
확률론
딥러닝에서 확률론이 쓰이는 이유는 딥러닝 자체가 확률론 기반의 기계학습 이론과 loss function에서 데이터 공간을 통계적으로 해석해서 유도해내기 때문이다.
이산확률변수&&연속확률변수
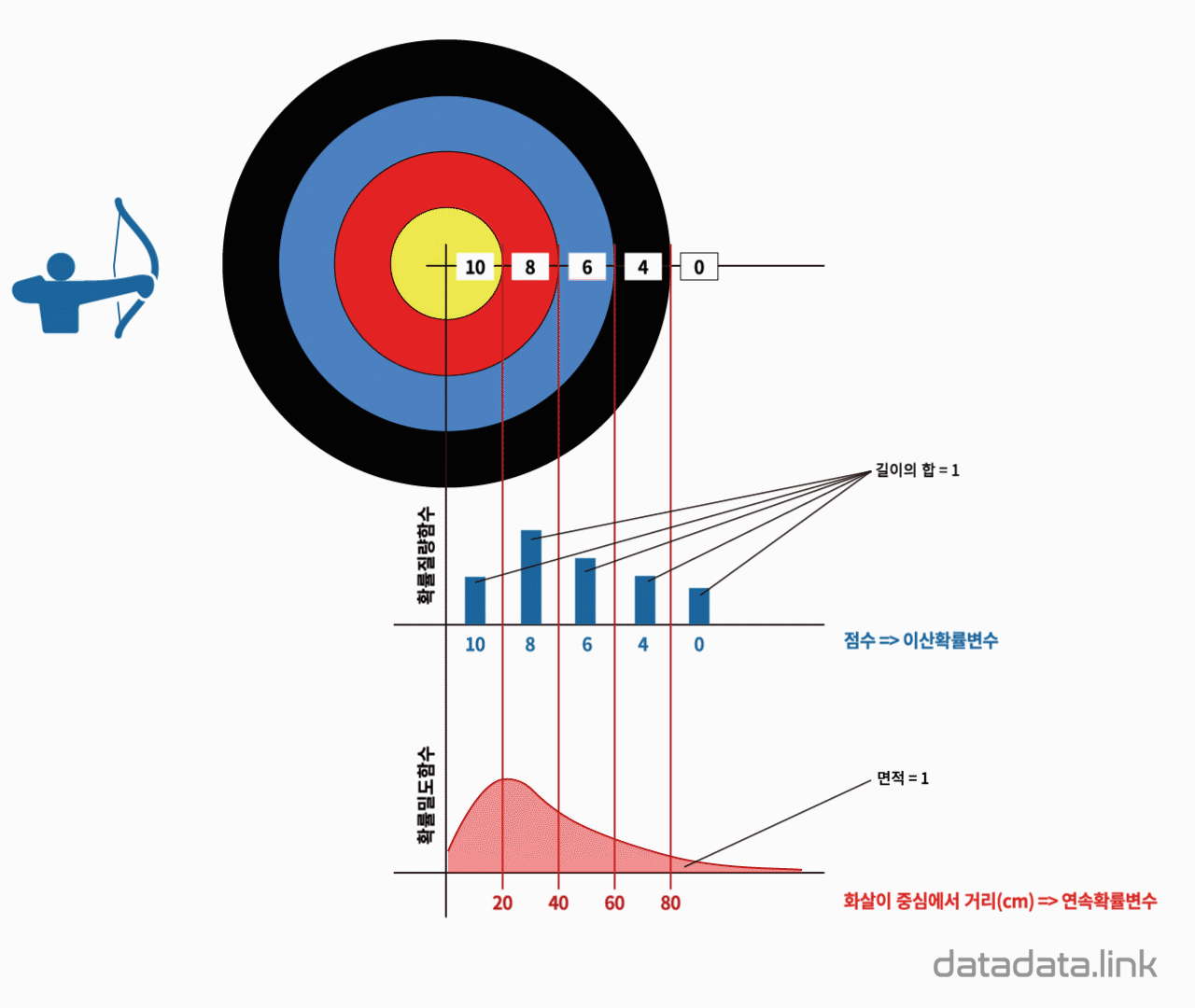
위의 사진을 보게될 경우 단순하게 보면 이산확률변수는 점수로 나오는 반면 연속확률변수는 거리로 나오게 된다.
- 이산형 확률변수는 확률변수가 가질 수 있는 경우의 수를 모두 고려하여 확률 더해서 모델링 한다.
- 연속형 확률변수는 데이터 공간의 정의된 확률변수의 밀도 위에서 적분을 통해 모델링을 진행한다.
통계
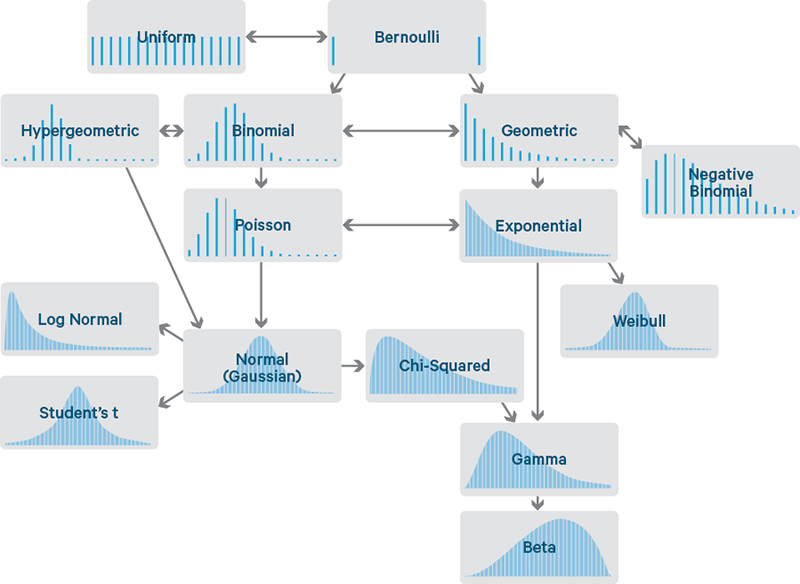
통계적 모델링은 우리가 이 데이터가 이러한 확률분포를 따를것이라고 가정하고 이를 추정하는 것이다. 하지만 정확하게는 알아낼수 없으므로 최대한 근사하는것이라고 할 수 있다.
각 분포들은 모수가 있으며 예시로 정규뷴포의 경우 평균 μ와 분산 으로 구성되있다.
최대 가능도 추정법
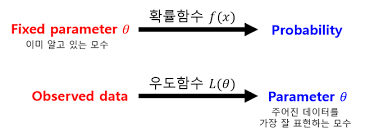
주어진 표본에 대해 가능도를 가장 크게하는 모수 를 찾는 방법이다. 수식은 생략하고 유의점은 우도함수는 확률함수가 아니다 기본적으로 확률의 합은 항상 1이지만 우도함수값은 1이 아니다.
베이즈 통계학
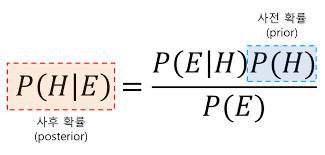
베이즈 정리는 새로운 정보를 토대로 어떤 사건이 발생했다는 주장에 대한 신뢰도를 갱신해나가는 방법이다.
https://angeloyeo.github.io/2020/01/09/Bayes_rule.html
회고
1주차에 내용이 너무 많아서 전부 다 정리하게 되면 쓸것이 너무 많아지는것 같다 1주차는 요약본만 정리하고 2주차부터 상세하게 쓰도록 해야겠다.

한성대학교 네이버 AI Tech 5기 NLP