
📖 오늘의 학습
- SQL, RDB, DW, Cloud, AWS, Redshift
SQL을 잘해야 하는 이유!
모든 데이터 관련 직군에서 SQL을 공통적으로 요구하고 있다.
1. 데이터 엔지니어
- 파이썬, 자바, SQL, 데이터베이스
- ETL/ELT (Airflow, DBT)
- Spark, Hadoop
2. 데이터 분석가
- SQL, 비즈니스 도메인 지식
- 통계 (AB 테스트 분석)
3. 데이터 과학자
- 머신러닝
- SQL, 파이썬
- 통계
이렇듯 SQL은 데이터 분야에 종사한다면 꼭 알아야 하는 필수적인 스킬이 되어버렸다..! 이제 SQL을 사용하는 RDB에 대해 알아보자
관계형 데이터베이스 (RDB, Relational Database)
- 구조화된 데이터를 저장하고 질의할 수 있도록 해주는 스토리지
- 엑셀 스프레드 시트 형태의 테이블로 데이터를 정의하고 저장
- 테이블에는 컬럼과 레코드가 존재
- 돌고돌아 RDB.. SQL
- 관계형 데이터베이스를 조작하는 프로그래밍 언어가 SQL
- 테이블 정의를 위한 DDL
- 테이블 데이터 조작/질의를 위한 DML
- 구조화된 데이터를 다루는 데 있어서 검증되고 사용하기 쉬운 언어이기 때문
대표적인 RDB는?
- 프로덕션 데이터베이스 : MySQL, PostgreSQL, Oracle…
- OLTP (Online Transaction Processing)
- 빠른 속도에 집중.
- 웹, 앱과 연동되어 서비스에 필요한 정보를 저장하고 전달해준다.
- 데이터 웨어하우스 : Redshift, Snowflake, BigQuery, Hive
- 데이터 직군이 사용하는 데이터베이스
- OLAP (Online Analytical Processing)
- 처리 데이터 크기에 집중.
- 빠른 속도보다는 처리할 수 있는 데이터가 얼마나 큰가가 중요
- 보통 프로덕션 데이터베이스를 복사해서 데이터 웨어하우스에 저장
만약 데이터팀을 위한 데이터베이스가 없고 프로덕션 데이터베이스를 사용해야 한다면?
-> 데이터팀에서 필요한 많은 양의 데이터를 가져오려고 시도했을 때 프로덕션 데이터베이스에 영향을 미치게 되고, 서비스 운영에 지장을 줄 수 있으로 데이터팀을 위한 데이터베이스 구축이 권장된다.
관계형 데이터베이스의 구조
-
2단계로 구성 : 폴더 - 테이블
가장 밑단에는 테이블들이 존재
데이블들은 폴더(데이터베이스 혹은 스키마) 밑으로 구성
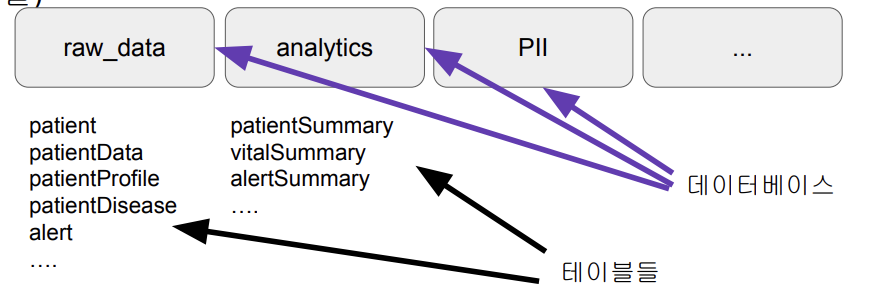
-
테이블의 구조
테이블은 레코드들로 구성 (행)
레코드는 하나 이상의 필드로 구성 (열)
* 필드는 이름과 타입과 속성으로 구성됨

SQL이란?
- Structured Query Language
- RDB에 있는 데이터를 질의하거나 조작해주는 언어
- 50년이상의 역사가 있는 언어
- 두 종류의 언어로 구성
- DDL
- DML
- 빅데이터 세상에서도 중요
- 구조화된 데이터를 다루는 한 SQL은 데이터 규모와 상관없이 쓰임
- 모든 대용량 DW는 SQL 기반이다 (Redshift, Snowflake, BigQuery, Hive…)
- Spark, Hadoop같은 대용량 분산환경 시스템도 SQL을 지원 (SparkSQL, Hive)
SQL의 단점
- 정규표현식(Regex)를 통해 비구조화된 데이터를 어느 정도 다루는 것은 가능하지만 제약이 심하다.
- nested 된 JSON 형태의 데이터를 지원하는 Redshft같은 데이터베이스와 달리, 플랫한 구조만 지원한다.
- 비구조화된 데이터를 다루는데 Spark, Hadoop과 같은 분산 컴퓨팅 환경이 필요해짐
- SQL만으로는 비구조화 데이터를 처리하지 못한다.
- RDB마다 SQL 문법이 조금씩 상이하다
- 어느정도 성장한 회사는 spark, hadoop 같은 데이터 인프라를 도입한다.
Schema
프로덕션 DB와 데이터팀 전용 DB에서 사용되는 Schema는 그 특성에 따라 달라진다.
Star Schema
- 프로덕션 DB용 RDB에서는 보통 스타 스키마를 사용해 데이터를 저장
- 데이터를 논리적 단위로 나눠 저장하고 필요시 조인.
- 스토리지의 낭비가 덜하고 업데이트가 쉬움
- 예를 들어 아래와같이 매출 테이블이 있으면 기간, 매장, 제품은 각각 따로 테이블이 있고,
매출테이블은 이들의 id만을 가지고 있음
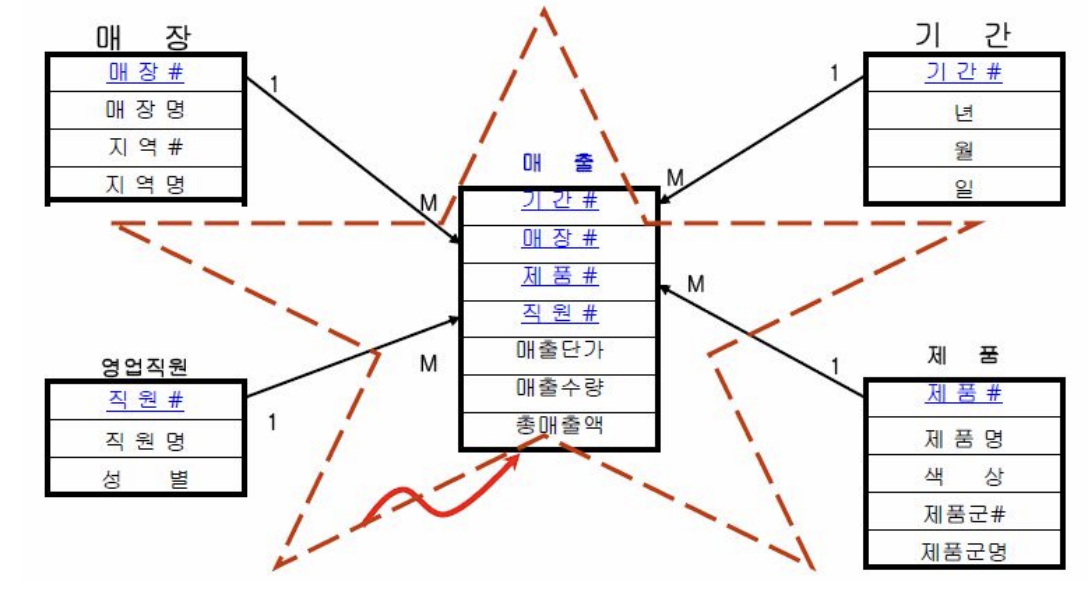
Denormalized Schema
- DW에서 사용하는 방식
- 단위 테이블로 나눠 저장하지 않아 조인이 필요없다
- 스토리지를 더 많이 사용하지만 조인이 필요없어 빠른 계산이 가능하다
- 하지만 만약 제품명이 변경되었을 경우 그 제품명이 들어가 있느 모든 레코드들을 바꿔주어야 한다.
- 하지만 이런 일은 거의 일어나지 않는다. 왜냐면 프로덕션 DB에서 이미 그 작업을 수행하고, DW에 그 DB를 복사하기 때문

데이터 인프라
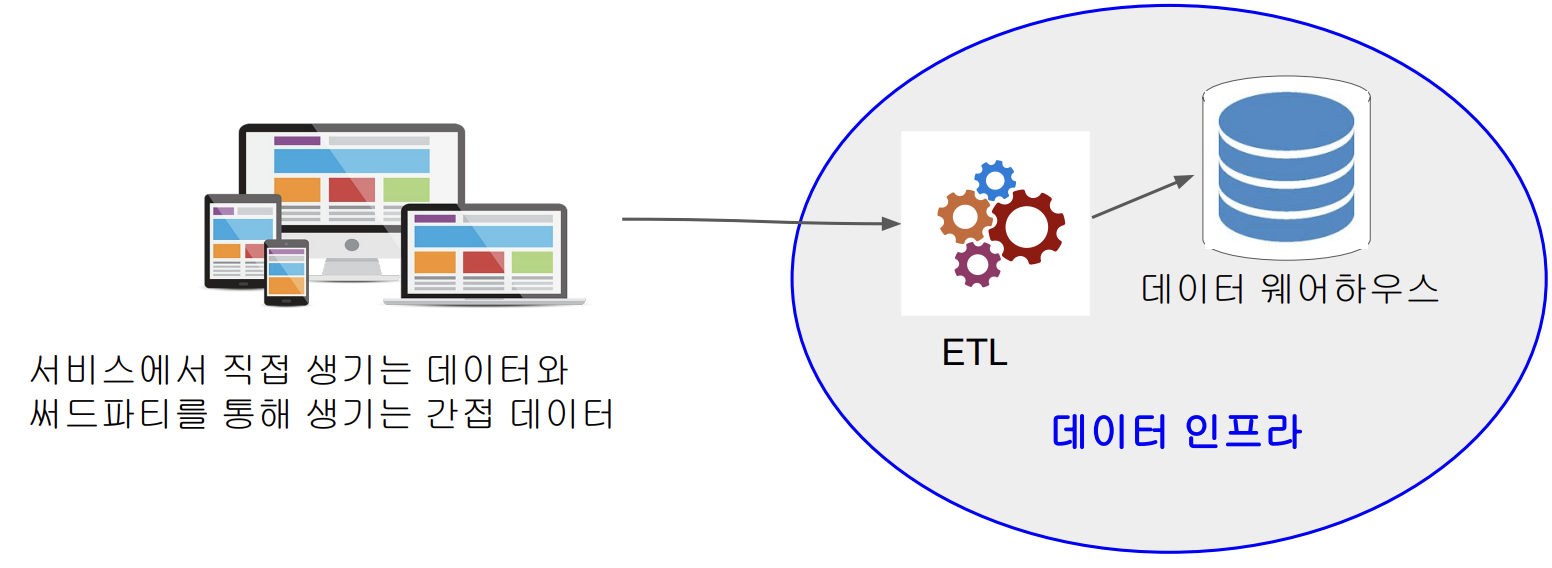
- 데이터 엔지니어가 관리
- ETL하는 flow를 정의하고 DW를 관리하는 것
- Spark과 같은 대용량 분산처리 시스템이 일부로 추가되는 경우가 있음
데이터 순환구조

- 데이터팀이 데이터 인프라를 구축
- DW의 데이터를 통해 비즈니스 인사이트를 얻음 (데이터 분석가가 수행)
- 인사이트를 통해 제품 서비스 개선 (개인화, 데이터 사이언티스트가 수행)
- 서비스가 데이터를 생성
-> 1로 순환
데이터웨어하우스 (DW)
- 회사에 필요한 모든 데이터를 저장
- 여전히 SQL기반의 관계형 데이터베이스
- 프로덕션 DB와는 별도로 있어야 함
- AWS-Redshift(고정비용), GCP-BigQuery, Snowflake(가변비용) 가 대표적
- 외부고객이 아닌 내부 고객을 위한 데이터베이스
- 처리 속도가 아닌 처리 데이터의 크기가 더 중요
- 외부에 존재하는 데이터를 읽어서 데이터 웨어하우스로 저장해주는 작업 = ETL = 데이터 파이프라인
클라우드
- 컴퓨팅 자원을 네트워크를 통해 서비스 형태로 사용하는 것
- No provisioning
- Pay as you go
- 자원을 필요한만큼 실시간으로 할당하여 사용한 만큼 지불
- 탄력적으로 필요한만큼의 자원을 유지하는 것이 중요
클라우드가 없었다면?
- 서버/네트워크/스토리지 구매와 설정 등을 직접 수행
- 데이터 센터 공간을 직접 확보
- 서버를 구매하여 설치하고 네트워크 설정
- 피크타임을 기준으로 Capacity planning을 해야함
- 직접 운영비용 vs. 클라우드 비용
AWS
- 가장 큰 클라우드 컴퓨팅 서비스 업체
- 2002년 아마존의 상품데이터를 API로 제공하면서 시작
- 남아공의 한 개발자가 놀고있는 서버를 상품화하면 어떻겠냐는 아이디어로부터 시작
- Amazon에서 가장 큰 이익을 내는 서비스
- 최근들어 ML/AI 관련 서비스들도 내놓기 시작
주요 서비스
EC2 - 서버 호스팅 서비스
S3 - 대용량 클라우드 스토리지 서비스
기타 서비스 (굉장히 많다..)
RDS
DynamoDB
Redshift
Elasticache
Neptune
ElasticSearch
MongoDB
lambda
- Event-driven, serverless computing engine
- API 로직만 있으면 서비스가 가능
- GCP의 Cloud function
- Azure의 Azure function
ML/AI services
- SageMaker - 딥러닝/머신러닝 프레임워크
- Lex - 챗봇 서비스
- Polly - text to speech engine
- Rekognition - 이미지 인식
현재 클라우드 서비스 Market Share (2023)
- AWS가 선두
- Azure의 점유율이 점점 오르고 있음
- 탑 3 이외에 여러가지 중소 클라우드 서비스가 많다.
Redshift
- 2PB까지 지원 - 사실상 문제가 생기기 때문에 정확한 수치는 아님
- still OLAP : 응답 속도가 빠르지 않기 때문에 프로덕션 DB로 사용 불가
- Columnar storage
- 컬럼별 압축이 가능
- 컬럼을 추가하거나 삭제하는 것이 아주 빠름
- 벌크 업데이트 지원
- 레코드 파일을 S3로 복사 후 COPY 커맨드로 Redshift로 일괄복사
- 고정용량/비용 SQL엔진 : 비용이 예상가능, 유연하지는 않음
- primary key uniqueness를 보장하지 않음
- Postgresql 8.*와 SQL이 호환됨
- Postgresql 8.*를 지원하는 툴이나 라이브러리로 액세스 가능 (JDBC/ODBC)
- 테이블 디자인이 중요
Redshift 폴더 구성
2단계의 구조를 가진다.
먼저 테이블들을 특성에 맞게 분류하고 폴더를 나누어 저장하고,
이를 데이터베이스 혹은 스키마 라고 부른다. (Postgresql, Redshift는 스키마라고 부름)
SQL커맨드로 생성 가능하다.
CREATE SCHEMA raw_data;
CREATE SCHEMA analytics;
CREATE SCHEMA adhoc;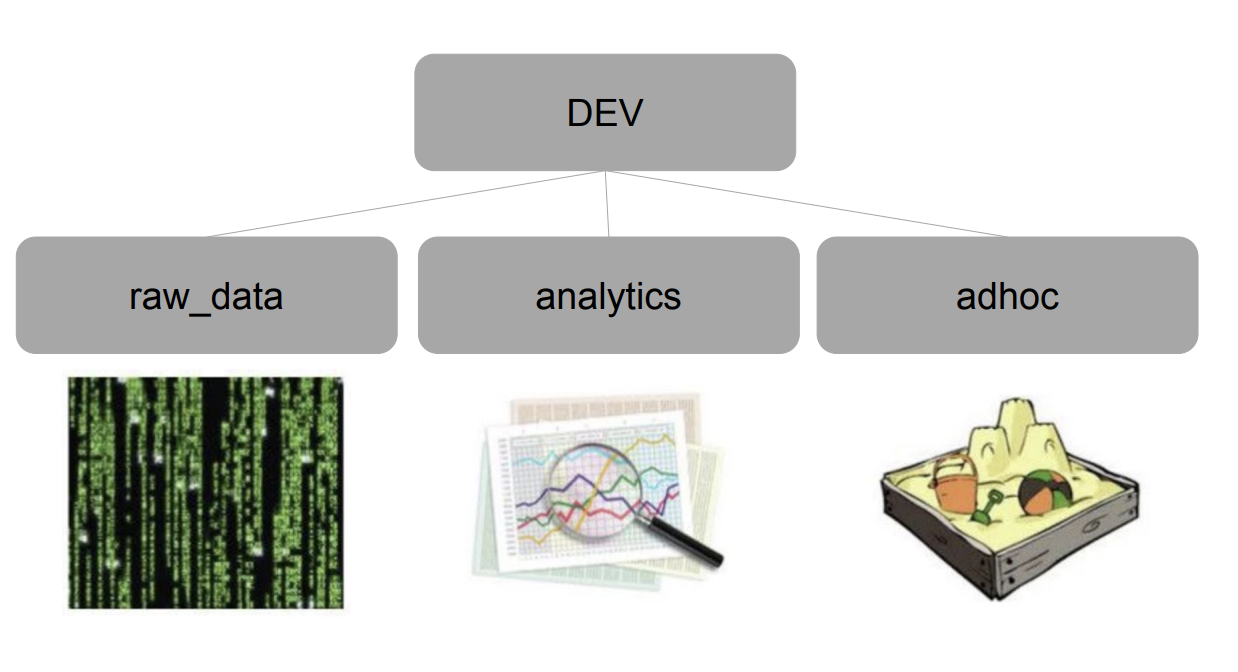
raw_data : 데이터 엔지니어가 관리, ETL 로 어디선가 읽어온 데이터
analytics : 정제한 데이터, 데이터 분석가가 사용
adhoc : 테스트용, 관리X
Redshift 액세스 방법
- Postgresql 8.*과 호환되는 모든 툴과 프로그램이 언어를 통해 접근 가능
- SQL Workbench, Postico(Mac only)
- Python 이라면 psycopg2 모듈
- 시각화/대시보드 툴이라면 Looker, Tableau, Power BI, Superset 등에서 연결가능
📝 주요메모사항
😵 공부하면서 어려웠던 내용
