에 맞는 값을 얻는다.
2. 작성한 SELECT 문을 사용하여 CTAS 구문을 작성한다.
DROP table 하게 되면 table이 없을 경우 오류가 반환되므로 IF EXISTS 를 추가하여 있는 경우에 테이블을 삭제할 수 있도록 한다.
DROP TABLE IF EXISTS adhoc.yujeong_monthly_sales_by_channel;
CREATE TABLE adhoc.yujeong_monthly_sales_by_channel AS
SELECT
TO_CHAR(B.ts, 'YYYY-MM') AS month,
A.channel,
COUNT(DISTINCT A.userId) AS uniqueUsers,
COUNT(CASE WHEN C.amount IS NOT NULL THEN 1 END) AS paidUsers,
CAST(CAST(COUNT(CASE WHEN C.amount IS NOT NULL THEN 1 END) AS DECIMAL(7,3)) / CAST(COUNT(DISTINCT A.userId) AS DECIMAL(7,3)) AS DECIMAL(7,3)) AS conversionRate,
SUM(CASE WHEN C.amount IS NOT NULL THEN C.amount END) AS grossRevenue,
SUM(CASE WHEN C.amount IS NOT NULL AND NOT C.refunded THEN C.amount END) AS netRevenue
FROM
raw_data.user_session_channel A
JOIN raw_data.session_timestamp B ON A.sessionid = B.sessionid
LEFT OUTER JOIN raw_data.session_transaction C ON A.sessionid = C.sessionid
GROUP BY 1,2
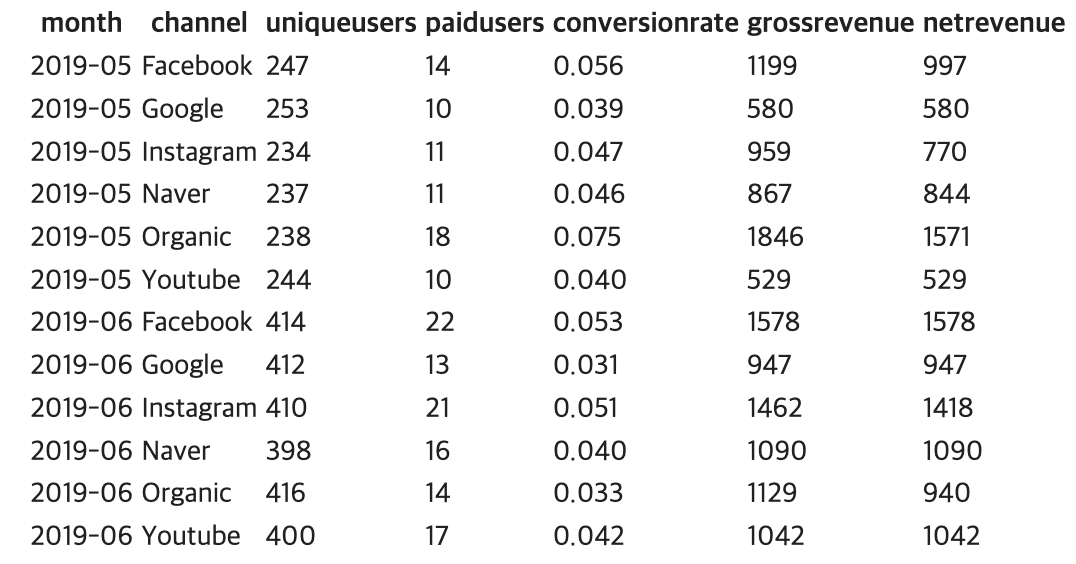
;이렇게 생성된 채널별 월별 매출액 테이블을 확인한다.
SELECT *
FROM adhoc.yujeong_monthly_sales_by_channel
ORDER BY 1,2
;
풀이 후 오답 정정
paidUsers
COUNT(CASE WHEN C.amount IS NOT NULL THEN 1 END) AS paidUsers,
-> COUNT(CASE WHEN C.amount > 0 THEN 1 END) AS paidUsers,C.amount 가 0인 경우를 조건에 걸지 않았다..😀
또한 COUNT함수는 NULL 값을 원래 세지 않으므로 필요없는 조건이었다.
conversionRate
CAST(CAST(COUNT(CASE WHEN C.amount IS NOT NULL THEN 1 END) AS DECIMAL(7,3)) / CAST(COUNT(DISTINCT A.userId) AS DECIMAL(7,3)) AS DECIMAL(7,3)) AS conversionRate,
-- 1번째 시도 - 소숫점으로 나옴, 퍼센티지로 가져오고 싶음
-> paidUsers::float / uniqueUsers AS conversionRate
-- 2번째 시도 - uniqueUsers가 0일 경우 에러 발생하므로 NULL 처리 필요
-> ROUND(paidUsers*100.0 / uniqueUsers, 2) AS conversionRate
-- 3번째 시도 - 완성!
-> ROUND(paidUsers*100.0 / NULLIF(uniqueUsers, 0), 2) AS conversionRate
이렇게 길게 형변환을 했는데 다른 방법으로 형변환을 할 수 있었다. 그리고 위에 alias로 정해준 이름대로 적어도 문제가 없었다. ㅎㅎ
- 분자나 분모나 하나라도 float형이라면 결과값이 해당 데이터형을 따라간다.
NULLIF1번째 인자가 2번째 인자이면 NULL을 리턴한다. 사칙연산에 NULL이 들어가면 결과도 NULL이 된다. 이 함수를 사용함으로써 0으로 나눌 때 발생할 에러를 방지한다.
📝 주요메모사항
Colab 링크 : https://colab.research.google.com/drive/1oNFdTX29J46SCufsinPZs0N5Itnp-0jJ#scrollTo=5P7xCPYhT3mA
😵 공부하면서 어려웠던 내용
