저번 포스트에선 몇개의 레이어를 통해 간단하게 MNIST 손글씨 분류를 진행해보았습니다.
하지만, 훈련 데이터의 정확도가 검증 데이터의 정확도를 아득히 뛰어넘어버리는, 즉 모델이 훈련 데이터에만 익숙해지는 오버피팅 현상이 일어났습니다. 이번 포스트에선 이러한 오버피팅 문제를 해결할 방법을 짧게 알아보겠습니다.
오버피팅의 문제점
오버피팅Overfitting은 말 그대로 특정 데이터에만 과하게 학습된 상태를 의미합니다. 대부분의 문제에선 특정 데이터는 훈련 데이터를 의미합니다.
오버피팅이 발생하게 되면 해당 데이터에선 높은 정확도를 보여주지만 검증 데이터, 테스트 데이터 등의 새로운 데이터에선 제대로 동작하지 않게 됩니다. 즉 모델의 성능에 치명적인 영향을 끼친다는 것이죠. 그렇다면 우리가 배우고 있는 인공신경망(Deep Learning)에선 어떤 방법을 통해 과적합을 줄일 수 있을까요?
1. 더 많은 데이터 확보하기
어떤 문제에서든, 훈련하는데 필요한 데이터가 부족하면 모델은 부족한 데이터에서 필요 없는 패턴이나 노이즈 등까지 학습하게 됩니다. 말 그대로 과하게 학습한 것이죠. 데이터의 수를 늘려 모델이 인식할 수 있는 패턴의 가짓수를 늘려줌으로써 특정 패턴에 익숙해지지 않도록 하는 것 입니다.
한편, 데이터의 양을 늘리는 것보단 기존에 있는 데이터를 약간 변형해 사용하는 데이터 증강이라는 방법이 존재합니다. 대표적으로 이미지 학습 방법에서는 이미지를 돌리거나(rotate) 반전, 특정 방향으로 밀어내는 등의 방법을 사용합니다.
2. 모델 복잡도 줄이기
인공 신경망의 복잡도는 은닉층(hidden layer)의 수나 매개변수의 수 등으로 결정됩니다. 신경망의 은닉층을 줄이거나, 노드의 수를 줄이는 방법 등으로 모델의 복잡도를 낮춰 과적합을 완화할 수 있습니다.
3. 가중치 규제 적용하기
모델의 가중치들에 직접적인 규제를 적용해서 모델의 복잡도를 줄일 수 있습니다. 대표적인 규제 두가지는 다음과 같습니다.
- L1 규제 : 가중치 w들의 절대값 합계를 손실 함수에 추가합니다. L1 노름이라고도 합니다.
- L2 규제 : 모든 가중치 w들의 제곱의 합을 손실 함수에 추가합니다. L2 노름이라고도 합니다.
두 규제 모두 가중치들의 크기가 작아져야 오차값이 줄어든다는 공통점을 가지고 있습니다. 옵티마이저는 오차의 값을 최대한 줄이는 방향으로 가중치를 바꾸며, 규제를 적용하면 가중치는 줄이고 정확도 높은 예측을 하는 방식으로 학습하게 됩니다.
위의 규제 외에도 인공신경망에선 정규화(Normalization)라는 방법을 사용할 수 있습니다.
배치 정규화, 층 정규화 등이 이에 해당합니다.
4. 드롭아웃 추가
드롭아웃DropOut 이라는 방법은 레이어의 가중치 일부를 사용하지 않는 방법입니다. 랜덤한 데이터의 특징을 사용하지 않는 방법으로 오버피팅을 완화합니다. 그림으로 표현하면 다음과 같습니다.
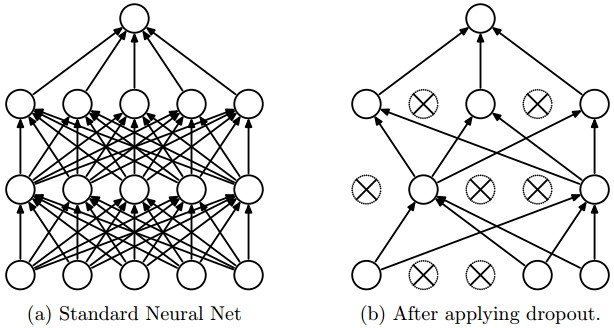
드롭아웃 방법은 모델을 훈련할 때만 사용하지 않으며, 예측때에는 모든 파라미터를 온전히 사용합니다.
실습
이전 포스트에서 작성한 모델에 드롭아웃 방법을 추가해 오버피팅을 줄여보겠습니다. 자세한 코드는 저번 포스트를 참고해주세요!
이전에 작성한 모델에 두개의 Dense 레이어를 추가하고, 그 사이마다 드롭아웃 층을 추가합니다.
model = Sequential() # 모델 선언
model.add(Dense(128, activation="relu", input_shape=(input_shape, )))
model.add(Dropout(0.2))
model.add(Dense(64, activation="relu"))
model.add(Dropout(0.2))
model.add(Dense(number_of_classes, activation="softmax"))각각의 드롭아웃 층은 2할에 해당하는 가중치를 사용하지 않도록 합니다. 첫번째 층에선 25개 가량의 가중치를, 두번째 층에선 12개 가량의 가중치를 사용하지 않습니다.
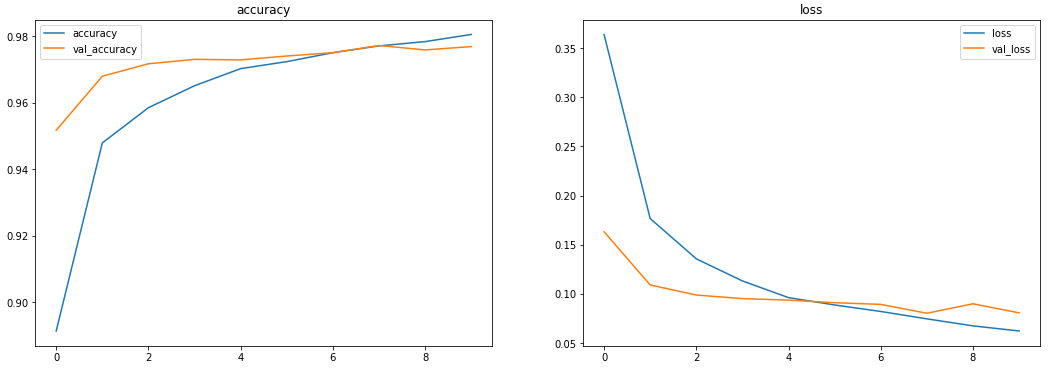
결과를 보니, 드롭아웃을 사용하지 않았을 때에 비에 확실히 과적합이 완화되었음을 확인할 수 있습니다. 나쁘지 않네요!
다음 포스팅에선 이미지를 처리하는데 굉장한 성능을 보이는 CNN 기법에 대해 알아보도록 하겠습니다. 어려운 점이나 궁금한 점은 댓글로 남겨주시면 성심성의껏 답변해드리겠습니다. 오탈자, 잘못된 정보 교정은 언제나 환영입니다!
