
인프런 강의 : 뇌를 자극하는 윈도우즈 시스템 프로그래밍을 듣고 정리한 학습 목적의 글입니다.
문제 시 댓글 혹은 메일 주시면 감사하겠습니다.
1. Windows에서의 유니코드
문자셋의 종류와 특성
-
SBCS (Single Byte Character Set)
: 문자를 표현하는데 1바이트 사용
ex) 아스키 코드 -
MBCS (Multi Byte Character Set)
: 한글은 2바이트, 영문은 1바이트 사용
문자열을 구성하는 내용에 따라 다르게 표현 -
WBCS (Wide Byte Character Set)
: 문자를 표현하는데 2바이트 사용
ex) 유니코드
한글, 영문 모두 표현해야 하기 때문에 대부분의 System은 SBCS가 아니라 MBCS 기반의 Character Set이다.
예제1
int main()
{
char str[] = "ABC한글";
int size = sizeof(str);
int len = strlen(str);
printf("배열의 크기 : %d \n", size);
printf("문자열 길이 : %d \n", len);
}결과
배열의 크기 : 8
문자열 길이 : 7배열의 크기 = 1 * 3 (영문) + 2 * 2 (한글) + 1 (널문자) = 8
문자열 길이 = 1 * 3 + 2 * 2
예제2
int main()
{
char str[] = "한글입니다";
for(int i= 0 ; i < 5 ; i++)
fputc(str[i], stdout)
fputs('\n', stdout);
for(int i =0 ; i < 10 ; i++)
fputc(str[i], stdout);
}결과
한글
한글입니다한글은 2바이트로 인식하니까 이렇게 결과가 나온다.
WBCS 기반의 프로그래밍
WBCS를 위해서는
1) char 대신 wchar_t을 사용한다
: 문자를 저장하는데
char은 1byte를, wchar_t는 2byte를 사용한다.
2) "ABC" 대신 L"ABC"로 선언한다
"ABC"로 문자열을 선언하면 아스키코드로, L"ABC"로 선언하면 유니코드로 선언하겠다고 의미하는 것이다.
그런데,
strlen은 char* 타입의 인자를 요청한다.
이렇게 자료형을 변경하여 WBCS 기반으로 프로그래밍 하는 경우에, 문자열 관련 함수를 변경해줘야 한다.
| SBCS 함수 | WBCS 함수 |
|---|---|
| strlen | size_t wcslen (const wchara_t* string) |
| strcpy | wchara_t* wcscpy (wchar_t* dest, const wchar_t* src) |
| strncpy | wchara_t* wcsncpy (wchar_t* dest, const wchar_t* src, size_t cnt) |
| strcat | wchar_t* wcscat (wchar_t* dest, const wchar_t* src) |
| strcmp | int wcscmp (const wchar_t* s1, const wchar_t* s2) |
| printf | int wprintf(const wchar_t* format [, argument] ...) |
| scanf | int scanf (const wchar_t* format [, argument] ...) |
| fgets | wchar_t* fgetws (wchar_t* string, int n, FILE* stream) |
| fputs | int fputws (const wchar_t* string, FILE* stream) |
이렇게 위 함수를 이용하면 된다.
그래서 아까 예제를 이러한 유니코드로 표현하고 싶다면,
int main()
{
wchar_t str[] = L"ABC";
int size = sizeof(str);
int len = wcslen(str);
wprintf(L"Array Size : %d \n", size);
wprintf(L"String Length : %d \n", len);
}결과
배열의 크기 : 8
문자열 길이 : 3이렇게 하면 된다.
매개변수 전달인자 유니코드화
main에 전달되는 매개변수를 유니코드 기반으로 전달해보자.
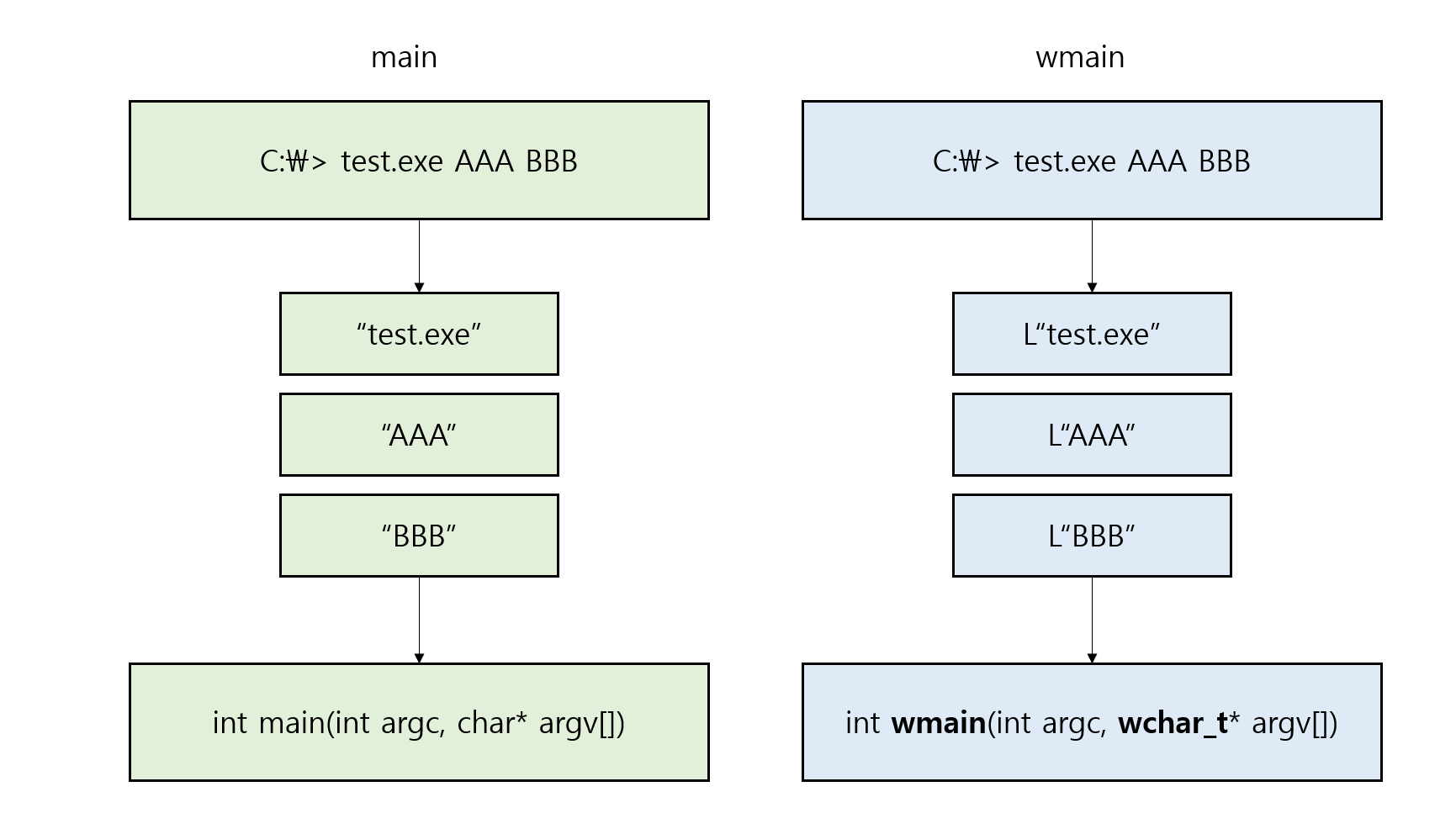
이렇게 wmain을 사용하면
전달되는 매개변수도 유니코드 기반으로 작성할 수 있다.
완벽한 유니코드 예제
int wmain(int argc, wchar_t* argv[])
{
for(int i = 1 ; i < argc ; i++) {
fputws(argv[i], stdout);
fputws(L"\n", stdout);
}
return 0;
}결과
AAA
BBB
CCC2. MBCS와 WBCS 동시지원
기존 MBCS 기준으로 개발된 프로그램과의 호환성이나, 유니코드를 지원하지 않는 사용자의 시스템 등의 사정 상, 유니코드로만 동작하도록 구현하기는 어렵다
서버는 업데이트가 편하므로 뭐 서버 프로그램 개발 시에는 크게 상관없긴 하다. 이러한 이유로 기업 대상 프로그램에서는 유니코드로만 작성되기도 한다.
하지만 클라이언트에게 제공되어야 할 프로그램의 경우에는 MBCS와 WBCS를 동시에 지원할 수 있도록 해야 한다.
Windows 정의 자료형
typedef char CHAR;
typedef wchar_t WCHAR;
#define CONST const
typedef CHAR* LPSTR;
typedef CONST CHAR* LPCSTR;
typedef WCHAR* LPWSTR;
typedef COSNT WCHAR* LPCWSTR;예제로 이렇게 사용하긴 한다...
회사마다, 프로젝트 마다 다를 수 있기 때문에 사용 방식만 이해하면 될 듯 하다!
어떻게 동시 지원?
#ifdef UNICODE
typedef WCHAR TCHAR;
typedef LPWSTR LPTSTR;
typedef LPCWSTR LPCTSTR;
#else
typedef CHAR TCHAR;
typedef LPSTR LPTSTR;
typedef LPCSTR LPCTSTR;
#endif이렇게 하면,
UNICODE로 선언할 경우와 선언하지 않을 경우를 전처리기에서 판단해서 위와 같이 매크로를 사용하면 된다.
즉, 이렇게 선언하고TCHAR를 썼을 때
유니코드가 정의되어 있다면 WHCAR를,
아니라면 CHAR로 사용된다.
이와 비슷하게,
#ifdef _UNICODE
#define __T(x) L## x
#else
#define __T(x) x
#endif
#define _T(x) __T(x)
#define _TEXT(x) __T(x)(L## x : L과 x를 붙여라)
그리고, 함수 관련도 이렇게 매크로를 정의해주자.
#ifdef _UNICODE
#define _tmain wmain
#define _tcslen wcslen
#define _tprintf wprintf
#define _tscanf wscanf
#else
#define _tmain main
#define _tcslen strlen
#define _tprintf printf
#define _tscanf scanf
#endif예제1
#define UNICODE
#define _UNICODE
int wmain(void)
{
TCHAR str[] = T("1234567");
int size = sizeof(str);
printf("string length : %d \n", size);
return 0;
}결과
string length : 16예제2
LPTSTR str1 = _T("MBCS or WBCS 1");
TCHAR str2[] = _T("MBCS or WBCS 2");
TCHAR str3[100];
TCHAR str4[50];
LPCTSTR pStr = str1;
_tprintf(_T("string size : %d \n"), sizeof(str2));
_tprintf(_T("string length : %d \n"), _tcslen(pStr));
_fputs(_T("Input String 1 : "), stdout);
_tscanf(_T("%s"), str3);이렇게 하면 MBCS와 WBCS를 동시지원하도록 프로그래밍할 수 있다.
_tprintf함수를 호출하면 매크로에 따라 MBCS, WBCS에 맞는 함수를 호출해 준다.
