3.2 쿼리 엔진
Hive에 의한 구조화 데이터의 생성과 Presto에 의한 대화식 쿼리
3.2.1 데이터 마트 구축의 파이프라인
쿼리 엔진을 사용하여 데이터 마트를 만들기까지의 흐름(Hive와 Presto 결합)
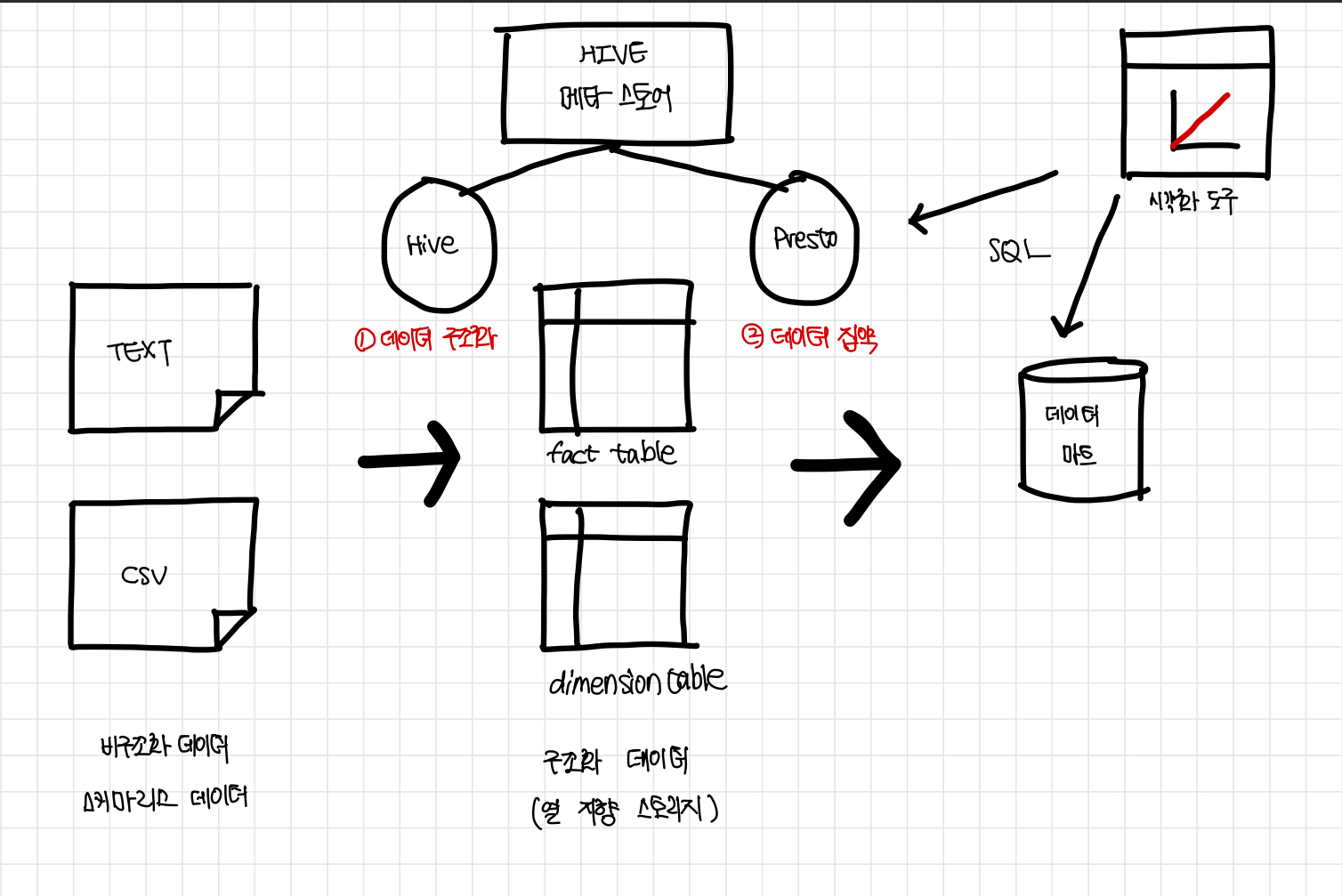
- 분산 스토리지에 저장된 데이터를 구조화하고 열 지향 스토리지 형식으로 저장
- 다수의 텍스트 파일을 읽어 들여 가공하는 부하가 큰 처리가 되기 때문에
Hive이용
- 다수의 텍스트 파일을 읽어 들여 가공하는 부하가 큰 처리가 되기 때문에
- 완성한 구조화 데이터를 결합, 집계하고 비정규화 테이블로 데이터 마트에 써서 내보냄
- 열 지향 스토리지를 이용한 쿼리의 실행에는
Presto를 사용함으로써 실행 시간 단축
- 열 지향 스토리지를 이용한 쿼리의 실행에는
Hive에서 만든 각 테이블의 정보는 ‘Hive 메타 스토어(Hive Metastore)’ 라고 불리는 특별한 데이터베이스에 저장됨
3.2.2 Hive에 의한 구조화 데이터 작성
외부 테이블(external table) 정의
- Hive 외부에 있는 특정 파일을 참고해 마치 거기에 테이블이 존재하는 것처럼 읽어 들이기 위해 지정
# Hive 가동
$ hive
# 외부 테이블 access_log_csv를 정의
CREATE EXTERNAL TABLE access_log_csv(
time string, request string, status int, bytes int
)
# csv 형식임을 지정
ROW FORMAT SERDE 'org,
# 경로를 지정(디렉터리 내의 모든 파일이 읽어짐)
STORED AT TEXTFILE LOCATION '/.../'
# csv의 헤더행 스킵
TBLPROPERTIEX('skip.header.line.count'='1');- 외부 테이블: Hive의 외부에 있는 특정 파일을 참고해 마치 거기에 테이블이 존재하는 것처럼 읽어 들이기 위해 지정
- Hive를 비롯한 대부분의 SQL-on-Hadoop의 쿼리 엔진은 MPP 데이터베이스처럼 데이터를 내부로 가져오지 않아도 텍스트 파일을 그대로 집계할 수 있다.
- 이 성질은 특히 애드 혹 데이터를 분석하기에 유용하며, 시간을 들여 데이터를 전송하지 않고도 원하는 정보를 얻을 수 있다.
- CSV 파일을 그대로 집계하는 것은 비효율적임. 따라서 열 지향 스토리지로 변환함
열 지향 스토리지로의 변환
데이터 집계의 고속화(배치형 쿼리 엔진)
- 테이블을 열 지향 스토리지 형식인 ORC 형식으로 변환
- ORC 형식으로 변환에는 다소 시간이 걸리지만, 변환 후의 테이블 집계는 1.5초까지 단축됨
- 작성은 시간이 걸리고, 집계는 고속화되는 특징 → 배치형 쿼리 엔진에서 실행하는 데 적합
- 파일의 크기도 원래에 비하면 1/10으로 단축됨
Hive로 비정규화 테이블을 작성하기
- 데이터의 구조화가 완료되면 다음은 데이터 마트의 구축을 해야 함
- 테이블을 결합 및 집약해서 ‘비정규화 테이블’을 만듦
- 이 때 Presto같은 대화형 쿼리 엔진을 사용할 것인지, Hive 같은 배치형 쿼리 엔진을 사용할 것인지에 따라 생각이 달라짐
- Hive → 시간이 걸리는 배치 처리
- 비정규화 테이블이 수억 레코드나 되면, 그것을 데이터 마트로 내보내는 것만으로도 상당한 시간이 소요됨
- 쿼리 엔진 자체의 성능은 최종적인 실행 시간에 그다지 많은 영향을 끼치지 않음
- 이렇게 비정규화 테이블을 만드는 데 오랜 시간이 걸리는 것은 흔한 일이며, 그렇기에 가능한 한 효율적인 쿼리를 작성해야 함.
- Hive → 시간이 걸리는 배치 처리
- Hive의 쿼리를 개선하는 예
- 서브 쿼리 안에서 레코드 수를 줄이는 방법
- 데이터의 편향을 방지하는 방법
Cf) 이러한 최적화는 Hive 뿐만 아니라 빅데이터를 집계할 때 항상 의식해두는 것이 중요하다
서브 쿼리 안에서 레코드 수 줄이기
초기 단계에서 팩트 테이블 작게 하기
-
Hive 쿼리는 SQL과 매우 유사하지만, 그 특성은 일반적인 RDB와는 전혀 다름
-
Hive는 데이터베이스가 아닌 데이터 처리를 위한 배치 처리 구조임. 따라서, 읽어들이는 데이터의 양을 의식하면서 쿼리를 작성하지 않으면 성능이 나오지 않음
-
비효율적인 쿼리의 예
-
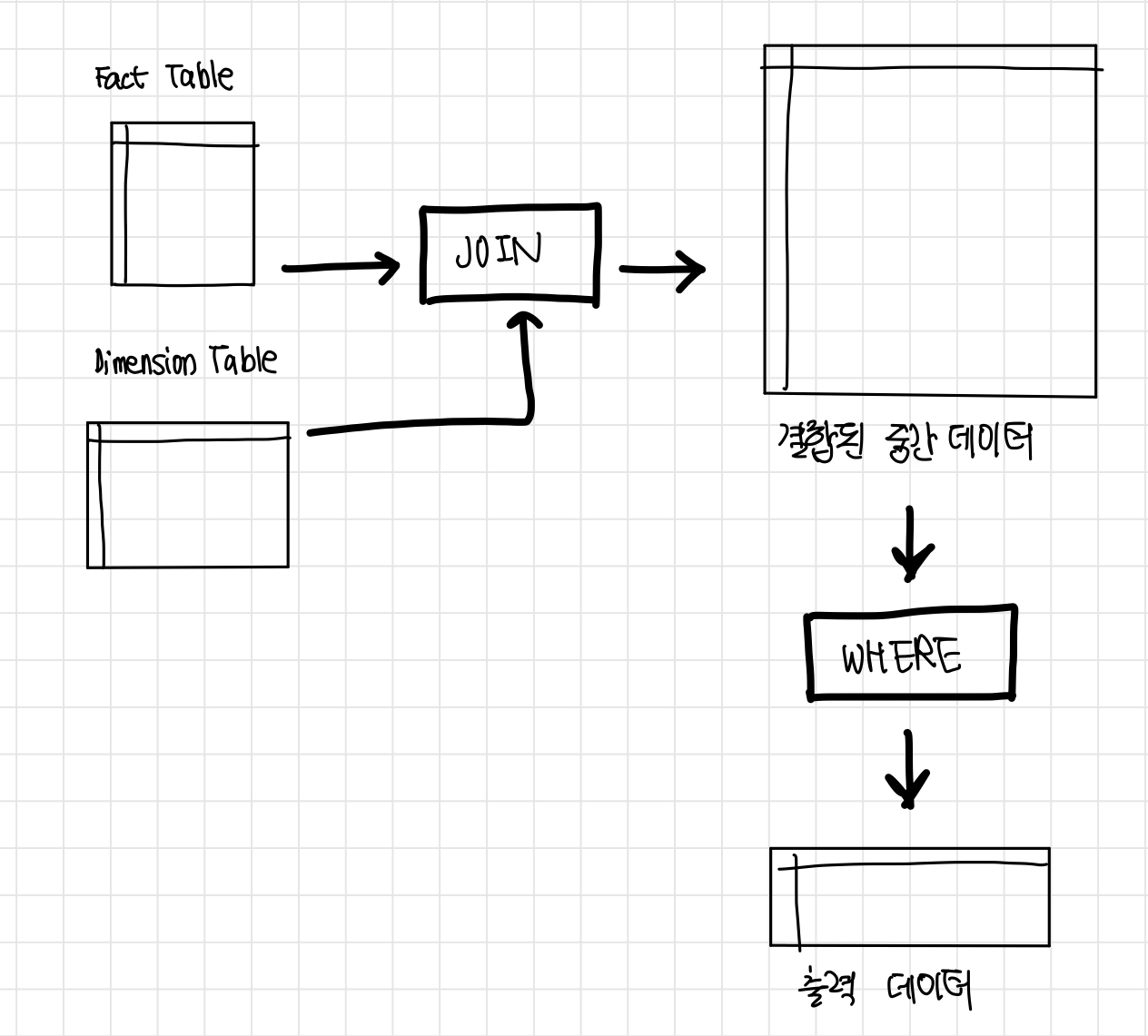
팩트 테이블(access_log)과 디멘션 테이블(user)을 결합하고 WHERE로 조건을 부여
-
팩트 테이블을 필터링할 조건이 없기 때문에, 모든 데이트럴 읽어 들인 후에 결합하고 이후에 나오는 WHERE에 의해 검색을 하게 됨
-
대량의 중간 데이터가 생성되고, 그 대부분을 그냥 버려 낭비가 큰 처리가 됨

-
SELECT ...
FROM access_log a
JOIN users b ON b.id = a.user_id
WHERE b.created_at = '2017-01-01'- 보다 효율적인 쿼리의 예
- 서브 쿼리 안에서 팩트 테이블을 작기 함.
- ‘초기에 팩트 테이블을 작게 하는 것’이 빅데이터의 집계에서 중요함
SELECT ...
FROM (
SELECT * access_log
WHERE time >= TIMESTAMP '2017-01-01 00:00:00'
) a
JOIN users b ON b.id = a.user_id
WHERE b.created_at = '2017-01-01'데이터 편향 피하기
분산 시스템의 성능 발휘를 위해
데이터 편차(data skew): 고속화를 방해하는 문제.
Ex) 분산 시스템에서 SELECT count(distinct...)을 실행하는 것은 다른 것을 실행하는 것보다 오래 걸림. 중복이 없는 값을 세려면, 데이터를 한 곳에 모아야 해서 분산 처리하기 어려워지기 때문
하지만, GROUP BY에 의한 그룹화는 분산 처리됨. 만약 30일동안의 데이터가 있다면, 쿼리는 최대 30으로 분할됨. 하지만 날짜별로 데이터에 편차가 있다면, 문제
분산 시스템의 성능을 발휘하기 위해서는 이러한 데이터의 편차를 최대한 없애고, 모든 노드에 데이터가 균등하게 분산되도록 해야 함.
3.2.3 대화형 쿼리 엔진 Presto의 구조
Presto로 구조화 데이터 집계하기
Hive같은 배치형 쿼리 엔진은 작은 쿼리를 여러 번 실행하는 대화형 데이터 처리에는 적합하지 않음. 쿼리 실행의 지연을 감소시키는 것을 목적으로 개발된 것이 ‘대화형 쿼리 엔진’ 임
이 분야에서 자주 참고되는 기술은 2010년 구글에서 발표된 ‘Dremel’임. 수천 대의 컴퓨터에 분산된 열 지향 스토리지를 사용하여 집계 가속화
Presto: 2013년 말 페이스북에서 출시됨
플러그인 가능한 스토리지
하나의 쿼리 안에서 여러 데이터 소스에 연결 가능
- Presto의 특징: 플러그인 가능한 스토리지 설계
- 전용 스토리지를 갖고 있디 않으므로 Hive와 마찬자기로 다양한 데이터 소스에서 직접 데이터를 읽어 들인다.
- Presto는 Hive 메타스토어에 등록된 테이블을 가져올 수 있으므로, Hive에서 만든 구조화 데이터를 좀 더 집계하는 목적에 적합함.
- Presto가 그 성능을 최대한 발휘하려면, 원래 스토리지가 열 지향 데이터 구조로 되어 있어야 함
- Presto는 특히 ORC 형식의 로드에 최적화되어 있으며, 그것을 확장성이 높은 분산 스토리지에 배치하여 최대의 성능을 발휘함.
- 데이터의 로딩 속도를 높이려면 Presto 클러스터를 분산 스토리지와 네트워크의 가까운 곳에 설치한 후에 그것들을 가능한 한 고속 네트워크에 연결하도록 해야 함
CPU 처리의 최적화
읽기와 코드 실행 병렬 처리
- Presto는 SQL의 실행에 특화된 시스템으로, 쿼리를 분석하여 최적의 실행 계획을 생성하고, 그것을 자바의 바이트 코드로 변환함. 이는 presto의 워커 노드에 배포되고, 그것은 런타임 시스템에 의해 기계 코드로 컴파일됨
- 코드는 병렬로 실행됨. 따라서 CPU 리소스만 충분하다면 데이터의 읽기 속도가 쿼리의 실행 시간을 결정하게 됨.
인 메모리 처리에 의한 고속화
쿼리 실행에는 가급적 대화형 쿼리 엔진 사용
- Presto는 쿼리의 실행 과정에서 디스크에 쓰기를 하지 않음. 모든 데이터 처리를 메모리상에서 실시하고, 메모리가 부족하면 기다리거나 실패함.
- 취급하는 데이터의 양이 아무리 많아도, 비례하여 메모리 소비가 늘어나지 않음.
- 따라서, 메모리상에서 할 수 있는 것은 메모리상에서 실행하고, 아무래도 디스크가 있어야 하는 일부 데이터 처리만을 Hive등에 맡기는 것이 효과적.
- 몇 시간이나 걸리는 대규모 배치 처리와 거대한 테이블끼리의 결합 등에는 디스크를 활용해야 함. 단기간 쿼리 실행에는 대화형 쿼리 사용
분산 결합과 브로드캐스트 결합
- 기본적으로 분산 결합 사용
- 한쪽 테이블이 충분히 작은 경우, 브로드캐스트 결합 사용
3.2.4 데이터분석의 프레임워크 선택하기
MPP 데이터베이스
완성된 비정규화 테이블의 고속 집계에 적합
- 구조화된 데이터 SQL로 집계 → 기존 DW 제품, 클라우드 서비스
- MPP 데이터베이스
- 스토리지 및 계산 노드가 일체화되어 있어, ETL 프로세스 등으로 처음에 데이터를 가져와야 하지만, 그 부분만 완성하면 SQL만으로 데이터 집계 가능
- 확장성 및 유연성은 분산 시스템이 나음
- 시각화를 위한 데이터마트를 구축하는 데 있어서는 최적
Hive
데이터양에 좌우되지 않는 쿼리 엔진
-
Hadoop 상의 분산 애플리케이션은 애초에 높은 확장성과 내결함성을 목표로 설계됨
- 수천 대나 되는 하드웨어를 이용하는 것이 전제
- Hive도 연장 선상에 있음: 대규모 배치 처리를 꾸준히 실시
-
텍스트 데이터 가공, 열 지향 스토리지를 만드는 등의 무거운 처리에 적합
-
대화성이라기 보다는 안전성에 장점이 있음
Presto
속도 중시 & 대화식으로 특화된 쿼리 엔진
장점
- 쿼리 엔진으로 속도가 엄청나게 빠름
- 표준SQL을 준수 → 일상적인 데이터 분석을 위해 자주 사용
- MySQL, 카산드라, 몽고DB등 많은 데이터 스토어에 대응
단점
- 쿼리 실행 중 오류가 발생하면 처음부터 다시 시작함
- 메모리가 부족하면 쿼리를 실행할 수 없을 수도 있음
- 텍스트 처리가 중심이 되는 ETL 프로세스 및 데이터 구조화에 부적합
- Presto의 쿼리는 닥시간에 대량의 리소스를 소비하기 때문에 너무 무리하게 사용을 하면 다른 쿼리를 실행할 수 없음
Spark
분산 시스템을 사용한 프로그래밍 환경
장점
-
인 메모리의 데이터 처리가 중심
-
대화형 쿼리 실행에 적합
-
ETL 프로세스에서 SQL에 이르기까지 일련의 흐름을 하나의 데이터 파이프라인으로 기술할 수 있음
-
분산 시스템을 사용한 프로그래밍 환경이므로, ETL 프로세스이거나 머신러닝같은 데이터 처리에 활용할 수 있음.
-
메모리를 어떻게 관리하느냐가 중요함.
- 여러 번 이용하는 데이터는 캐시에 올려놓거나, 디스크에 스왑(swap)시킴으로써 메모리를 해제하는 등 메모리의 사용을 프로그래머가 어느 정도 제어할 수 있음.
