현재 논문의 인용관계에 대한 시각화를 해주는 프로젝트를 진행중입니다.
이를 위해 논문에 대한 데이터가 필요했었는데, 이를 무료로 제공해주는 DOI를 등록하는 기관인 CrossRef 라는 회사에서 자체적인 API를 제공합니다.
https://www.crossref.org/
DOI는 “Digital Object Identifier”의 약어이며, “디지털 객체의 식별자(identifier of a digital object)”가 아니라 “객체의 디지털 식별자(digital identifier of an object)”를 의미한다. (논문의 주민등록번호라고 생각하시면 될 듯 합니다.)
다행히 프로젝트에 필요한 데이터를 제공해주는 api가 있다는 것은 다행이었고, 해당 API가이드에서도 데이터 마이닝에 대한 주의사항을 적어 두는 것을 보아, 무료로 데이터 마이닝도 문제가 없다는 뜻으로 받아들이고 우리 프로젝트의 데이터를 crossref API에 의존하기로 결정하고 진행했었습니다.
우리의 프로젝트에서 CrossRef API를 사용하는 곳은 크게 3가지로 나눌 수 있었습니다.
- 논문의 검색 자동완성 기능.
- 논문을 검색했을 때 나오는 검색 화면.
- 한 논문의 인용한 자식노드들을 탐색하는 과정.
처음 설계 단계에서는 CrossRef API를 사용하면 모두 해결할 수 있을 것 같았고, 자동완성기능을 위한 API호출에 Debounce를 걸어주면 적당한 API호출이 될 것이라 생각하고 진행했었습니다.
문제점
문제1. API 응답속도가 느리고 변동이 심하다.
API에 모든 데이터를 전적으로 의존하기 때문에 CrossRef API 속도에 따라 우리 서비스의 속도가 결정되는 안좋은 상황에 놓였습니다.
자동완성검색의 경우에는 google의 예시로 빠르게 표시해주어야 하는데 빠르면 3초 느리면 10초간 로딩창을 보아야하는 상황이 발생했었습니다.
해결방안.
=> 자동완성기능을 위한 자체 DB를 구축해보자.
이 DB는? 검색엔진에 자주 사용된다는 elasticseach를 활용하여 보기로 했습니다.
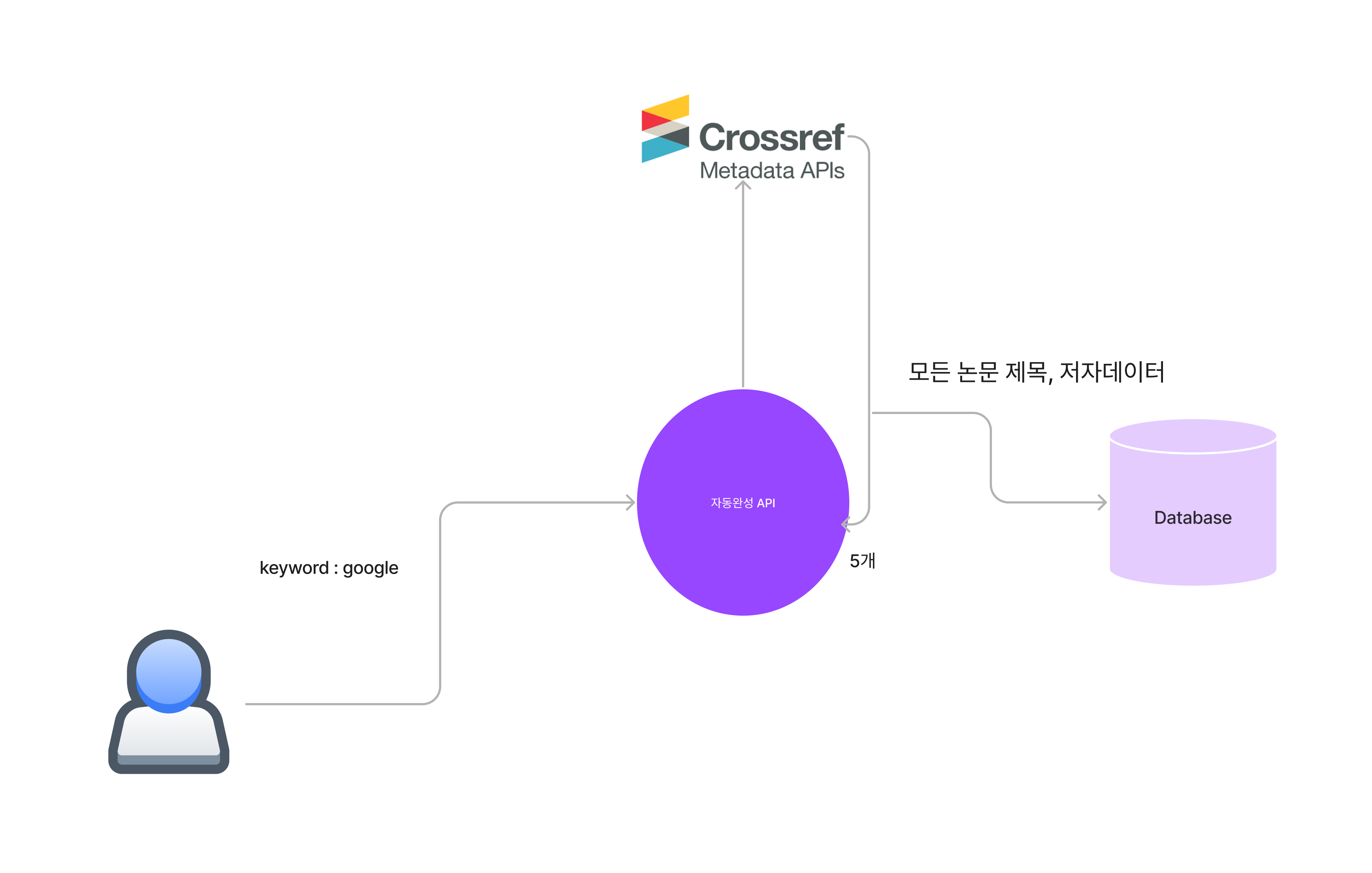
다음과 같이 자동완성 기능을 호출 할 때마다 crossref API에 데이터를 요청하고 CrossRef API의 response의 상위 5개만 사용자에게 응답해주고, 그 외의 모든 논문은 DB에 저장을 하는 형식을 생각했습니다.
https://api.crossref.org/works?query=googleapi 요청 url은 다음과 같이 되겠네요.
문제2. 한 페이지에 1000개의 논문 정보밖에 못가져온다.
위와 같이 CrossRef API를 이용한 한가지 키워드에 관해 최대한 많은 논문을 캐싱하고 싶었지만, 한번의 API Call 요청에는 1000개의 데이터 밖에 가져오지 못하는 단점이 있었습니다.
다행히 해당 API에는 데이터 마이닝을 위한 offset을 제공하였습니다
그러면 위의 URL을 조금 변경해볼까요?
https://api.crossref.org/works?query=google&row=1000&offset=0
다음과 같이 한페이지에 1000개의 데이터를 0번 인덱스부터 가져와라!
라고 해석할 수 있겠네요.
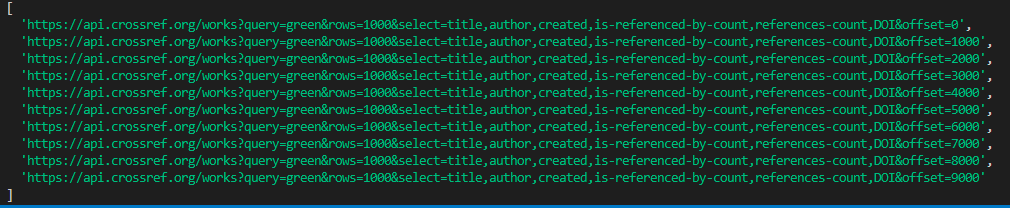
그러면 1만개를 가져와야 할때는?
https://api.crossref.org/works?query=google&row=1000&offset=1000
https://api.crossref.org/works?query=google&row=1000&offset=2000
https://api.crossref.org/works?query=google&row=1000&offset=3000
...
https://api.crossref.org/works?query=google&row=1000&offset=9000다음과 같이 url을 만들고 해당 api 신호를 Promise.all로 묶어서 모든 요청을 한번에 보내면 될듯 합니다.
const result = await Promise.all(urls.map(i,v)=>{axios.get(v)})하지만 생각했던대로 저장이 진행되지 않고 멈췄습니다..
문제3. Too Many Request(status 429)
오류가 발생하였고, 제 로컬 컴퓨터에서 다시 API 요청을 보낼 수가 없었습니다.
그 이유는 Promise.all()을 이용하여 모든 API 요청을 동시다발적으로 보내다 보니 CrossRef API의 공식문서에서 x-late-limit을 데이터 마이닝의 경우 1초, 일반적인 요청인경우 0.5초를 요구하고 있었습니다.
즉 API 요청의 속도를 조절해야할 필요성을 느꼈습니다.
그래서 위의 파이프라인을 큐를 이용하여 변경하였습니다.
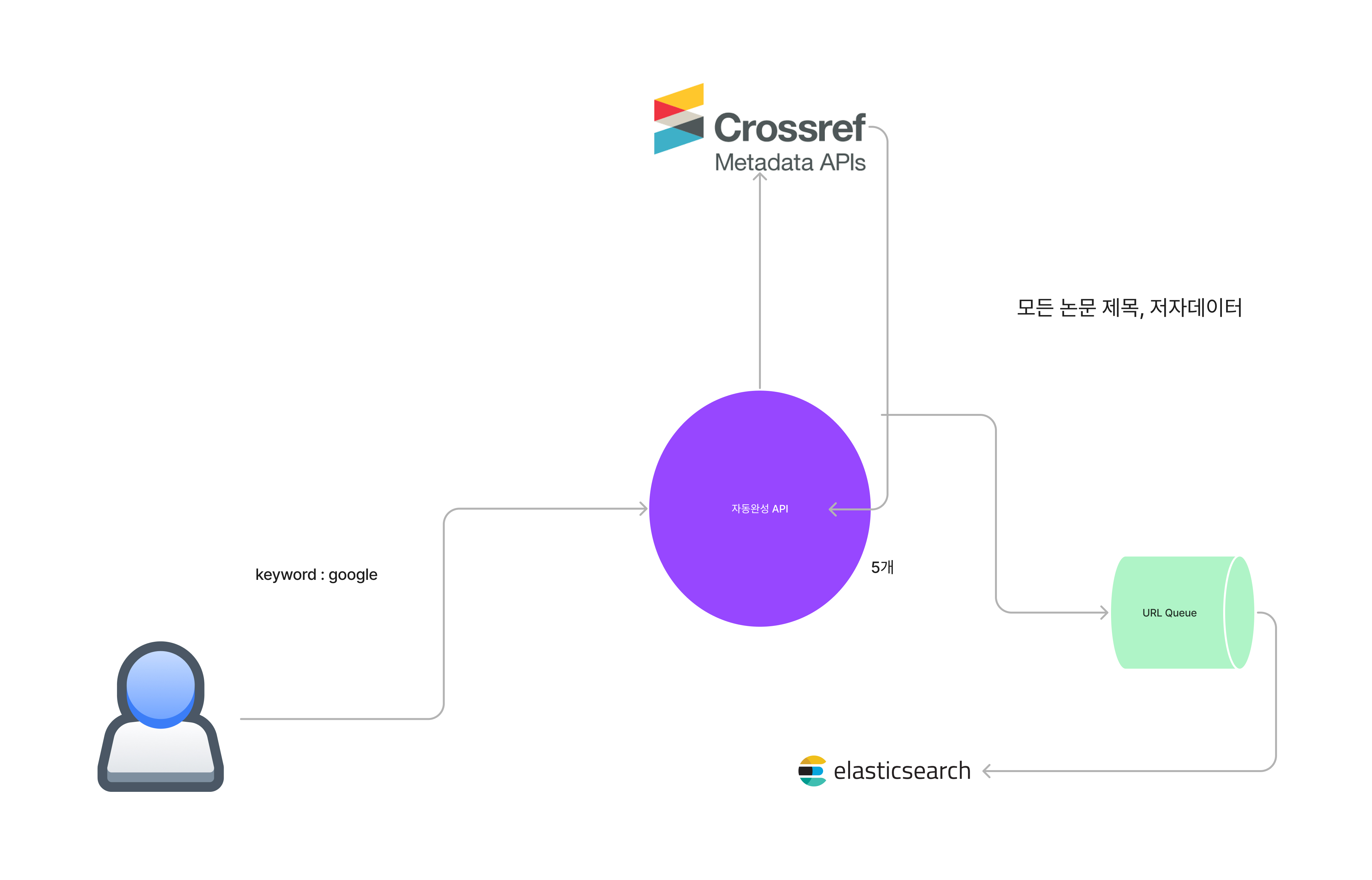
위에서 만든 url들을 queue에 집어 넣고, 해당하는 queue에서 우리 서버에서 정한 delay만큼 (1초) queue에서 url을 꺼내어 해당 url로 api 요청을 하고, 받은 response들을 elasticsearch에 저장하는 파이프라인을 구성하였습니다.
 차례를 기다리는 URL들 ...
차례를 기다리는 URL들 ...
문제4. 한 키워드에 대해 1만개? 너무 적다.
일부 키워드는 한 키워드로 검색하면 40만개~60만개의 논문 데이터가 검색되는 것을 확인 할 수 있습니다.
다행히 CrossRef API에서는 CURSOR를 이용한 완전 탐색기능을 제공하였습니다.
이는 Crossref API에 CURSOR를 통한 요청을 최초에 보내면 이 해당 특정한 CURSOR의 주소를 가지고 Request => Response => Request를 반복합니다.
여기에서의 문제점은 request를 response를 받기전에 재요청을 보내면 cursor가 깨져버리고, 앞으로 이후의 데이터 요청을 보낼 수 없다는 점과 기존의 offset을 이용한 탐색보다 훨씬 느리다는 문제점이 있습니다.
왜 데이터 저장에 왜이리 집착해? 그냥 API에 전적으로 의존하면 되지 않나요?
=>
모든 논문데이터를 CrossRef API에 의존하면 구현은 쉬우나, 속도의 변동성이 심하고, 가장 심각한 문제는 사용자가 몰린경우 동시에 10명의 사용자가 검색을 하면, 외부 API에 Block을 당하는 순간 우리 서비스는 최소 1분간은 모든 서비스가 중지되는 최악의 사태가 발생합니다.
그래서 최대한 우리의 DB를 확보하고, 없는 정보만을 외부 API에 요청하는 가장 최적의 상황을 구현하기 위해 이렇게 데이터 캐싱에 진심입니다.
Batch System
이러한 모든 문제를 해결하기 위해 탄생한 우리 서비스의 Batch System을 소개합니다.

다음과 같은 flow를 가지고 있으며, 저희의 기존 시스템을 적극적으로 활요하여 데이터를 저장합니다.
간단하게 분류하면 이렇게 됩니다.
- 사용자가 특정 keyword로 검색한다. (모든 검색어는 redis에 저장중)
- 해당 keyword로 검색된 적이 있으면 elasticsearch의 데이터를 사용자에게 전달.
- 해당 keyword로 검색된 적이 없으면 해당 keyword로 Batch 시스템에 전달
이러한 batch 시스템에선 기본적으로 한 논문을 토대로 데이터를 저장하게 되며, 해당 논문의 모든 정보를 저장합니다. (reference 목록까지)
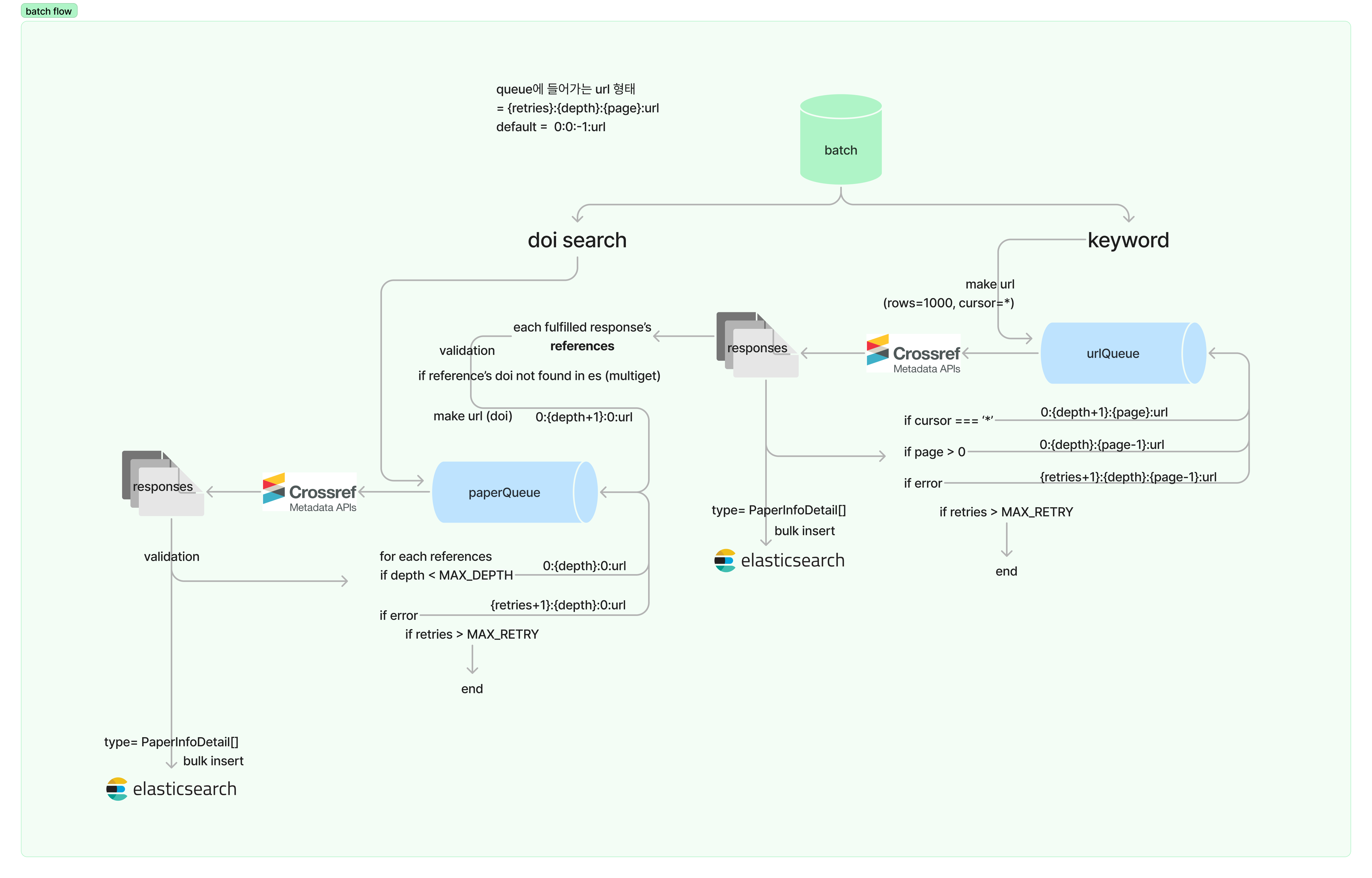
다음과 같은 흐름으로 elasticsearch에 데이터를 저장합니다.
- 모든 논문의 list를 가져온다.
- 논문 list를 각각 한 논문씩 paperQueue에 넣는다.
- paperQueue에서 논문을 하나씩 꺼내어, 다시 CrossRef API 한 논문에 관한 상세정보를 요청한다.
- 논문의 정보 유효성을 검증한 뒤에 elasticsearch에 저장
이러한 batchsystem은 계속해서 BE서버에서 실행중이며 3일의 시간동안 약 400만개의 논문을 저장하였습니다.
결론
batch 시스템의 도입으로 자동완성기능과 검색 결과에서는 엄청난 속도의 향상을 이룰 수 있었습니다.
평균적으로 3~5초가 걸리던 검색이 ms단위로 매우 빠르게 검색이 되며, 느린 속도로 인한 로딩바를 볼 일이 극히 줄어들었습니다.
우리의 프로젝트가 궁금하다면?
https://github.com/boostcampwm-2022/web18-PRV
