Will Affective Computing Emerge from Foundation Models and General AI? A First Evaluation on ChatGPT
KAIST Intern
1. Summary
1-1. 연구 목적
이 연구의 목적은 ChatGPT의 감정 문제에서의 성능을 평가하여, 큰 데이터 기반의 기초 모델인 (foundation model as ChatGPT)이 특정 작업을 위한 별도의 훈련 없이도 다양한 NLP 작업에서 전반적으로 우수한 성능을 보일 수 있는지 확인한다.
1-2. 연구 내용
본 연구에서는 총 3가지의 데이터 셋으로 OCEAN 성격 예측, 트위터 기반 긍정,부정 감정 분석, 자살 경향 탐지의 데이터셋으로 구성되어있다.
이를 위해 RoBERTa, Word2Vec, BoW의 모델을 사용하며 ChatGPT의 예측 수준이 어느정도인지 수집 및 결과를 비교한다.
각 모델은 전문가 모델 : RoBERTa, 보통 모델 : Word2Vec, Bow로 구성된다.
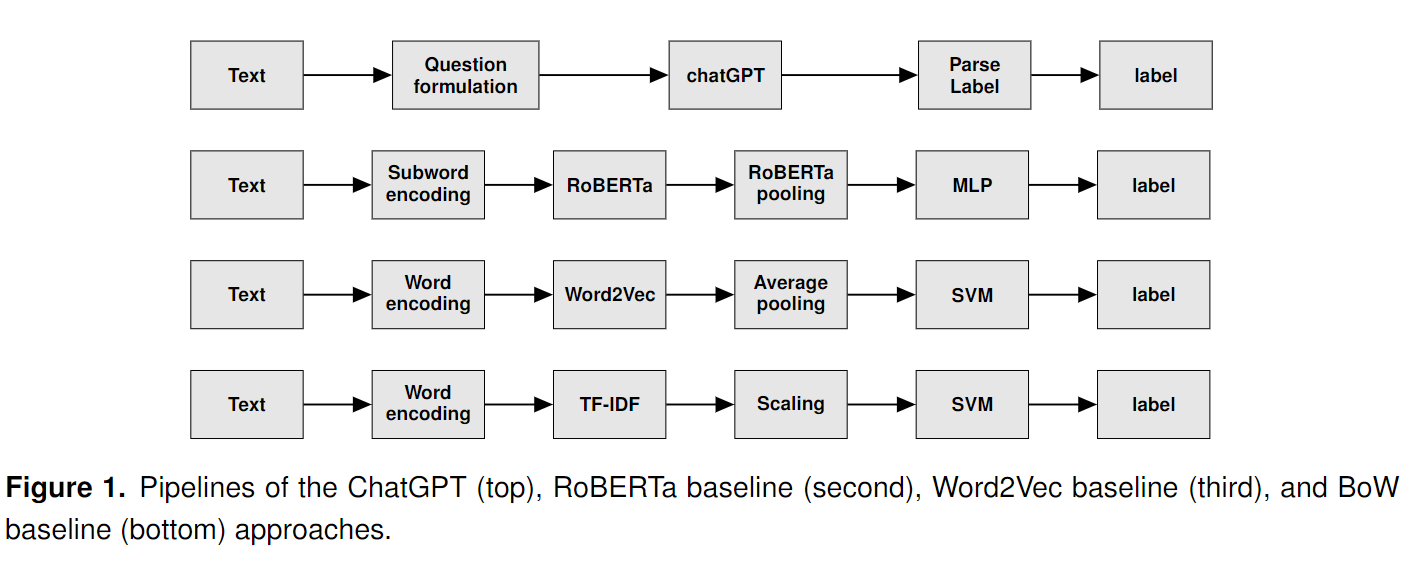
ChatGPT의 경우는 특정 프롬프트를 사용하며 아래와 같다. 이외의 모델의 예측 기법은 위와 같다.
특히 ChatGPT의 경우 주의 내용으로 프롬프트에 대한 확실한 질문과 대답의 경우 프롬프트를 지정하여도 정확하게 나오지 않고 예외(긍정,긍정)(긍정 긍정)(긍정 1 긍정 1)등 여러 형식이 있으므로 이를 잘 파싱해야한다.
1-3. 결과
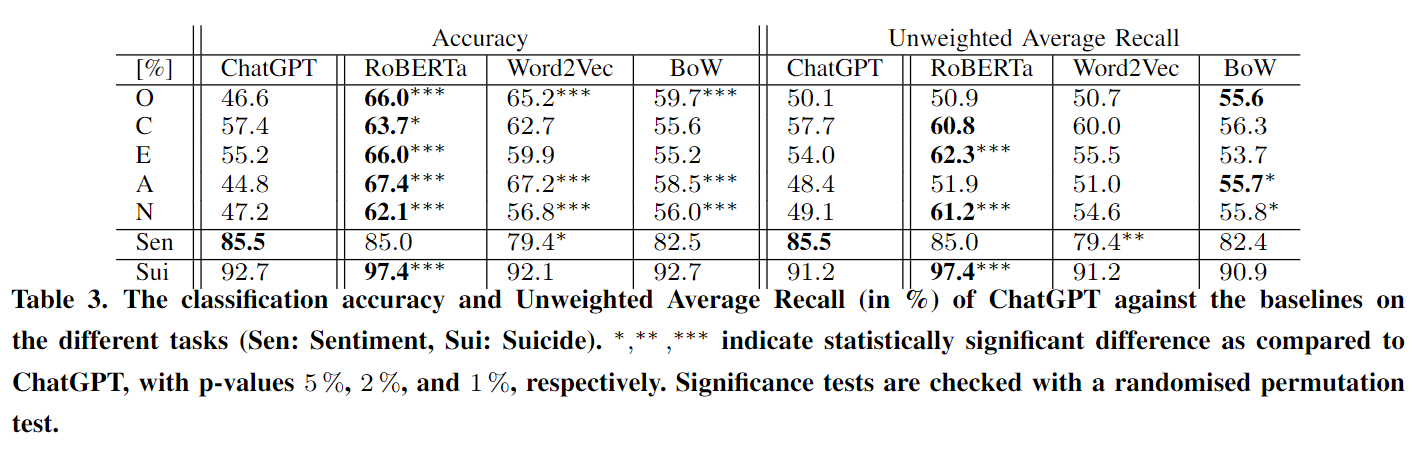
ChatGPT는 일반적인 모델로서 많은 작업에서 괜찮은 성능을 보였지만, 특정 작업에 특화된 모델에 비해 성능이 떨어졌다.
감정 분석에서는 RoBERTa와 유사한 성능을 보였지만, OCEAN과 자살 경향 탐지에서는 RoBERTa보다 성능이 낮았으며 특히, 데이터가 노이즈(트위터 긍정 부정 데이터)가 많은 경우 Word2Vec보다 더 나은 성능을 보였지만, 전체적으로는 BoW 모델과 유사한 수준의 성능을 보였다.
2. Conculsion
ChatGPT의 경우 다양한 문제에서 일반적인 성능을 보이는 모델이라는 점을 확인 시켜주었다. 하지만 최고의 성능의 경우는 역시 전문가 모델이 필요하며 이는 여전히 특정 작업에 대해서는 특화된 훈련 모델이 필요함을 시사한다. 하지만 추후 GPT의 성능도 향상됨에 따라 과연 전문가 모델과 크게 차이가 안날경우 전문화된 지식 데이터베이스를 모으는 것이 오히려 손해라는 것임 또한 시사한다.
