1. 데이터 찾기 및 선정
part1에서와 결정한 것과 같이 조금 더 정리가 된 데이터로 바꾸었다. 목표는 여전히 데이터를 통하여 창업시 미래를 예측하는 것이다.
2. 데이터 Wrangling, EDA
2.1 데이터 불러오기

이미지와 같이 필요없어 보이는 피처들은 삭제 되어 보이고 가장 큰 문제였던 market이 단일 업종으로 정리가 되어있어 고민이 사라졌다.
<in>
data_count = df.shape[0]
feature_count = df.shape[1]
print('data_count: %s' % data_count, 'feature_count: %s' % feature_count) # %문자 % 입력값 1:1에 맞춰서 대입
<out>
data_count: 61398 feature_count: 112.2 데이터 탐색
2.2.1피처 의미 파악
name = 회사명
market = 업종
funding_total_usd = 총 투자받은 금액
status = 상태
country_code = 국가코드
state_code = 지역코드
city = 도시
funding_rounds = 투자받은 횟수
founded_at = 설립일
first_funding_at = 처음 투자받은 날
last_funding_at = 마지막 투자받은 날
part1과 거의 유사했다. 여기서 'status'를 타겟으로 정했으며
<in>
df['status'].unique()
<out>
array(['ipo', 'operating', 'acquired', 'closed'], dtype=object)클래스는 총 4가지가 있었다. 'ipo'는 주식상장을 의미하며 'acquired'는 인수된걸 의미한다.
따라서 내가 생각하기엔 'ipo','acquired'는 성공이라 생각하고 타겟을 3가지로 줄여서 다중분류분석으로 진행할 계획이다.
2.2.2 Feature 제거 및 추가
분석에 불피요하다고 생각한 'name','State_code','City_code', 'First_funding_at','Last_fundin_gat','Last_funding_at' 제거했다. 여기서 'First_funding_at','Last_funding_at'는 뭔가 만들어낼수 있었을 텐데 도메인 지식이 부족하여 사용하지 못한게 많이 아쉬웠다.
그리고 'Average_funding_once'라는 새로운 feature를 생성하였다. 'funding_total_usd'/'funding_rounds'로 1회 평균 투자금액이라는 의미를 가지고 있다.
2.2.3 Group
업종, 국가코드의 경우 많은 카디널리티를 가지나 중요한 feature라 생각하여 삭제는 못하고 줄여야 될 것 같았다. 따라서 그 당시에는 '상위 20개만 남기고 나머지는 etc로 그룹을 해버리자' 라고 판단을 하였고 이렇게 진행을 했다.
<in>
a = df['market'].value_counts().head(20)
a = a.reset_index()
b = np.array(a['index'])
test_list = b
def jung(i):
if i in test_list:
return i
else:
return 'etc'
df2['market']=df['market'].apply(jung)
df2['market'].value_counts().head(21)
<out>
etc 29735
Software 5610
Biotechnology 4110
Mobile 2348
E-Commerce 2209
Curated Web 1778
Enterprise Software 1465
Games 1351
Clean Technology 1322
Advertising 1268
Health Care 1234
Hardware + Software 1183
Health and Wellness 1158
Education 1094
Finance 1056
Social Media 1050
Manufacturing 891
Analytics 767
Security 623
Consulting 576
Apps 570
Name: market, dtype: int64설립일의 경우 일자별로 다루기엔 시계열 데이터를 어떻게 정리를 해야될까 라는 고민을 하다 시간이 없어서 5년 단위로 그룹을 하여 진행했다.
여기서 정말 아쉬웠던 건 국가의 경우 135개라 좀 더 크게 아시아, 아프리카, 북아메리카, 남아메리카, 남극, 유럽, 오세아니아 이렇게 대륙으로 나누어서 했으면 더 좋지 않았을까 라는 생각이 들었다.
2.2.4 이상치 처리
이상치를 상한선, 하한선에 맞추거나 제거하려 했지만 생각을 해보니 트리모델은 외삽이 불가능한걸로 알고 있다. 따라서 이상치도 중요한 데이터라 생각하고 그대로 가져가서 사용기로 하였고 대신 뒤에 나올 내용중에 이상치에 덜 민감한 robustscaler를 고려하였다.
2.2.5 데이터 불균형
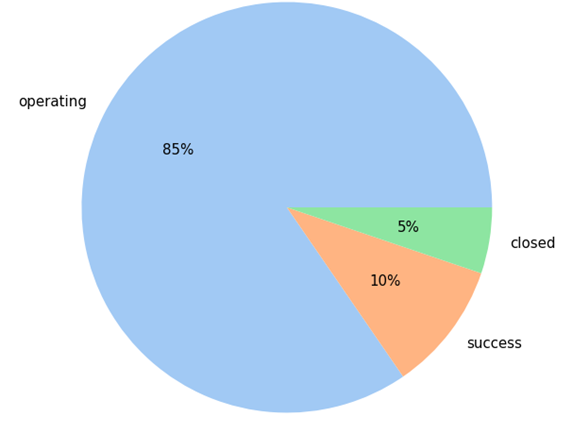
파이그래프를 보면 타겟의 데이터가 불균형으로 여겨진다. 따라서 오버샘플링, 언더샘플링을 진행하기로 결정했다.
2.3 분석 목표 및 가설 설정
우선 나는 내가 창업을 한다면 어떤 조건에 따라 결과가 달라지지 않을까?? 라는 질문에 답하려고 설정했다.
1) 창업을 한다면 어떤 업종으로 할 것인가?
창업 성공에 유리한 업종이 있을 것이다.
2)성공하기 좋은 국가가 있을까?
창업 성공에 유리한 국가가 있을 것이다.
3)선택한 업종은 어느정도 투자를 받아야 할 것인가?
어느정도 투자금액이 있어야 안정적으로 운영이 될 것이다.
2.4 데이터 시각화
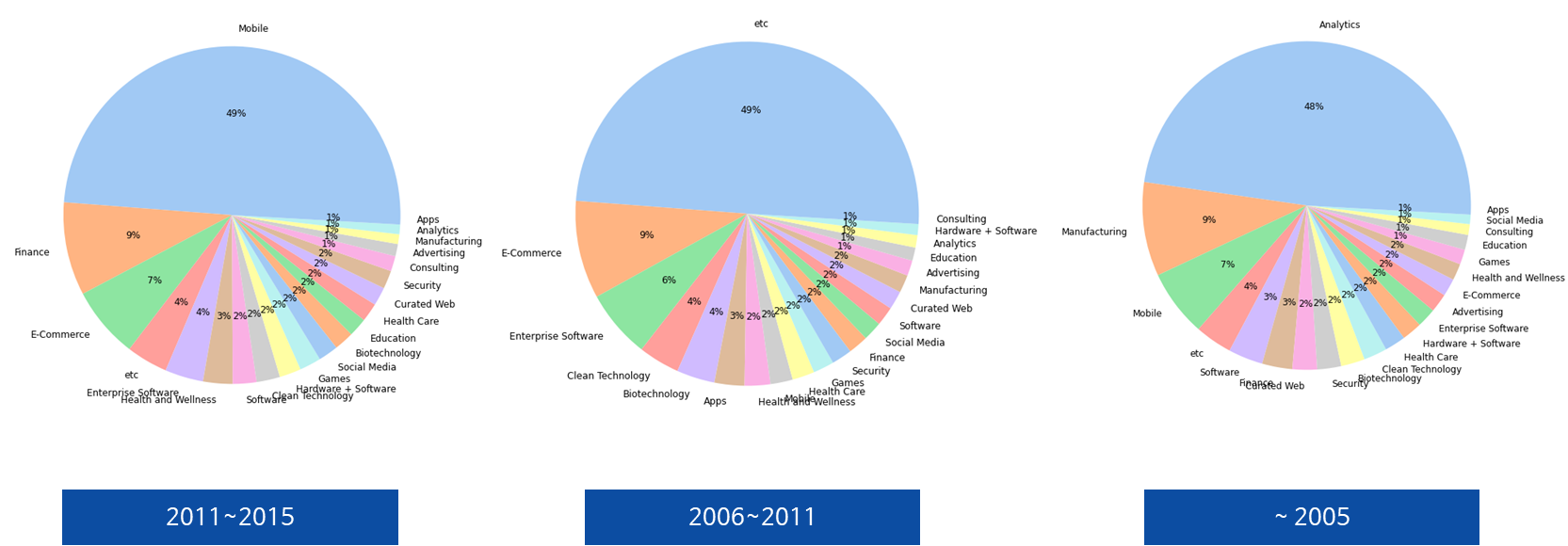
우선 연도별 데이터 업종 트렌드가 있을 것으로 판단하여 시각화 하였더니 역시 존재하였다.
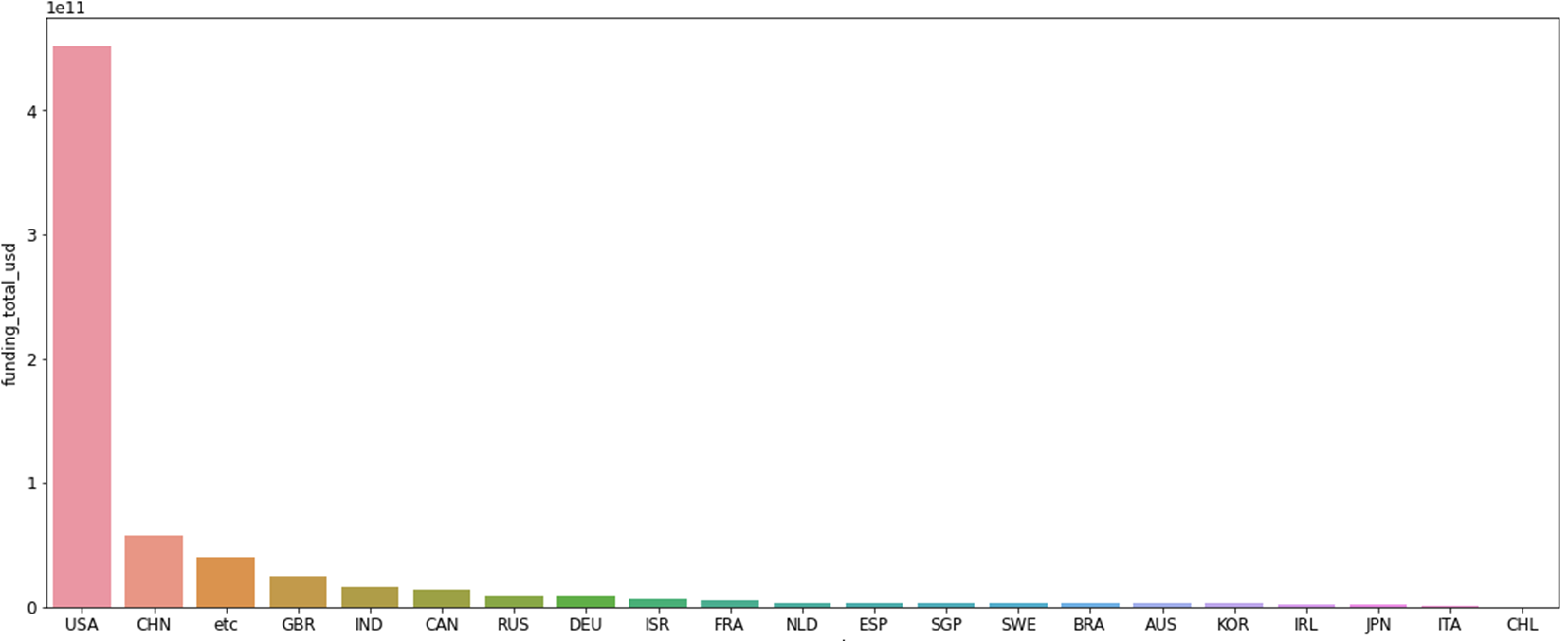
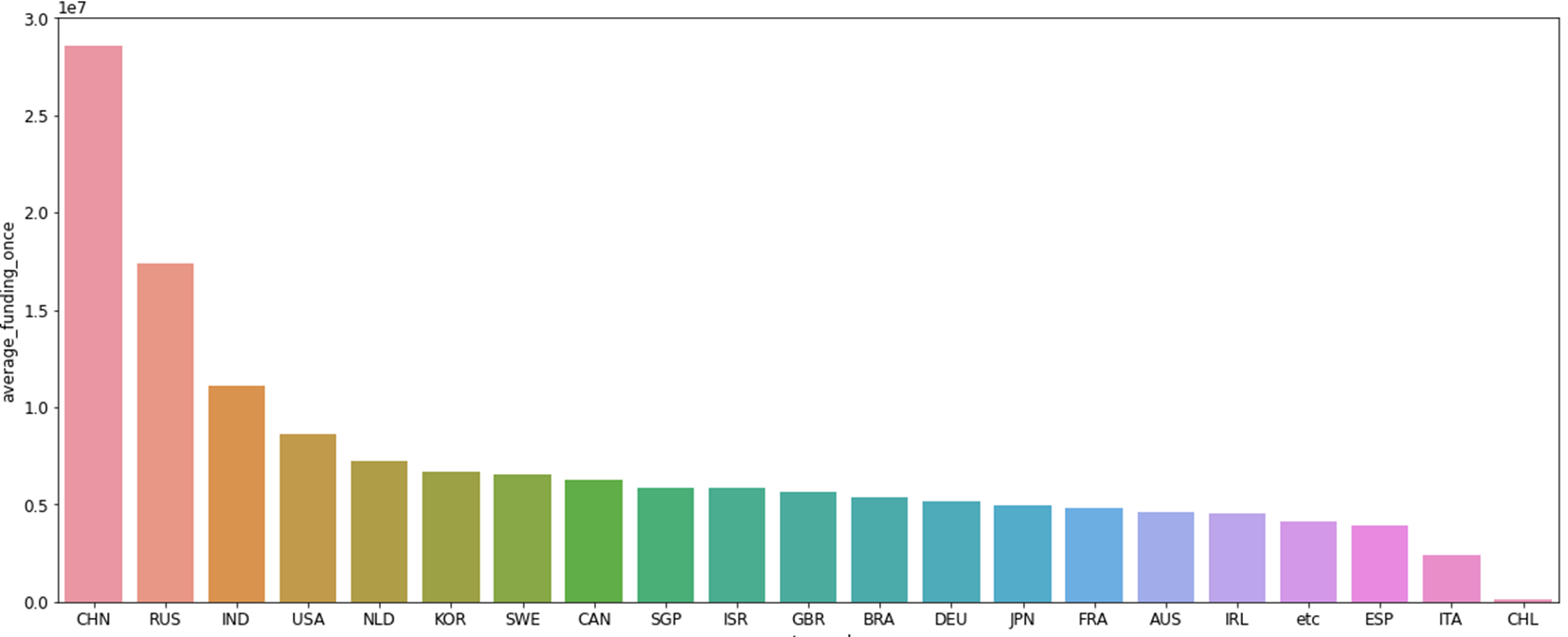
다음으로 위에는 '국가별 총 투자금액', 아래는 '국가별 평균 투자금액'그래프로 총 투자금액보단 평균투자금액을 사용하는 것이 더 좋은 피처라고 생각이 들었다. 총 투자금액은 미국이 회사도 많고 하다보니 총 투자금액이 높을 수 밖에 없는거 같았다.
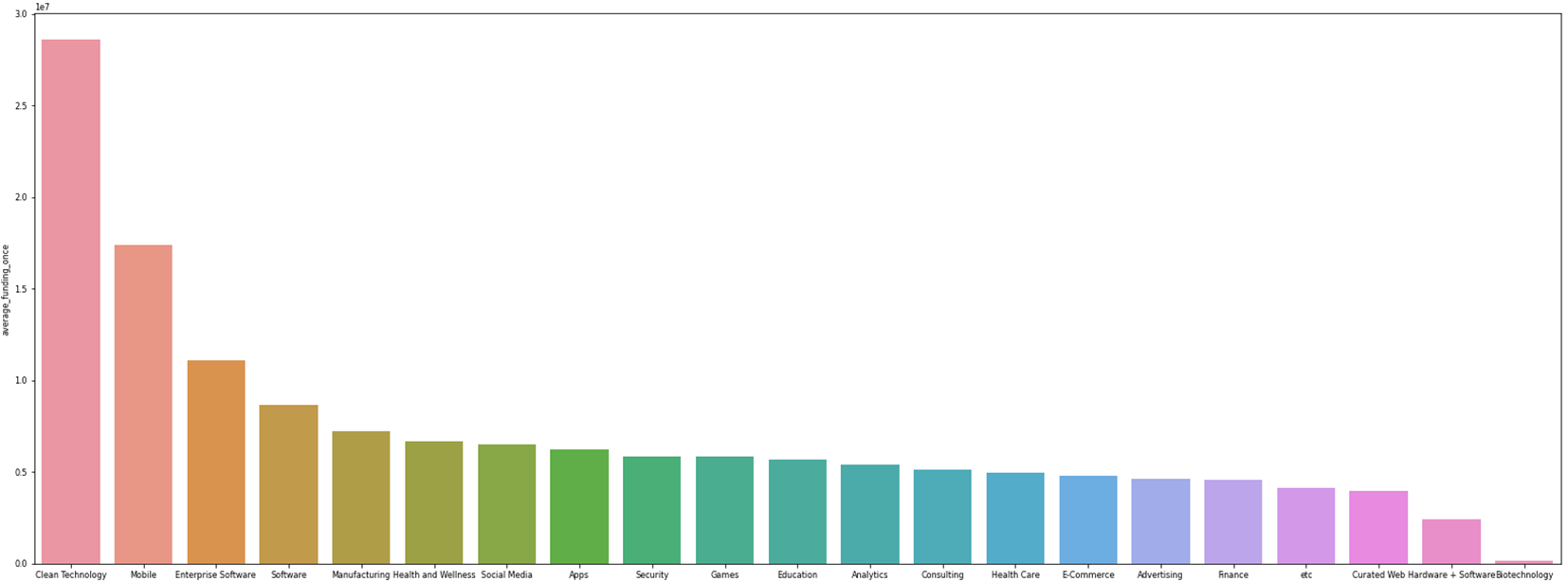
마지막으로 '업종별 1회 평균 투자금액'으로 업종마다 투자금액 수준이 달라질 것이다.
3. 모델링
우선 스케일러를 사용하여 모델링의 성능을 높일 것이며, 오버샘플링 또는 언더샘플링을 통해 데이터 불균형을 해결, 마지막으로 어떤 분석방법을 사용할 것인지 비교하여 선택하는 과정으로 진행했다.
3.1 모델링 성능 비교
3.1.1 Robustscaler & MinMaxScaler & StandardScaler
우선 스케일러를 어느것을 사용할지 결정하기위해 3가지 스케일러를 비교했다.
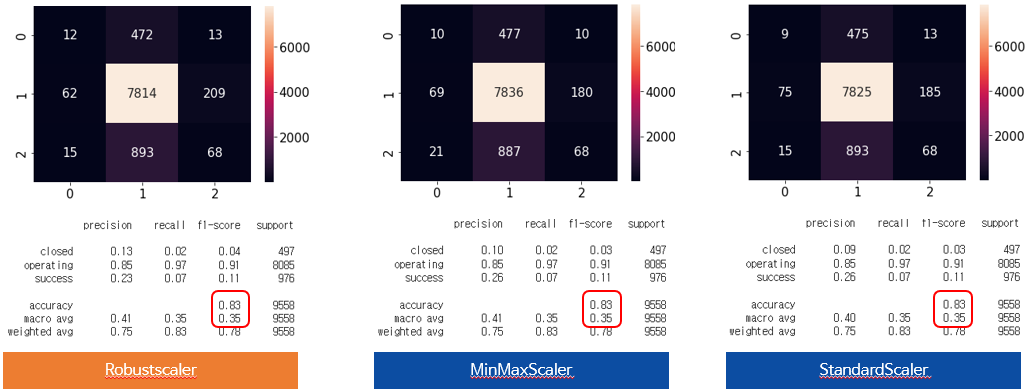
3가지 스케일러 모두 정확도, f1_score가 동일하지만 앞에서 말했듯이 이상치를 제거 안하고 사용함에 따라 영향을 적게 받는 Robustscaler를 사용하기로 했다.
3.1.2 Undersampling(Nearmiss) & Oversampling(SMOTE)
오버샘플링과, 언더샘플링은 이번에 처음 사용한거라 좀 미숙한 것도 있었지만 새로운걸 또 알게되어서 재밌게 진행했다. 또 중요하게 깨달은건 훈련셋트에만 적용을 한다는 것이다. 검정셋트나, 테스트셋트도 변경하면 의미가 없기 때문이다.
먼저 언더샘플링은 Nearmiss라는 것을 사용했다. 간단한 알고리즘 구현 방식은
- 알고리즘은 먼저 더 작은 클래스의 포인트와 더 큰 클래스의 모든 포인트 사이의 거리를 계산합니다. 이렇게 하면 언더샘플링 프로세스를 더 쉽게 만들 수 있습니다.
- 더 작은 클래스와 가장 짧은 거리를 가진 더 큰 클래스의 인스턴스를 선택하십시오. 이 n개의 클래스는 제거를 위해 저장해야 합니다.
- 더 작은 클래스의 m개의 인스턴스가 있는 경우 알고리즘은 더 큰 클래스의 m*n개의 인스턴스를 반환합니다.
이렇다고 한다.(https://analyticsindiamag.com/using-near-miss-algorithm-for-imbalanced-datasets/)
따라서 내가 가진 데이터에 적용을 하면
<in>
from imblearn.under_sampling import NearMiss
nr = NearMiss()
X_train_under, y_train_under = nr.fit_resample(X_train_encoder, y_train)
y_train_under.value_counts()
<out>
closed 1989
operating 1989
success 1989
Name: status, dtype: int64이처럼 제일 적은 클래스 수에 맞추다보니 데이터 손실이 엄청났다. 아마 훈련이 제대로 안될것이다.
다음 오버샘플링은 SMOTE라는 방식을 선택했다. 구현 방식은
- 소수 데이터 중 특정 벡터 (샘플)와 가장 가까운 이웃 사이의 차이를 계산한다.
- 이 차이에 0과 1사이의 난수를 곱한다.
- 타겟 벡터에 추가한다.
- 두 개의 특정 기능 사이의 선분을 따라 임의의 점을 선택할 수 있다.
라고한다.
구현을 해보자!
<IN>
smote = SMOTE(k_neighbors=4, random_state=2, n_jobs=-1)
X_train_over,y_train_over = smote.fit_resample(X_train_encoder,y_train)
y_train_over.value_counts()
<out>
operating 32337
success 32337
closed 32337
Name: status, dtype: int64데이터가 엄청 늘어났다. 가상의 데이터를 쓰는거라 사용하기전엔 믿음이 그렇게 가진 않았다.
이후 둘의 성능을 비교해봤다.
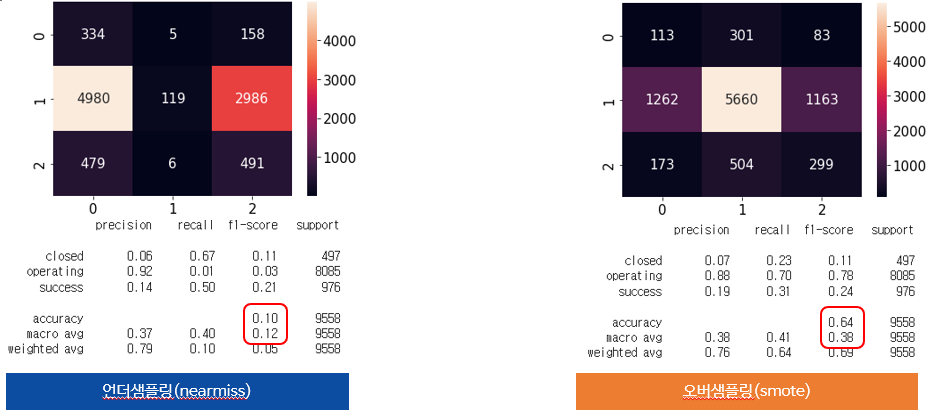
이번 데이터는 오버샘플링이 언더샘플링보다 더 좋은 성능임을 확인하여 오버샘플링을 선택하였다. 여기서 타겟의 비율을 1:1:1로 설정하였는데 아쉬운건 조금 더 시간이 있었다면 오버샘플링을 선택후 '클래스의 비율을 바꿔가면서 좋은 쪽을 선택했으면 어땠을까??' 라는 미련이 남았다.
3.1.3 RandomForestClassifier & KNN(K-Nearest Neighbours)
KNN 역시 이번에 다중분류를 위해 처음 써보게 되었다. 아직 미숙하여 조금 더 알아보는게 좋을꺼같다.
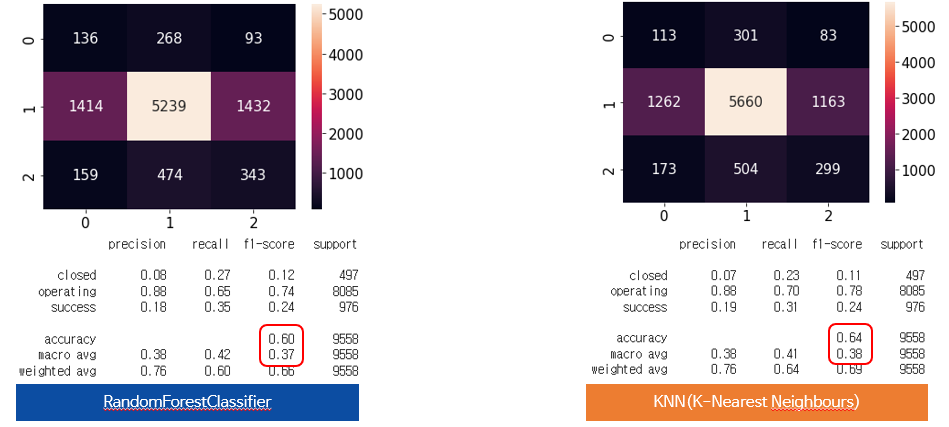
이처럼 둘의 성능을 비교해 봤을때 KNN이 조금 더 적합한 것이라고 판단했다.
3.2 최적 파라미터 설정
KNN의 경우 파라미터가 크게 3가지 사용한다고 한다.
-
n_neighbors = 최근접 이웃 수 설정 후 주변데이터가 더 많이 포함된 것으로 설정 따라서 짝수로 설정 시 동점이 나올 가능성이 있어 홀수 추천
-
weights = 분류할 때 인접한 샘플의 거리에 따라 다른 가중치 부여
-
metric = 거리계산 방식
그리고 Scoreing은 f1_score가 너무 떨어짐 따라서 f1으로 설정하기로 했다.
이제 구현을 해보자
<in>
from sklearn.model_selection import RandomizedSearchCV
pipe3 = make_pipeline(
RobustScaler(),
KNeighborsClassifier())
dists = {
'kneighborsclassifier__n_neighbors' : [3,5,7,9],
'kneighborsclassifier__weights' : ['uniform','distance'],
'kneighborsclassifier__metric' : ['euclidean','manhattan','chebyshev','seuclidean','minkowski']
}
clf= RandomizedSearchCV(
pipe3,
param_distributions=dists, # 파라미터 입력
n_iter = 50, # random search 탐색 횟수
cv = 5, # cv 검증을 위한 분할 검증 횟수
scoring='f1', # 오차 평가방법
verbose=1, # 진행상황
random_state = 2
)
clf.fit(X_train_over, y_train_over)
y_test_pred = clf.predict(X_test_encoder)
print('최적 하이퍼파라미터: ', clf.best_params_)
<out>
최적 하이퍼파라미터: {'kneighborsclassifier__weights': 'uniform', 'kneighborsclassifier__n_neighbors': 3, 'kneighborsclassifier__metric': 'euclidean'}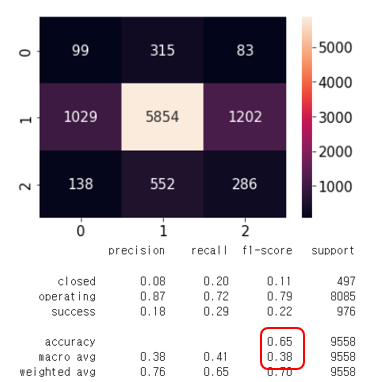
여기서 weights는 uniform이라고 나왔지만 실제로 distance로 설정시 더 잘나왔다.....
그래서 최종모델의 성능은 정확도가 0.65, f1-score가 0.38로 나왔다.
4. 모델 해석
모델 해석은 이번에 배운 plpplot을 통하여 해석 해보려고 한다.
import matplotlib.pyplot as plt
from pdpbox import pdp
feature = 'average_funding_once'
features = X_test_encoder.columns
pdp_dist = pdp.pdp_isolate(model=pipe4, dataset=X_test_encoder, model_features=features, feature=feature)
pdp.pdp_plot(pdp_dist, feature);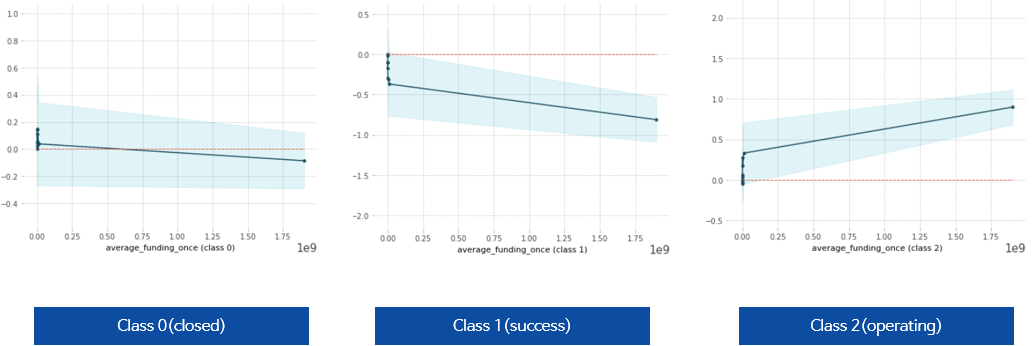
1회 평균 투자 받은 금액이 증가할수록 실패 또는 성공할 확률은 적어지고, 운영에 대한 확률은 증가한다고 보여진다.
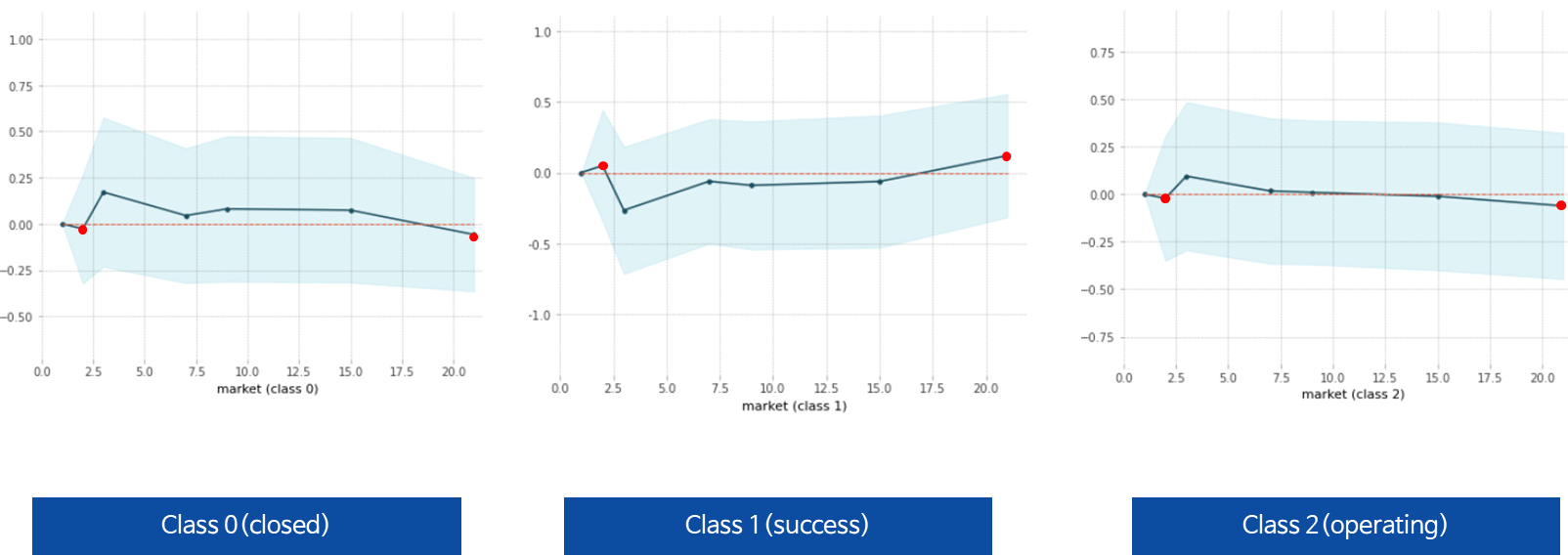
빨간 포인트는 성공확률이 높은 곳을 표시, 성공할 확률이 높은 업종이 존재한다.
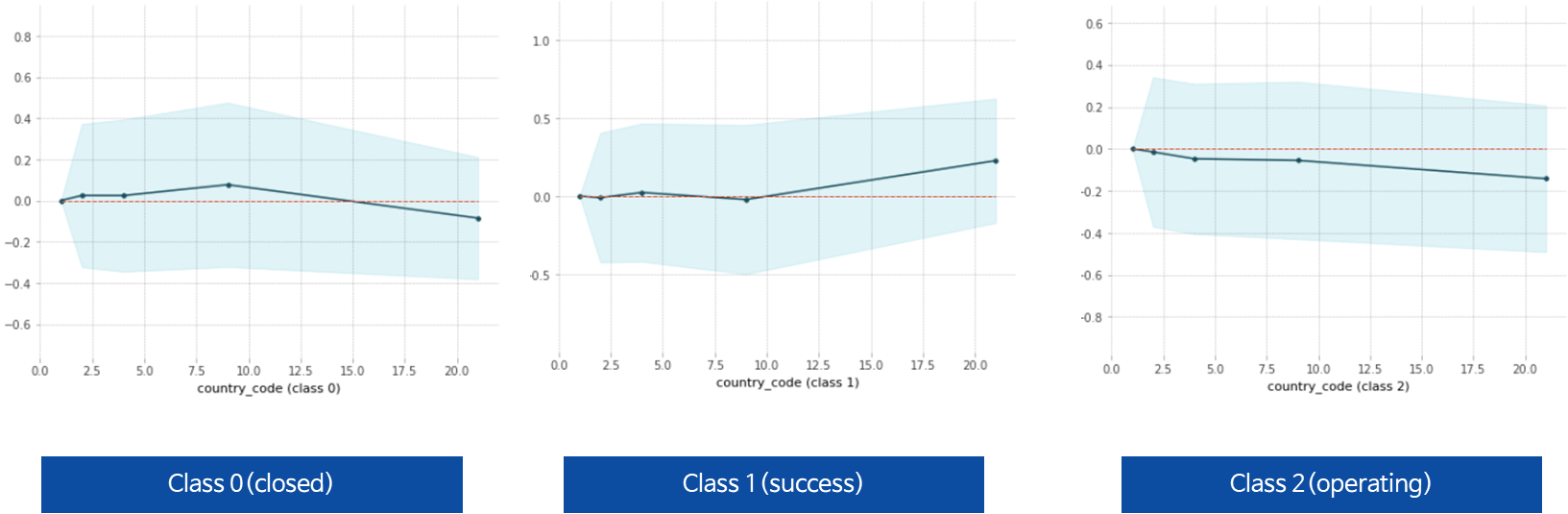
Class0 ,Class1 그래프를 보면 성공 확률이 높아지는 국가는 존재한다.
아직 해석이 좀 미흡한 부분이 있었던거 같다. 또한 2가지 변수를 이용한 pdpplot은 못그렸는데 아쉬웠다.
최종 결론은
데이터를 통해(2015년까지) 스타트업 회사가 늘어나는 추세임을 알 수 있고 성공(인수,주식상장)을 하려면 업종과 국가선택이 중요하다고 내렸다.
정말 아쉬운 부분들이 넘처나는 프로젝트였다. 섹션3때는 같은 실수를 반복하지 말고 더 좋은 모습으로 해보고 싶다.
