아래와 같은 코드가 있다.
#include <iostream>
using namespace std;
int main()
{
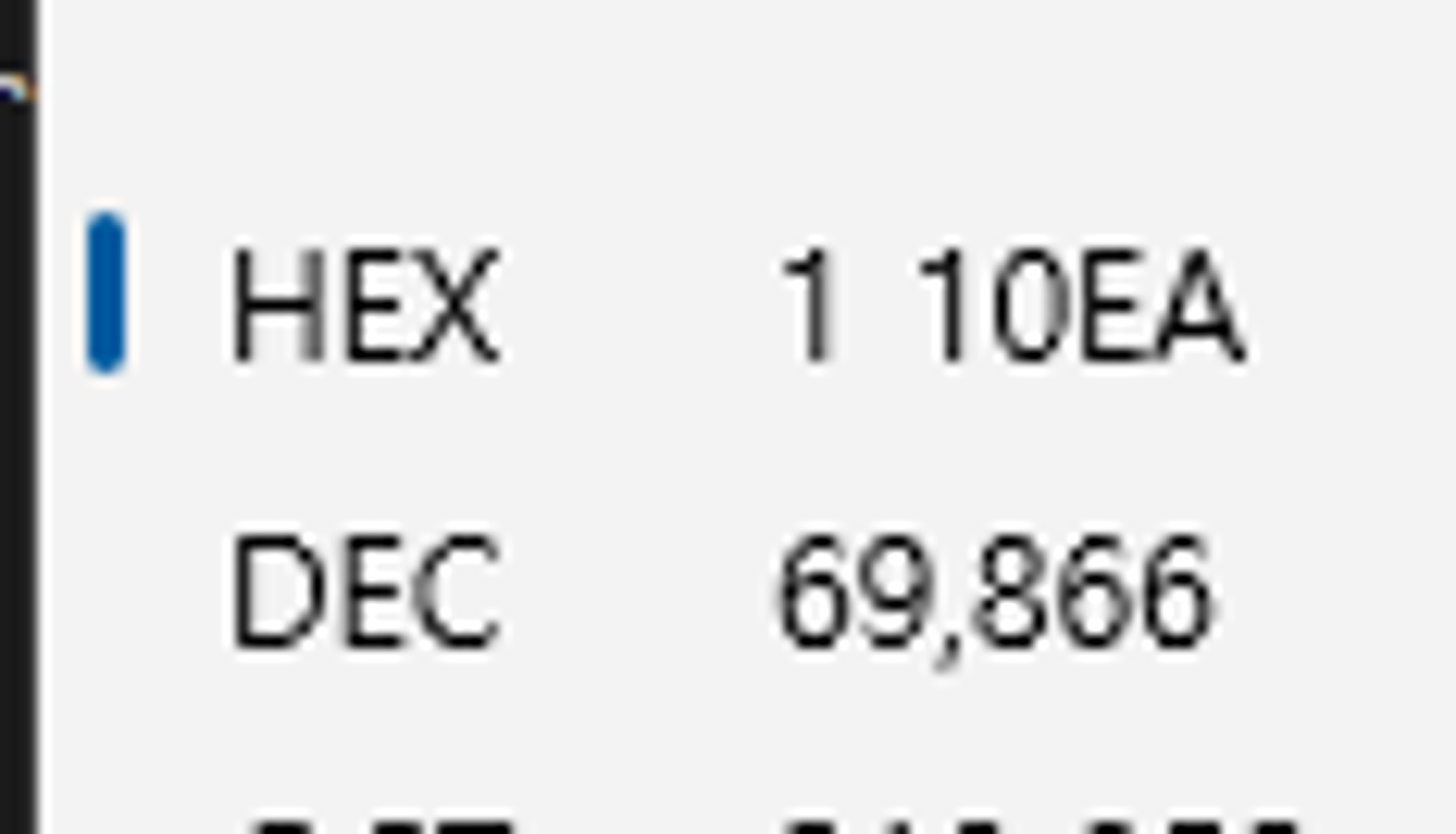
uint32_t a = 69866;
const uint32_t* ptr = &a;
}여기서 ptr 변수의 값을 확인하고자 한다.
코드를 눈으로만 봐도 값이 69866인걸 알 수 있지만, 실제 코드는 이렇지 않기에~!
사실 디버깅중이라면, 조사식에 추가해 간단히 포인터변수가 가리키고 있는 값을 알 수 있다.

하지만, 이 변수… 메모리에선 어떨까?
직접 확인해보도록 하자.
디버깅/창/메모리 경로를 통해 메모리 창을 열어보자.
조사식에서 얻은 메모리 주소값을 검색하면 아래와 같이 값이 나온다.

uint32 형식의 포인터이기에, 4byte를 확인해보면 된다.
참고로, 32비트 운영체제에서 포인터의 크기는, 타입에 관계없이 모두 4byte이다.
그런데 이를 계산해보면?

이상함.
왤까?
왜냐면, 메모리에는 리틀 엔디안 방식으로 값이 저장되어있기 때문이다.
리틀엔디안, 빅엔디안이 뭔데?
이는 메모리에 데이터를 저장하는 방식들이다.
빅 엔디안 (Big Endian)
빅 엔디안(Big Endian)의 경우, 주로 네트워크에서 사용되는 방식이다.
데이터의 하위 바이트가 메모리의 높은 주소에, 데이터의 상위 바이트가 낮은 주소에 저장되는 방식이다.
메모리에 저장된 순서대로 읽을 수 있다.
만약 32비트 크기의 정수 0x123456578 이 빅 엔디안 방식으로 저장되어 있다면,
0x12, 0x34, 0x56, 0x78 과 같이 저장되어 있을 것이다.
때문에 대부분의 프로토콜이 빅 엔디안 방식을 사용한다.
리틀 엔디안 (Little Endian)
리틀 엔디안(Little Endian)의 경우, 주로 Intel x86 및 x86-64에서 사용되는 방식이다.
이는 빅 엔디안과 반대로 데이터의 하위 바이트가 메모리의 낮은 주소에, 상위 바이트가 높은 주소에 저장되는 방식이다.
그래서 0x12345678 이 리틀 엔디안 방식으로 저장되어있다면,
0x78, 0x56, 0x34, 0x12 이렇게 저장되어 있었을 것이다.
왜 굳이 우리 눈과 반대로.. 거꾸로 저장했을까?
이 리틀 엔디안 방식이 가지는 장점은 뭘까?
- 현대 운영체제 및 소프트웨어가 리틀 엔디안 방식을 표준화해서 사용하고 있기 때문에, 호환성이 높다.
- 메모리의 하위 바이트만 접근할 때 편리할 수 있다.
만약 위0x12345678변수의 하위 1byte만 접근하고 싶다면, 가장 높은 주소만 접근하면 되기 때문에 편리하다.
리틀 엔디안 방식으로 다시 계산해보면 다음과 같이 정상적으로 나오는 것을 확인할 수 있다.