
출처 표기가 없는 그림의 각 섹션의 원 논문을 참고하였다.
1. Learning Deep Features for Discriminative Localization, 2016 [paper]
1-1. Abstract
본 연구에서는 Global Average Pooling(이하 GAP) 레이어를 다시 살펴보고, image level label를 이용한 학습 없이도 CNN이 Localization 능력을 가질 수 있도록 명시적으로 지원하는 방법을 조명한다. GAP는 이전에 regularization 용도로 제안되었지만, 우리는 CNN의 암묵적인 attention을 드러내는 generic localizable deep representation을 구축한다는 것을 발견했다. GAP의 단순함에도 불구하고, bounding box annotation 없이 학습한 결과 ILSVRC 2014에서 37.1%의 top-5 object localization error를 달성하였다. 우리는 다양한 실험을 통해 classification task를 해결하기 위해 학습된 네트워크가 localization 능력이 있음을 검증했다.
1-2. GAP란?
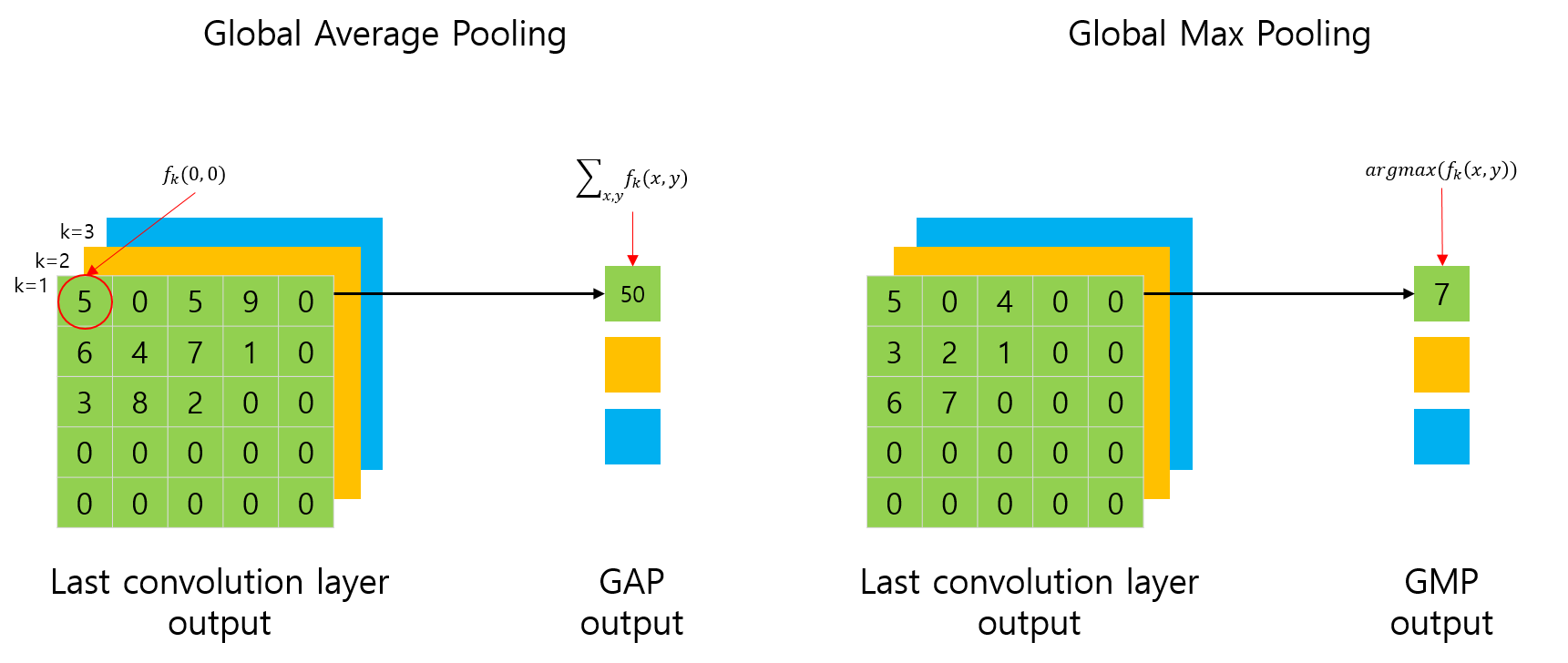
그림 출처: https://you359.github.io/cnn visualization/CAM/
GAP layer는 각각의 feature map의 값들을 평균을 취한 것이다. 즉, feature map의 크기와 관계없이 channel이 k개라면 k개의 평균 값을 얻을 수 있다.(그림에서는 논문과 일관성을 갖기 위해 그림에서 평균을 취하지 않고 합으로 표현했다.) 이러한 GAP는 Fully Connected(이하 FC) Layer와 달리 연산이 필요한 파라미터 수를 크게 줄일 수 있으며, 결과적으로 regulariztion과 유사한 동작을 통해 overfitting을 방지할 수 있다. 또한 FC layer는 Convolution layer에서 유지하던 위치정보가 손실되는 반면에, GAP layer는 위치정보를 담고 있기 때문에 localization에 유리하다.
1-3. Class Activation Map(이하 CAM)
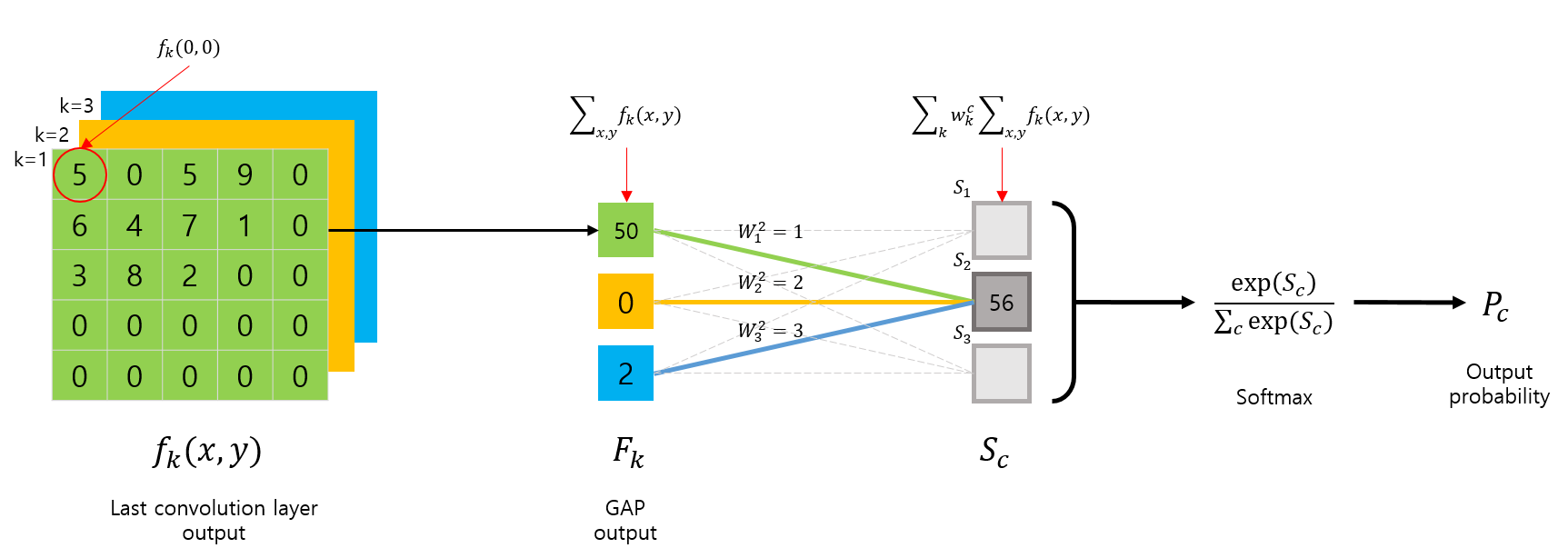
그림 출처: https://you359.github.io/cnn visualization/CAM/
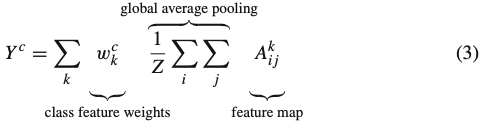
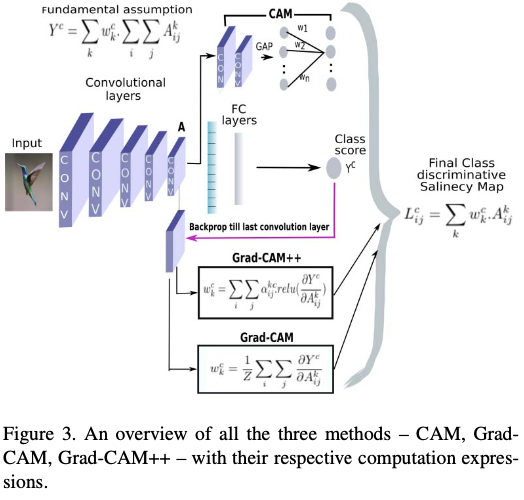
GAP layer를 사용하여 classification을 진행하는 모델의 구조는 위와 같다. 즉, CNN layer를 거쳐 마지막에 k개의 feature map을 얻는다면, GAP를 적용하여 총 k개의 output을 얻을 수 있다. 이 값을 선형결합한 후 여기에 softmax를 적용하면 최종 output probability가 출력된다. 이를 수식으로 표현하면 다음과 같다.
: k번째 Feature map의 GAP
: softmax의 input
: class c에 대한 의 중요도
: class cc에 대한 softmax output
이 때, 바이어스는 classification 성능에 영향을 미치지 않는다고 가정하고 bias는 0으로 설정한다.
이때, class c에 대한 activation map을 다음과 같이 로 정의한다.
즉, 로 쓸 수 있고, 는 class c에 지점이 미치는 영향을 나타낸다. 이를 그림으로 표현하면 아래와 같다.
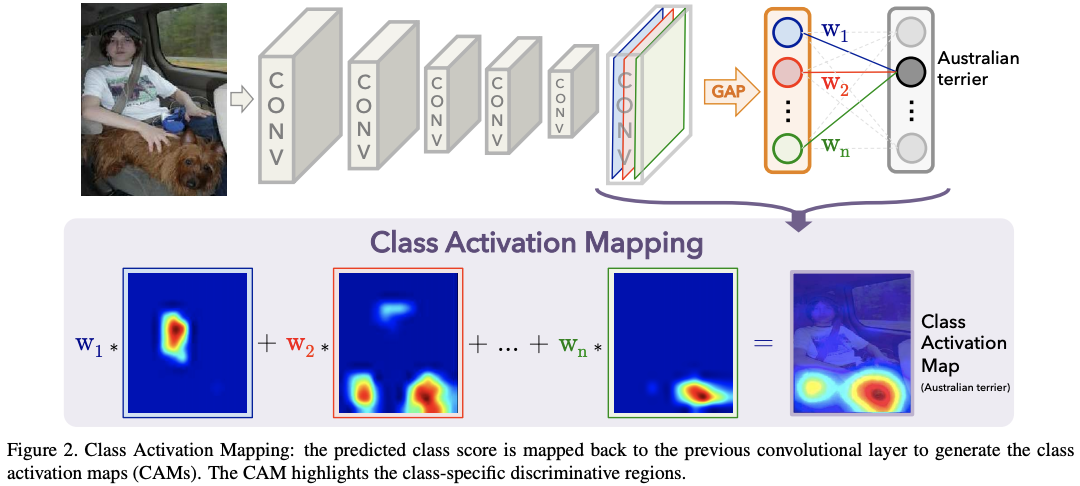
이제 class activation map을 input image의 사이즈로 upsampling하면 특정 class c와 관련된 부분을 찾을 수 있다. 결과는 아래와 같다. 관련 실험 내용과 코드 리뷰는 여기를 참고하길 바란다.
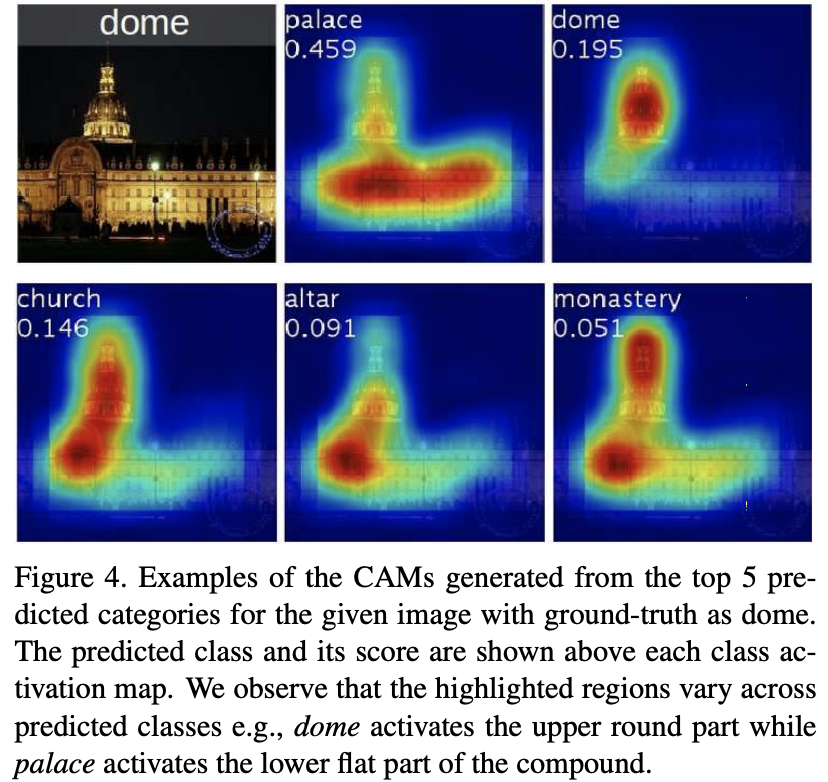
2. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization, 2017 [paper]
2-1. Abstract
우리는 대규모 CNN-based mode에서 의사결정을 위한 'visual explanation'을 생성하여 투명성을 증가하는 기술을 제안한다. 우리의 접근법인 Gradient-weighted Class Activation Mapping(이하 Grad-CAM)은 어떤 target concept일지라도 final convolutional layer로 흐르는 gradient를 사용하여 이미지의 중요한 영역을 강조하는 localization map을 만든다.
이전의 접근법과 달리 Grad-CAM은 모델의 구조 변화나 재학습 없이 다양한 CNN 모델군에 사용할 수 있다: ①FC layer가 있는 CNN 모델(e.g. VGG) ② structured output을 가진 CNN 모델(e.g. captioning) ③ multi-modal input을 가지는 태스크에 사용되는 CNN (e.g. visual question answering(이하 VQA)) 혹은 강화학습. 우리는 Grad-CAM과 기존의 세분화된 시각화 기법과 결합하여 고해상도 class-discriminative visualization인 Guided Grad-CAM을 만들고, 이것을 이미지 분류, 이미지 캡셔닝, VQA 모델, ResNet 기반 모델에 적용하였다.
이미지 분류 모델에서 우리의 시각화 기법은 ⓐ 이 모델들의 실패에 대한 인사이트를 제공한다(비합리적인 예측은 합리적인 설명을 가지고 있음을 보인다) ⓑ ILSCRC-15 weakly-supervisied localization task에서 기존의 방법들보다 뛰어난 성능을 보여준다 ⓒ 기본 모델에 더 충실하다ⓓ 데이터셋의 바이어스를 통해 모델 일반화를 돕는다. 이미지 캡셔닝과 VQA에서 우리의 시각화는 non-attention based models일지라도 input을 localize하는 것이 가능함을 보여준다. 마지막으로, human study를 실시하여 사용자가 딥러닝 모델의 예측에 대해 적절한 신뢰를 얻는 데 도움이 되고, 같은 결과를 내는 모델일지라도 Grad-CAM은 강한 모델과 약한 모델을 식별할 수 있도록 도와주는 것을 보여준다. 코드는 여기, 그리고 데모비디오는 여기에서 확인할 수 있다.
2-2. Grad-CAM
이전 연구들을 통해 CNN의 deeper representation은 higer-level visual construct를 포착한다. 게다가, Convolutional Feature가 지니는 공간적 정보는 FC layer에서 손실되기 때문에 세밀한 공간적 정보와 high-level semantic의 절충안을 찾고자 마지막 Convolutional Layer를 사용했다. 이 레이어의 뉴런들은 object와 같이 이미지에서 클래스의 의미와 관련된 정보들을 포함하고 있다. Grad-CAM은 마지막 CNN layer로 흐르는 gradient 정보를 이용하여 의사결정과 관련된 각 뉴런의 중요도를 이해하고자 하였다.
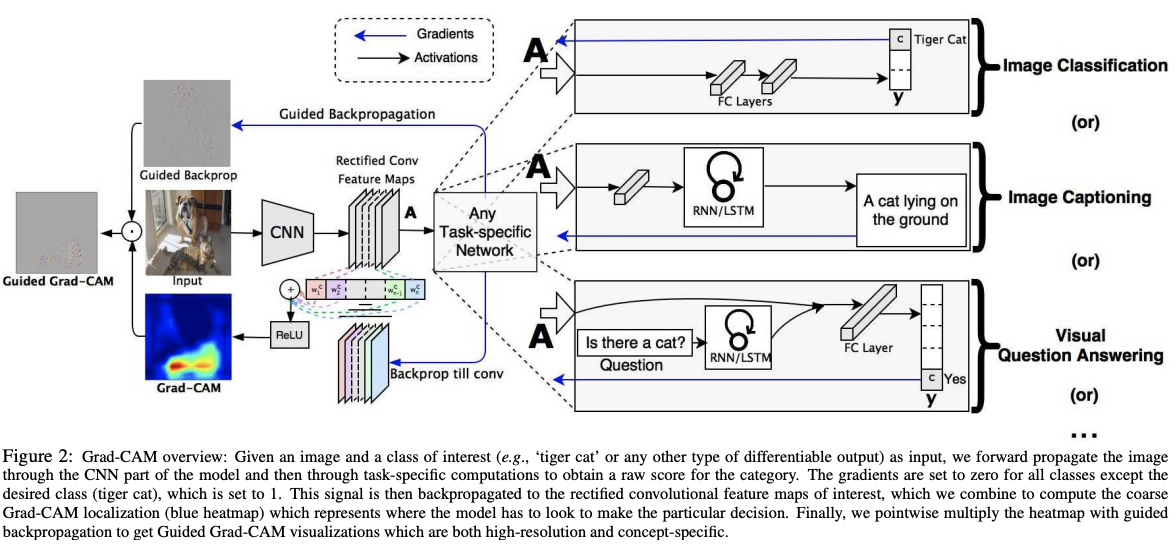
CAM은 GAP가 있어야만 사용할 수 있다. 따라서 GAP가 없는 경우 FC layer를 GAP로 대체한 후 재학습을 시켜준 후 visualzation을 진행하였다. 반면, Grad-CAM은 범용적으로 CAM을 사용하기 위해 CAM의 가중치 w를 다른 값으로 대체한다. 이를 위해 다음과 같이 notation을 정의한다.
: 클래스 c에 대한 사이즈의 class-discriminative localiztion map
: softmax 이전의 class c에 대한 score. 이 값을 일반화하여 classification외에 caption이나 question의 answer의 word가 될 수도 있다.
: 마지막 CNN layer의 k번째 채널의 feature map
: deep network의 partial linerarization을 의미하며, 타겟 클래스 c에 대한 k채널의 feature map의 중요도를 나타낸다. 이 때, 는 backpropagation을 통해 계산할 수 있고, 는 GAP를 의미한다.
: feature map의 픽셀 수
이제, Activation map을 위에서 구한 가중치로 선형결합한 후 ReLU를 적용하면 된다.
ReLU는 class c에 긍정적인 영향을 미치는 feature만을 확인하기 위해 사용한다. 즉, 부정적인 영향을 끼치는 픽셀을 알아보기 위해서는 Counterfactual explanation를 사용하면 된다. ReLU가 없는 경우 localization map는 가끔 우리가 원하는 클래스 외의 지역을 하이라이트하고, localization 성능이 떨어진다.

2-3. Grad-CAM이 CAM의 일반화인 이유
CAM의 수식은 다음과 같다.
GAP output 을 다음과 같이 정의할 수 있다.
즉, 를 식(3)에 대입하면 CAM은 최종 스코어를 다음과 같이 계산한다.
이때, 는 k번째 feature map과 class c를 잇는 가중치를 의미한다. 클래스 스코어에 대한 feature map 의 gradient를 계산하면 다음과 같다.
이때, 이므로 다음과 같은 식을 얻을 수 있다.
또한, 이므로 다음과 같이 정리할 수 있다.
모든 픽셀 (i,j)에 대해 양변에 시그마를 적용한다.
이때, 는 (i,j)에 무관하고, 이므로 다음과 같이 를 얻을 수 있다.
는 normalization term이므로 Grad-CAM에서는 임을 알 수 있다. 따라서 Grad-CAM은 CAM의 일반화 버전이다.
2-4. Guided Grad-CAM
Grad-CAM은 이미지 픽셀 단위의 세밀한 요소들 다루지 못한다는 단점이 있다. Guided backpropagation visualization은 ReLu layer를 거쳐 backpropagating할 대, 음의 gradient를 없애며 시각화한다. 이것은 직관적으로 뉴런에 의해 탐지되는 픽셀을 알아보기 위함이다. Grad-CAM은 쉽게 물체를 localize할 수 있지만 조잡한 heatmap을 통해 왜 네트워크가 특정 물체를 해당 클래스로 분류하였는지 알기 어렵다. 두 방법론의 장점을 결합하여 Guided backpropagation과 Grad-CAM을 element-wise 곱하여 시각화를 진행한다.(은 먼저 2차원 선형 보간법을 이용하여 인풋 이미지와 같은 사이즈로 upscaling한다.)

결과는 위와 같다. 시각화 결과는 고해상도인 동시에 class-discriminative한 것을 볼 수 있다. Guided backpropagation with Decovolution과 비슷한 결과이지만 훨씬 노이즈가 적다.
2-5. Evaluating Localization Ability of Grad-CAM
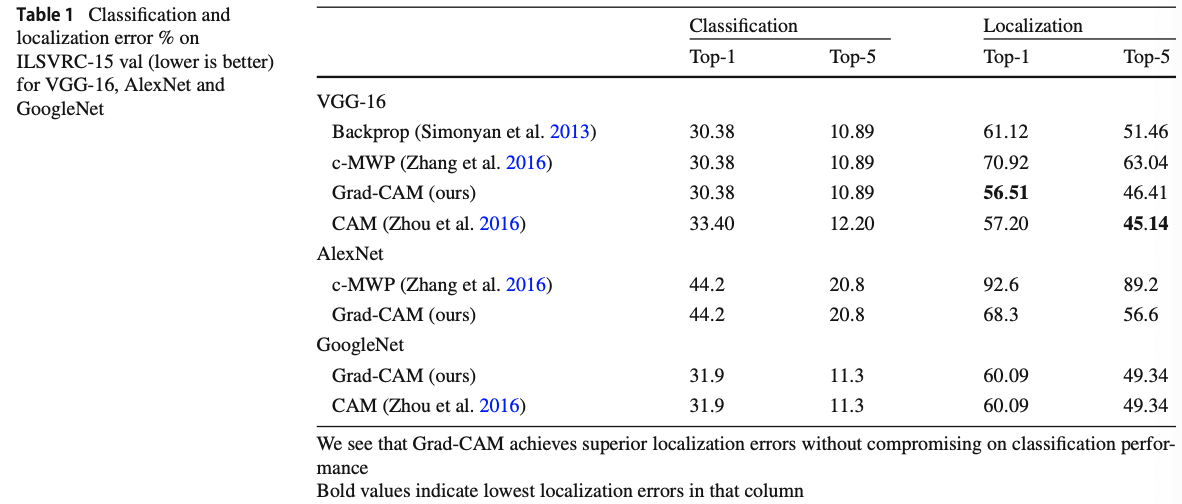
-
Weakly-Supervised Localization
Weakly-Supervised Localization은 bounding box에 대한 정보 없이 학습하는 모델을 의미한다. 이미지가 주어지면, 먼저 네트워크로부터 class prediction을 진행하고, 예측한 클래스에 대한 Grad-CAM map을 생성한다. 최대 강도의 15%를 threshold로 사용하여 각각의 픽셀을 이분화한다. 가장 큰 하나의 segment 주위에 bounding box를 그린다. GRAD-CCAM은 모델의 구조에 변화를 가하지 않기 때문에 classification 성능의 손실 없이 높은 localization 성능을 자랑한다.
-
Weakly-Supervised Segmentation
Semantic Segmentation은 각각의 픽셀들에 대해 classification을 진행한다. Weakly-Supervised Segmentation은 imagle-level에 대한 정보가 없이 학습이 이뤄지기 때문에 image classification dataset으로부터 데이터를 쉽게 구할 수 있다. 기존의 알고리즘은 weak localization seed에 따라 성능이 민감하게 차이난다는 단점이 있다. 결과는 아래와 같다.

-
Pointing Game
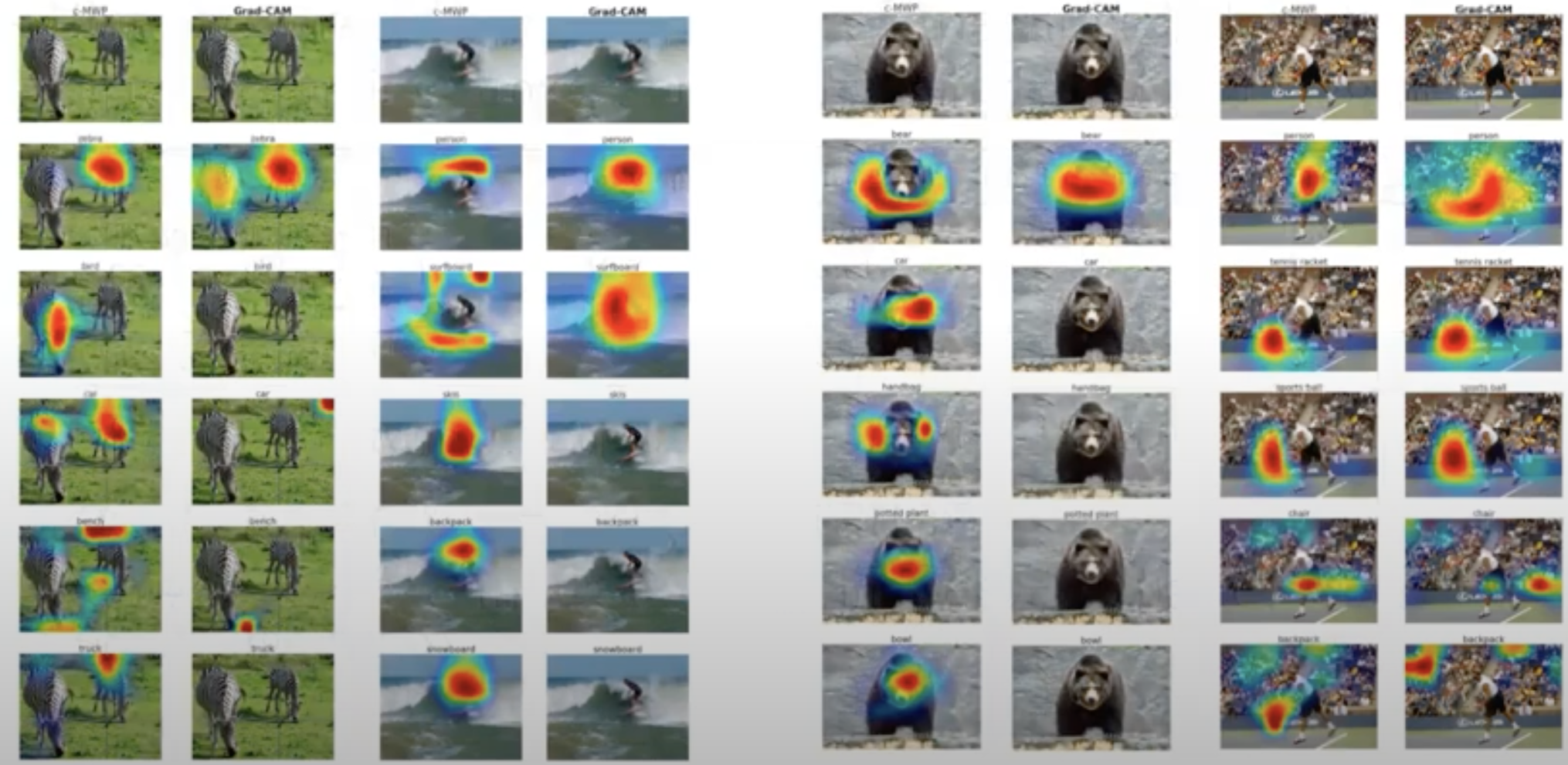
그림 출처: https://www.youtube.com/watch?v=faGsrPX1yFMpointing game experiment는 이미지에서 타겟 물체를 localizing하는 시각화 방법들의 discriminativeness를 평가한다. 히트맵에서 가장 크게 activate된 지점을 추출하고 실제 물체의 라벨과 비교하여 를 구한다. 그러나 이 방법론은 정확도만을 측정하기 때문에 우리는 recall을 고려하기 위해 top-5 class prediction에 대한 localization map을 계산하고 만약 ground-truth가 아닌 부분을 아니라고 정확히 예측했다면 hit으로 분류하였다. 그 결과 Grad-CAM은 70.58%의 성능으로 c-MWP의 60.30%를 상회하였다. 또한, Grad-CAM의 경우 이미지에서 해당 클래스가 나타나지 않으면 c-MWP와 달리 heatmap이 그려지지 않는 것을 확인할 수 있다.
2-6. Evaluating Visualizations
-
Class Discrimination
Grad-CAM이 클래스들을 구별하는 데 도움이 되는지를 측정하기 위해 2개의 카테고리가 들어간 이미지셋인 PASCAL VOC 2007 val set에 대해 하나의 클래스를 시각화하였다. VGG-16과 AlexNet CNN에 대해 다음 네가지 방법론1) Deconvolution 2) Guided Backpropagation 3) Deconvolution Grad-CAM 4) Guided Grad-CAM을 사용하였다.

43명의 Amazone Mechanical Turk(이하 AMT)에게 Fig.5 (b)를 보여주고, 두개의 카테고리 중 어느 것이 보이는지에 대해 질문을 하였다. 직관적으로 보면, 좋은 설명은 클래스를 쉽게 알아보는 것을 의미한다. 그리고 결과는 아래와 같다.
Deconv (53.33%)
Guided Backprop (44.44%)
Guided Grad-CAM: 61.23%
Deconv Grad-CAM: 60.37%
재미있는 점은 Guided backpropagation이 미적으로 아름다워 보이지만 Deconvolution이 더 class-dicriminative라는 점이다.
-
Trust worthiness
Guided Backpropagation과 Guided Grad-CCAM의 visualization을 비교하기 위해 AlexNet과 VGG-16을 사용하였다. 우리는 이미 AlexNet보다 VGG의 성능이 더 좋다는 것을 알고 있다. 54명의 AMT 작업자들에게 Fig.5 (c)와 같이 제시하고 어떤 설명이 더 믿을만한지에 대해 상대적 수치(+2/+1/0/-1/-2)로 물어보았다. 바이어스를 제거하기 위해 VGG-16과 AlexNet이 비슷한 확률로 output을 내는 경우에 대해 실험을 진행하였다. 피험자들은 VGG-16이 더 정확한 모델로 판단하였다. 그리고 Guided Backpropagation은 평균적으로 1(VGG가 AlexNet보다 살짝 더 믿을 만하다)의 점수를 받은 것에 반해, Grad-CAM은 평균적으로 1.27(VGG가 확실히 더 믿을 만 하다)의 점수를 받았다.
2-7. Diagnosing Image Classification CNNs with Grad-CAM
-
Analyzing Failure Modes for VGG-16
VGG-16이 분류를 실패한 케이스들에 대해 실제 라벨과 예측된 라벨의 Guided Grad-CAM을 그려보았다.
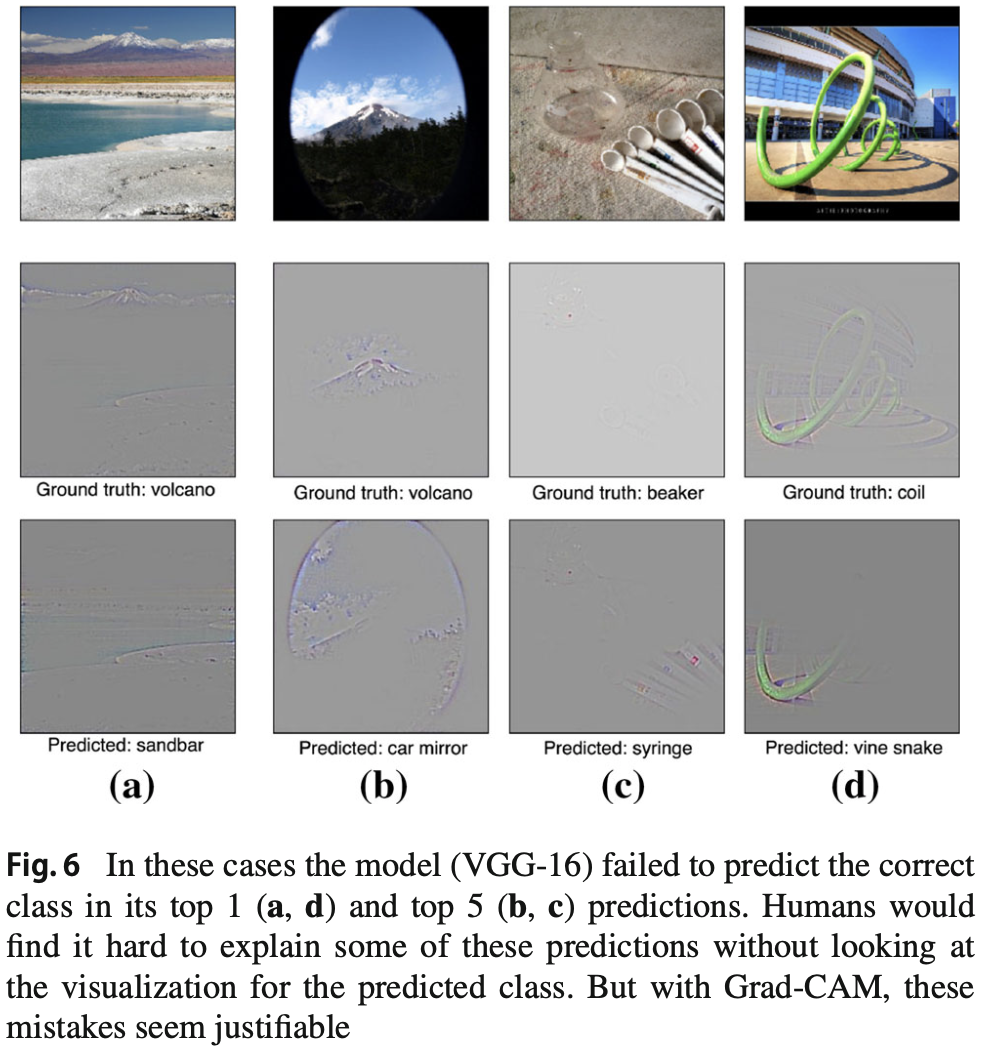
위의 그림을 통해 알 수 있듯이 잘못된 예측에는 그럴만한 이유가 있음을 알 수 있다. 즉, Guided Grad-CAM의 장점 중 하나는 고해상도이고, class-discriminative하므로 이러한 분석을 쉽게 할 수 있다. -
Effect of Adversarial Noise on VGG-16
Adversarial attack은 현재의 deep network가 가지는 취약점이다. 입력 이미지에 인지할 수 없는 노이즈를 넣으면 높은 확률로 잘못 분류를 한다. VGG-16모델에 대해 실제로 존재하는 카테고리의 확률은 낮고, 존재하지 않는 카테고리의 확률이 높은 adversarial image를 생성하여 Grad-CAM visualization을 실행하였다. 그 결과 아래와 같이 Grad-CAM이 adversarial noise에 대해 상당히 robust함을 알 수 있다.

-
Identifying Bias in Dataset
Grad-CAM의 또다른 사용법은 training dataset에 있는 bias를 탖고 줄이는 것이다. bias가 포함된 데이터셋으로 학습된 모델을 실제 세계를 일반화하지 못한다. 이미지 검색 엔진을 통해 의사와 간호사에 대한 데이터250개씩을 구하고 VGG-16모델을 binary classification task를 수행하도록 학습시켰다. 이 모델은 validation accuracy는 좋았지만 82% test acc로 generalize는 잘 되지 않았다. 중간 열을 보면, 모델은 의사와 간호사를 구분할 때 얼굴이나 머리 스타일을 본 것을 확인할 수 있다. 따라서 여자 의사를 간호사로, 남자 간호사를 의사로 잘못 분류하였다. 실제로 의사에 대한 이미지 검색 결과 78%가 남자였고, 간호사 검색 결과 93%가 여자였다. 따라서 이러한 Grad-CAM의 결과를 바탕으로 바이어스를 줄이기 위해 남자 간호사와 여자 의사에 대한 이미지를 학습 데이터에 추가해야 함을 알 수 있다. 새로 학습한 결과는 오른쪽 열과 같다. 이 실험을 통해 Grad-CAM은 데이터셋에 존재하는 bias를 찾고 줄이는 것을 도와줄 수 있다. 이는 generalization 성능을 높이는 것 뿐만 아니라 사회에서 의사결정을 할 때에는 공정하고 윤리적인 결과를 나타내야 하기 때문에 매우 중요하다.
2-8. Grad-CAM for Image Captioning and VQA
-
Image Captioning
이미지 캡션에 대한 위치를 시각화하기 위해 Grad-CAM을 사용할 수 있다. 본 연구에서는 finetuned VGG-16 모델과 LSTM-based language model을 사용한 neuraltalk2를 이용하였다. 캡션이 주어지면 log probability에 대한 마지막 CNN layer의 gradient를 계산하고 Grad-CAM visualization을 생성하였다.

왼쪽 그림은 Grad-CAM이 생성한 것이고, 오른쪽 그림은 Fully Convolutional Localization Newtwork가 single forward pass로 language model이 만든 캡션에 대해 Region of interest를 bounding box로 표시한 것이다. 오른쪽의 bounding box를 기준으로 Grad-CAM의 박스 내부와 외부의 평균 activation 값의 비율을 계산하였다. 모든 이미지를 균일하게 highlight한 경우를 baseline인 1로 설정했을 때, Grad-CAM은 을 달성했고, Guided Backpropagation은 을, Guided Grad-CAM은 를 달성했다. 따라서 Grad-CAM은 bounding box로 학습시키지 않고 DenseCap 모델의 image region을 잘 localize함을 알 수 있다.
-
Visual Question Answering
일반적인 VQA pipeline은 이미지를 처리하기 위한 CNN과 question을 위한 RNN language model로 이뤄져 있다. 이미지와 질문은 일반적으로 answer를 예측하는 것이다. 즉, answer space가 1000개라면, 1000-way classification 문제이다. 따라서 answer를 하나 뽑아서 Grad-CAM visualization을 통해 answer를 설명하고자 한다. task가 복잡함에도 불구하고 아래 그림에 나타난 explanation은 상당히 직관적이고 정보적이다.
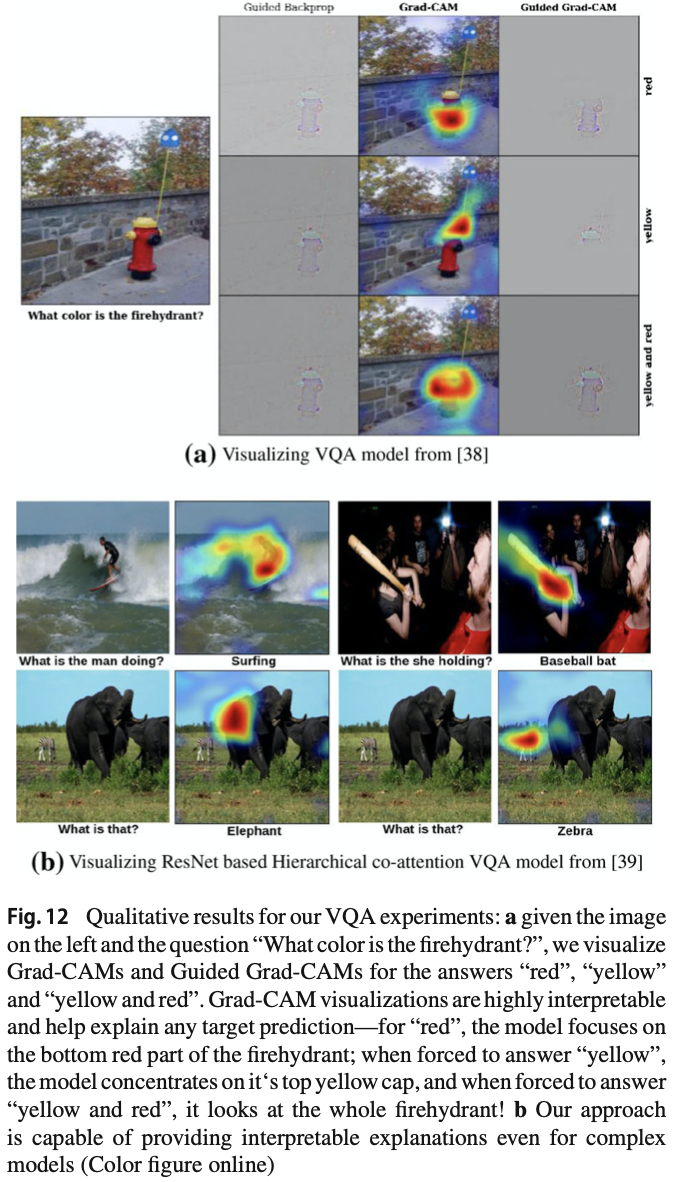
정량적으로 Grad-CAM을 평가하기 위해 occlusion map과의 correlation을 구하였다. occlusion map에 대한 rank correlation은 Guided Backpropagation의 경우 이고, Grad-CAM의 경우 이다. 즉, Grad-CAM이 더 높은 faithfulness를 보여준다.
2-9. Code Review
def generate_gradcam(img_tensor, model, class_index, activation_layer):
model_input = model.input
# y_c : class_index에 해당하는 CNN 마지막 layer op(softmax, linear, ...)의 입력
y_c = model.output[0, class_index]
# A_k: activation conv layer의 출력 feature map
A_k = model.get_layer(activation_layer).output
# model의 입력에 대해서,
# activation conv layer의 출력(A_k)과
# 최종 layer activation 입력(y_c)의 A_k에 대한 gradient,
# 모델의 최종 출력(prediction) 계산
get_output = K.function([model_input], [A_k, K.gradients(y_c, A_k)[0]])
[conv_output, grad_val] = get_output([img_tensor])
# batch size가 포함되어 shape가 (1, width, height, k)이므로
# (width, height, k)로 shape 변경
# 여기서 width, height는 activation conv layer인 A_k feature map의 width와 height를 의미함
conv_output = conv_output[0]
grad_val = grad_val[0]
# global average pooling 연산
# gradient의 width, height에 대해 평균을 구해서(1/Z) weights(a^c_k) 계산
weights = np.mean(grad_val, axis=(0, 1))
# activation conv layer의 출력 feature map(conv_output)과
# class_index에 해당하는 weights(a^c_k)를 k에 대응해서 weighted combination 계산
# feature map(conv_output)의 (width, height)로 초기화
grad_cam = np.zeros(dtype=np.float32, shape=conv_output.shape[0:2])
for k, w in enumerate(weights):
grad_cam += w * conv_output[:, :, k]
# 계산된 weighted combination 에 ReLU 적용
grad_cam = np.maximum(grad_cam, 0)
return grad_cam, weights파이토치 코드는 여기를 참고하길 바란다.
3. Grad-CAM++: Improved Visual Explanations for Deep Convolutional Networks
3-1. Abstract
지난 10여 년간 CNN 모델은 복잡한 비젼 문제들을 해결하는 데 큰 성공을 거두었다. 그런난, 이러한 deep model들은 "black box"로 여겨지며 내부의 작동원리를 파악하는 데 어려움을 겪었다. 최근에 설명 가능한 딥러닝 모델에 대한 중요한 연구들이 있었고, 본 논문은 이 방향성을 위해 노력하였다. 최근에 발표된 방법인 Grad-CAM을 발전하여, 우리는 SOTA와 비교하여 하나의 이미지에 여러 종류의 object가 발생한 경우 설명하고 localization하기 위해 CNN 모델 예측에 대해 더 나은 visual explanation을 제공하는 일반화된 방법인 Grad-CAM++을 제안한다. 우리는 특정 클래스에 대한 visual explanation을 만들기 위해 해당 클래스 스코어에 대한 마지막 convolutional layer의 feature map의 양의 편미분 값에 대한 가중 합을 사용하는 방법을 제안하며, 이에 대한 수학적 유도를 제공한다. standard dataser에 대한 Grad-CAM++의 classification, image caption generation, 3D action recognition, knowledge distillation 등의 다양한 태스크에서 진행된 실험과 평가는 주관적, 객관적 측면에서 더 나은 성능을 보여준다.
3-2. Grad-CAM의 한계
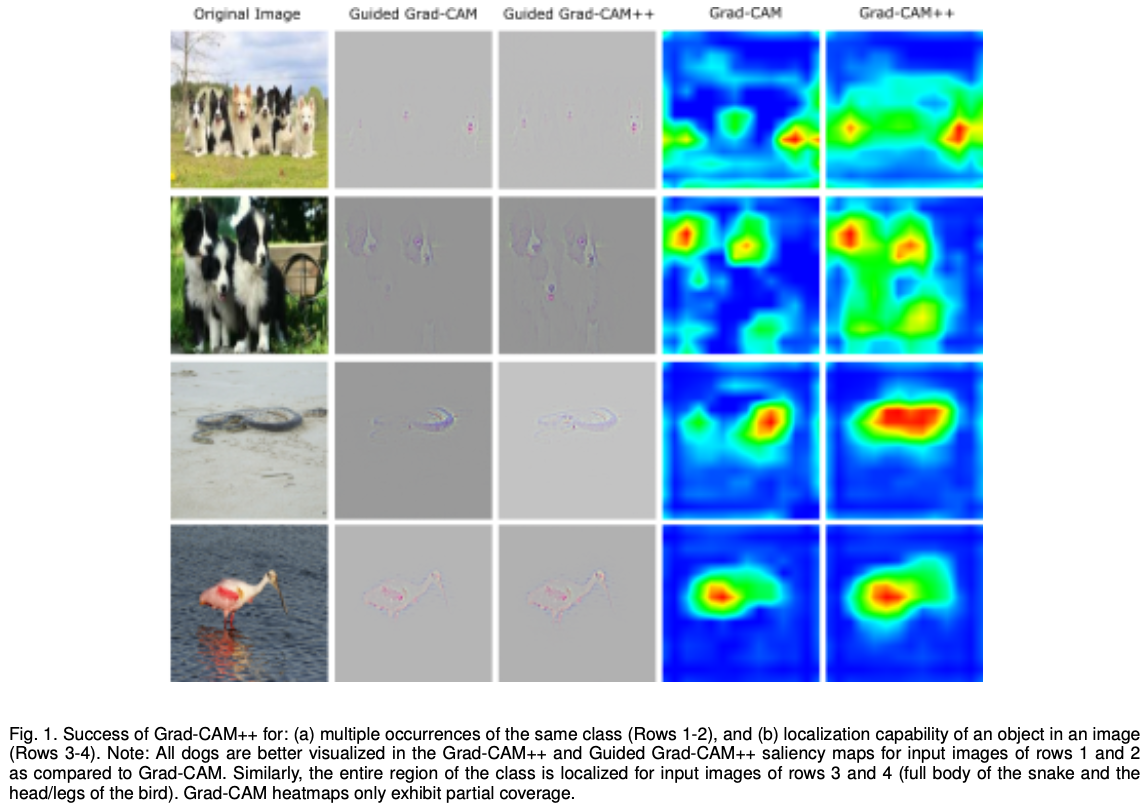
Grad-CAM++는 Grad-CAM의 두가지 문제를 해결했다. 첫번째는 하나의 이미지에서 같은 클래스의 물체가 여러번 발생하는 경우이다. 위 그림의 1번 행에는 강아지가 총 여섯마리이지만, Grad-CAM의 heat map에서는 세마리 정도밖에 구별하지 못한다. 2번행도 마찬가지로 세마리의 강아지가 있지만 heat map에 나타난 것은 두마리 뿐이다. 두번째 문제는 Grad-CAM은 object의 전체 영역을 커버하지 못한다는 점이다. 3번 행을 보면 뱀의 전체 영역을 커버하지 못하고 중간에 끊기는 점이 생긴다. 4번 그림도 새의 몸통에 집중되어 있고, 다리나 부리에는 heat map이 그려지지 않은 것을 확인할 수 있다. 반면 마지막 열을 보면 Grad-CAM++는 이러한 문제를 해결하였다.
3-3. Grad-CAM++의 방법론
Grad-CAM의 GAP는 주요한 gradient를 하나의 값으로 합치기 때문에 visualization에서 뭉개지는 현상이 나타난다. 따라서 Grad-CAM++에서는 이를 weighted sum으로 대체하였다.
: class c에 대한 k번째 feature map의 중요도
Grad-CAM에서 사용한 와 비교하면 pixel-level에서 ReLU가 적용되고, 가 추가된 것을 확인할 수 있다. 는 class c에 대한 convolutional feature map 의 gradient에 대한 가중 co-efficient이다. ReLU는 이전과 마찬가지로 class score에 긍정적 영향을 미치는 양의 gradient만 사용하기 위함이다. 새로 정의한 w를 대입하면 아래와 같이 쓸 수 있다.
ReLU는 threshold를 넘는지 판단하는 함수이므로 미분할 때는 잠시 제거한다. 양변을 에 대해 편미분 하면 다음과 같다.
한번 더 양변을 에 대해 편미분 하면 다음과 같다.
위 식을 에 대해 정리하면 다음과 같다.
만약, 모든 i,j에 대해 인 경우 Grad-CAM의 식이 된다. 즉, Grad-CAM++는 이름을 통해 알 수 있듯이 Grad-CAM의 일반화된 버전이다. 단 하나의 제한 사항은 가 미분가능한 smooth function이어야 한다. 따라서 Grad-CAM과 달리 무한번 미분 가능한 softmax 레이어를 사용한다.(Grad-CAM은 softmax 이전 레이어를 사용했다) 이를 이용하면 계산 복잡도를 줄일 수 있다. 자세한 내용은 원 논문을 참고하길 바란다.
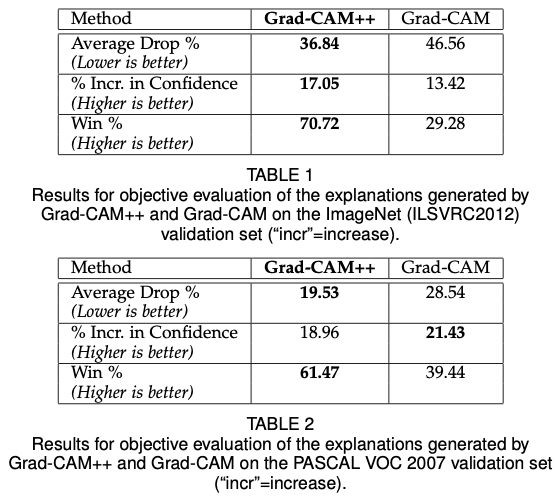
3-4. Grad-CAM++의 결과
정성적인 결과는 아래와 같다. 위에서 언급한 Grad-CAM의 한계를 극복한 것을 확인할 수 있다.

Average Drop %: 중요한 부분을 occlusion했을 때 성능 저하.
% increase in confidence: 중요하지 않은 부분을 occlusion 했을 때 성능 향상
win%: 주어진 데이터셋에서 explanation map의 confidence가 높은 방법론이 이긴 것이다. 전체 이미지 중 이긴 비율을 나타낸다.
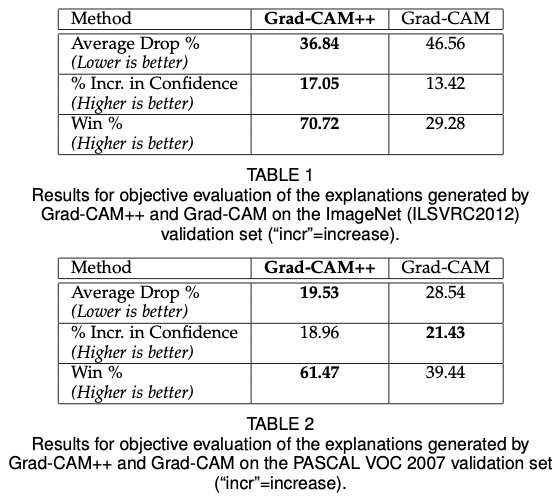
또한, 딥러닝과 관련된 지식이 없는 13명의 실험 참가자들에게 어떤 explanation algorithm이 더 믿을만한지에 대해 질문하였다. Grad-CAM을 baseline으로 사용하였다. 가장 많은 투표를 받은 알고리즘은 VGG-16을 사용한 모델이다.

또한, 위와 같이 Grad-CAM과 Grad-CAM++로 생성한 explanation map들을 제시하고, 어떤 것이 더 나은지에 대해 물어보았다. 총점 250점 중 109.69점이 Grad-CAM++이 낫다고 대답했고, 84.23이 같다고 대답했으며, 56.08이 Grad-CAM이 낫다고 대답하였다.
4. Summary
작성자: 투빅스 15기 황보진경
참고문헌
- CAM
- Bolei Zhou, Khosla, Aditya, Lapedriza, Agata, Oliva, Aude, & Torralba, Antonio. (2016). Learning Deep Features for Discriminative Localization. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2921-2929.
- you359. Paper Review - Class Activation Map. (2018.8.21.). https://you359.github.io/cnn visualization/CAM/. 검색일: 2021.05.09.
- Grad-CAM
- Selvaraju, Ramprasaath R, Cogswell, Michael, Das, Abhishek, Vedantam, Ramakrishna, Parikh, Devi, & Batra, Dhruv. (2020). Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. International Journal of Computer Vision, 128(2), 336-359.
- Taesu Kim. PR-053: Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. (2017.12.10.).https://www.youtube.com/watch?v=faGsrPX1yFM. 검색일: 2021.05.09.
- you359. Paper Review - Grad-CAM. (2018.8.22.). https://you359.github.io/cnn visualization/GradCAM/. 검색일: 2021.05.09.
- Grad-CAM++
- A. Chattopadhay, A. Sarkar, P. Howlader and V. N. Balasubramanian. Grad-CAM++: Generalized Gradient-Based Visual Explanations for Deep Convolutional Networks. (2018). IEEE Winter Conference on Applications of Computer Vision (WACV). pp. 839-847
- Wonju Seo. Grad-CAM++ 내용 정리 [XAI-3]. (2021.4.9.). https://wewinserv.tistory.com/144. 검색일: 2021.05.10.
