
Firestore 사용량 측정 및 과금 방식 살펴보기
Firebase 세팅하기
Firestore 사용해 보기 1편
Firestore 사용해 보기 2편
Realtime Database 사용해 보기
Storage 사용해 보기
최근 바쁜 일이 생겨서 오랜만에 글을 작성하게 되었다.
Firebase 플랫폼을 사용해서 백엔드 없이 1인 개발 앱을 종종 개발해 왔는데, 최근 개발한 앱에서 대량 쿼리를 요청해야 하는 기능이 추가되어 Firestore 과금 체계에 대해 다뤄보고자 한다.
Firebase는 앱 개발 플랫폼으로 다양한 기능을 사용할 수 있도록 지원해주고 있다. 아마도 1인 앱 개발자가 Firebase를 사용하려고 하는 이유는 대부분 Firestore DB를 사용하기 위해 Firebase에 대해서 알아보고 사용할 것으로 생각된다.
Firestore를 사용하게 되면 NoSQL DB를 과금이 되지만 않는다면 무료 티어로 사용이 가능하고 쉽게 구축할 수 있는데 여기서 문제는 과금이 되기 시작하면 비용 부담이 만만치 않다는 것이다.
국내만 타겟으로 개발을 하면 Resion 선택시 별 문제가 되지 않지만 글로벌 타겟을 목표로 한다면 어떤 Resion을 선택해야 할지도 큰 고민거리다.
저는 지금까지 보통 단순한 데이터를 호출이 빈번한 영역에는 Realtime Data를 사용하고, 메인으로는 Firestore를 사용하고 있습니다.
Realtime은 용량으로 비용을 측정하기 때문에, 용량이 높지 않다면 문제가 되지 않지만 Firestore는 건수를 기준으로 하기에 기준이 조금 모호합니다.
아래에서 Resion에 따른 과금 체계와 실제로 건수라고 하는 기준이 어떻게 측정 되는지에 대해서 CRUD 기능 별로 살펴보도록 하겠다.
Resion
Firestore Documents
공식 문서를 보면 무료 사용량 및 과금 비용 등을 확인할 수 있음.
Price


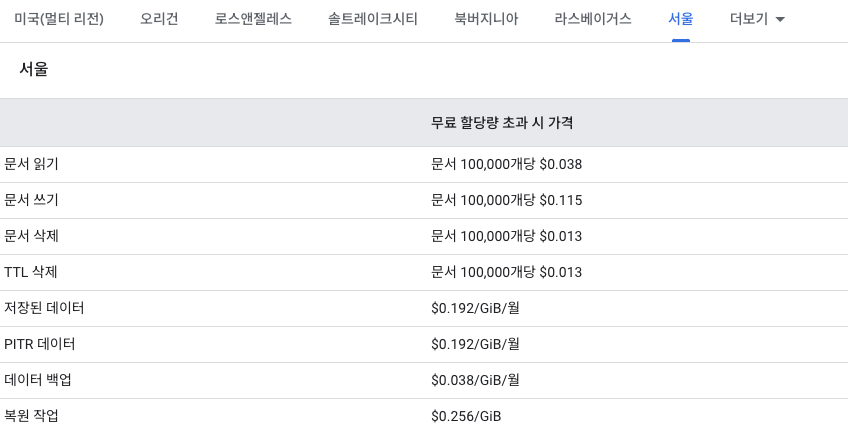
Resion별로 과금 비용을 확인할 수 있는데, 대표적으로 많이 사용하는 리전만 가져와봤다.
보통 Firestore를 대시보드에서 생성할 때에 디폴트 리전으로 nam5(북미 멀티리전)을 사용하게 된다. 멀티 리전은 북미와 유럽 2곳만 지원하는데, 재해나 확장성에 있어 장점이 있지만 비용이 거의 단일 리전에 비해 2배 정도 높은 것을 확인할 수 있다.
운영하는 서비스가 잘되서 비용을 크게 생각하지 않는다면 멀티 리전이 가장 좋겠지만, 과금 비용을 최대한 줄이고 싶다면 단일 리전을 선택하는 것이 좋다.
멀티 리전은 사용자의 위치에 근접한 리전에 데이터를 저장하는데, 북미 멀티리전이라고 해서 북미 전역에 있는 리전을 사용할 수 있는 것은 아니고 정해진 리전으로만 사용이 된다. 이 부분은 공식문서를 살펴보면 자세히 안내하고 있다.
Performance
Measure your latency to Google Cloud regions

리전별 가격을 살펴봤으니, 서비스 사용자의 위치에 따른 속도 차이를 간단하게 살펴보도록 하자. 해당 사이트는 GCP 리전별 현재 접속한 위치의 퍼포먼스를 체크할 수 있도록 해주는데, 한국에 있으니 당연히 아시아 리전의 속도가 높은 것을 확인할 수 있다.
해당 사이트를 계속 켜놓고 있으면 결국 서울 리전 속도가 제일 높은 것으로 나올 것이다. 저는 접속 하자마자 캡쳐를 해서 일본 리전 속도가 제일 높게 나와 있다.
퍼포먼스 부분도 중요한 문제인 것이 실제로 북미를 타겟으로 하는 기업에서 Firebase 플랫폼으로 SNS 서비스를 운영한 적이 있는데, 리전을 북미에 두고 사용을 해본 결과 체감할 정도까지는 아니였지만, 아시아권 리전보다 퍼포먼스 측면에서 다소 비효율적이라 생각이 들었었다.
CRUD
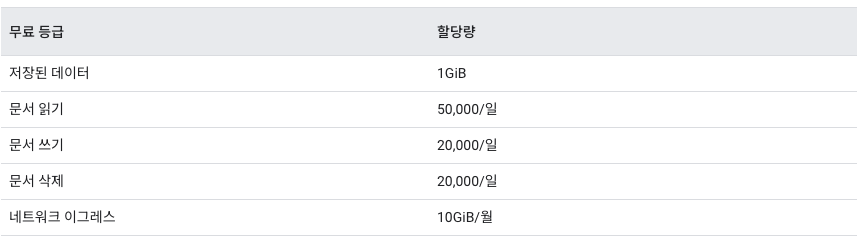
이번에는 가장 중요한 부분인 무료 할당량에 대해서 살펴보도록 하자.
서비스를 안정적으로 운영하기 위해서는 리전 위치에 따른 퍼포먼스도 중요하지만 결국 무료 할당량을 최대한 활용해 비용을 줄이는 것도 중요한 부분이라 생각한다.
먼저 쓰기, 삭제를 보면 20,000건이라고 나와있다. 20,000건 처음에는 많아 보이지만 저는 쓰기, 삭제로 과금되본 적은 없다. 문제는 읽기 건수다.
건수라고 측정되는 것이 문서를 읽는 건수라 설명하고 있는데, 이 부분의 설명이 모호해서 구현하려는 기능이나 쿼리문에 대해서 먼저 건수가 어떻게 찍히는지 확인해 보는 것이 좋다.
저는 처음에 건수라고 해서 제가 쿼리를 요청하는 건수를 1건이라 생각해 개발을 했었는데, 이건 완전 잘못 알고 있던 거였다. Firestore가 사용량을 측정하는 방법은 문서를 1건 읽는 기준인 것이다.
NoSQL DB는 Collection-Document 라는 Depth 구조를 가지고 있는데, 여기서 Document가 바로 문서에 속한다.
결국 Document를 읽어올 때마다 건수가 잡히는 건데, 아래에서 자세한 내용은 따로 다룰 것이니 간단하게만 예를 들어보도록 하겠다.
Case 1. ToDo 앱을 만든다고 하자. 하루에 ToDo가 10건이 생성된다. 이 때 쿼리를 해당 날짜의 00:00초 부터 23:59초 까지 쿼리를 조회하면 Firestore 건수는 10건이 찍힌다. 쿼리를 요청할 때에 limit을 1로 지정하고 요청하면 읽는 건수도 1건이 되는 것이다.
근데, 달력에 사용자가 생성한 ToDo 데이터가 존재하는 경우 달력에 표시를 해주고 싶다고 하면, 한달치(30일)를 쿼리로 요청하게 될 것이다. 정작 우리가 필요한 데이터는 해당 날짜에 있는 데이터 1개만 읽어와서 달력에 해당하는 날짜만 표시해주면 되는데, Firestore는 이러한 쿼리가 없기 때문에 결국 전부 조회하여야 한다. 이럴경우 하루에 10건씩 30일치 300건의 읽는 건수가 잡히는 것이다.
Case 2. 이번엔 커뮤니티 서비스를 만든다고 가정하는데, 커뮤니티 게시글 하단부에 페이지 번호를 매긴다고 가정해보자. 페이지 번호를 매기기 위해서는 결국 모든 Document를 조회해와야 총 몇건인지를 알 수 있게되 모든 Document가 읽는 건수에 모두 포함하게 된다.
예시를 극단적인 상황으로 가정한 부분이 있고, 위의 케이스로 개발하지 않아도 다른 방식으로 개발을 할 수도 있다. 이번 글은 과금 방식을 이해하고자 작성하는 글이니 편하게 봐주시길 바란다.
이제 아래에서 실제 Firestore를 연결하여 테스트를 진행해 CRUD 과금 방식을 좀 더 자세히 살펴보도록 하겠다.
CRUD
먼저 위에서 언급한 Case 1 상황을 가정하여, 1~30일 까지 매일 100개씩의 데이터를 Firestore DB에 Write 하도록 하자.
Future<void> _write() async {
DateTime standard = DateTime(2023, 11, 1);
for (int i = 0; i < 30; i++) {
for (int j = 0; j < 100; j++) {
DateTime date = standard.add(Duration(days: i));
await FirebaseFirestore.instance.collection("test").doc().set({
"index": j,
"date": Timestamp.fromDate(date),
});
}
}
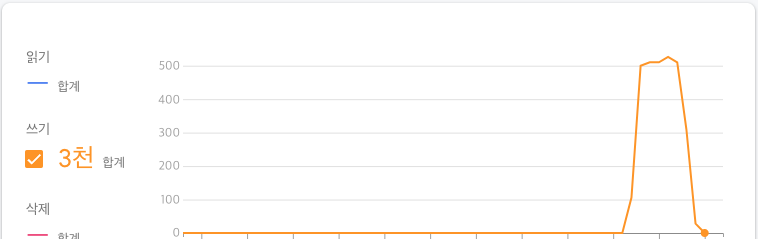
}이제 Firestore 사용량 탭에서 쓰기가 몇 건 발생했는지 확인해 보자.
정확히 3천건이 발생한 것을 확인할 수 있다.
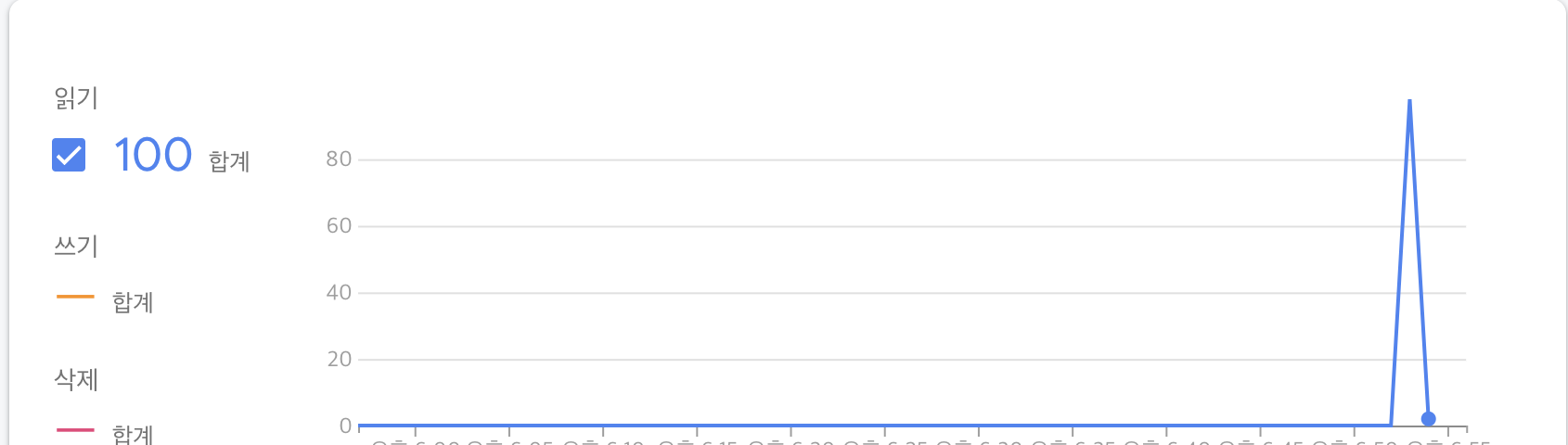
이번엔 20231101 하루의 데이터를 제한 없이 불러와보자. 하루에 100건씩 데이터를 생성했기 때문에 읽기 건수도 100건이 발생해야 할 것이다.
DateTime start = DateTime(2023, 11, 1);
await FirebaseFirestore.instance
.collection("test")
.where(
"date",
isGreaterThanOrEqualTo: start,
isLessThanOrEqualTo:
DateTime(start.year, start.month, start.day, 23, 59),
)
.get();정확히 100건의 읽기가 발생한 것을 확인할 수 있다.
이번에는 전체 문서 중 index 값이 50인 문서 하나만 읽어와보자.
await FirebaseFirestore.instance
.collection("test")
.where("index", isEqualTo: 50)
.get();index 값이 50인 문서는 각 날짜별 1개의 문서만 존재하기에 30건의 Read가 발생한 것을 확인할 수 있다.
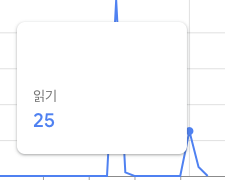 |  |
그렇다면 이번에는 각 날짜별 문서 1개씩만을 읽어오도록 해보자. 이렇게 되면 Read는 30건이 찍혀야 한다.
하지만 Firestore 쿼리로는 해당 쿼리를 구성할 수 없다. 이 부분은 공식 문서에도 나와있는 부분이어서 이럴 경우 어쩔 수 없이 해당 하는 날짜 쿼리의 데이터를 일단 불러오고 그 중에 1건의 데이터만 따로 가져다 사용해야 한다.
이렇게 되면 3천건의 문서를 읽게 된다. 사용자 100명만 조회 하더라도 벌써 Read가 30만건이 발생하게 되는 것이다.
과금을 피하기 위해서는 서비스 구조에 알맞는 데이터베이스를 설계하고 운영하여야 과금 폭탄을 피할 수 있다.
이번에 테스트 하면서 알게된 사실인데, 대시보드에서 직접 데이터베이스를 조회하여도 쓰기, 읽기, 삭제가 모두 적용된다.
Document 부분의 스크롤을 내려 데이터를 계속 불러와 보면 아래와 같이 읽기 건수가 올라가는 것을 확인할 수 있다.
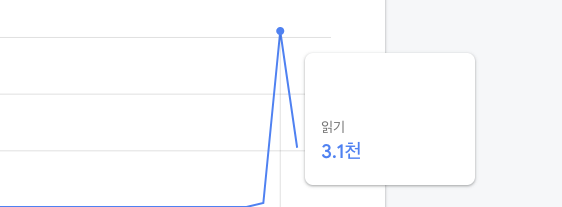
만일 쿼리를 요청한 조건에 해당하는 문서가 없을 경우 사용량은 어떻게 변화할지 테스트를 진행 하였는데, 결과는 건수에 포함되지 않았다.
지금까지 테스트를 위해 생성한 데이터를 삭제하도록 하자. Collection에 포함된 모든 document를 삭제하기 위해 먼저 해당 document를 읽어오고 읽어온 document의 reference를 사용해 순차적으로 삭제해 주어야 한다.
QuerySnapshot<Map<String, dynamic>> snapshot = await FirebaseFirestore.instance.collection("test").get();
WriteBatch batch = FirebaseFirestore.instance.batch();
if (snapshot.docs.isNotEmpty) {
for (QueryDocumentSnapshot<Map<String, dynamic>> document
in snapshot.docs) {
batch.delete(document.reference);
}
await batch.commit();
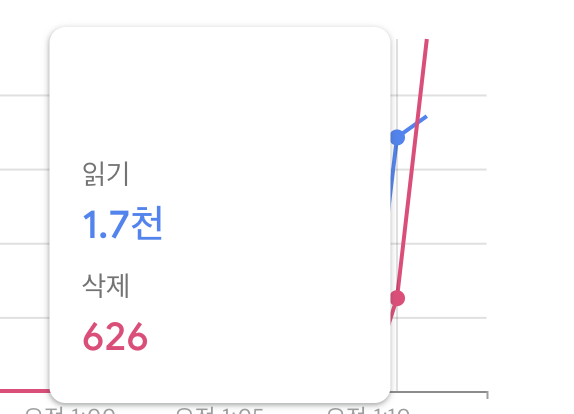
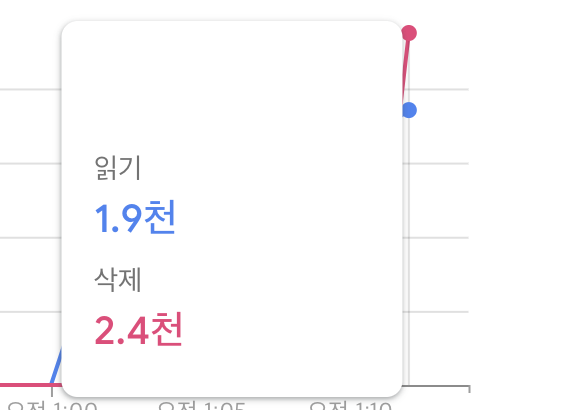
}이제 정상적으로 collection이 삭제되었다. 사용량을 확인해 보자.
3천건을 삭제하기 위해 결국 3천건의 읽기를 발생시킨 것을 확인할 수 있다. 데이터를 삭제시에도 읽기 건수의 할당량을 고려할 수 밖에 없다.
 |  |  |
지금까지 Collection 내에 Document를 생성하고 읽어오고 삭제하는 할당량에 대해서 살펴 봤다면, 이제부터는 Document 내에 쓰여지는 Field의 할당량에 대해서도 살펴보도록 하자.
하나의 document에 10개의 Object로 Field 데이터를 생성하도록 해보자.
TestModel이라는 object를 생성하였다.
class TestModel {
final bool isOne;
final bool isTwo;
final bool isThree;
final bool isFour;
final bool isFive;
final bool isSix;
final bool isSeven;
final bool isEight;
final bool isNine;
final bool isTen;
...
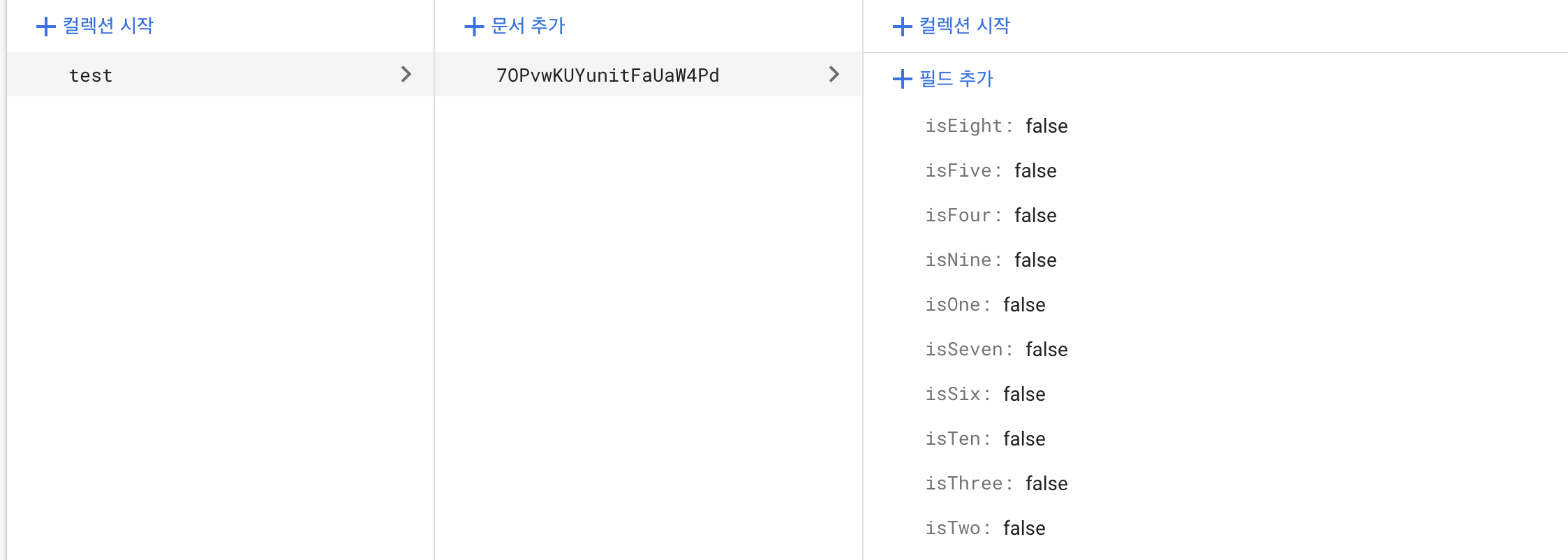
}생성한 TestModel을 Field 데이터로 생성해보자.
TestModel test = TestModel.empty();
await FirebaseFirestore.instance
.collection("test")
.doc()
.set(test.toJson());아래와 같이 Field에 데이터가 추가 되었다.
사용량은 당연히 쓰기 1건만 발생했을 것이다.

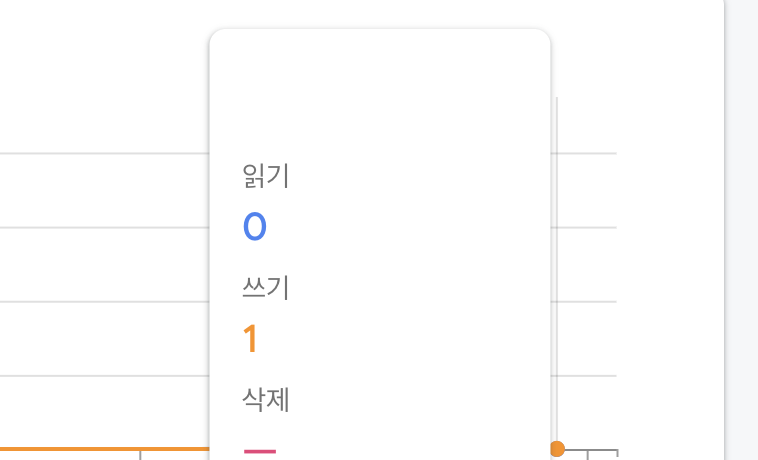
필드 데이터 중 "isTwo"라는 파라미터의 값을 true로 변경해서 업데이트를 해주자. 이 때에 사용량은 어떻게 될까 ?
await FirebaseFirestore.instance
.collection("test")
.doc("7OPvwKUYunitFaUaW4Pd")
.update({
"isTwo": true,
});사용량이 쓰기 1건이 발생하였다.
이번에는 필드 전체의 데이터를 업데이트 해보자. "isFour", "isFive", "isSix" 데이터를 true로 변경하도록 하자. 이번에 사용량은 어떻게 될까 ?
TestModel test = TestModel.empty();
test = test.copyWith(isFour: true, isFive: true, isSix: true);
await FirebaseFirestore.instance
.collection("test")
.doc("7OPvwKUYunitFaUaW4Pd")
.update(test.toJson());역시나 사용량은 1건만 발생했다. 결국 건수는 document를 기준으로 하기 때문에 필드 데이터의 파라미터 수는 사용량에 영향을 미치지 않는다는 것을 확인할 수 있다.

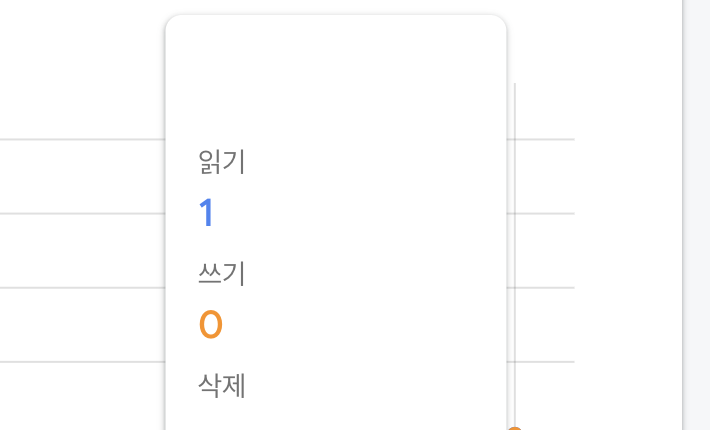
만약에 필드 데이터 업데이트를 요청 했는데, 변경될 필드 값이 없을 경우에는 사용량의 변화가 있을까 ? 테스트를 해보자. 해당 문서를 읽고 읽어온 필드 데이터를 그대로 업데이트 해보자.
DocumentSnapshot<Map<String, dynamic>> snapshot = await FirebaseFirestore
.instance
.collection("test")
.doc("7OPvwKUYunitFaUaW4Pd")
.get();
if (snapshot.exists) {
TestModel field = TestModel.fromJson(snapshot.data()!);
await FirebaseFirestore.instance
.collection("test")
.doc("7OPvwKUYunitFaUaW4Pd")
.update(field.toJson());
}문서를 읽어올 때에 1건이 발생하고, 수정할 필드 데이터가 없더라도 쓰기는 동일하게 1건이 발생한 것을 확인할 수 있다. 이처럼 필드 값의 변화가 없을 때에 불필요하게 업데이트를 하지 않는 것이 좋다.
 |  |
이번에는 Batch를 사용해서 데이터를 쓰고 읽어오도록 하자.
먼저 첫 번째 데이터는 "batch_test" - document에 데이터를 쓰고, 두 번째 데이터는 "batch_test" - "첫 번째 데이터 ID" - "test" - document 구조로 데이터를 batch를 사용해서 저장하도록 하자.
batch를 사용해서 한 번에 데이터를 읽어오거나 저장 하더라도 동일하게 문서 건수가 발생한 만큼만 사용량이 발생하게 되어 2건이 발생한다.
WriteBatch batch = FirebaseFirestore.instance.batch();
DocumentReference<Map<String, dynamic>> first =
FirebaseFirestore.instance.collection("batch_test").doc();
DocumentReference<Map<String, dynamic>> second = FirebaseFirestore.instance
.collection("batch_test")
.doc(first.id)
.collection("test2")
.doc();
batch.set(first, {"test": "test"});
batch.set(second, {"test2": "test2"});
await batch.commit();마무리
이렇게 Resion 위치별 과금과 CRUD 기능별 과금 방식을 살펴 보았는데, 제가 측정한 방법이 100% 맞지는 않을 수도 있으니 필요한 기능에 따라 미리 테스트 해보고 배포하여야 최대한 비용을 줄일 수 있습니다.
Firestore DB를 어떻게 구성하는냐에 따라서도 조회 방식을 변경할 수 있기 때문에, 고민을 해보시면 좋은 해결책이 나올 겁니다. 제 경험상 쓰기, 삭제로 과금된 적은 없었습니다. 항상 읽기로만 과금이 발생 했습니다.
잘 못 설명한 부분이 있거나 궁금하신 부분은 댓글 남겨주시면 답변하도록 하겠습니다 !
긴 글 읽어주셔서 감사합니다.
