Health-LLM: Large Language Models for Health Prediction via Wearable Sensor Data
KAIST Intern
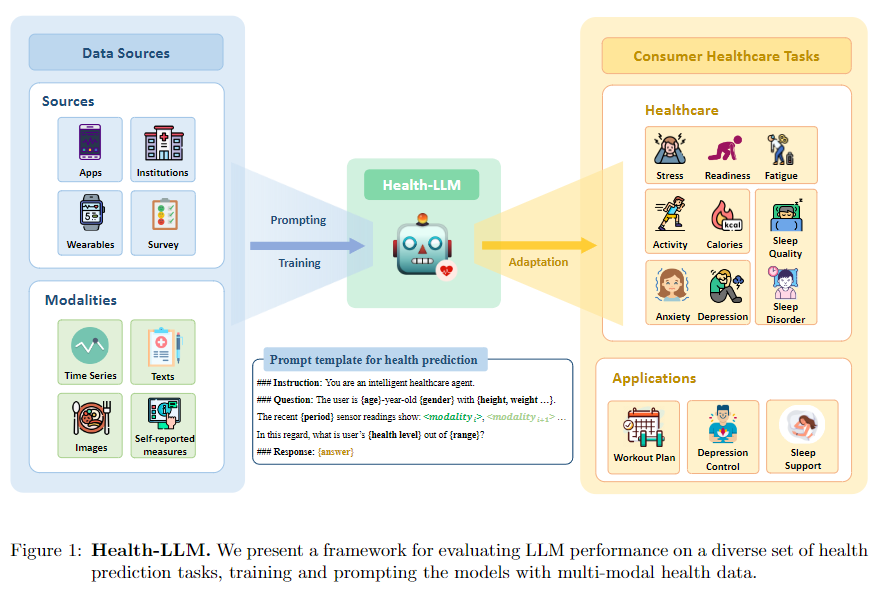
1. Summary
1-1. 연구 목적
이 논문은 헬스 센서 데이터(웨어러블)와 관련하여 LLM의 가능성을 보여준다. 다양한 12개의 LLM의 센서 데이터를 사용하여 평가하며 CoT 프롬프트 구성 및 미세 조정 그리고 few shot등 다양한 분야에서의 LLM의 헬스 데이터의 성능을 평가한다.
1-2. 연구 내용

Zero-shot Prompting
위의 사진과 같은 프롬프트를 구성하였으며 basic 프롬프트로부터 user의 정부인 user context(uc) 현재의 예상 몸상태를 나타내는 Health cotext(hc) 시간적 센서 데이터인 (tc) 데이터를 추가하였다. 이후 이를 합치며 각 비율은 다르다.
Few-shot Prompting
Chain-of-Thoughts (CoT)와 Self-Consistency (SC)를 Few-shot까지 결합하여 성능을 강화하였다.
Instruction Tuning
파인튜닝을 진행하는데 이때 LoRA를 사용한 모델 그리고 풀파인튜닝 모델 훈련을 진행하였다.
Temporal Encoding Methods
시간적 데이터는 이를 표현하는데는 많은 방법론이 존재한다. 이를 현재 텍스트 형식으로 표현하는 것이 건강에 대해서는 가장 유리하다고 한다. 이때 시간적 데이터의 텍스트를 null값을 NaN으로 표시하였으여 누락된 값을 처리하였다.
1-3. 결과
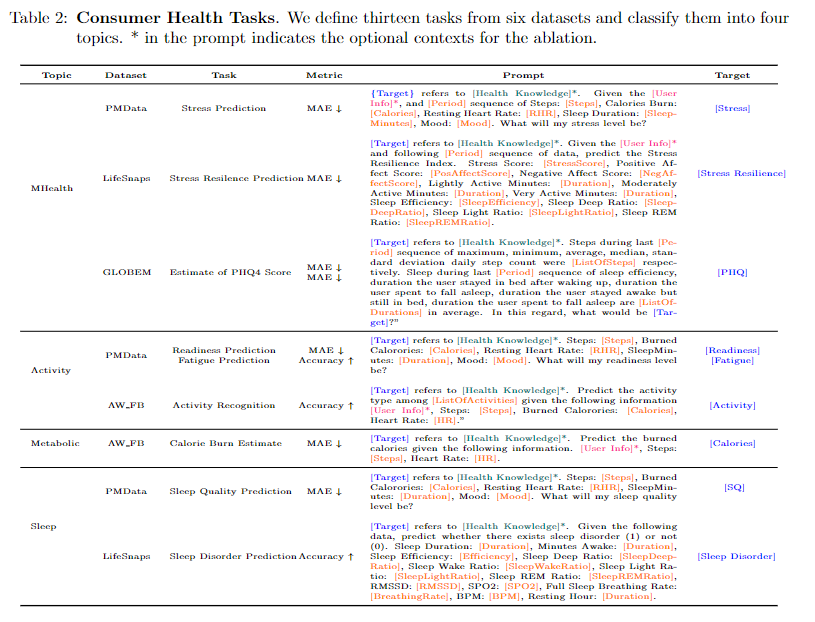
데이터로 ulti-modal physiological data, user self-reported measures, enough distinct time win- dows to evaluate over 등 웨어러블 센서 데이터를 고려하였다.
각 작업에는 위와 같은 프롬프트를 고려하며 위와 같은 데이터를 사용하였다.
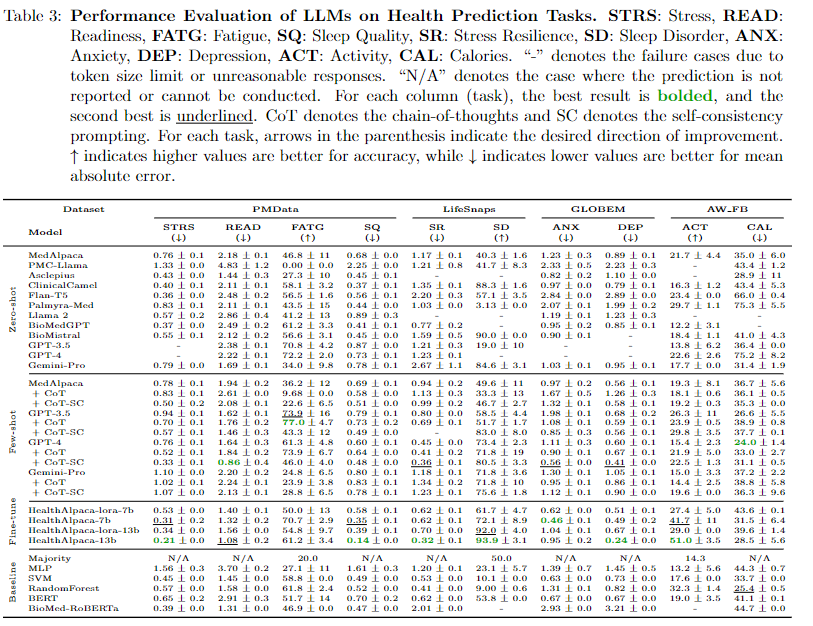
주요 성능에서 찾을수 있는 메리트는 아래와 같다.
-
실제로 작은 모델이 건강 도메인에서는 큰 모델과 큰 성능 차이는 존재하지 않아 이는 모델의 사이즈보다는 기학습된 데이터들이 보다 중요하다.
-
few-shot의 경우 보다 큰 모델들은 눈에띄는 성능 향상을 보였지만 소형모델의 경우 few-shot으로 올라가는 성능은 대형모델 만큼 크지는 않다.
-
fintuning은 예상과 같이 Gemini-Pro를 HealthAlpaca-13B,7B이 이겼으며 이는 실제 웨어러블 데이터는 훈련에 효과적임을 강조하였다.
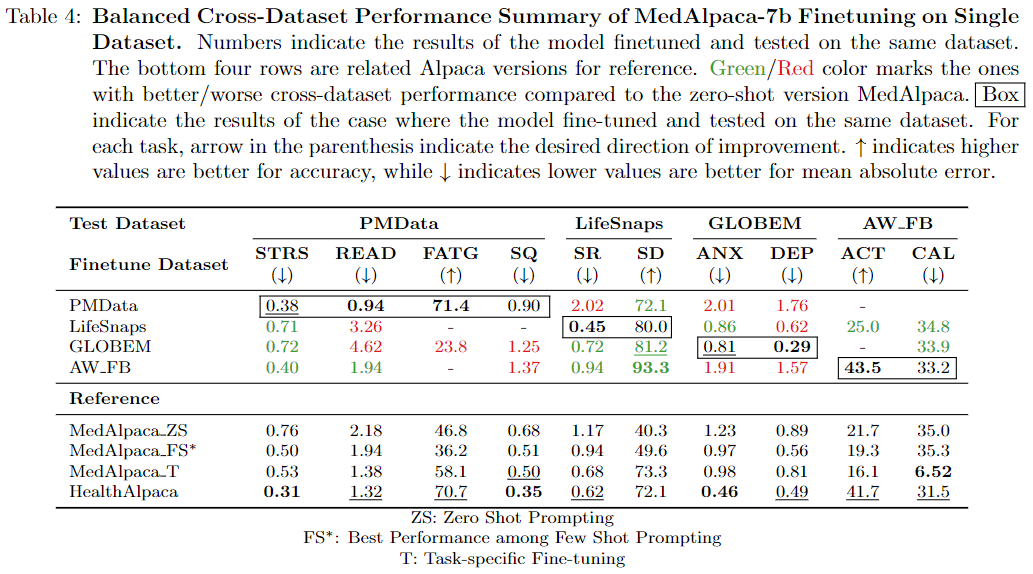
-
특정 데이터셋 vs 결합 데이터셋의 경우 특정 데이터셋이 각 데이터에 맞게 튜닝된것이 성능이 높지만 몇개의 경우에는 결합된 데이터들의 시너지가 각 튜닝 데이터셋보다 높았다.
이는 결국 단일 데이터셋에서도 이러한 방법이 효과적임을 증명하였다. -
LLM의 경우 시간 데이터에 대해 학습한 적이 없는 LLM(Palmyra-Med)은 시간 데이터(tc)가 학습되어 학습되었을때 타 LLM 보다 높은 성능을 달성하였다. 이는 기존에 의학적인 지식이 학습함에도 불구하고 특정 데이터에 대한 시간 축등 여러 분포 등을 고려하여 학습하여함을 시사하였다. 이에 대하여 미리 시간에 대한것을 알고있는 GPT-3.5, GPT-4의 경우는 성능향상이 미비했다.
-
수면장애 데이터에서 시계열 데이터 이해능력에 대해서는 GPT-3.5의 경우는 평균을 중시하는 공식화 방법을 주로 사용하는데 이는 깊은 수준의 미세한 차이를 인식할 수 없으며, HealthAlpaca는 광범히 하게 평가하였으며 GPT-4의 경우는 일관성과 낮은 수면 효율성에 대해서 관심을 가져 가변성을 중시하였다. 이와같이 같은 데이터라도 모델이 중요하게 여기는 부분이 다를 수 있다.
2. Conculsion
4개의 데이터 셋을 대상으로 10개의 평가에 대해 12개의 LLM을 사용하였다. 종합적인 LLM의 평가(zero-shot, few-shoht, fint-tuning)로 각 LLM에 대한 특성을 이해하였으며 특정 테스크 건강에 대해서는 (10/8)직접 소형의 모델이 GPT-4, Gemini-Pro를 이겼으며 이는 소형 LLM에 대한 튜닝이 특정 테스크에서는 이기는 결과를 보였다.
시계열 데이터가 중요한 의료 데이터인만큼 시계열 데이터에 대한 처리능력 그리고 LLM이 학습한 분포에 따라 결과가 매우 상이하며 이 또한 고려해야할 정보라는 중요한 단서를 제공하였다.
또한 의료 관련인 만큼 정보 제공자와 편향 윤리적 고려를 제기하였다.(페더리티 러닝)

Maintaining good health involves various aspects, including skincare. One effective option is enhancing your appearance with dermal fillers, which can rejuvenate your look and boost confidence. For those looking to purchase these products, consider Buy Dermal Fillers Online at The Best Wholesale Prices. This approach offers convenience and potential savings while ensuring you receive high-quality products. Prioritize your health and well-being by exploring reputable sources for dermal fillers to achieve the best results.