
db의 key-value 저장방식 -> log structured 방식을 살펴본 후,
이를 기반으로 db의 인덱스는 어떤 원리이고 어떤 방식들이 있는지 정리하는 글입니다.
Log - structured 스토리지의 인덱스
Log - structured 스토리지
데이터를 원시적으로 저장한다면, key - value를 append only하게 로그 파일에 저장하는 방식일 것입니다. 아래 스크립트 파일처럼 파일에 키와 json형태의 value를 저장하는 방식이다.
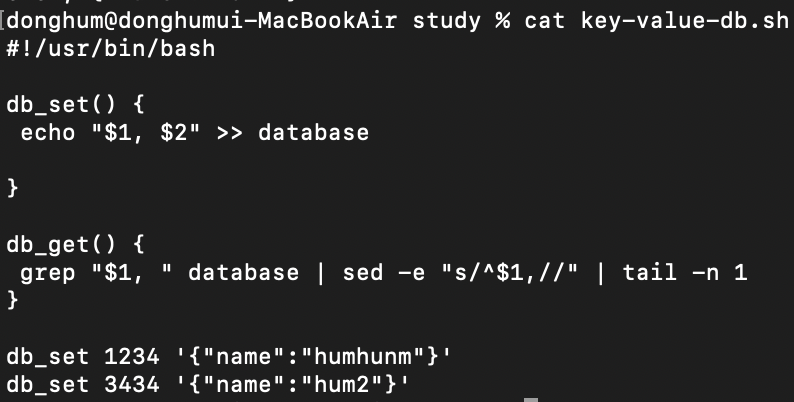

이를 로그 구조 스토리지라 합니다.
full scan하는 단점
이 경우 단점은 읽기(db_get)의 경우 디스크의 로그 파일(database파일)을 full scan하기에 성능이 좋지 않습니다.
이 쿼리 성능의 개선을 위해 메타 데이터를 저장해 이를 이용해 탐색하는 것이 인덱스의 본질입니다.
우선 가장 1차원적으로 메타 데이터를 만들어서 로그파일의 scan을 줄이는 방법이 뭘까요?
hash인덱스
각 키에 대한 로그 파일에서의 저장 위치를 저장해 이를 보고 해당 로그 파일 위치를 바로 탐색하는 hash index방법이 가능합니다.
key에 대한 value의 위치를 저장하고 읽기 시 이 저장파일을 참고해 value에 위치에 바로 접근하는 방법입니다.
예를 들면 아래와 같습니다.

하지만 이렇게 인덱스를 구성해도 남은 문제가 있습니다.
hash index개선 - 불필요한 데이터 조각화, 중복제거
불필요한 데이터가 로그 파일에 계속 저장된어서 불필요하게 읽어야 하는 파일도 많아집니다.
- ex) 키 1234에 대한 value를 수정해도 database파일에는 기존의 {name:humhunm}이 남아있다.
이를 보완하는 방법은 파일을 여러 조각으로(segment file) 나누고 compaction하여 최적화하는 것입니다. 파일들을 일정한 크기로 나누면, 현재 write하고 있지않은 파일에 대해서는 임의적으로 중복제거를 하여 최적화할 수 있습니다.
- ex) purr 라는 키에 대해 2103, 2104 , 2105, 2106,2107,2108을 모두 로그파일에 저장 -> 최신의 2108만 저장하도록 최적화.
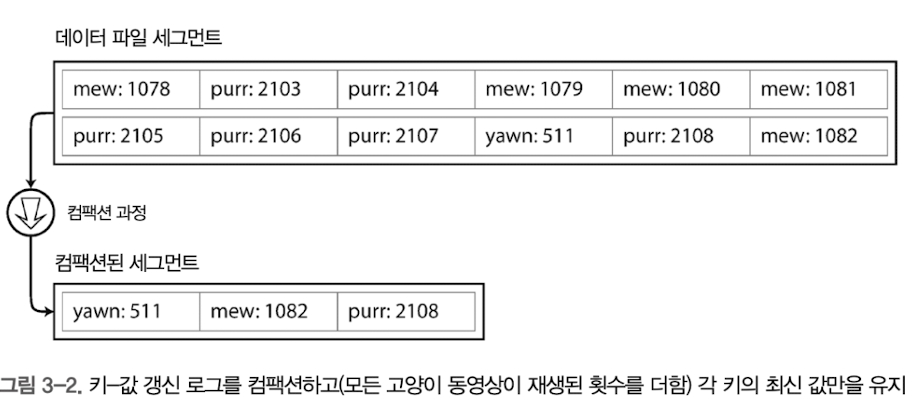
궁금한점: compaction과정에서 로그 파일에 접근할 수가 있을까?
그 사이에 락을 거는건지, 복사본을 만들고 기존거는 삭제하는 방식인지...
hash인덱스의 한계
정리하면 레코드를 append-only한 로그 파일에 저장한다.(log-structured)
쿼리 개선을 위해 key의 로그파일에서 위치를 저장하는 인덱스를 저장하고, 이때 불필요한 데이터 저장과 탐색을 막기 위해 로그 파일을 나누고 불필요한 데이터는 삭제하는 식으로 최적화한다.
하지만 이런 append-only log와 hash index를 이용한 방법은 단 건 조회에서는 효과적이지만 한계도 있습니다.
1) 모든 키를 메모리에 로드해야 하며
2) 범위 질의의 효율이 좋지 않다. 모든 키를 조회해 검사해야 한다.
이런 단점을 보완하기 위한 인덱스 구조가 현대의 nosql에서 사용하는 구조인 LSM-tree,ssTable를 이용하는 방식입니다.
다른 방식 - LSM-tree(log-structured-merge tree):정렬하고 merge
LSM 트리에서는
로그 파일안의 레코드들이 정렬되어있습니다. 즉 ssTable(sorted string table)로 만듭니다.
key에 따라 정렬이 되있으니 범위 쿼리의 수행을 효율적으로 할 수 있습니다.
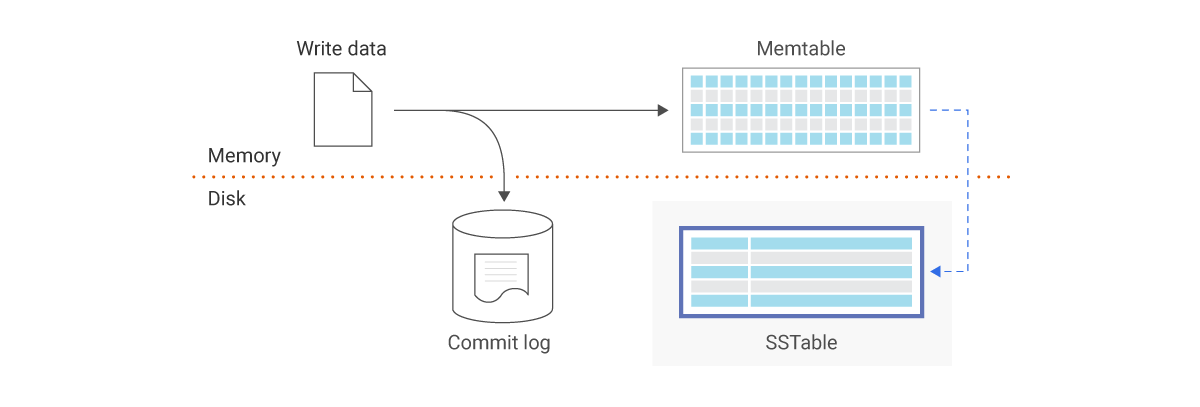
그렇다면 ssTable에 새로운 레코드 저장은 어떻게 할까요?
저장 할 때 마다 디스크의 로그 파일을 전부 다시 정렬하는 건 너무 비효율적인 방법일 것입니다.
이 때문에 메모리의 memtable이 존재합니다.
일종의 레코드 데이터에 대한 트리 형태의 캐시이죠.
일종의 binary-tree로, 이 안의 레코드들은 정렬되고 일정크기를 초과해 저장되면 이것을 디스크에 sstable로 저장합니다.
memtable - sstable의 싱크 문제
이 때 모든 저장이 바로 바로 디스크에 저장되는 게 아니기에 sstable로 저장 전에 db가 강제 종료(crash)된다면 데이터가 누락될 수 있습니다.
이런 문제를 막기 위해 레코드를 실시간으로 sstable이 아닌 로그 파일(commit log)에 따로 저장한다.(crash recovery) 별도의 sort없이 요청된 순서 그대로 commit log에 저장한다.
이러면 모든 키를 메모리에 로드할 필요도 없어집니다. 로그파일(sstable) 내에서 키들이 정렬되있기에, 메모리에 모든 키를 저장할 필요가 없이 인덱스를 타고 간 sstable부터 순차적으로 탐색하면 된다.
결론
정리하자면 LSM 트리방식은 기존의 log-structre방식에서 레코드를 정렬한 후(memtable 이용) 정렬된 채로 로그 파일(sstable)로 merge해 저장하는 방식입니다.
이 sstable또한 compaction으로 중복제거해서 탐색할 공간을 줄입니다.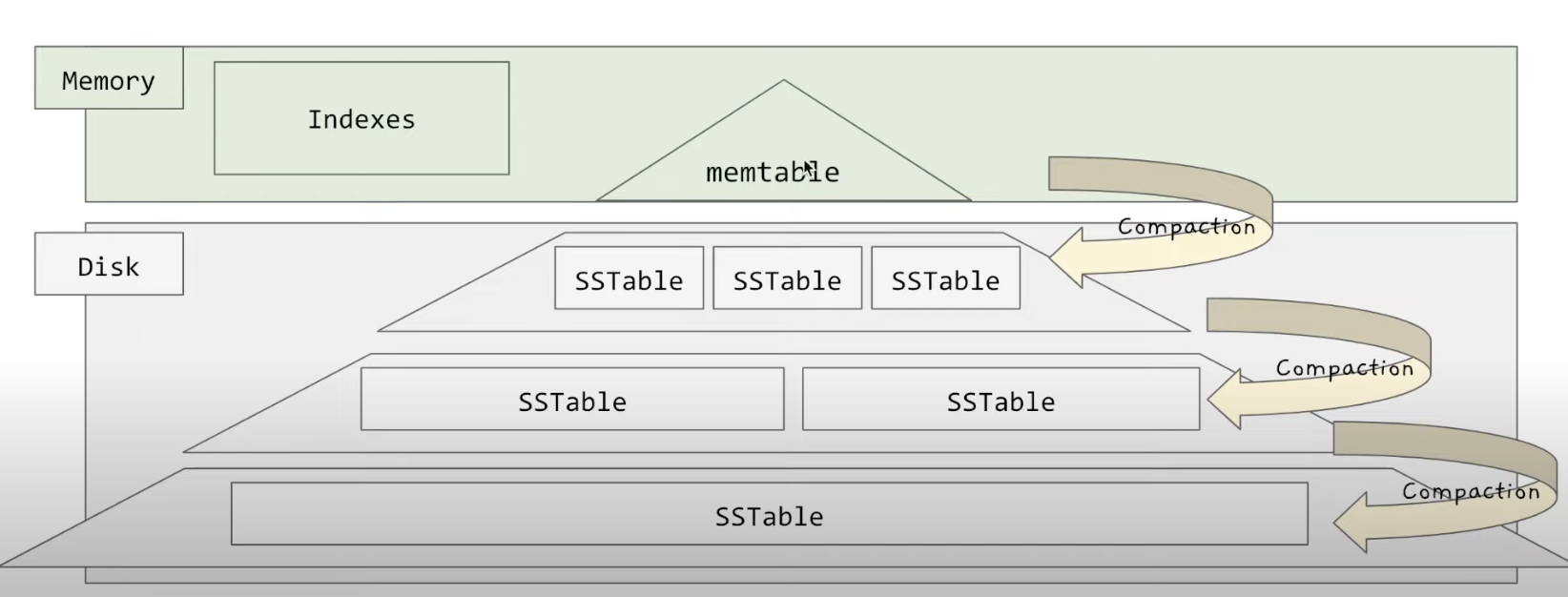
lsm tree에서 delete는 어떻게 이뤄질까?
memtable에 있으면 그대로 삭제gksk?
sstable에 있으면 그대로 삭제. sparse index에 있으면 삭제. 일정한 크기를 꼭 유지할 필요는 없을 것 같은데 더 할 작업이 있나.
soft delete처럼 삭제 필드를 두어서 삭제?
-> 삭제마다 sstable의 재구성이 필요없이 삭제되었으면 오류 발생시키는 방식인가
reference
https://www.youtube.com/watch?v=i_vmkaR1x-I&t=535s
책 데이터 중심 어플리케이션 설계
b tree
인덱스 노드들은 기본적으로는 disk에 저장되어 있다.
인덱스 노드들은 기준 컬럼에 따라 노드들이 b+ tree로 연결되어있다.
b+ tree의 마지막 노드는 디스크에 저장된 실제 레코드이다.
b+ tree의 노드들은 형제 노드끼리 연결되어 있어 범위 검색에 유리.
디스크에 있는 노드들 중 어떤 노드를 메모리에 올릴지는 별도의 알고리즘으로 채택.
lsm은 레코드를 디스크에 정렬해서 저장하는 방식이었다면,
b tree는 레코드를 디스크에 정렬해서 저장하지는 않는 대신 인덱스 노드들을 전부 트리 방식으로 정렬해서 쿼리 성능을 개선하는 방식이다.
b tree의 경우 읽기 작업이 lsm보다 유리한데, 이유는 disk의 로그파일에 접근하는 횟수가 더 낮기 때문이다.
lsm에서는 memtable에 찾는 레코드가 없다면 sparse인덱스를 통하더라도 여러 sstable들을 탐색해야 해 디스크 접근 확률이 보다 높다. 반면 b tree방식에서는 대부의 인덱스 노드들이 메모리에 올려져 있기에 마지막 한 노드에서만 디스크의 로그파일에 접근할 가능성이 높다.
다만 lsm방식이 쓰기 성능에서는 b tree보다 우월하다. 많은 인덱스 수정을 할 필요도 없고 memtable과 log file에 쓰기만 하면 되기 때문이다.
-
질문들
-
db의 인덱스란 어떤 형태로 존재하는 건가?
-
클러스터링 인덱스, 세컨더리 인덱스는 어떻게 다르게 존재하나? *
-
메모리에 페이지로 저장된다는 건 어떤 형태인건가?
-
메모리는(ram) random access로 어떤 주소든 같은 속도로 접근할텐데 페이지로 정렬하면 이득이 있나?
-
b-tree 와 b+tree의 차이?
-
클러스터 인덱스의 리프 노드에는 레코드 자체를 저장한다는데 이러면 저장공간이 부족할텐데? 인덱스의 페이지 트리에 모든 레코드들을 저장하는 건 아닌가? 일단 버퍼풀에 존재하는 것만 인덱스로 만드는 건가 기준이 뭐지.
- 어떤 리프 페이지든 중간의 페이지든 페이지든 버퍼풀에 항상 있다고 보장하는 건 아니다. 페이지의 데이터로 서로 참조하고, 필요하면 디스크에서 불러올 뿐이다.
-
결국 db는 디스크의 i/0를 메모리를 통해서 효율성을 높이는 것인데, 이를 어떤 원리로 가능하게 했나?
https://d2.naver.com/helloworld/7005 -
db의 인덱스는 무엇일까?
- 인덱스는 어떻게 탐색 효율을 높일까
- 디스크와 메모리의 구조, 이 둘의 괴리를 어떻게 해결
- mysql의 구조/ 서버 엔진, 스토리지 엔진
-
b tree는 어떤식으로 만들어져 있나?
- b tree의 페이지 구성
-
해시 테이블
- 자바의 해시 테이블과 뭐가 다른가
버퍼풀과 페이지
버퍼풀은 아래와 같이 구성되어 있다.
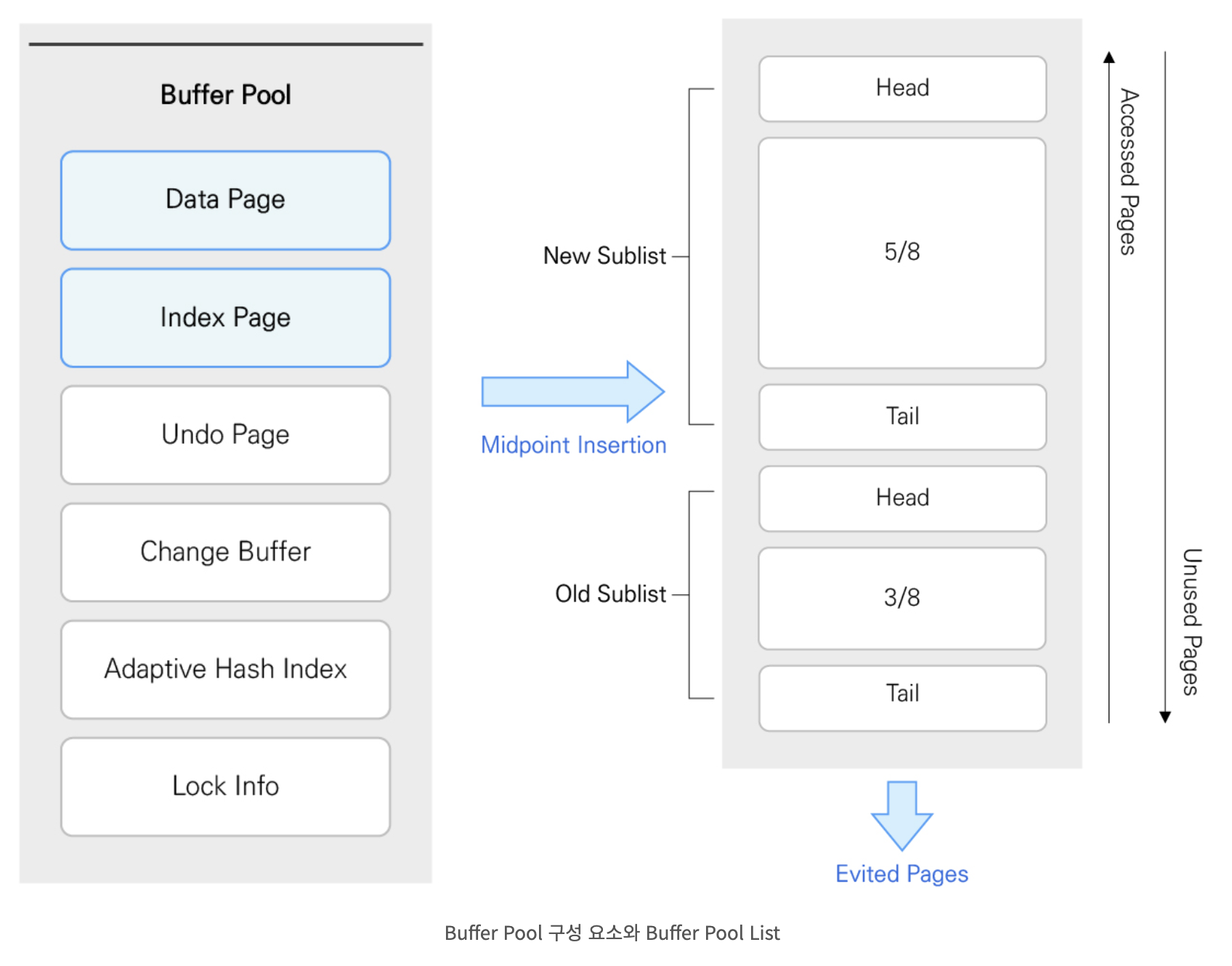
db의 버퍼풀 크기(메모리 크기)를 가능하면 크게 설정하는 게 성능 상 유리하겠다. 서버 메모리의 80퍼 정도를 할당하라는 글도 있지만, 버퍼풀 뿐 아니라 실행엔진의 레코드 버퍼에서도 상당한 메모리 사용을 할 경우가 있기에 이를 고려해서 버퍼풀 크기를 설정하자.
인덱스가 버퍼풀에 페이지 형태로 저장된다는 건 알겠다. 페이지는 그러면 어떤 형태인거지?
db의 페이지는 고정길이이다.(시스템마다 다르게 정의될 수는 있다. 디스크의 페이지 크기와 같을 것이다.)
페이지들이 버퍼풀에 저장되어 있고, 이에 대한 정보를 page directory에 저장한다. 어떤 페이지가 어디에 있는지 page directory를 통해 알아낼 수 있다.
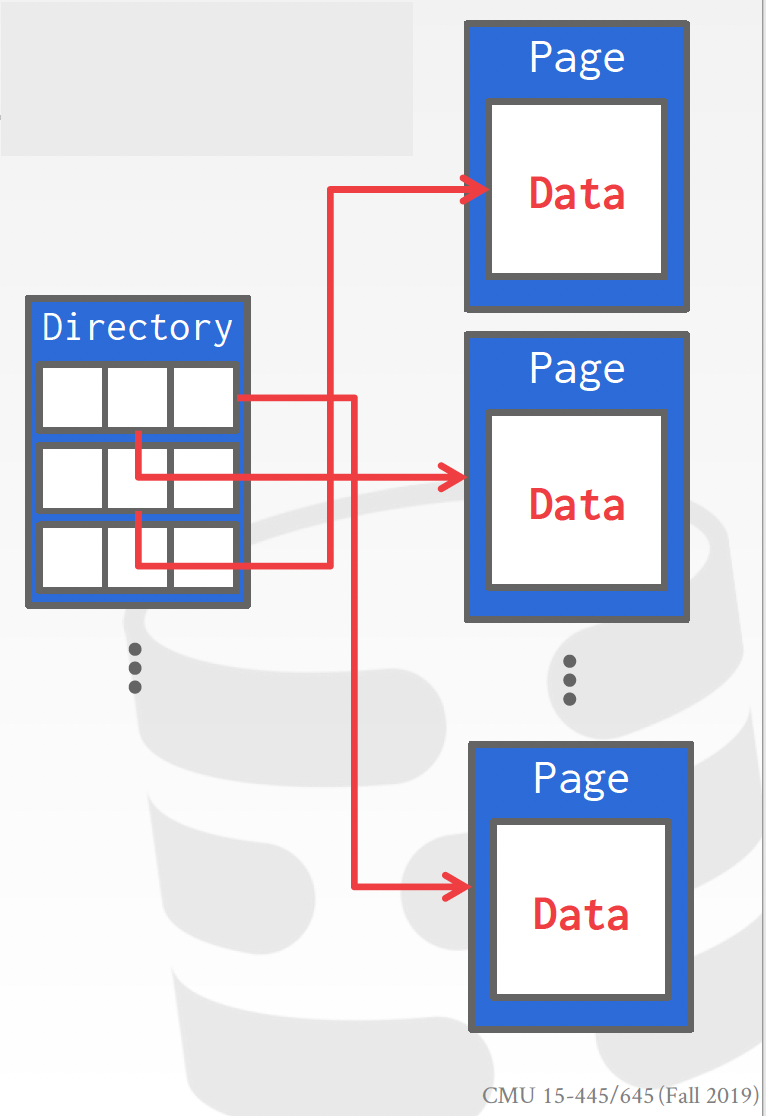
-그러면 페이지 접근시마다 매번 directory에서 주소를 가져온 후 접근하나?
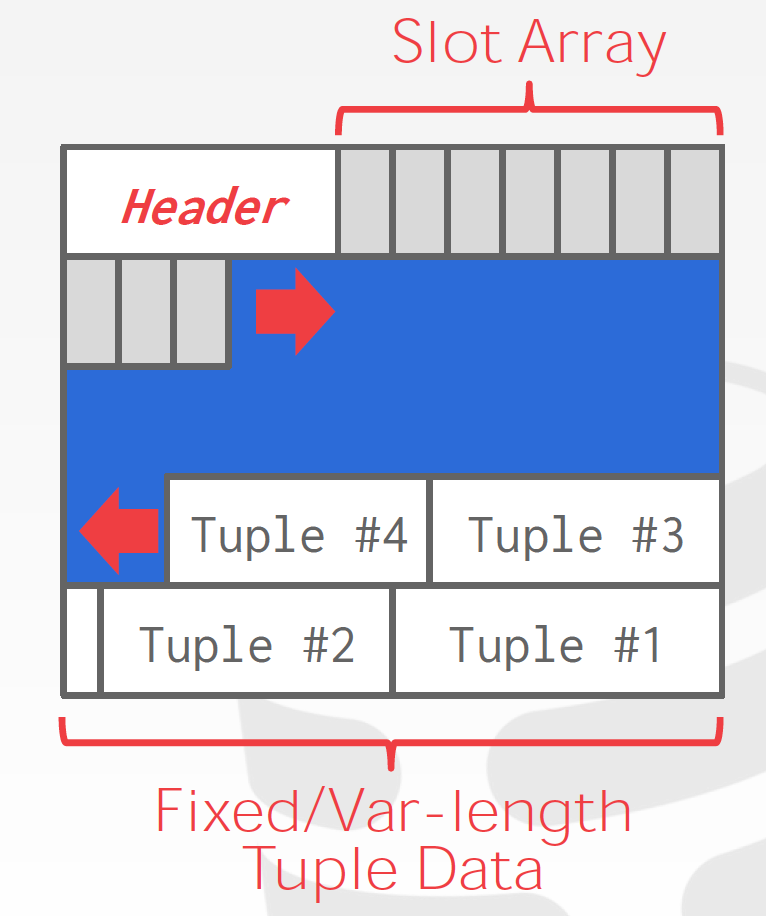
페이지의 구조

튜플을 slot방식으로 저장한다면 아래처럼 header에 tuple의 참조주소를 저장해서 접근하는 식으로 데이터를 저장한다.
인덱스
innodb의 모든 row들은 클러스터링 인덱스(pk)의 순서대로 디스크에 저장된다.
세컨더리 인덱스들은 레코드의 주소를 메모리 주소가 아닌 pk로 사용한다.
아래처럼 리프노드에서 레코드의 주소를 pk로 인지하고,
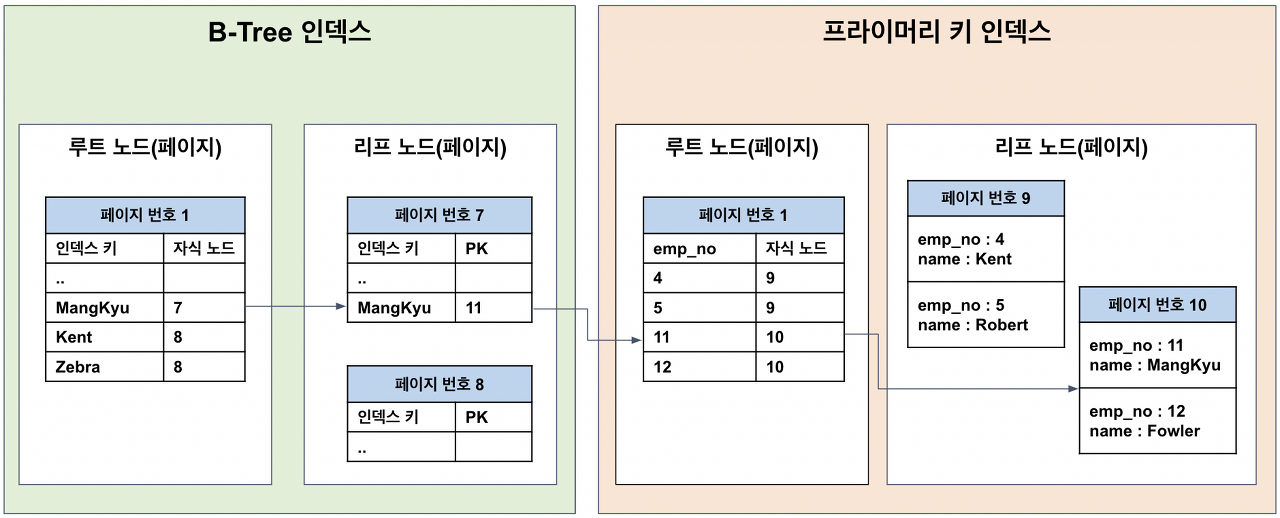
- pk 클러스터 인덱스의 리프노드는 버퍼풀에 존재하는 페이지를 말하는 건가? 아니면 디스크에 있는 레코드정보를 말하는 건가.
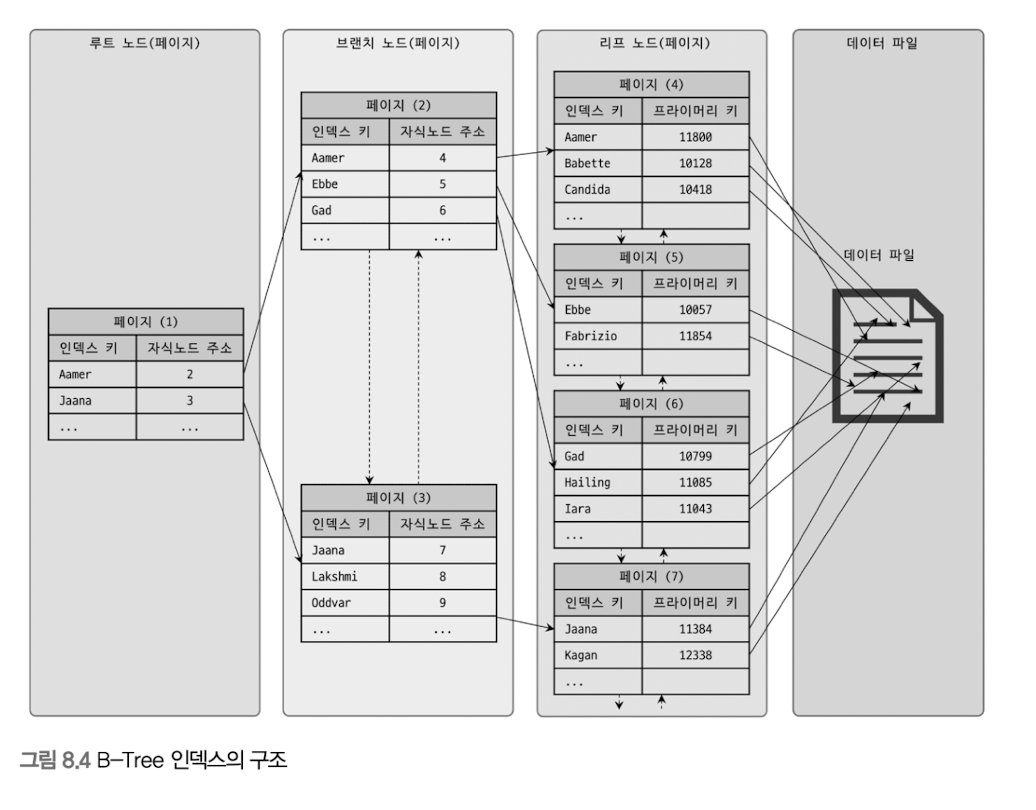
- b- tree라 적혀있지만 리프 노드간에 연결이 있고, 인덱스 키도 중복되는 걸 보니 b+tree를 말하는 듯하다. mysql은 b+tree를 쓴다.
https://dba.stackexchange.com/questions/204561/does-mysql-use-b-tree-btree-or-both
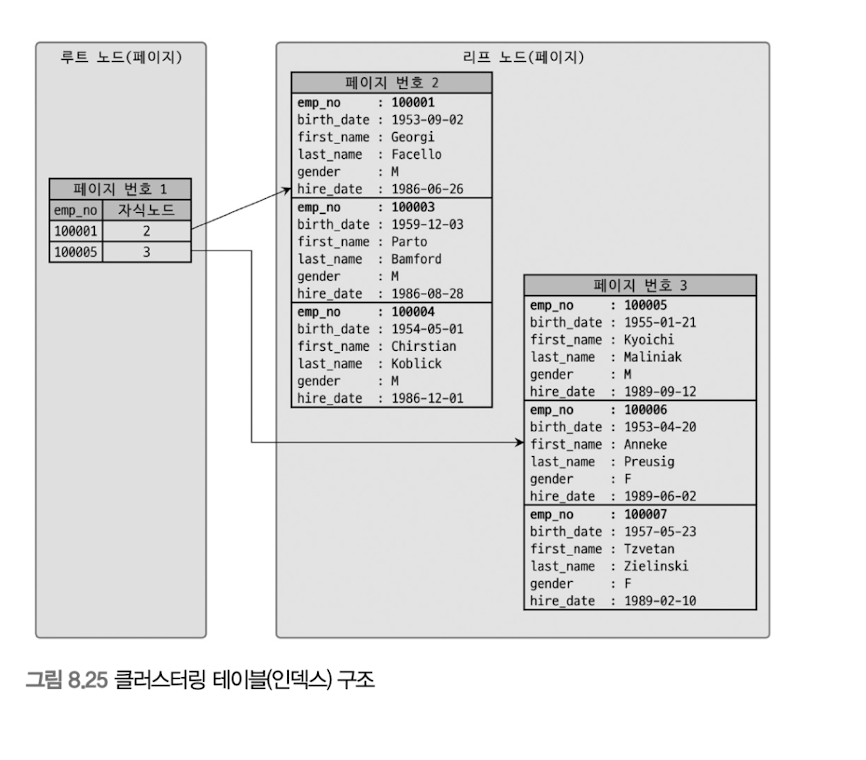
인덱스 페이지 말고 다른 페이지(레코드가 저장된 페이지)도 트리 구조로 저장되나?
-> 레코드가 저장된 페이지가 클러스터링 인덱스의 일부가 되는 것이다.
- pk를 알고 있는 경우, 클러스터링 인덱스가 아니라 hash index에서 바로 레코드를 찾을 수도 있다.
정리
인덱스 정보, 레코드 정보는 페이지 형태로 디스크(데이터 파일)에 저장된다.
이들은 참조를 통해 연결되어 있으며 알고리즘에 따라 버퍼풀에 올라가 있을 수도 없을 수도 있다. (버퍼풀에 인덱스 페이지만을 위한 별도의 저장공간이 있는 건 아니다. 버퍼풀에 있을 확률이 높을 뿐이다.)
레코드들은 클러스터 인덱스 순서대로 디스크에 저장된다. 클러스터링 인덱스 트리의 리프 노드에는 이 레코드 정보가 저장된 페이지가 있다.
세컨더리 인덱스의 리프 노드에는 pk(클러스터링 인덱스 키)가 저장된다.
둘의 차이는 결국 리프노드의 값들이 pk순으로 정렬되어 있느냐이다.
b+ tree와 b- tree의 차이는
1) 노드 b+tree는 리프 노드간에 링크드리스트 처럼 양방향연결이 있다.
2) b+ tree는 노드의 키 값이 중복된다.(리프노드에 모든 정보를 담아야 하기에)
mysql은 b+tree를 사용한다.
의문2
- 버퍼풀의 페이지에 올라와있지 않은 데이터는 디스크로부터 어떻게 찾아오나?
- 카디널리티가 낮으면 어떻게 성능이 안 좋나? (index condition push down해도 성능이 안좋나, 어케 이뤄지지)
- 버퍼풀의 페이지 교체 알고리즘
