'High Performance Browser Networking'의 내용을 주로 참고하였습니다.
https://hpbn.co/
HTTP 0.9과 HTTP 1.1의 차이점과 특징을 정리했습니다.
HTTP
HTTP는 'hypertext transfer protocol'의 줄임말로 서버와 클라이언트 사이의 데이터 전송을 위한 어플리케이션 계층의 프로토콜입니다.
주로 웹 브라우저와 웹 서버가 사용하지만, 인터넷을 이용하는 여러 응용 프로그램에서도 사용합니다.
HTTP/0.9
HTTP 0.9는 원래 버전 번호가 붙지 않았지만 후에 새로운 버전이 나오면서 구분을 위해 0.9가 붙게 되었습니다.
1991년 world wide web이 공개되고 사용되었던 초기의 http는 원-라인 구조로 아주 단순합니다.
Request는 GET 메소드와 요청하는 문서의 경로만 담고 있고, Response로는 header 등이 없이 오직 요청된 HTML 문서만을 보냅니다.
Connected to 74.125.xxx.xxx
GET /about/
(hypertext response)
(connection closed)HTTP 0.9의 특징으로는
- 클라이언트, 서버 간 requset, response를 주고 받는 구조입니다.
- TCP/IP 위에서 ASCII 문자로 통신합니다.
- HTML을 전달하기 위해 만들어졌습니다.
- 매 요청이 끝나면 connection이 끊어집니다.
HTTP 1.0
인터넷과 웹 브라우저의 빠른 발달과 함께 사람들은 HTTP 0.9의 제한적인 기능에서 더 많은 걸 요구하게 되었습니다.
그래서 1996년 HTTP 1.0이 나오게 됩니다.
Connected to xxx.xxx.xxx.xxx
GET /rfc/rfc1945.txt HTTP/1.0
User-Agent: CERN-LineMode/2.15 libwww/2.17b3
Accept: */*
HTTP/1.0 200 OK
Content-Type: text/plain
Content-Length: 137582
Expires: Thu, 01 Dec 1997 16:00:00 GMT
Last-Modified: Wed, 1 May 1996 12:45:26 GMT
Server: Apache 0.84
(plain-text response)
(connection closed)HTTP 1.0에서는 response와 request 모두 여러 개의 header field를 가져서 좀 더 풍부한 메타 데이터를 제공합니다.
그리고 hypertext 외에도 이미지 같이 다양한 리소스 전달이 가능해졌습니다.
HTTP 1.0으로 바뀌면서 개선된 점은
- hypertext 외에도 다양한 타입의 리소스를 전달할 수 있게 되었고,
- 여러 줄의 header를 통해 각각의 요청 또는 응답에 대한 메타 데이터를 풍부하게 하였다.
정도로 생각할 수 있을 것 같습니다.
HTTP 1.1
HTTP 1.0이 나오고 약 6개월 뒤인 1997년 1월에 HTTP 1.1이 처음 발표됩니다.
그 뒤로 여러 개선 작업 등이 반영된 버전이 1999년에 6월에 발표됩니다.
HTTP 1.1은 성능 개선을 위해서 여러가지 방법을 도입합니다.
- Connection Reuse
- HTTP Pipelining
- Multiple TCP Connections
Connection Reuse
HTTP 1.0까지는 하나의 요청에 대한 TCP connection을 생성하고 응답이 완료된 후 생성한 TCP connection을 종료합니다.
TCP connection 생성에는 3-way handshake을 거치는 동안 1 RTT (Round Trip Time) 만큼의 시간이 소요됩니다.
이는 네트워크의 환경에 따라 큰 비용이 될 수 있습니다.
HTTP 1.1에서는 이전 요청으로 생성된 connection을 다음 요청에서 사용할 수 있게 유지합니다.
이를 통해 3-way handshake 과정을 생략할 수 있어서 재사용하는 요청마다 1 RTT 만큼의 시간을 단축할 수 있습니다.
[그림 1]
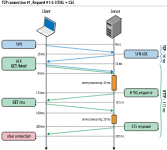
HTTP Pipelining
HTTP 요청은 순차적으로 처리됩니다.
이 방법은 짧은 시간 안에 여러 개의 리소스에 대한 요청이 발생하는 경우 비효율적입니다.
[그림 1]처럼 HTML 파일과 CSS 파일이 필요한 경우, 클라이언트가 HTML 파일 요청에 대한 응답을 받은 후 CSS 파일 요청을 보내는 것을 볼 수 있습니다.
즉, 다음 요청을 보내기 위해서는 이전 요청에 대한 응답이 완료될 때까지 기다려야 합니다.
이런 대기 시간을 없애려고 HTTP 1.1에서는 pipelining을 도입합니다.
pipelining을 통해 이전 요청에 대한 응답이 도착하기 전에 새로운 요청을 서버에 보내 처리될 수 있도록 합니다.
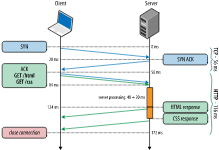
여기서 서버가 요청에 대한 병렬 처리가 가능하다면 클라이언트는 더 빠른 시간 안에 필요한 리소스를 얻을 수 있습니다.
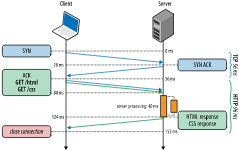
이렇게 좋아보이는 Pipelining도 문제점이 있습니다.
- 요청은 병렬적으로 처리될 수 있어도 서버의 응답은 순서대로 보내져야 합니다. 그래서 앞선 요청이 처리될 동안 이어지는 요청은 처리가 완료되더라도 응답이 이뤄지지 않습니다. (HTTP Head-of-Line Blocking)
- 서버가 클라이언트의 이어지는 요청을 기억해야 하므로 리소스 부족 문제가 생길 수 있습니다.
- 하나의 요청에 대한 응답이 실패해서 TCP connection이 끊기게 되면 이후 요청들이 다시 서버로 요청되어 중복으로 처리될 수 있습니다.
그리고 실제로 pipelining은 거의 채택되지 않는 기술입니다.
서버나 미들박스가 정확하게 pipelining을 지원하지 않는 경우가 많아서 크롬 브라우저에서도 pipelining 기능에 대한 옵션이 삭제되었다고 합니다.
Multiple TCP Connections
순차적으로 처리되는 HTTP의 성능적 한계를 극복하기 위해 HTTP 1.1에서는 여러 개의 TCP Connection을 이용하는 방법도 도입합니다.
장점으로는
- TCP Connection 개수만큼 동시에 여러 요청과 응답을 처리할 수 있게 됩니다.
- 응답의 개수가 늘어나는 만큼 congestion control을 위한 TCP window도 빠르게 커지는 이점이 있습니다.
하지만 단점으로는
- connection의 개수가 늘어나는 만큼 리소스가 추가적으로 사용됩니다.
- 한정된 네트워크 대역폭을 가지고 connection끼리 경쟁하게 됩니다.
- 여러 connection을 염두한 복잡한 구현이 필요합니다.
> Domain sharding
대부분의 브라우저에서는 최대 6개의 TCP connection을 지원합니다.
그런데 경우에 따라 6개 보다 더 많은 connection이 더 알맞을 때가 있습니다.
그런 경우에는 Domain sharding을 통해 사용하는 connection을 늘릴 수 있습니다.
브라우저는 domain을 기준으로 connection의 개수를 제한합니다.
그렇기 때문에 리소스를 여러 서브도메인으로 분산시키면 사용할 수 있는 connection의 개수를 늘릴 수 있습니다.
하지만 domain sharding은 추가적인 domain lookup 과정에 따른 오버헤드가 발생합니다.
초기 버전에서 HTTP/1.1로 변화하면서 성능 향상을 위한 노력을 위주로 정리해봤습니다.
공부하는 과정에서 pipelining이 제시되었지만 실제로는 사용되지 않는 것을 알 수 있었는데, 표준과 실사용이 다른 경우를 처음 봐서 흥미로웠습니다.
다음은 HTTP 1.1에서 2.0으로 변화를 정리해보겠습니다.
