자바 7 이전 병렬처리: 데이터를 서브파트로 분할 → 분할된 서브파트를 각각 스레드에 할당 → 의도치 않은 레이스 컨디션이 발생하지 않도록 동기화를 추가 → 병합
자바7: 포크/조인 프레임워크 기능을 제공해 병렬화가 이전 보다는 쉬워짐
자바8: 스트림으로 병렬 처리가 이전보다 더 쉬워짐
병렬 스트림
parallelStream: 각각의 스레드에서 처리할 수 있도록 스트림 요소를 여러 청크로 분할한 스트림
병렬로 분할 후 해당 스트림을 각각 처리 후 리듀싱 연산으로 합쳐서 전체 스트림의 결과를 도출
- 청크로 분할이 되지 않는 연산의 경우 오버헤드가 발생해 오히려 성능이 안좋아질 수 도 있다
- rangedClosed 메서드를 사용해 오토박싱과 같은 오버헤드를 줄여주는 것이 성능에 도움이 될 수 있다
- 병렬화를 잘못 사용하면 데이터 레이스 문제가 일어나 원하지 않는 결과가 도출될 수 도 있다
병렬화 사용 조건
- 확신이 없을 경우 성능 측정을 해볼 것
- 박싱은 성능을 저하시킬 수 있으므로 사용에 주의
- limit, findFirst같이 순서에 의존하는 연산의 경우 순차 스트림이 성능이 더 좋다
- 비용은 N(처리할 요소 수)*Q(하나의 요소를 처리하는 비용)인데 Q가 높은 연산의 경우 병렬로 처리하는 것이 효과적
- 소량의 데이터에서는 병렬 스트림이 도움이 되지 않는다
- 스트림을 구성하는 자료요소가 적절한지 확인
- 파이프라인의 중간 연산이 병렬처리 성능에 영향을 미칠 수 있다
- 최종 병합 과정에서의 비용을 고려해라
포크/조인 프레임워크
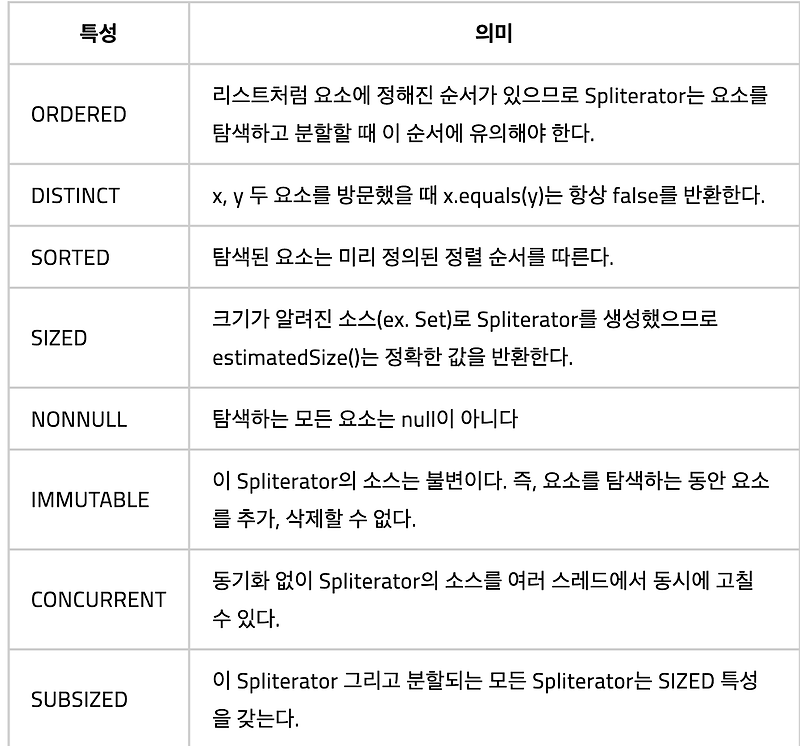
병렬화할 수 있는 작업을 재귀적으로 작은 작업으로 분할한 다음에 서브태스크 각각의 결과를 합쳐서 결과를 만든다
분할 후 정복 알고리즘의 병렬화 버전
public static long forkJoinSum(long n){
long[] numbers = LongStream.rangedClosed(1,n).toArray();
ForkJoinTask<Long> task = new ForkJoinSumCalculator(numbers);
return new ForkJoinPool().invoke(task);
}LongStream으로 배열 생성 → 배열을 ForkJoinSumCalculator 생성자로 전달 → 생성한 테스크를 ForkJoinPool의 invoke 메서드로 전달
ForkJoinPool에서 실행되는 마지막 invoke 메서드의 반환값은 ForkSumCalculator에서 정의한 테스크의 결과
한 애플리케이션에서는 둘 이상의 ForkJoinPool을 사용하지 않고 한 번만 인스턴스화해서 정적 필드에 싱글턴으로 저장
포크/조인 사용 조건
- 두 서브태스크가 모두 시작된 다음에 join을 호출
- RecursieTask 내에서는 invoke 메서드를 사용하지 말고 compute나 fork 메서드를 직접 호출
- 서브태스크에서 fork 메서드를 호출해서 ForkJoinPool의 일정을 조절할 수 있다
- 포크/조인으로 병렬 계산을 하면 디버깅이 어려워 진다
- 포크/조인을 잘 사용하지 않으면 오히려 성능이 좋지 않은 경우도 발생
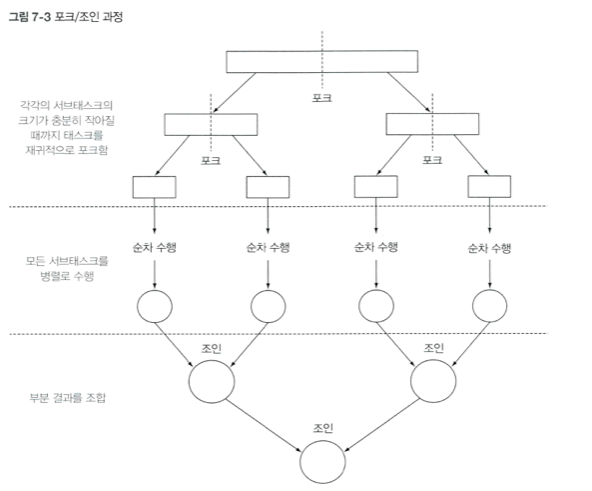
작업 훔치기
ForkJoinPool의 모든 스레드를 거의 공정하게 분할
각각의 스레드는 자신에게 할당된 테스크를 포함하는 이중 연결 리스트를 참조하면서 작업이 끝날때마다 큐의 헤드에서 다른 태스크를 가져와 작업을 처리
Spliterator
분할할 수 있는 반복자
소스의 요소 탐색 기능을 제공하지만 병렬 작업에 특화되어 있다
public interface Spliterator<T>{
boolean tryAdavance(Consumer<? super T> action);
Spliterator<T> trySplit();
long estimateSize();
int characteristics();
}T: 탐색하는 요소의 형식
tryAdvance: 요소를 하나씩 순차적으로 소비하면서 탐색해야 할 요소가 남아 있으면 참을 반환
trySplit: 일부 요소를 분할해서 두번째 Spliterator을 생성
estimateSize: 탐색해야 할 요소 수 정보 제공
characteristics: Spliterator 자체의 특성 집합을 포함하는 int를 반환
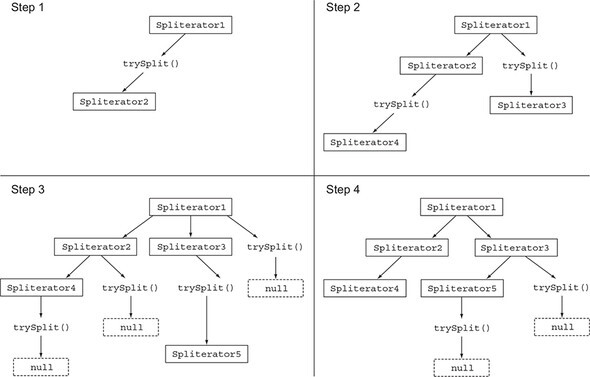
Spliterator 특성