Regression
우리가 12단원에 배울 것
-
내가 만든 데이터가 정규분포를 따르는지 확인
-
regression(회귀) 분석
회귀 분석은 통계학 용어로여러 자료들간의 관계를 수학적으로 증명하는 것을 의미
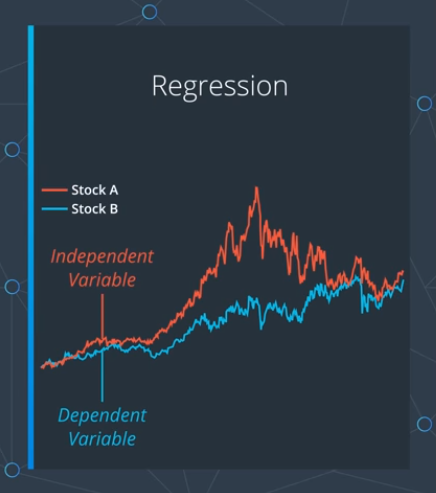
회귀 분석을 하게 되면 한개 이상의 독립적인 변수를 사용함. 이를 통해 종속적인 변수를 찾아냄
- 독립 변수 : 'X' 값
market indices(시장 지수) + employment numbers(취업률) - 종속 변수 : 'Y' 값
stock price returns(주식 가격 이익) + electricity consumption(전기 사용료) + corn harvested(옥수수 재배) 등등
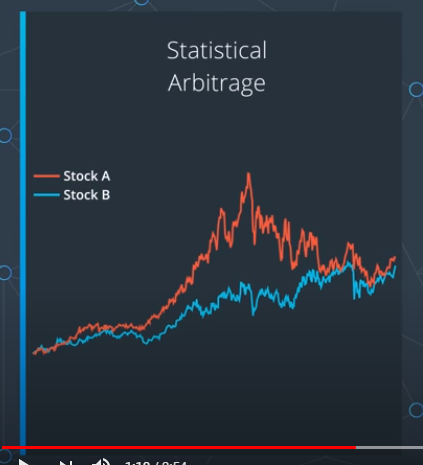
회귀 분석을 하는 이유는 두 개의 주가의 관계를 파악하는 데 사용

이러한 행위를 Statistical Arbitrage(통계적 차익거래)이라고 부름.
Statistical Arbitrage은 두개의 주가의 관계를 보고 거래를 하는 거래기법이라고 볼 수 있다.
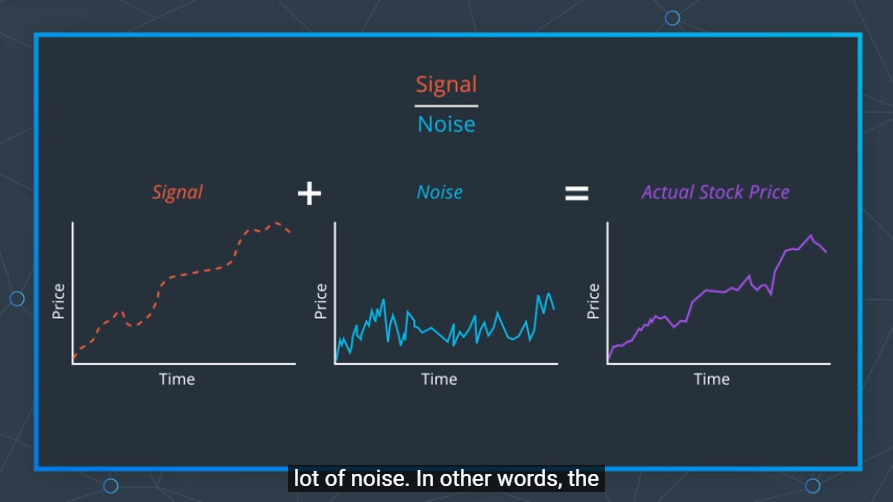
이때 우리가 분석하며 생기는 데이터는 두가지로 나뉘어 지는데
1. Signal : 우리에게 도움이 되는 실질적인 데이터로 우리가 종속 변수를 예측하는데 도움을 줌
2. Noise : 우리에게 1도 도움이 안되는 필요없는 데이터
-
Actual Stock Price : Signal은 극도로 적지만 Noise는 다수인 데이터
이러한 데이터는 Signal-to-Ratio 비율이 극도록 낮음 -> 이때 예측 모델들은 굉장히 데이터와 적합한 결과가 나오기 때문에 실재 세계의 예측과는 큰 괴리가 있을 수 있음결론적으로 독립변수와 주가 수익간의 관계는 시간에 걸치어 변할 수 있다. => 즉 우리의 예측 모델은 미래에는 맞이 않을 수 있다고 생각할 수 있다. 그렇기 때문에 최근의 지표에 우리의 예측 모델을 지속적으로 업데이트 해줄 필요가 있다.
1. Distribution(분포)
많은 통계적 모델들은 정규 분포(가우시안, 벨 곡선)를 따른다고 가정
이 모델들은 우리의 모델이 쓸모 있는지 확인하는데 사용
그렇기에 앞으로 우리는 정규 분포로 만드는 법과 이용하는 법에 대해서 배우도록 함

Random Variable = Take on a Random Value, 그냥 'x' 값
이때 랜덤 변수가 받는 값은 확률분포(probability distribution)에 따라 달라지게 됨
즉, 확률변수에 들어가는 정의값에 따라 확률값이 달라지는 확률 분포값이 곧 우리가 사용할 랜덤변수를 의미하게 됨
이때 확률분포가 underlying probability distribution인지를 알 방법이 없기 때문에 우리는 방정식(확률질량함수 또는 확률밀도함수)을 활용하여 이 확률분포를 알아내야 함
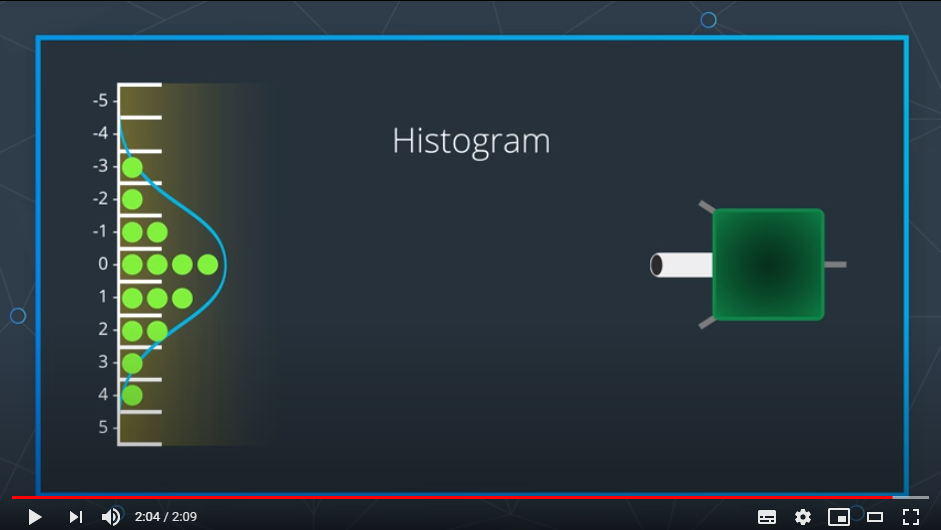
그리고 이러한 방식으로 만들어진 그래프를 Histogram 이라고 부름
여기에서 가장 중요한 것은 절때 숫자별로 확률 값이 달라지는 것이 아닌. 특정값의 확률이 어떻게 정의되어 있다는 것을 의미함을 이해하여야 한다.
2. Parameters of a Distribution
이때 우리가 자주사용하는 확률분포
1. PDF - Probability Density Function(확률 밀도 함수)

PDF 는 우선
X값은 D 값을 따른다고 표현하고
P(x|D) = p(x) 꼴의 조건부 확률을 만들어 0과 1사이의 확률 값을 가지게 됩니다.
그리고 이때 나온 값들을 가지고 '정규화'를 하게 되는데
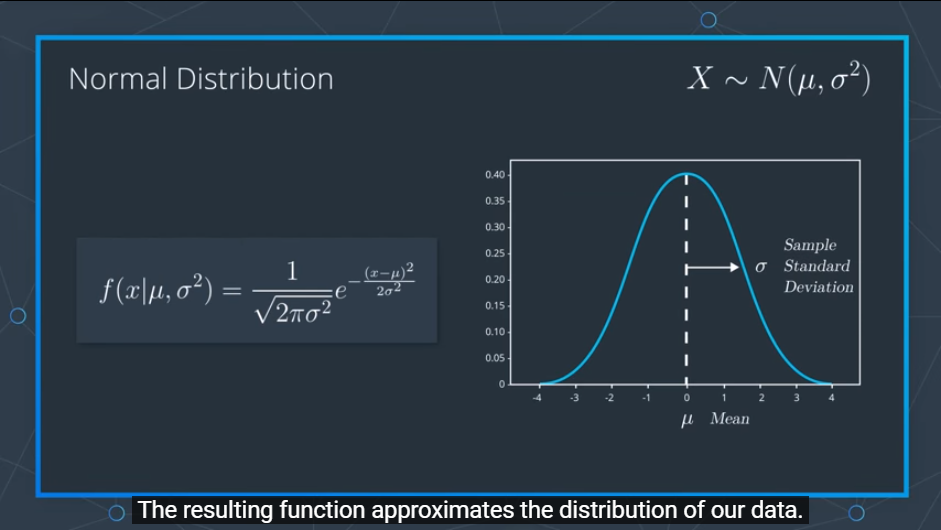
위와 같이 μ(평균) 값과 σ^2(분산) 값을 기반으로 0을 기점으로 정규분포가 그려지게 됩니다.
3. Testing for Normality
우리가 만든 정규분포가 제대로 된 정규분포인지 확인 하는 방법
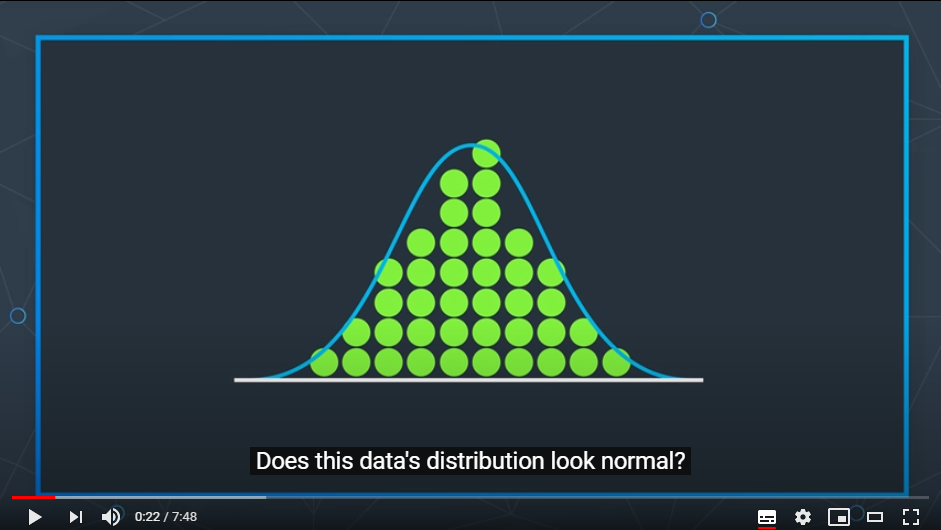
1) 가장 쉬운 방법은 히스토그램을 그려보아 그래프를 비교하는 것이지만
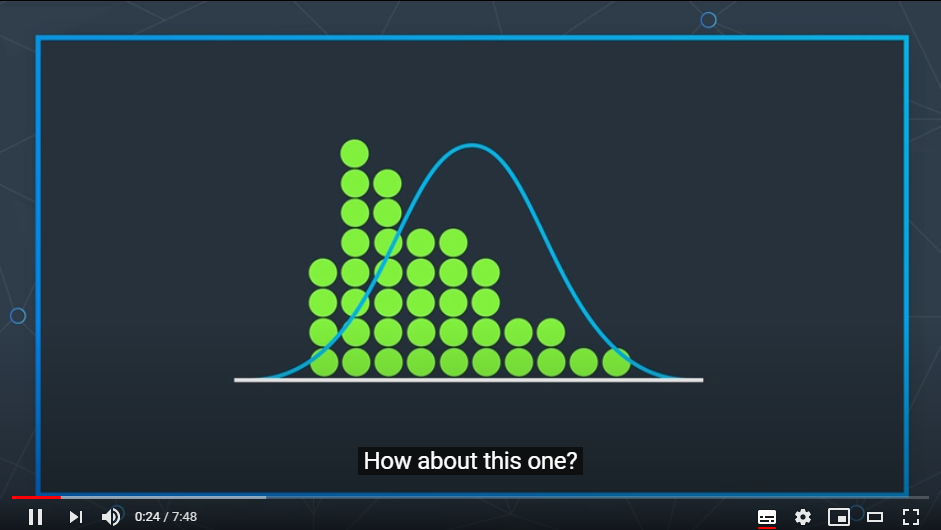
우리의 눈은 정확하지 못하여서 그렇게 할 수 없다.
그래서 사용하는 것이
2) Boxplot

박스플롯의 다섯 수치는 다음과 같은데
1. 최솟값 : Q1에서 1.5 IQR(Q3-Q1)을 뺀 위치(Whisker)를 의미
2. 최댓값 : Q3에서 1.5 IQR을 더한 위치(Whickser)을 의미
3. Q1(제 1사분위수) : 25% 위치의 값
4. Q2(제 2사분위수) : 50% 위치의 값
5. Q3(제 3사분위수) : 75% 위치의 값
그리고 박스릴 제외한 Qutliers(사분위수)들이 쭉 늘어진 형태를 가지고 있습니다.
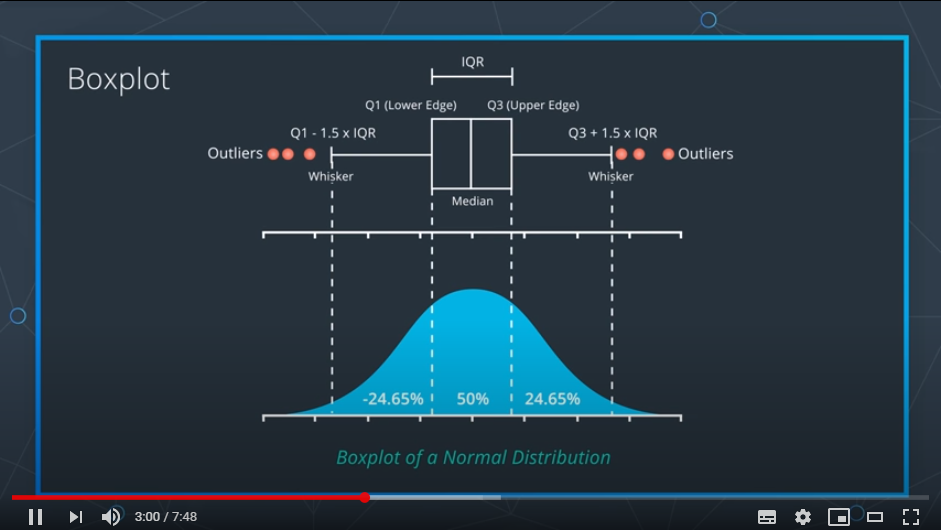
최종적으로 만들어진 Boxplot이 정규분포과 동일하게 생기었다면 우리가 만든 정규분포는 제대로 된 정규분포라고 할 수 있다.
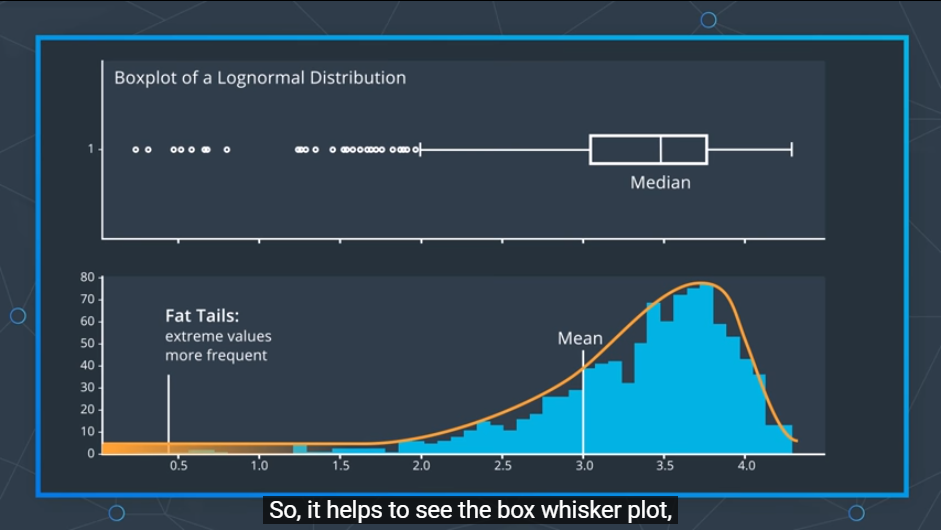
반대로 이렇게 왼쪽 꼬리는 길고 오른쪽 절벽은 뚱뚱한 경우도 볼 수 있다.
이러한 그래프는 곧 negative returns(손해)가 종종 발생할 수 있다는 것을 의미한다.
또한 그래프는 매번 종 모양이 아닐 수 있다는 것을 유의하여야만 한다.
3) QQ-Plot
더 정밀하고 엄밀한 방법으로 QQ-Plot 방법이 존재한다.
QQ-Plot은 데이터분포 그래프와 PDF의 정규분포 그래프를 가지고 와서 두 그래프가 얼마나 일치하는지를 확인하는 방법이다.

이때 앞과 뒤의 Q는 Quantile 이라고 부르며 정의에 의하면 확률분포를 쪼개는 간격이라고 한다.
또한 가장 흔히 쓰는 표준 Quantile에는
- Quartiles
- Deciles
- Percentiles
이 존재한다.
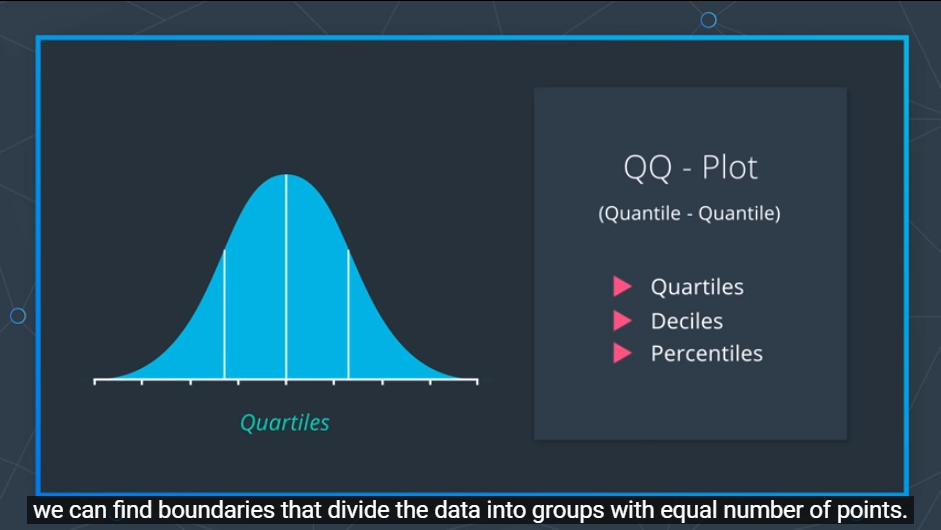
Quartiles는 정규분포를 4개의 그룹으로 나누는 세개의 경계선을 의미한다.

Deciles는 10개의 조각으로 나누는 9개의 경계선을 의미한다.
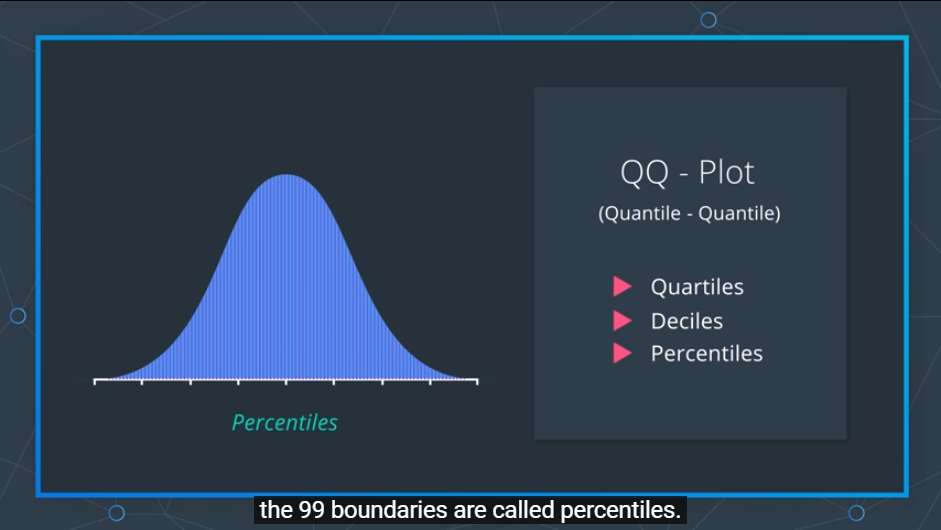
Percentiles는 100개의 조각으로 나누는 99개의 경계선을 의미한다.
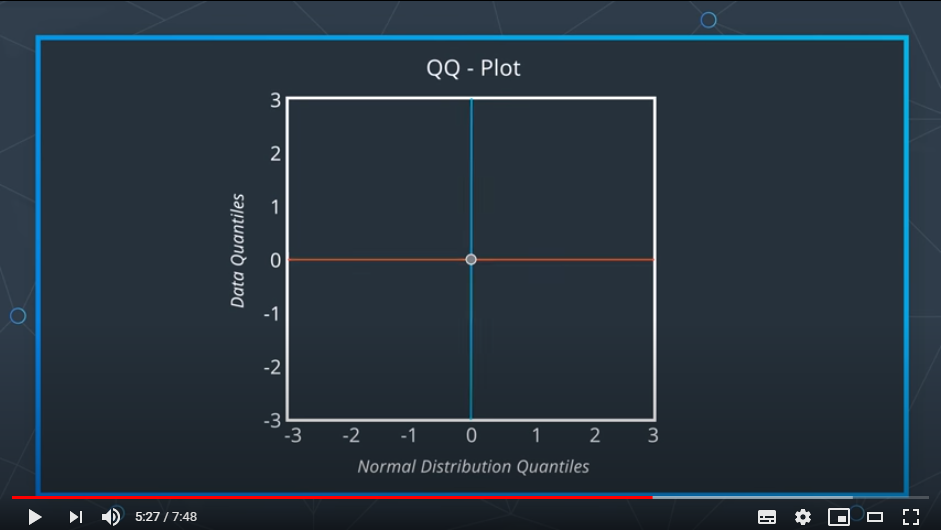
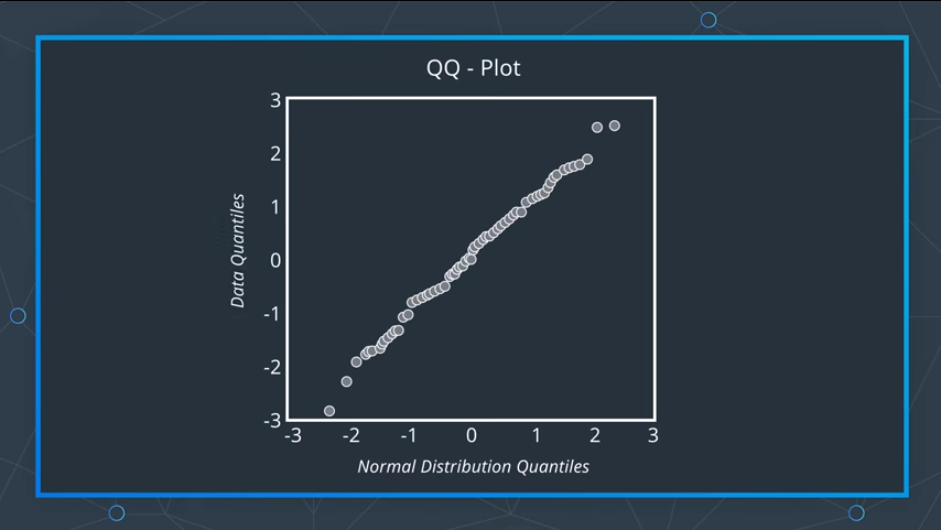
이제 각 그래프 위의 지점을 선으로 그리어 겹치는 점을 찍어내면 하나의 선과 같은 형태를 만들 수 있다.
(위의 사진은 각각 50%의 지점을 찍는 것부터 시작한 것)
만약 만들어진 그래프가 1차식 형태라면 두 그래프는 매우 일치한다고 볼 수 있다.
