목표
- 문제 task 구별
- benchmark dataset 및 model 알기
NLU ( Natural Language Understanding, 자연어 이해 )
NLU의 목표는 자연어를 이해해 특정 task를 풀 수 있는 모델이 정보 처리 자동화를 하는 것이다.
모델이 시간이 많이 소요되는 반복적인 업무(우리가 보고 싶은 정보만 뽑고 정리를 하는 업무)를 대신 수행해줄 것이다.
- Syntactic : 문법적으로 옳은 문장인지 구분할 수 있는가?
- Semantic : 문장의 의미를 아는가?
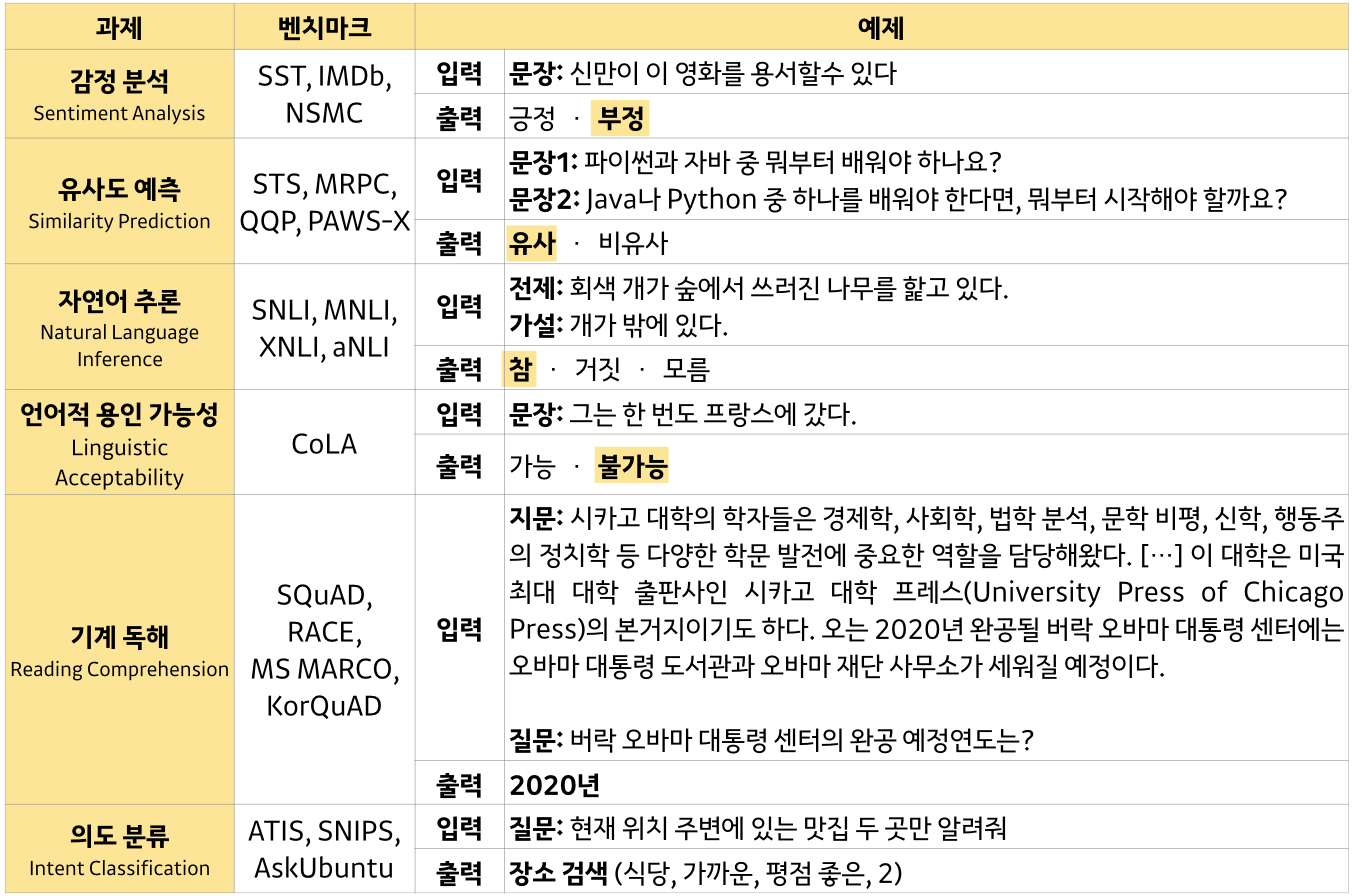
- 감정 분석 ( 긍정/부정 ), 문장간 유사도, 의도 파악, 질문에 대답, 추론 등
- 감정 분석 ( 긍정/부정 ), 문장간 유사도, 의도 파악, 질문에 대답, 추론 등
언어를 이해한다는 것은?
➡ "기계(모델, 프로그램)가 문법을 잘 맞추고 문장이나 대화의 의미를 잘 알고 있다."는 의미
NLU의 task ➡ 사용되는 예시
- 문법 검사 ➡ 자동 문법 교정
- 감성 분석 ( SST ) ➡ 상품&서비스 리뷰 데이터 긍부정 판별
- 문장 유사성 ( paraphrase )( STS, MRPC, QQP ) ➡ 유사 문서 클러스터
- ex) Quora Question Pair Competition : 유사한 Question을 묶는 대회
- 전문가가 질문에 답변해주는 사이트에서 이전에 이미 답변되어있는 비슷한 내용의 질문이 많이 게시됨. 쉽게 찾아보기 위해서 유사한 Question을 묶어 보여주기 위함
- ex) Quora Question Pair Competition : 유사한 Question을 묶는 대회
- 추론 ( MNLI, RTE ) ➡ 자동 내부 및 회계 감사
- 언급 대상 추론 ( WNLI ) ➡ QA, 요약, 번역 등의 성능 향상을 위해 필수 요소
- QA ( SQuAD ) ➡ 검색 시스템 스닛펫
Benchmark
Benchmark : 세계에서 가장 공신력 있는 NLU 대회
dataset이 open되어 있기 때문에 어떤 것이 SOTA 모델인지 쉽게 비교할 수 있다.
GLUE
GLUE ( General Language Understanding Evaluation, 일반 언어 이해 평가 ) : NLU System을 교육, 평가 및 분석하기 위한 resource의 모음
- baseline : BiLSTM
- dataset ( 9가지 )
- single-sentence tasks
- 문법 검사 ( acceptability )
- CoLA (Corpus of Linguistic Acceptability)
- 감성 분석 ( sentiment )
- SST-2 (Stanford Sentiment Treebank)
- 문법 검사 ( acceptability )
- similarity and paraphrase tasks
- 문장 유사성 : classification (same/not same) / Regression
- MRPC (Microsoft Research Paraphrase Corpus)
- QQP (Quora Question Pairs)
- STS-B (Semantic Textual Similarity Benchmark)
- label : 1 ~ 5 (similarity score)
- 문장 유사성 : classification (same/not same) / Regression
- inference tasks
- 추론 ( NLI )
- MNLI (Multi-Genre Natural Language Inference)
- QNLI (Question Natural Language Inference) : QA/NLI
- RTE (Recognizing Textual Entailment)
- 언급 대상 추론 ( coreference/NLI )( it, them의 대상 찾기 )
- WNLI (Winograd Natural Language Inference)
- 추론 ( NLI )
- single-sentence tasks
| Corpus | task | Metrics | label |
|---|---|---|---|
| CoLA | acceptability, 문법적 판단 | Matthews corr. | acceptable / not acceptable |
| SST-2 | sentiment, 감성 분석 | acc. | positive / negative |
| MRPC | paraphrase, 문장 유사성 | acc. / F1 | same / not same |
| QQP | paraphrase, 문장 유사성 | acc. / F1 | same / not same |
| STS-B | sentence similarity, 문장 유사성 | Pearson/Spearman corr. | 1 ~ 5 (similarity score) |
| MNLI | NLI, 추론 | metched acc. / mismatched acc. | entailment / neutral / contradiction |
| QNLI | QA/NLI, 질문 답변/추론 | acc. | entailment / not entailment |
| RTE | NLI, 추론 | acc. | entailment / not entailment |
| WNLI | coreference/NLI, 언급 대상 추론 | acc. |
SuperGLUE
SuperGLUE : GLUE보다 더 어려운 NLU task를 모은 Benchmark
- baseline : Bert
- dataset ( 8가지 )
- QA
- BoolQ (Boolean Questions)
- COPA (Choice of Plausible Alternatives)
- MultiRC (Multi-Sentence Reading Comprehension)
- ReCoRD (Reading Comprehension with Commonsense Reasoning Dataset)
- NLI
- CB (CommitmentBank)
- RTE (Recognizing Textual Entailment)
- WSD
- WiC (Word-in-Context)
- coref.
- WSC (Winograd Schema Challenge)
- QA
SQuAD
SQuAD ( Stanford Question Answering Dataset, 스탠포드 질문 답변 데이터 셋 ) : 독해 dataset으로, Wikipedia 기사 set에 대해 crowdworkers(기계가 아닌 사람)가 제기한 질문으로 구성되며, label(답변)은 해당 읽기 구절의 텍스트 또는 범위이거나 답이 없을 수 있다.
➡ 지문이 주어졌을 때 질문에 대한 답을 찾는 것
- SQuAD2.0 : SQuAD 1.1에 새로운 5만개 이상의 어려운 질문이 추가된 task ( ex. 표에서 답을 찾는 경우, 답변이 없는 경우 등)
NLP task SOTA model
"각 NLP task별 SOTA(가장 우수한 모델)은 무엇일까?"
- GLUE
- 문법 ➡ biLSTM, BERT(RoBERTa)
- 감성 분석 ➡ BERT(RoBERTa)
- 문장 유사성 ➡ Bert(RoBERTa)
- 추론 ➡ T5, Bert(ALBERT, DeBERTa)
- 언급 대상 추론 (WNLI) ➡ Bert(SpanBERT, RoBERTa)
- SQuAD
- QA ➡ T5, Bert(Bigbird), XLNet
- QA ➡ T5, Bert(Bigbird), XLNet
Applications
Benchmark task 이외에 NLU가 활용되는 예
- 분류 ➡ 이탈 고객 예측, 상품 카테고리 분류, 위험 판별
- 군집화 ➡ 유사 제품군 군집화, 유사 키워드 생성
- Vectorize ➡ distance ( K-means )
참조
