[Python] Pandas_대학원 입학과 스펙의 연관성 #1

우리가 흔히 말하는 '스펙' (GRE 점수, Research 여부, TOEFL 시험 성적 등)이 대학원 입학에 미치는 영향과 가장 중요한 역할을 하는 요소에 관한 데이터 분석
#1 에서는 기본적인 환경 세팅하는 방법, 테이블 구조 등 정보 확인 및 변경, 간단한 결과 출력 방법에 대해서 적었습니다
***해당 분석은 Google Colab를 활용하여 출력한 자료들입니다
환경 세팅하기
경고 무시
import warnings
warnings.filterwarnings('ignore')kaggle 설치
!pip install kaggle.json token 업로드
from google.colab import files
files.upload()kaggle.json을 사용 가능하도록 설정
!mkdir -p ~/.kaggle
!cp kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.jsonKaggle 데이터 불러오기 (zip 파일일 경우 unzip 해주는 방법)
!kaggle datasets download -d [Kaggle 데이터 작성자 / 데이터 이름]
!unzip '*.zip'pandas 불러오기
import pandas as pd.csv 파일 불러오기 & 변수'data'에 저장하기
data = pd.read_csv('CSV파일이름.csv')파일 Manipulation
shape 함수로 테이블 전체 ROW(행)과 COLUMN(열)의 수를 파악하기
data.shape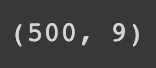
(n, m)으로 출력되며 n은 ROW m은 COLUMN수를 표현한다
***shape함수에는 ()에 유의하자
~.describe() 함수로 전체 COLUMN에 대한 파생 정보 확인
data.describe()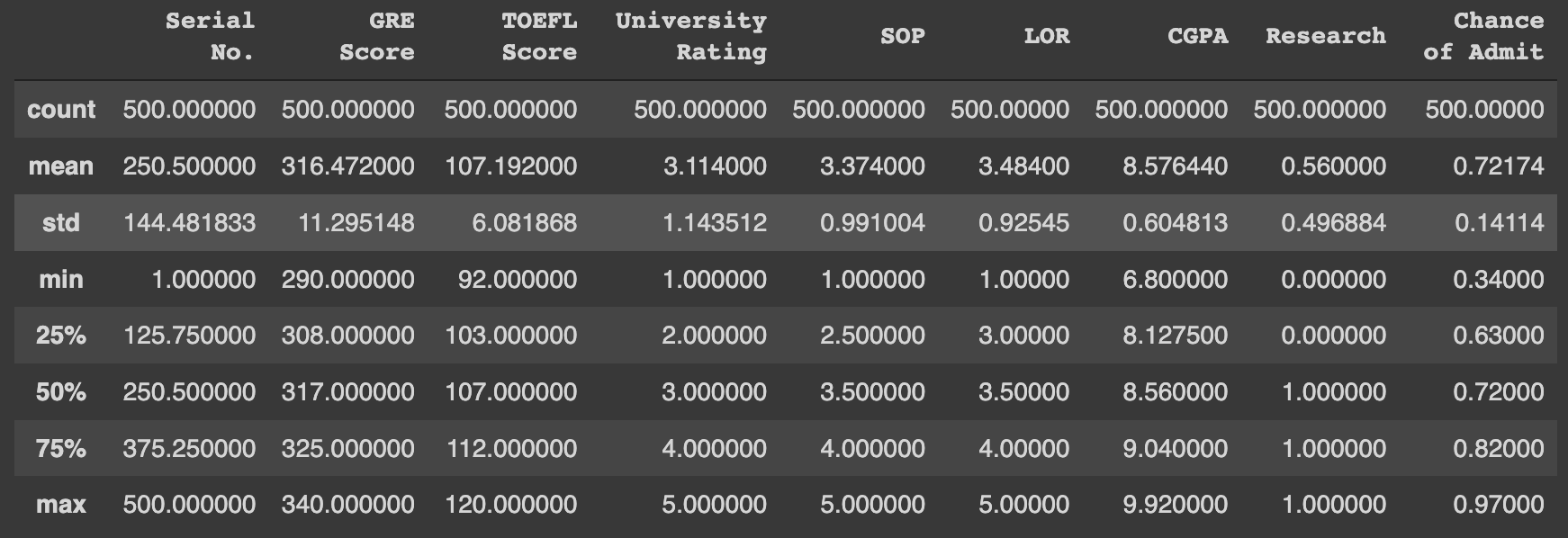
각 열에 대하여 위와 같이 min, max 등의 자료를 보여준다
~.info()함수로 NON-NULL 데이터 갯수와 데이터타입 확인하기
data.info()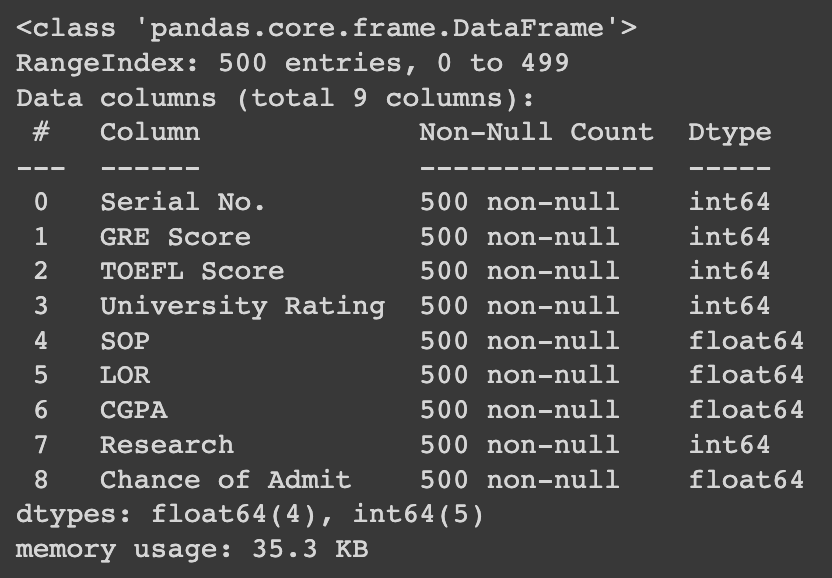
데이터타입 그룹으로 갯수 반환 및 memory usage또한 출력해준다
~.isna().(sum) 함수로 NULL 데이터 갯수 확인
data.isna().(sum)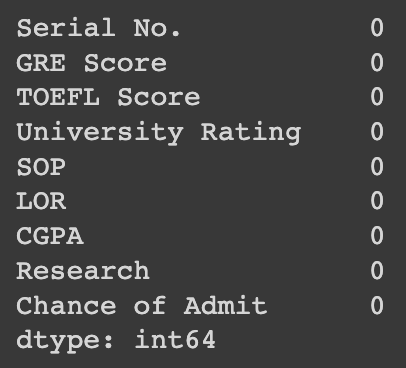
info와 다르게 NULL인 각 COLUMN에 대한 NULL 데이터 갯수를 확인하고 싶을 때 활용한다
data.index로 start, stop, step 확인하기
data.index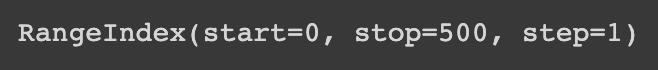
start는 시작하는 행의 ROW_NUMBER
stop은 마지막 행의 ROW_NUMBER
step은 각 행의 증가율이다 (위 예시에서 출력된 1은 각 ROW_NUMBER가 1씩 증가하고 있음을 보여준다
~.columns로 각 COLUMN명 확인하기
data.columns
파일 내 존재하는 모든 COLUMN을 위와 같이 표기해준다
테이블 구조 변경하기
~.drop함수로 원하지 않는 COLUMN은 빼고 출력하기
data.drop(columns = ['Serial No.'])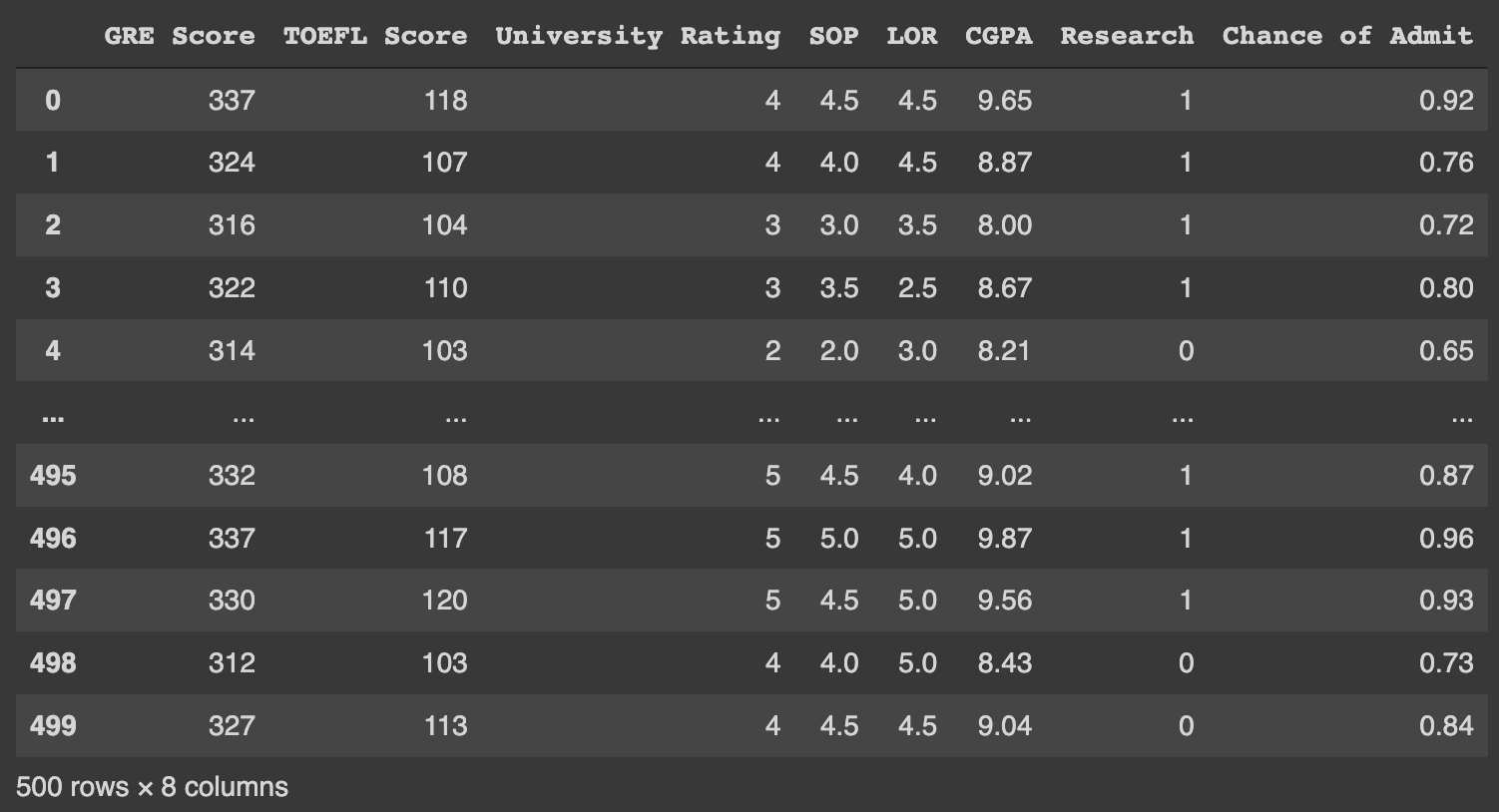
주의해야할 점은 위와 같이 출력하면 원본 파일에서는 계속 살아있다 그 결과로 아래와 같이 data.head()로 다시 출력해보면 'Serial No.' COLUMN을 다시 출력할 수 있다
~.drop (+ inplace = True) 함수로 원하지 않는 COLUMN 완전 삭제 처리
data.drop(columns = ['Serial No.], inplace = True)
data.head()data.head() 적용해야 변경된 테이블 구조가 출력된다
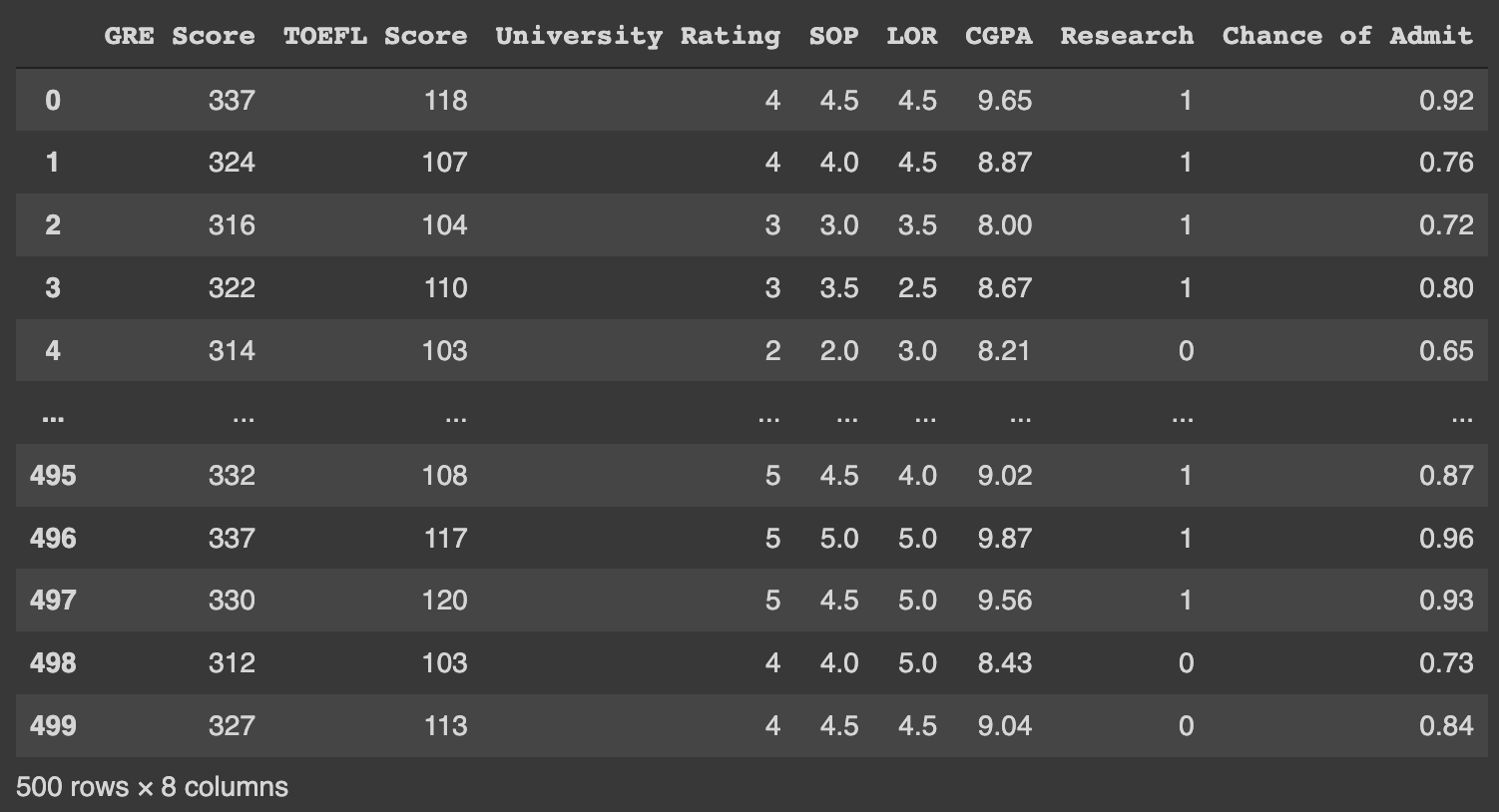
~.rename(columns = {'기존컬럼명' : '새로운컬럼명'} 함수로 COLUMN명 변경하기
data.rename(columns = {'GRE Score' : 'GRE', 'TOEFL Score' : 'TOEFL', 'University Rating': 'Univ.', 'LOR ': 'LOR', 'Chance of Admit ':'Admit'}, inplace = True)
data.head()위 함수도 drop 함수와 동일하게 inplace = True없이는 원본 파일을 변경시키지 않는다
Data를 출력하는 여러가지 방법
head() 함수
data.head()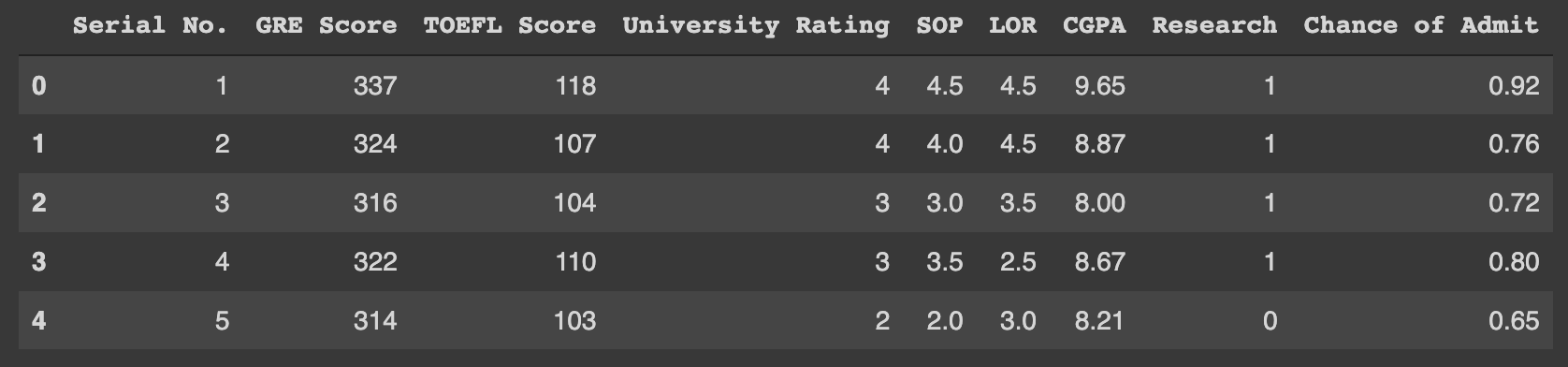
위에서 보는 것과 같이 테이블이 구성되어 있다.
~.head()는 테이블 데이터 상단 (default) 5개의 ROW를 출력하여 보여주는 역할을 하며 ()안에 숫자를 넣으면 그 수 만큼 출력한다
tail() 함수
data.tail()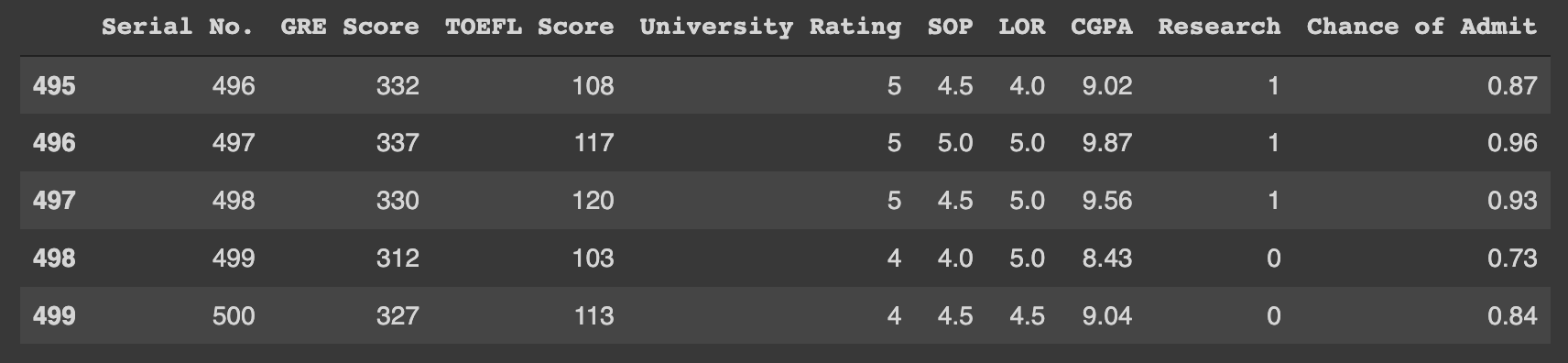
tail함수는 head와 반대로 최하단에 있는 (default) 5개의 ROW를 출력하며 ()안에 숫자를 넣으면 그 수 만큼 출력한다
특정 ROW 출력_슬라이싱
data[1:4]
파이썬의 슬라이싱 기법을 활용할 경우 위와 같이 출력된다.
***최상단 row는 0 부터 시작하는 것을 명시할 것
특정 COLUMN 출력_컬럼명
data[['TOEFL', 'SOP']]
data[['컬럼명']] 으로 사용하며 원하는 만큼 출력이 가능하다
특정 ROW와 COLUMN 출력_슬라이싱 & 컬럼명
data[0:1][['SOP']]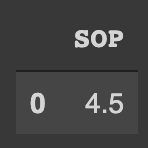
iloc을 활용한 출력방법_Only 숫자
data.iloc[0:2, 2:7]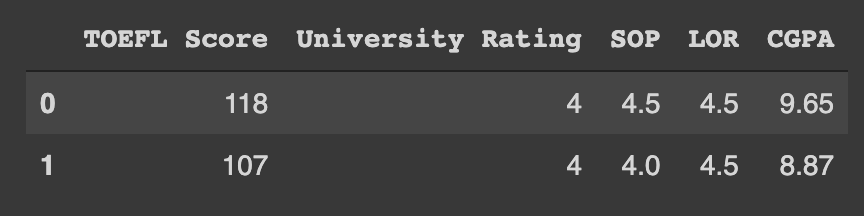
[n1:n2, m1:m2]로 구분지어 사용한다
n과 m은 모두 숫자이다
loc을 활용한 출력방법_with 문자
data.loc[1:4, 'TOEFL Score': 'CGPA']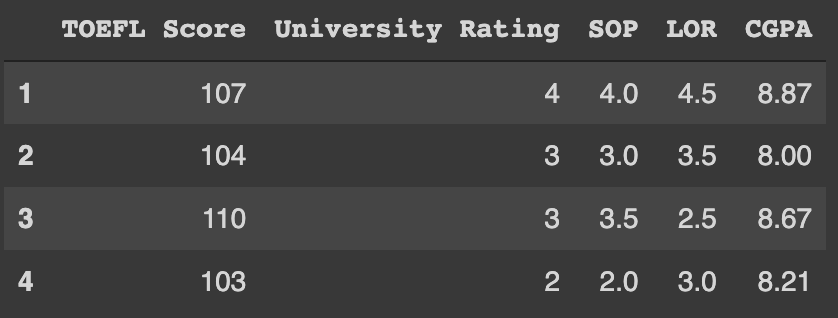
[n1:n2, a1:a2]로 구분지어 사용한다
n은 숫자이며 a는 문자열이다
