
🖊️ 문제
https://school.programmers.co.kr/learn/courses/30/lessons/42577#
🖊️ 풀이
1차 풀이
냅다..
phone_book의 원소들에 대해 find로 찾아야할 게 있는지 찾았다.
-> 접두사가 아닌데도 false가 나온다.
반례 : ["123", "3123"]
2차 풀이
어차피 접두사니까 substr을 이용해서 문자열을 잘라서 비교한다.
#include <string>
#include <vector>
using namespace std;
bool solution(vector<string> phone_book) {
bool answer = true;
for (int i = 0 ; i < phone_book.size() - 1 ; i++) {
int size = phone_book[i].length();
string str = phone_book[i];
for (int j = i + 1 ; j < phone_book.size() ; j++) {
if (str == phone_book[j].substr(0, size)) {
answer = false;
break;
}
}
if (!answer) break;
}
return answer;
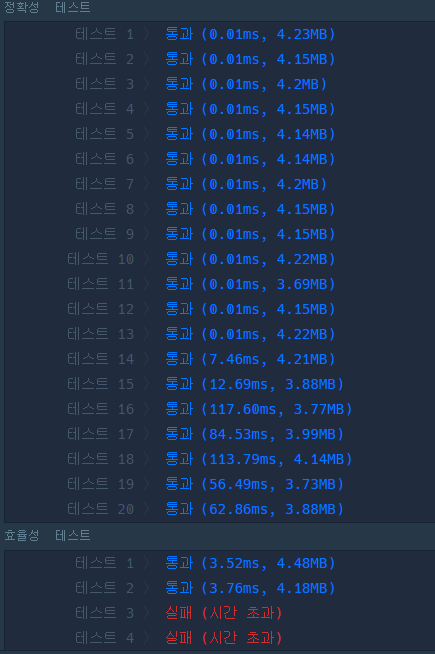
}-> 정확성 8, 9, 19 / 효율성 3, 4 실패
3차 풀이
솔직히 여기서 ,,
질문하기 봤다 ㅋ ㅋ
답이 생각이 안났다..
분명 카테고리는 해시인데.. 무식한 이중포문? 흠...
정렬해야 한다는 힌트를 얻고 나왔다.
일단 맨 위에서 정렬만 해줬다.
-> 반례 : ["32", "3"]
(3은 32의 접두사인데, 정렬 안해놔서 3->32를 비교 못했던 문제)
흠.. 정확성 테스트는 통과했는데
효율성이 망했다.
당연함
이중포문 어칼건데..
여기서 근데,
왜 정렬을 해야 했던걸까?
애초에 정렬을 해야 정확성테스트가 통과된 이유.
C++ stl sort()
정렬에 필요한, 원하는 방식의 비교 방식을 세 번째 인자에 넣어주면 가능하지만,
기본적으로 냅다sort하면
문자열 기준으로
문자열의 첫 번째 인덱스를 기준으로 사전식 정렬해준다.a, ab, abb, abbc, ad, bb, bd, bdk, cds이런식으로.
당연히 숫자가 들어가도1, 11, 12, 123, 123532, 21, 2234 // str1이런식으로 정렬해준다.
그니까
일단 사전식으로 정렬되어 있으니까
각 원소에 대해
다음 원소만 비교하면 된다.
위 str1을 예시로 들면,
1 다음은 11이고, 12이다.
str1[0]에 대해 str1[1]만 비교하면 된다.
str1[0]와 사전식으로 가장 가까운 단어는 str[2]이다.
중복이 없다고 했으니까.
1 / 11 비교 -> 접두사 O
1 / 12 --> 비교할 필요 없음. 이미 접두사임
123532 / 21 비교 -> 접두사 X
123532 / 2234 비교할 필요 없음. 이미 바로 다음 원소가 접두사가 아니라면 절대 그 다음 원소는 접두사가 될 수 없음.
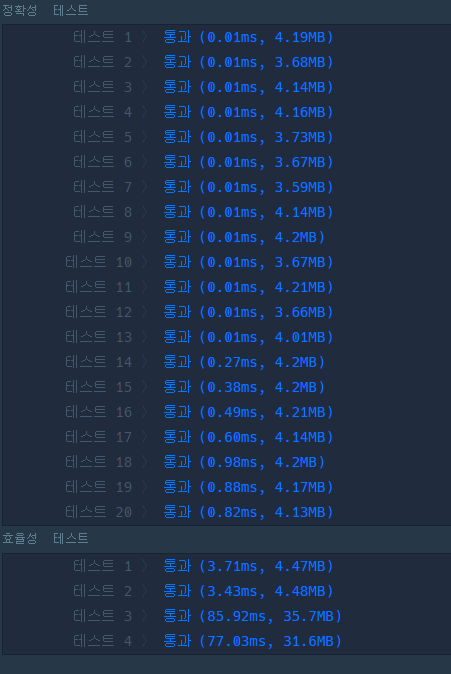
그니까 한 번 정렬해 놓으면
for문을 한 번만 쓰면 된다.
#include <string>
#include <vector>
#include <algorithm>
using namespace std;
bool solution(vector<string> phone_book) {
bool answer = true;
sort(phone_book.begin(), phone_book.end());
for (int i = 0 ; i < phone_book.size() - 1 ; i++) {
if (phone_book[i] == phone_book[i+1].substr(0, phone_book[i].length())) {
answer = false;
break;
}
}
return answer;
}
해-결
Hash 쓰기
카테고리가 해시로 되어있다.
해시로 한 번 풀어봐야겠다..
unordered_map 사용
전체 phone_book 자체를 unordered_map에 넣어놓고
str에 비교할 것(접두사가 될 것들)을 넣어놓고 um에 있는지 확인한다.
#include <string>
#include <vector>
#include <unordered_map>
using namespace std;
bool solution(vector<string> phone_book) {
bool answer = true;
unordered_map<string, int> um;
for(auto& pb : phone_book) {
um[pb] = 1;
}
for (int i = 0 ; i < phone_book.size() ; i++) {
string str = "";
for (int j = 0 ; j < phone_book[i].length() ; j++) {
str += phone_book[i][j];
if (um[str] && str != phone_book[i]) {
answer = false;
break;
}
}
}
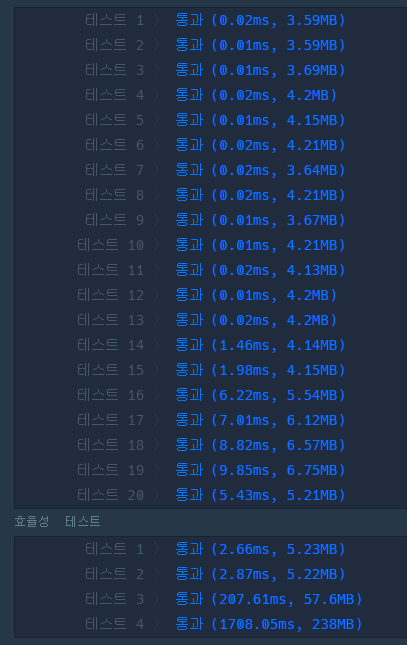
return answer;
}
unordered_set 사용
#include <string>
#include <vector>
#include <unordered_set>
using namespace std;
bool solution(vector<string> phone_book) {
bool answer = true;
unordered_set<string> us(phone_book.begin(), phone_book.end());
for (int i = 0 ; i < phone_book.size() ; i++) {
string str = "";
for (int j = 0 ; j < phone_book[i].length() ; j++) {
str += phone_book[i][j];
if (us.find(str) != us.end() && str != phone_book[i]) {
answer = false;
break;
}
}
}
return answer;
}value값을 사용할 필요가 없으므로 unordered_set을 써봤다.
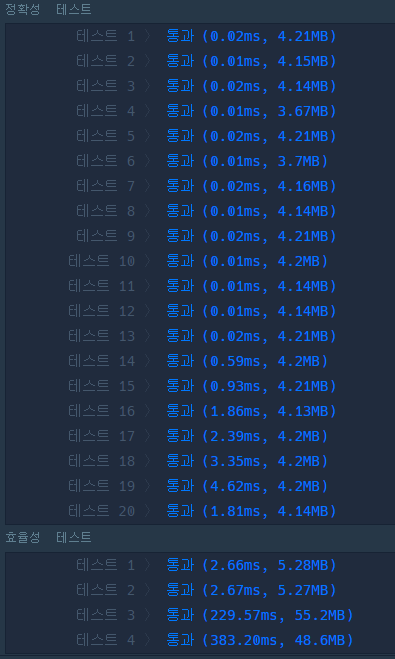
굿
흠...
sort 후 for문 / hash 사용
사실 시간적으로 보나 메모리적으로 보나..
sort 후 for문이 더 효율적이라고 느껴진다.
아무래도 hash는 이중포문도 있고, 새로운 메모리를 할당해야 하니까....
그치만 hash이용해서 풀어본다는 거에 의의를 두도록 하겠당...
