코루틴이란?
코루틴의 개념
코루틴은 비동기적인 작업을 편리하게 처리할 수 있는 매커니즘입니다.
비동기적인 작업을 수행하기 위해서는 주로 스레드나 콜백함수를 이용했는데요, 코루틴을 사용하면 보다 직관적이고 간단하게 처리할 수 있습니다.
코루틴을 한마디로 정의하면, 진입 지점을 여러 개 가질 수 있는 함수입니다.
이 말이 너무 문어체고 딱딱해서, 직관적으로 이해하기 어렵네요
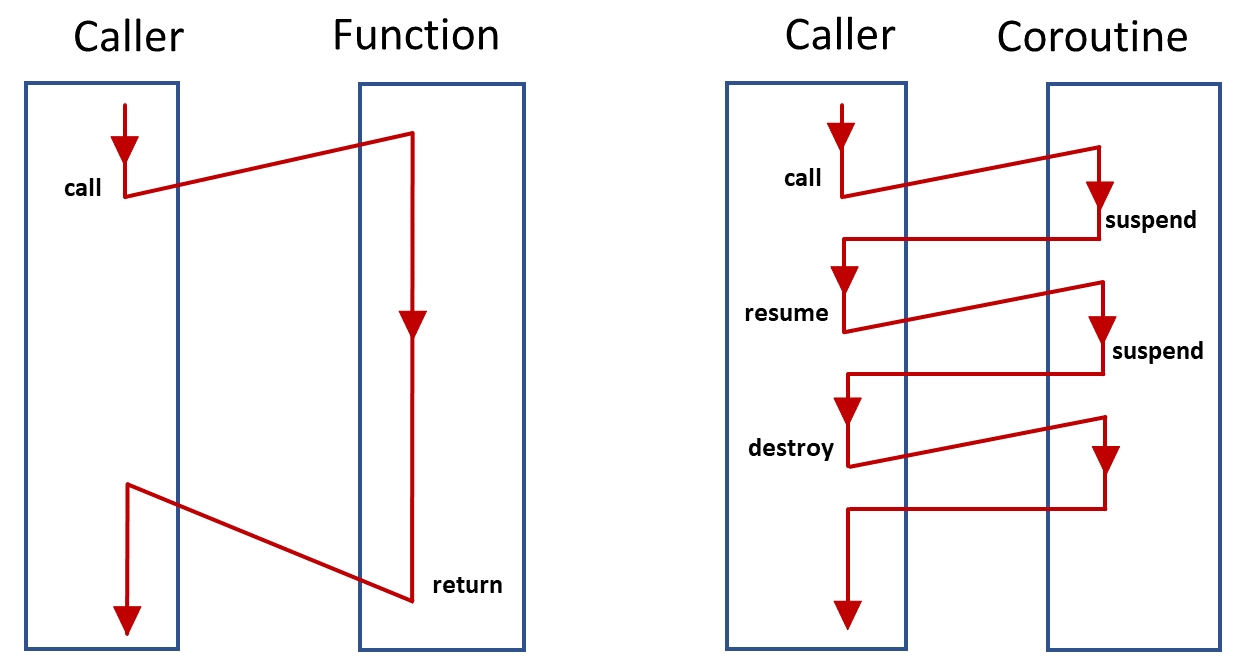
코루틴은 함수 실행 중에 중단(suspend)될 수 있는 함수입니다.
함수는 중단된 지점에서의 상태가 보존되고, 나중에 재개(resume)할 수 있습니다. 그러면 함수가 중단되는 동안 다른 작업을 할 수 있는거죠.
사실 병렬적으로 처리하는 것 같지만, 코루틴은 그렇지 않습니다. 직렬적으로 처리하는데 병렬처리처럼 보이게 하는거죠. 코루틴을 이용하면 싱글스레드에서도 멀티태스킹을 할 수 있겠습니다.
그렇다고 코루틴이 스레드라는 것은 아닙니다.
코루틴은 스레드와는 별개의 개념입니다. 스레드 내에서 동작한 작업 단위입니다. Task같은거죠.
이러한 코루틴은 I/O, 네트워크 통신, 타이머 등의 작업을 하는데 효율적으로 사용할 수 있을 것 같습니다.
코루틴의 장점
1. ContextSwitching 비용이 적다
코루틴의 ContextSwitching은 스레드의 ContextSwitching과 비교했을 때, 적은 비용을 가집니다.
2. 데이터레이스가 발생하지 않는다
멀티스레드 방식을 이용해서 동시성 처리를 한다면, 스레드간의 공유자원에 동시에 접근하여 데이터레이스 문제가 발생할 수 있습니다.
그러나 코루틴은 제어권이 넘어가는 개념이기 때문에 데이터레이스 문제가 발생하지 않습니다. 그냥 잠깐 할 일 하러 다녀오는 것이기 때문이죠.
코루틴의 키워드
코루틴을 정의하고 사용하기 위해서는 특별한 키워드가 필요합니다.
아래 키워드와 같은 코루틴 키워드가 포함된 함수는 코루틴 함수로 처리됩니다.
co_await
코루틴 함수 내에서 비동기 작업 결과를 기다리고, 그 작업이 완료될 때까지 해당 코루틴을 중단시키는 키워드입니다.
제어권을 받아 재개될 때, 이 키워드 이후부터 이어서 실행합니다.
co_return
코루틴 함수의 리턴 지점입니다.
이 키워드를 사용하면 코루틴의 실행이 종료되고, 해당 값을 반환합니다.
co_yield
코루틴 함수 내에서 값을 생성하고 중단할 때 사용하는 키워드입니다.
일반 함수에서는 return 키워드가 값을 반환한다면, 코루틴 함수에서는 co_yield 키워드가 값을 반환합니다.
단, co_return과는 달리 코루틴의 실행이 종료되지 않습니다. 그저 값과 함께 제어권을 넘겨줍니다.
