Optuna : 특히 기계 학습을 위해 설계된 자동 하이퍼파라미터 최적화 software framework이다.
- 가볍고 다양한 플랫폼에 적용 가능한 아키텍처 ( Python으로 작성됨 )
- pythonic 검색 범위 지정 가능
- 효율적인 최적화 알고리즘 ( optuna.samplers.TPESampler(Tree, default), CmaEsSampler(CMA-ES), GridSampler, RandomSampler)
- 쉬운 병렬화
- 하이퍼파라미터 최적화 분석을 위한 빠른 시각화
예시 코드
- 공식 예제
import optuna
def ackley(x, y):
# ...
return -a - b + math.e + 20
def objective(trial, low, high):
x = trial.suggest_float("x", low, high)
y = trial.suggest_float("y", low, high)
return ackley(x, y)
sampler = optuna.samplers.RandomSampler(seed=10)
# Widest search space.
study0 = optuna.create_study(study_name="x=[0,5), y=[0,5)", sampler=sampler)
study0.optimize(lambda t: objective(t, 0, 5), n_trials=500)
# Narrower search space.
study1 = optuna.create_study(study_name="x=[0,4), y=[0,4)", sampler=sampler)
study1.optimize(lambda t: objective(t, 0, 4), n_trials=500)
# Narrowest search space but it doesn't include the global optimum point.
study2 = optuna.create_study(study_name="x=[1,3), y=[1,3)", sampler=sampler)
study2.optimize(lambda t: objective(t, 1, 3), n_trials=500)
fig = optuna.visualization.plot_edf([study0, study1, study2])
fig.show()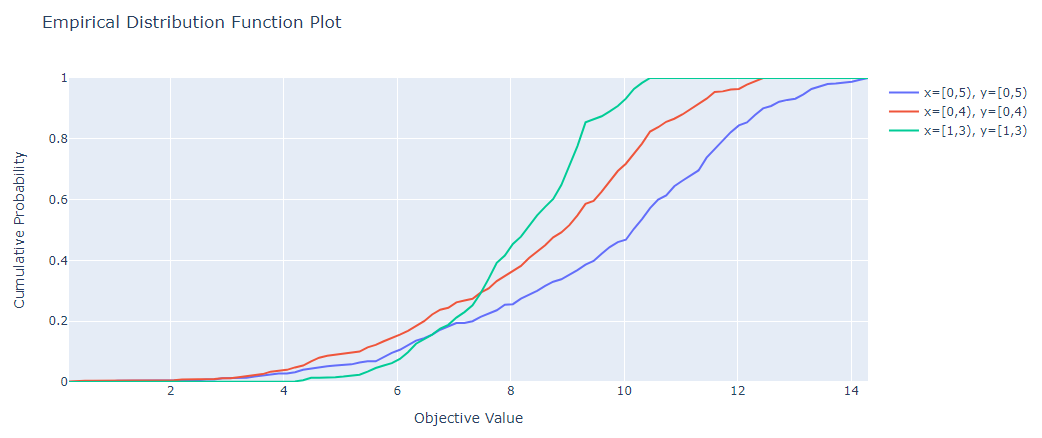
-
사용
- objective function ( 조절할 파라미터와 그 범위를 지정하는 함수 )
import optuna def objective(trial: optuna.Trial): # 모델마다 최적의 하이퍼파라미터값은 다르다. model_name = 'klue/bert-base' learning_rate = trial.suggest_loguniform('learning_rate', low=5e-5, high=0.01) weight_decay = trial.suggest_loguniform('weight_decay', low=4e-5, high=0.01) # 16 ~ 88 사이의 값 리턴(train_batch_size값의 범위) train_batch_size = trial.suggest_int("per_device_train_batch_size", 16, 88) train_dataloader = make_dataloader(train_dataset, model_name, train_batch_size, 'train') valid_dataloader = make_dataloader(valid_dataset, model_name, 32, 'valid') model, optimizer, scheduler = initializer(train_dataloader, 4, model_name, learning_rate, weight_decay) train_dict, valid_dict = train(model, optimizer, scheduler, train_dataloader, valid_dataloader, 4, model_name) gc.collect() # cuda memory 부족 방지 return max(valid_dict['f1']) # 검증데이터의 f1중 가장 큰 값 return- 최적화 실행
study = optuna.create_study(direction="maximize") study.optimize(objective, n_trials=3) # 최적화 실행- 최적화 결과 보기
# objective의 return값이 가장 "maximize"된 값 # (optuna.create_study의 direction) print(f'study.best_trial.value : {study.best_trial.value}') # objective의 return값이 가장 "maximize"된 파라미터 값 print(f'study.best_params : {study.best_params}') # 모든 시도 출력(FrozenTrail의 리스트) # print(f'study.trials : {study.trials}') # 시각화 ( Empirical Distribution Function Plot, EDF, 경험적 분포 함수) optuna.visualization.plot_edf(study)
optuna.trial.Trial(study, trial_id)의 attributes와 method 목록
suggest : value를 제안함.
-
suggest_categorical(name, choices) : choices는 list이다.
kernel = trial.suggest_categorical("kernel", ["linear", "poly", "rbf"]) -
suggest_discrete_uniform(name, low, high, q) : low부터 hight까지 q만큼의 간격을 두고 list를 구한다. ( 이산 균등 분포 값이 선택됨 )
sample = trial.suggest_discrete_uniform("sample", 0.1, 1.0, 0.2)- [0.1, 0.1+0.2, 0.1+2 x 0.2+ ... + 0.1+k x 0.2], low+kq <= high
-
suggest_float(name, low, high, *[, step, log]) : low부터 high 사이의 float값 중 선택됨 (step이 있다면 step만큼의 간격을 가진다)
t = trial.suggest_float("t", 0.2, 0.8, step=0.1) -
suggest_int(name, low, high[, step, log]) : low부터 high 사이의 정수값 중 선택됨
n_estimators = trial.suggest_int("n_estimators", 50, 400) -
suggest_loguniform(name, low, high) : low부터 high까지 로그 함수 선상에 있는 값들 중 선택됨 (low == high일 때 low return)
c = trial.suggest_loguniform("c", 1e-5, 1e2) -
suggest_uniform(name, low, high) : low부터 high까지 균일 분포 값들 중 선택됨 (low == high일 때 low return)
momentum = trial.suggest_uniform("momentum", 0.0, 1.0)
attributes
- datetime_start, distributions, number, params, system_attrs, user_attrs
- report(value, step) : 주어진 step에서의 objective 함수 값을 보고한다.
- should_prune() : prouned가 되었는지 아닌지 제안
- set_user_attr(key, value), set_system_attr(key, value) : trial에서 system, user 속성값 지정
Plot 함수
Tutorial/Quick Visualization for Hyperparameter Optimization Analysis
import optuna
from optuna.visualization import plot_contour
from optuna.visualization import plot_edf
from optuna.visualization import plot_intermediate_values
from optuna.visualization import plot_optimization_history
from optuna.visualization import plot_parallel_coordinate
from optuna.visualization import plot_param_importances
from optuna.visualization import plot_slice
# 최적화 기록 시각화 - x : trails, y : objective value
plot_optimization_history(study)
# trial의 학습 곡선 시각화 - x : step, y : intermediate value
plot_intermediate_values(study)
# 고차원 매개변수 관계 시각화 - x : 매개변수, y : objective value
plot_parallel_coordinate(study) # 아래는 매개변수 선택
plot_parallel_coordinate(study, params=["bagging_freq", "bagging_fraction"])
# 초매개변수 관계 시각화(매개변수끼리의 관계 시각화)
plot_contour(study) # 아래는 매개변수 선택
plot_parallel_coordinate(study, params=["bagging_freq", "bagging_fraction"])
# 개별 하이퍼파라미터를 슬라이스 플롯으로 시각화 - x : 파라미터, y : objective value, spot:trials
plot_slice(study)
plot_slice(study, params=["bagging_freq", "bagging_fraction"])
# 매개변수 중요도를 시각화 - x : importance for objective value, y : hyperparameter
plot_param_importances(study)
optuna.visualization.plot_param_importances(
study, target=lambda t: t.duration.total_seconds(), target_name="duration"
) # 어떤 하이퍼파라미터가 trail duration에 영향을 미치는지 중요성 알아보기
# EDF(경험적 분포 함수) 시각화 - x : objective value, y : cumulative probability
plot_edf(study)FrozenTrail(값 변경 불가능)
확실하지 않다
objective function 내에서 값 변경은 불가능하다 -> FrozenTrail
-> set_system_attr, set_user_attr를 통해 attributes는 변경할 수 있다.
trial.set_user_attr("evaluation time", datetime.datetime.now())- max batch_size 찾기 -> FrozenTrail로 인해 불가능. 미리 찾아보고 와야하거나, objective를 return시킨 뒤, 다시 지정해야한다.(or 매개변수로 주어야한다.)
- 아래는 수정이 안된 예시이다.
def objective(trial):
# 의도 : max_batch_size에서 cuda memory 에러가 났을 때, 2씩 빼서 할당할 수 있는 가장 큰 max_batch_size 찾기
# max_batch_size를 찾기 위해 성공할 때까지 돌리려했으나, 한번 할당되면 Frozen된다.
global max_batch_size
while True :
try :
# 한번 할당시켰다면, 수정 불가능 ( FrozenTrail로 인해서 objective function이 한번 실행될 때까지 값은 바뀌지않는다. )
train_batch_size = trial.suggest_int("per_device_train_batch_size", 16, max_batch_size)
train_dataloader = make_dataloader(train_dataset, model_name, train_batch_size, 'train')
model, optimizer, scheduler = initializer(train_dataloader, 4, model_name, learning_rate, weight_decay)
start = time.time()
train_dict, valid_dict = train(model, optimizer, scheduler, train_dataloader, valid_dataloader, 4, model_name)
end = time.time()
print(f"time : {(end - start)//60}분 {(end - start)%60}초")
break
except RuntimeError as e : # CUDA memory error 났을 때
train_batch_size -= 2
max_batch_size = train_batch_size # 적용되지 않는다.
print(f'out of memory with train_batch_size : {train_batch_size}')