
작성자: 오진석
📄 Neural Collaborative Filtering(2017, Xiangnan He)
ABSTRACT
-
논문이 발제된 2017년에는 딥러닝이 음성 인식, 컴퓨터 비전 그리고 자연어 처리와 같은 분야에서 다양한 성공적인 결과를 낳았지만, 추천 시스템에서의 딥러닝 기술은 상대적으로 적은 적용 사례를 보여왔습니다.
-
이번 논문에서는, implicit feedback에 기반한 collaborative filtering이라는 추천 알고리즘을 딥러닝을 적용하여 다뤄보도록 하였습니다.
-
추천 시스템에 딥러닝을 활용한 최근(2017년) 연구들을 보게 되면, 대부분 아이템의 설명 텍스트, 노래의 음향 정보와 같은 부가 정보(auxiliary information)를 활용하는 경우가 많았습니다.
-
collaborative filtering의 key factor을 모델링하기 위해서는 유저와 아이템 간의 interaction이 요구되며, 여전히 matrix factorization 기법에 의존하고 유저와 아이템의 latent features의 내적 과정을 거치게 됩니다.
-
내적 과정을 비선형적 관계를 학습할 수 있는 인공신경망 구조로 대체한다면, Neural Network-based Collaborative Filtering, NCF 라는 모델을 제시할 수 있습니다.
-
비선형적인 특징을 모델에서 학습하기 위해, 유저와 아이템 간의 interaction을 학습할 수 있는 MLP를 적용할 수 있습니다.
-
이번 논문에서 제안한 NCF 모델은 실제 데이터 셋에서 다른 최신 모델들과 비교해서 보다 좋은 성능을 보이기도 했습니다.
-
-
딥러닝을 활용한 추천 시스템이 보다 우수한 추천 성능을 보이는 것은 이번 프로젝트를 통해 깨달을 수 있었습니다.
1. INTRODUCTION
-
정보 폭발 시대에서, 추천 시스템은 e-커머스, 온라인 뉴스, sns 등과 같은 온라인 서비스에서 정보 과다를 완화하는 중요한 역할을 하고 있습니다.
-
개인화된 추천 시스템의 방법은 아이템에 대한 유저의 선호도와 과거 interaction 정보를 활용하는 collaborative filtering가 있습니다.
- 다양한 collaborative filtering 방법 중에서, Matrix Factorization(MF)은 가장 대중적인 알고리즘이며, 유저와 아이템의 latent features(잠재 요인)을 벡터화함으로써, 유저와 아이템을 한 공간으로 투영하게 됩니다.
-
Netfix prize가 유명해지면서, MF는 잠재 요인 추천 알고리즘의 de facto(기본적인) 알고리즘이 되었습니다.
-
많은 연구들이 MF 알고리즘을 개선하기 위해서, neighbor-based models을 적용해보거나, 아이템 데이터의 토픽 모델링을 결합하거나, 여러 feature를 포괄적으로 사용하기 위해 factorization machine 모델로 확장하기도 했습니다.
-
collaborative filtering에서 MF가 효과적임에도 불구하고, 내적을 통한 interaction을 학습하는 것은 성능 향상을 방해하는 것으로 잘 알려져 있습니다.
-
예를 들어, explicit feedback을 통한 평점 예측 과제에서, 유저와 아이템의 bias 항을 추가함으로써 성능을 향상할 수 있다는 결과가 있습니다.
-
즉, 항을 추가하는 것과 같은 시도는 내적 과정에 있어 아주 사소한 변경 혹은 시도에 불과하지만, 유저와 아이템 간의 latent feature interaction을 학습하는 것에 있어서는 매우 긍정적인 효과와 결과를 이끌어 낼 수 있었습니다.
-
-
latent features을 선형적으로 곱하여 결합하는 내적 과정은 유저 interaction 데이터에서 복잡한 관계를 학습함에 있어 충분치 못한다고 해석할 수 있습니다.
-
이 논문에서는 handcraft가 주로 이뤄졌던 많은 이전 연구와는 달리, 딥러닝을 활용함으로써 데이터로부터 interaction을 학습하는 과정에 대해 연구하고 있습니다.
-
인공신경망은 continuous function(연속 함수)를 근사함이 가능하다는 것이 꾸준히 밝혀지고 있으며, 최근에는 딥러닝이 보다 다양한 분야에서 활용될 수 있음이 증명되고 있습니다.
-
그럼에도 불구하고, MF의 방대한 연구자료와 대조적으로 추천 시스템에 딥러닝이 활용된 연구 사례가 상대적으로 굉장히 적었습니다.
- 딥러닝이 적용된 추천 시스템의 최근 연구 사례를 살펴보면, 대부분 부가 정보를 모델링하는 것 정도에 딥러닝을 활용했다는 사실을 확인할 수 있습니다.
-
이번 논문에서는 collaborative filtering의 관점에서 인공신경망 접근법을 구체화함으로써 앞선 연구 자료들의 문제점을 제시합니다.
-
이 과정에서는, 비디오를 보거나, 물품을 구매하거나, 아이템을 클릭하는 행동에 대한 유저의 선호도를 간접적으로 반영한 implicit feedback에 보다 초점을 맞추었습니다.
-
리뷰나 평점과 같은 explicit feedback과 비교했을 때, implicit feedback은 자동적으로 혹은 더 쉽게 추적하고 수집할 수 있습니다.
- 그러나, 사용자 만족도에 대한 정확한 측정치가 아니고 부정적인 평가에 대한 자연스러운 반응이 부족하기 때문에 implicit feedback 사실 활용하기 어렵기도 합니다.
-
이번 논문에서는, 딥러닝을 활용하여 noisy implicit feedback을 모델링하는 것을 주로 다뤄보도록 하겠습니다.
-
논문의 주요 내용은 다음과 같습니다.
-
유저와 아이템의 latent feature를 모델링하는 인공신경망 구조를 제시하고 구체화하여, 인공신경망 기반 collaborative filtering 모델인 NCF를 설계하였습니다.
-
MF 알고리즘을 기본적으로 따르는 NCF는 MLP를 통해 고차원의 비선형적인 특징을 학습할 수 있습니다.
-
2가지 현실 데이터에 NCF를 적용해봄으로써, 딥러닝을 활용한 collaborative filtering의 성능 향상과 효과성에 대해 보여줍니다.
-
2. PRELIMINARIES
- 먼저 implicit feedback을 CF에서 사용하기 위해서는 현재의 문제점과 방법론에 대해서 다뤄보아야 하고, MF 모델에서 대중적으로 사용되고 있는 내적 과정의 한계점에 대해서도 다뤄보아야 합니다.
2.1 Learning from Implicit Data
-
유저와 아이템의 수를 M과 N으로 하는 R 행렬을 정의할 때, feedback의 발생 여부를 기준으로 1 / 0 으로 행렬을 정의할 수 있습니다.
-
이 때, implicit feedback이란 유저와 아이템의 interaction을 의미할 수는 있으나, 발생 여부를 유저가 아이템을 선호한다고 정의할 수는 없습니다.
-
반대로, interaction이 발생하지 않았다고 하더라도, 유저가 아이템을 싫어한다고 생각하기 보다는 인지하지 못하는 경우에도 interaction이 발생하지 않기 때문에 0이 부여될 수 있습니다.
-
이러한 경우가 유저의 선호도에 대한 noise 신호를 의미하는 implicit data로부터 발생하는 학습의 어려움이라고 할 수 있습니다.
-
또한, 유저와 아이템 간의 interaction이 발생하지 않는 경우에는, 이를 missing data로 처리해야 하며 부정적인 feedback에 대한 interaction을 파악하기 어렵습니다.
-
-
implicit feedback의 추천 과정에서 발생하는 문제로는, 아이템을 랭킹화하기 위한 unobserved enteries(=interaction이 존재하지 않는 아이템 set)의 score를 예측하는 다음 과정에서 발생합니다.
-
위 수식에 대해 조금 설명하자면, 는 유저와 아이템이 입력으로 주어졌을 때, score를 return하는 interaction function이며, 는 해당 function의 parameter라고 생각하면 될 것 같습니다.
-
이 때, 해당 function의 parameter를 최적화할 수 있는 목적 함수, objective function은 두 가지가 있습니다.
-
pointwise loss의 경우에는 실제값과 예측값의 차이를 최소화(minimize) 하는 목적 함수로 보통 회귀 문제에서 사용되곤 합니다.
- negative feedback 데이터의 부족을 처리하기 위해서, interaction이 발생하지 않은 데이터를 하여금 negative feedback으로 처리하거나 sampling 하여 처리하는 방법을 적용하기도 했습니다.
-
pairwise loss의 경우에는 관측된 데이터(interaction이 발생한)가 그렇지 않은 데이터에 비해 링킹이 높아야 한다는 아이디어에 기반하여, 관측된 데이터와 관측되지 않은 데이터의 랭킹 차를 최대화(maximize)하는 목적 함수입니다.
-
다시 돌아가서, 논문에서 제시하는 NCF 모델 구조는 인공신경망을 사용함으로써 위 두 목적 함수를 모두 만족하는 결과를 얻을 수 있다고 합니다.
2.2 Matrix Factorization
-
MF, Matrix Factorization은 유저, 와 아이템, 의 latent features인 의 반복적인 내적을 통해 interaction인 를 추정하게 됩니다.
- 는 각 latent feature의 차원을 의미하며, 유저와 아이템의 독립적인 latent factor를 동일한 weight를 기반으로 선형적으로(linearly) 결합하게 됩니다.
- 계속해서 MF의 내적 과정은 유저와 아이템의 복잡한 관계를 표현함에 있어 한계점을 가진다고 말하는데, 다음 그림이 이를 설명합니다.
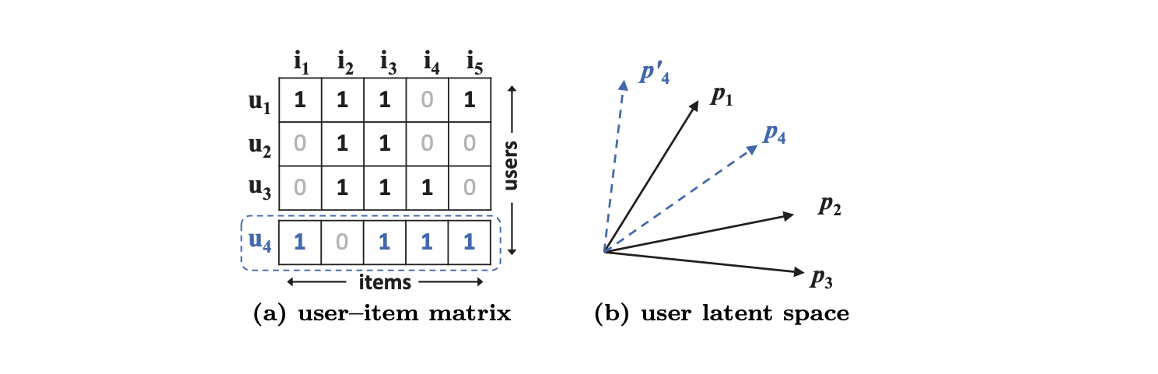
-
위와 같이 유저-아이템 행렬이 존재하게 된다면, 두 유저간 유사도는 내적 혹은 코사인 유사도, 자카드 유사도를 통해 구해볼 수 있습니다.
-
여기서, 유저 와 의 유사도를 로 표현할 때, 유사도 순으로 정렬하게 되면 유저 (2,3), 유저 (1,2), 유저 (1,3) 순으로 높은 유사도를 보이며 유사도 관계를 벡터 공간에서 표현하게 되면 우측 그림과 같습니다.
- 그런데 이 때, 새로운 유저 4가 등장함으로써, 다른 유저들과의 유사도가 계산되어 다음과 같은 유사도 관계가 형성되게 되면 MF 모델에서 공유하고 있던 벡터 공간에서 유저 4를 표현하는 것에 있어 한계를 가지게 되고, 결과적으로 ranking loss가 커지는 현상이 발생하게 됩니다.
-
정리하자면, Matrix Factorization의 단순하고 고정된 내적 과정은 저차원 latent space에서 복잡한 유저와 아이템의 관계를 추정하는 것에 한계점을 가진다고 할 수 있습니다.
-
이러한 문제점을 해결하는 방법 중 하나는 매우 큰 K차원의 latent factor를 지정하는 것이지만, 이 방법 또한 모델의 generalization 관점에 있어 부정적인 결과를 낳을 수 있습니다.
3. NEURAL COLLABORATIVE FILTERING
3.1 General Framework
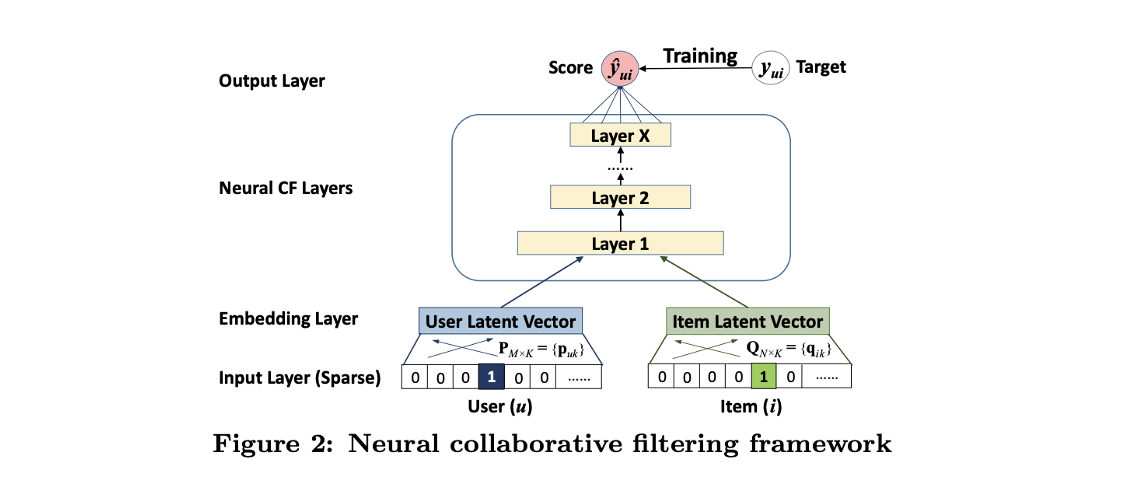
-
인공신경망을 CF에 적용하기 위해서, 위 그림과 같이 한 층의 결과가 다른 층의 입력으로 이루어져 interaction을 추정하는 MLP 구조를 적용해 볼 수 있습니다.
-
입력층의 두 벡터는 각각 유저와 아이템의 벡터를 의미하며, 다양한 방법으로 임베딩될 수 있습니다.
-
이 구조에서는 기본적인 CF 환경을 구성하기 위해서 오직 유저와 아이템의 idx를 활용하여 input feature를 구성하였으며, 원핫 인코딩 형태로 입력될 수 있습니다.
-
-
Embedding layer에서는 Fully-connected layer를 통해 입력층의 벡터를 기반으로 dense vector를 얻을 수 있습니다.
-
이 때 얻은 dense vector를 흔히 말하는 유저와 아이템의 latent vector라고 할 수 있으며, latent vecotr를 neural collaborative filtering layers라고 할 수 있는 MLP 구조에 입력하게 되면서 score를 예측하는 과정을 가지게 됩니다.
-
Fully-connected layer를 통해 dense vector를 얻는 과정은 hidden layer의 weight(가중치)가 업데이트되는 결과물이라고 생각하면 될 것 같습니다.
-
-
MLP 구조는 최종적으로 특정 유저 와 특정 아이템 의 score 를 실제값과의 차이를 최소화하는 pointwise loss를 적용하여 추정하게 됩니다.(해당 논문에서는 인공신경망 모델링에 집중하기 위해서 Bayesian Personalized Ranking이나 margin-based loss와 같은 pairwise loss에 대한 과정은 고려하지 않았다고 합니다.)
3.1.1 Learning NCF
-
오차를 활용하는 pointwise loss에서는 정 분포에 근거하여 관측치를 설명하기 때문에 interaction의 발생 여부 1 / 0 으로 이루어져 있는 implicit data에 적용하기 적합하지 않다고 합니다.
-
그렇기 때문에 implicit data의 binary한 특징을 고려하여 logistic 혹은 probit function인 probabilistic function을 사용하고 추정하고자 하는 가 [0, 1]의 범위값을 가지도록 설정할 수 있습니다.
- probabilistic function에 대해 아주 간단히 설명하자면, 하나의 클래스에 대한 확률 예측 모델에서 실제값 이고 모델의 예측이 이라면 probabilistic function은 이 에 가까워지도록 파라미터를 조정해나가는 것입니다.
-
결국 Objective Function을 다음과 같이 설정할 수 있는데, binary cross-entropy loss와 같다고 이해할 수 있습니다.
- 실제값 일 때, 이라면, 이 될 것이며, 이라면, 이 되기 때문에 목점 함수의 방향성에 대해 쉽게 이해할 수 있습니다.
- 해당 목적 함수에서 존재하는 은 interaction이 발생하지 않은 데이터라고 할 수 있는데, 이러한 데이터는 unobserved interaction 데이터에서 negative sampling을 통해 구축할 수 있었습니다.
3.2 Generalized Matrix Factorization (GMF)
-
해당 섹션에서는 제안할 NCF 모델 구조에서 이뤄지는 Matrix Factorization에 대해 다루게 됩니다.
-
GMF는 본래의 Matrix Factorization과 크게 다른 점은 없지만 내적인 아닌 element-wise product가 이뤄지고, edge weights와 activation function을 사용했다는 점에서 약간의 차이를 찾아볼 수 있었습니다.
-
이렇게 기존 MF와 약간의 다른 구조를 보이는 GMF가 가지는 장점으로는 다음과 같습니다.
-
가중치에 non-uniform 특징으로 학습하게 되면 allows varing importance of latent dimension 할 수 있다고 합니다.
-
그리고 에 non-linear function을 적용하게 되면 linear한 MF 모델 보다 풍분한 표현력을 가질 수 있습니다.
-
3.3 Multi-Layer Perceptron (MLP)
-
NCF 모델에서는 유저와 아이템이라는 2가지 벡터를 입력으로 받기 때문에 두 벡터를 연결(concat)하는 것으로 MLP에 대한 입력 벡터를 구성할 수 있습니다.
-
또한 유저와 아이템 간의 복잡한 interaction 관계를 학습하기 위해서 hidden layer를 여러 개 추가함으로써 flexibility하고 non-linearity한 딥러닝의 장점을 모델에 적용할 수 있습니다.
-
concat된 입력 벡터가 layer를 통과하면, 선형 계산과 비선형 계산의 반복이 이뤄지게 되고 output layer에서 sigmoid function을 적용함으로써 특정 유저와 특정 아이템 간의 interaction 발생 여부에 대한 확률값을 추정할 수 있게 됩니다.
3.4 Fusion of GMF and MLP
- 지금까지 알아본 latent feature interaction에 대한 선형 계산의 GMF와 비선형 계산의 MLP를 NCF 모델 구조에서 함께 사용하게 된다면 각 알고리즘의 장점으로 유저와 아이템 간의 복잡한 관계를 학습함에 있어 보다 시너지 효과를 낼 것이라고 말합니다.
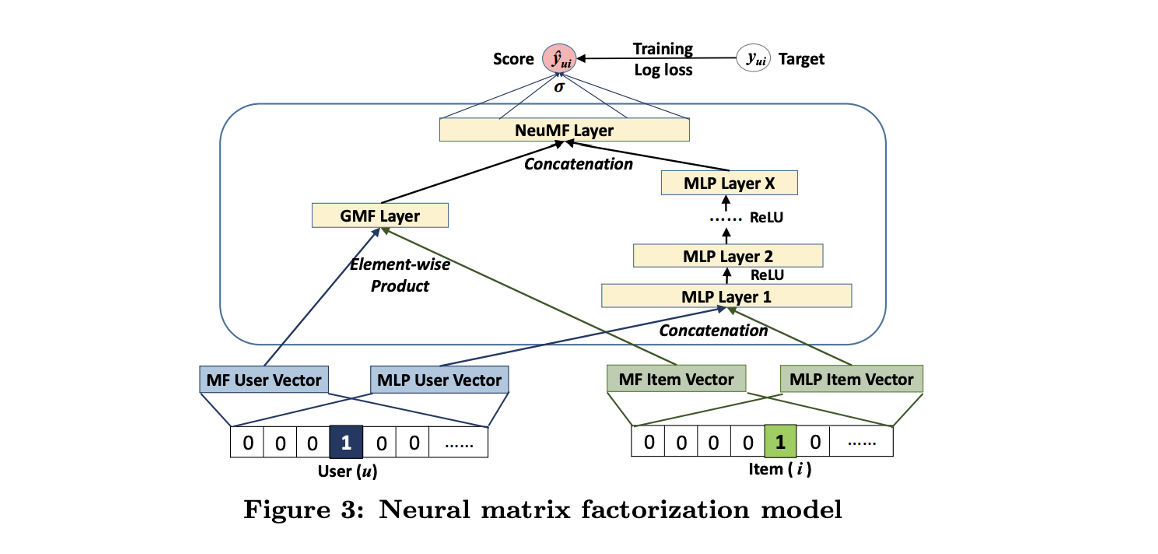
-
가장 단순한 방법으로는 GMF와 MLP 모두 같은 embedding layer를 공유하는 것이며, 각 모델의 결과값을 결합하여 확률값을 추정하는 것입니다.(같은 embedding layer를 공유한다는 것은 같은 embedding vector를 사용한다는 것으로 이해하면 될 것 같습니다.)
- 하지만 이렇게 embedding layer를 공유하게 되면, 임베딩 차원이 같아야 함을 의미하기 때문에 각 모델에 적합한 임베딩 차원을 택할 수 없기 때문에 최적의 앙상블 결과를 얻을 수 없을 수도 있습니다.
-
하이브리드(fused) 모델에 유연성을 부여하기 위해서, GMF와 MLP에 다른 embedding layer를 사용함으로써 다른 embbedding vector를 사용하고 각 모델의 결과값을 연결(concat)하여 확률값을 추정할 수 있습니다.
- 수식을 보면 각 모델에 유저 latent vactor가 로 다르게 입력되었음을 알 수 있습니다.
- 결론적으로 GMF와 MLP가 결합된 위 모델은 MF의 선형성과 DNN의 비선형성을 결합 및 활용하여 유저와 아이템의 관계를 모델링한 구조이며 논문에서는 해당 모델을 NeuMF, Neural Matrix Factorization 이라고 정의하였습니다.
4. EXPERIMENTS
- 이번 섹션에서는 설계한 NeuMF의 모델 성능을 측정하기 위한 실험에 대해 다뤄보고 있으며, 다음 3가지 질문을 기반으로 실험을 진행하였습니다.
RQ1 제시한 NCF 기법이 implicit CF 기법에서 높은 성능을 보이는가?
RQ2 제안한 최적 구조가 추천 과제에 있어 어떻게 작동하는가?
RQ3 DNN 구조가 유저 아이템의 interation을 학습함에 있어 효과적인가?
4.1 Experimental Settings
- MovieLens와 Pinterest, 2개의 데이터에서 실험을 진행하였으며 데이터에 대한 메타데이터는 다음과 같습니다.

4.2 Performance Comparison (RQ1)
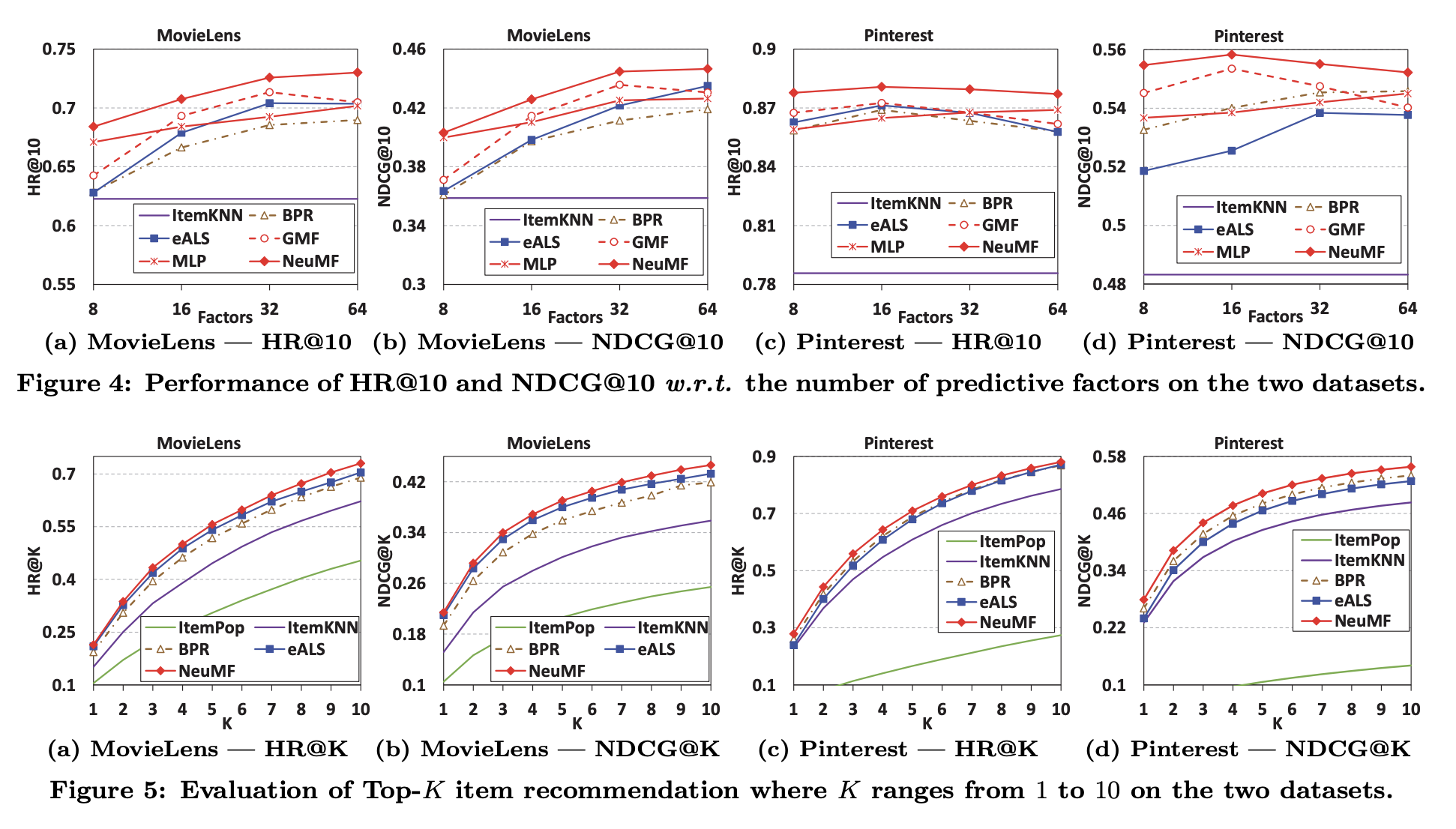
-
성능 평가를 위한 HR@10과 NDCH@10에 대한 각 모델 별 성능 평가표입니다.
-
상단 성능 평가표의 x축인 Factors는 마지막 hidden layer의 차원을 의미하며, 여기서는 model capability 그리고 predictive factors라고 합니다.
-
하단 성능 평가표는 각 성능 지표의 Top-K를 의미하며, 이 때에도 NeuMF가 가장 좋은 성능을 보입니다.
-
4.3 Log Loss with Negative Sampling (RQ2)
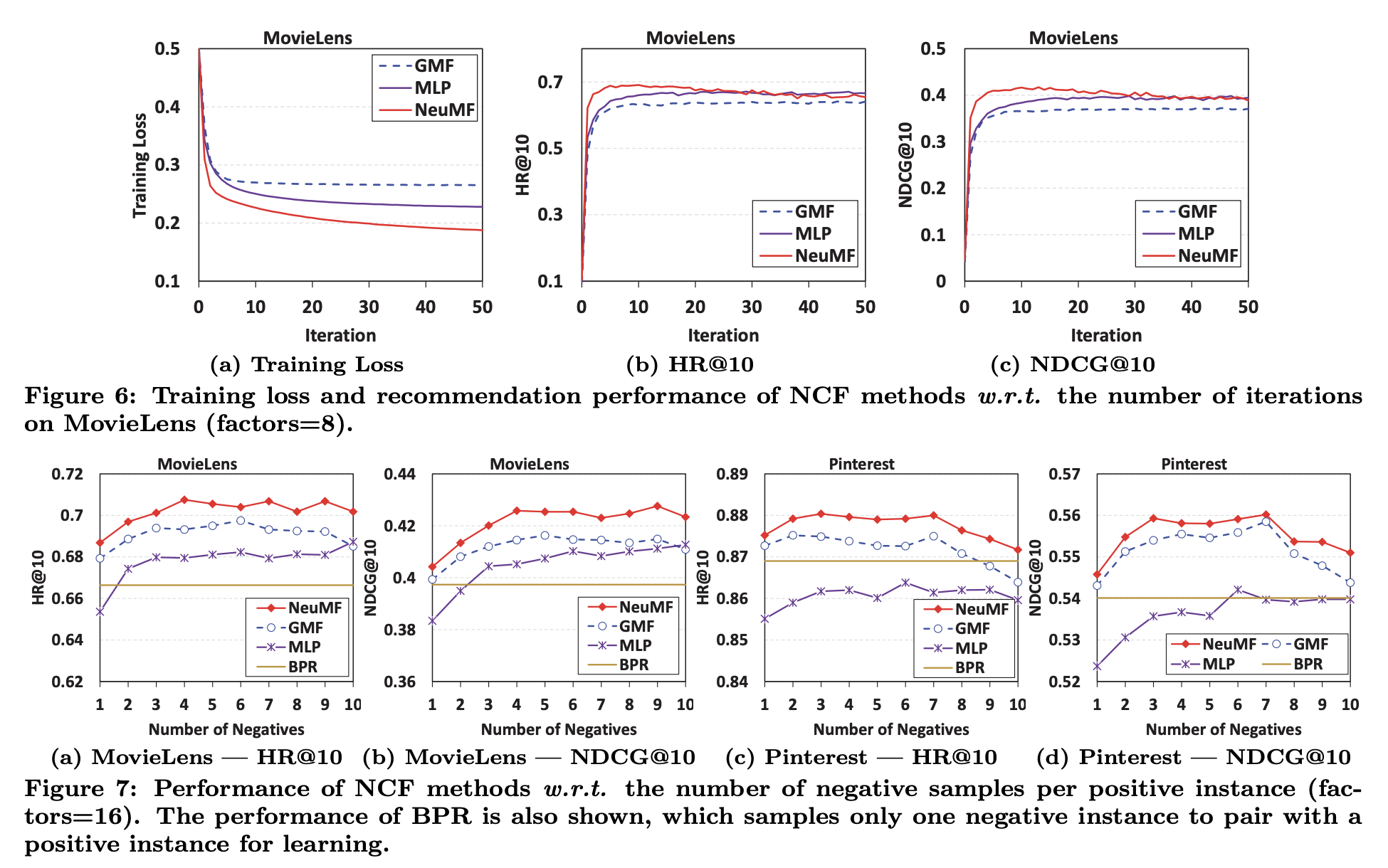
-
Iteration에 따른 각 history와 negative sampling ratio에 대한 성능 평가표입니다.
-
상단 history 표를 통해 'The above findins provide empirical evidence for the rationality and effectiveness of optimizing the log loss for learning from implicit data'. 라고 하는데, 정확한 이유를 모르겠습니다. 아마, 학습이 진행됨에 따라 loss가 줄어들고 성능이 향상됨으로써 제안한 NeuMF가 implicit data에 적합하다는 것을 의미하는 것 같습니다.(그렇지 않다면 loss가 줄어들지도, 성능이 좋아지지도 않을 수 있기 때문입니다.)
-
pairwise objective function은 positive와 negative가 1대1의 쌍이 이뤄져야하는 반면에 pointwise loss을 통해 샘플링 비율을 조절할 수 있었고, negative sampling의 비율을 다르게 함으로써 성능을 비교할 수 있었습니다.
-
4.4 Is Deep Learning Helpful? (RQ3)
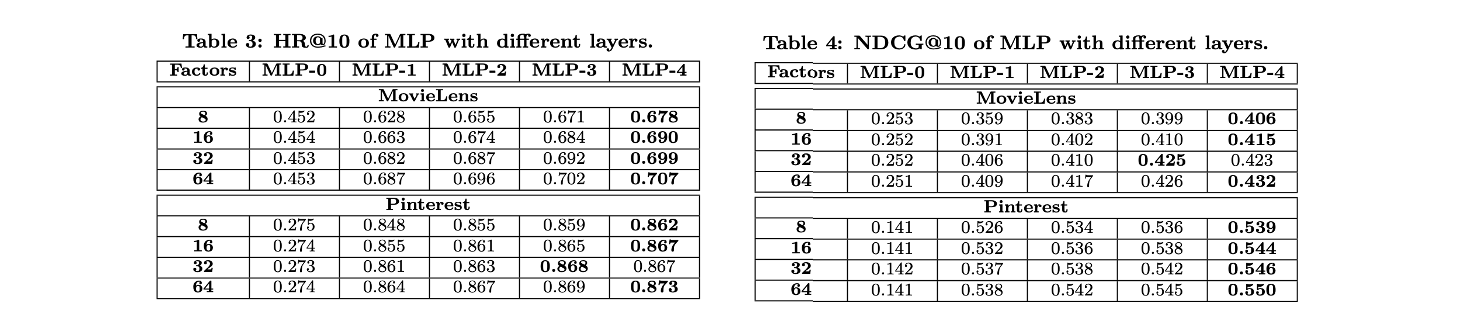
-
유저와 아이템의 관계를 학습함에 있어 DNN을 적용해본 간단한 연구였지만, 추천 과제에 있어 DNN 구조가 굉장히 적합할 수 있음을 알 수 있었다고 합니다.
-
해당 성능 평가표는 마지막 hidden layer의 capacity인 factor와 layer-depth에 따른 각 성능 지표를 보여주며, layer가 깊어질수록 높은 성능을 보이고 있음을 알 수 있습니다.
참고자료
- HyeJinLee, [논문 리뷰] Neural Collaborative Filtering
- Seho Kim blog, Neural Collaborative Filtering(NCF)
- HyeJinLee, Neural_CF-neural collaborative filtering tensorflow 2.0
- 웅사이다, Neural Collaborative Filtering 논문 리뷰
- Hello Blog!, [손실함수] Binary Cross Entropy
- Y.LAB, [Recommender System] - Python으로 Matrix Factorization 구현하기

7개의 댓글

[15기 권오현]
아이템에 대한 유저의 선호도와 interection 정보를 활용하는 기존 Collaborative filtering의 기법중 하나인 Matrix Factorization은 추천 알고리즘의 de facto 알고리즘이 되었다.
MF가 효과적임을 보였지만, 내적을 통한 interaction을 학습하는 것은 성능 향상을 방해하는 문제점을 지니고 있다. 이에 인공신경망 접근법을 구체화 하여 Collaborative filtering 모델인 NCF을 제시하였다.
인공신경망을 CF에 적용하기 위해 유저와 아이템의 벡터를 각각 임베딩하여 Neural CF layers를 통과하여 학습을 진행하는 방안을 제시 하였다. 이 때 Fully-Connected layer를 사용하였으며, 출력으로 나온 dense vector를 유저와 아이템에 대한 latent vector로 볼 수 있다.
논문에서는 NCF 모델 구조에서 인공신경망을 적용한 Matrix Factorization을 Generalized Matrix Factorization(GMF)라고 제안하였다. GMF는 MF와 다르게 유저와 아이템에 대하여 inner product 대신에 element-wise product를 하였으며, edge weights와 activation function을 통해 MF 모델 보다 풍부한 표현력을 가질 수 있다고 설명하였다.
GMF뿐만 아니라 유저와 아이템의 벡터를 연결하여 선형계산과 비선형 계산을 통해 특정 유저와 아이템간의 interaction에 대한 확률값을 추정할 수 있는 MLP 구조도 제안을 하였다.
결론적으로 latent feature interaction에 대한 선형 계산의 GMF와 비선형 계산의 MLP 구조를 fusion한 Neural Matrix Factorization이라는 모델 구조를 제시하였으며, 여러 데이터셋에 대하여 우수한 성능들을 입증하였다.

[15기 류채은]
Collaborative Filtering의 key factor을 모델링하기 위해서는 유저와 아이템 간의 interaction이 요구됨 유저와 아이템의 latent features의 내적과정을 거치게 되는데 이 때 Neural Network-based Collaborative Filtering이 제시된다.
이 논문에서는 유저와 아이템의 latent feature을 모델링하는 인공신경망 구조를 제시하고 구체화하여 인공신경망 기반 collaborative filtering 모델인 NCF를 설계했고 MLP를 통해 NCF는 고차원의 비선형적인 특징을 학습할 수 있었다.
GMF는 내적이 아닌 elemen-wise product가 이루어지며 edge weights와 activation function을 사용한다.
MLP는 유저와 아이템이라는 두 벡터를 concat하여 입력 벡터를 구성하고 hidden layer을 여러 개 추가하여 유연하고 비선형적인 장점을 얻을 수 있다.
GMF와 MLP의 융합의 NCF 모델 구조에서의 사용은 아이템과 유저 사이의 복잡한 관계를 학습하는 데에 있어서 더 좋은 시너지 효과를 낼 수 있다. 이처럼 MF의 선형성과 DNN의 비선형성을 결합 및 활용하여 유저와 아이템 관계를 모델링한 구조를 NeuMF(Neural Matrix Factorization)이라고 일컫는다.

15기 장아연]
기존 Collaborative filtering에서 사용된 Matrix Factorization은 User와 Item의 Interaction과 선호 정도를 표현하는 정보를 이용해 추천시스템에서 사용됨. 그러나 해당 모델의 선형학습으로 인해 다양한 관계를 표현하는데 한계가 존재함. 이를 반영해 GMF와 MLP기반의 MF, 이 둘이 결합한 NeuMF까지 한계를 극복하기 위한 새로운 모델이 등장함.
GMF
기존의 MF에서 이루어진 User와 Item에 대해 inner-product가 아닌 element-wise product가 이루어지고 edge weight와 activation function을 거치면서 비선형성이 더 강해지면서 다양한 관계 표현 가능함.
MLP 기반의 MF
User와 Item을 concat해 MLP의 입력 벡터를 구성해 여러 hidden layer를 통과하며 비선형적성이 적용되고 interaction 발생 여부에 대한 확률이 추청 가능함
NeuMF
latent feature interaction에 대한 계산으로 GMF와 MLP가 결합되어 MF의 선형성과 DNN의 비선형성이 결합되어 user와 item간의 다양한 관계 표현 가능함

[15기 김현지]
NCF는 인공신경망 기반의 collaborative filtering 모델이다.
Generalized Matrix Factorization (GMF)
기존 MF와 유사하지만 내적이 아닌 element-wise product가 이루어 지고 edge weights와 activation function을 사용했다. 비선형성을 추가함으로써 선형적인 MF 모델보다 풍부한 표력을 가진다.
Multi-Layer Perceptron (MLP) 기반 MF
유저와 아이템의 두 벡터를 concat하여 MLP의 input 벡터를 구성한다. hidden layer를 여러 개 추가하여 유저와 아이템 간의 복잡한 상호작용을 학습함으로써 딥러닝 모델의 장점을 CF 모델에 적용하게 된다.
Fusion of GMP and MLP
GMF와 MLP를 결합하여 유저와 아이템간의 다양한 관계를 모델링한다. 이러한 모델을 NeuMF라고 제시하였다.

[14기 이혜린]
- 기존 matrix factorization 모델의 경우, 내적 과정을 거치기 때문에 유저 아이템간 비선형적 관계를 학습하지 못함 → 인공신경망 구조로 대체 (Neural Collaborative Filtering)
- GMF (Generalized Matrix Factorization) : 기존 matrix factorization과 크게 다른 점은 없지만 내적이 아닌 element-wise product가 이뤄지고, edge weights와 activation function을 사용한 것이 차이
- MLP (Multi-Layer Perceptron) : 유저와 아이템 2가지 벡터를 concatenate한 값을 input값으로 사용. 유저와 아이템 간 복잡한 관계를 여러개의 hidden layer를 통해 학습
- Fusion of GMF and MLP : 선형 계산의 GMF와 비선형 계산의 MLP를 NCF구조에서 함께 사용함으로써 확률값 추출
- 결론 : MF의 선형성과 DNN의 비선형성을 결합 및 활용하여 유저와 아이템의 관계를 모델링한 구조
14기 박지은
Neural Collaborative Filtering은 기존 추천시스템에서 널리 사용되는 linear한 matrix factorization에 neural net을 사용하여 non-linear한 구조까지 표현하여 일반화하는 모델입니다. 가장 먼저 유저와 아이템의 원핫벡터가 input으로 입력되면, embedding layer에서 input 단계의 sparse 벡터가 dense 벡터로 매핑됩니다. 이 과정에서 나오는 가중치 행렬의 각 행을 각 유저를 표현하는 저차원의 user latent vector로 사용하게 됩니다. 다음으로 neural collaborative filtering layer에서는 user latent vector와 item latent vector를 합친 벡터를 DNN에 통과시킵니다. 마지막으로 output layer에서는 각 유저와 아이템이 서로 얼마나 관련있는지를 구하기 위해 logistic 함수나 probit 함수를 이용합니다. 일반적 Matrix Factorization에 DNN을 결합하여 성능을 높이는 인상적인 연구였습니다. 좋은 강의 감사드립니다!
[15기 이성범]
본 논문은 기존의 MF알고리즘에 NN의 방식을 활용한 새로운 모델(NCF)인 GMF와 MLP 기반의 MF, 그리고 두 모델을 concat한 NeuMF 까지 총 3가지 유형의 추천시스템 모델을 제안했다.
기존의 MF 알고리즘은 User와 Item의 Latent Features에 내적을 통하여 input을 추론하는 과정으로 이루어진다. 이러한 학습방식은 선형 결합이기 때문에 User와 Item간의 복잡한 관계를 충분히 학습하지 못한다고 한다.
GMF은 User와 Item의 Latent Features에 element-wise product을 한 후, Linear Layer와 activation function을 거침으로써 선형적인 기존의 MF보다 비선형성이 강해짐으로써 조금 더 다양한 관계를 표현할 수 있다고 한다.
MLP 기반의 MF은 User와 Item의 Latent Features를 concat한 후, hidden layer룰 여러 개 거치는 방식으로 학습이 진행된다. 이러한 학습 방식 덕분에 비선형적인 딥러닝의 장점을 모델에 적용할 수 있다고 한다.
NeuMF는 GMF와 MLP 기반의 MF의 output을 서로 concat 한 후, Linear Layer와 activation function을 거치는 방식으로 학습이 진행된다. 이러한 학습 방식 덕분에 MF의 선형성과 DNN의 비선형성을 결합함으로써 유저와 아이템의 관계를 조금 더 풍부하게 표현할 수 있다고 한다.
기존의 MF 알고리즘을 NN의 방식으로 재해석했다는 점이 본 논문이 가져다주는 가장 큰 시사점이라고 생각한다.
개인적으로 본 논문에서 제시한 NeuMF 모델의 경우 negative sampling을 어떻게 하느냐에 따라서 모델의 성능이 매우 달라질 것이라고 생각된다. 기존의 MF 알고리즘의 경우 모든 Data를 활용했지만 본 논문에서 제시한 NeuMF 모델은 유저가 이미 시청한 Item인 positive sampling과 유저가 아직 시정하지 않은 Item 중 몇 개를 선정하여 negative sampling을 하고 두 sampling을 합쳐서 모델을 학습시킨다. 이러한 학습 방법 때문에 negative sampling 방식에 따라서 모델의 성능차이가 크게 발생할 것이다. 왜냐하면 유저가 아직 시청하지 않았다고 해서 앞으로도 시청하지 않을 Item은 아니며 앞으로 시청할 가능성이 높은 Item 일 수도 있기 때문이다. 따라서 본 논문에서 제시한 NeuMF 모델의 성능을 높이기 위해서는 개인적으로 Content-based Model을 활용하여 어느 정도 Item을 sampling하여 negative sampling을 하는 것이 좋다고 생각한다.