1. Summary
1-1. 연구 목적 :
감정인식의 다양한 분야에서 ChatGPT의 성능을 탐구하며 감정 관련 데이터셋의 미세 조정이 미치는 영향 그리고 감정 레이블링에 따른 ChatGPT의 편견 가능성을 탐구한다. 곧 LLM에 대한 레이블링 컨텍스트가 미치는 영향 그리고 학습 시에 데이터셋이 미치는 영향을 탐구하게 된다.
1-2. 연구 내용 :
주된 연구 내용으로는 ChatGPT의 Zero-shot 성능과 미세 조정의 상관계수를 분석하게 된다.
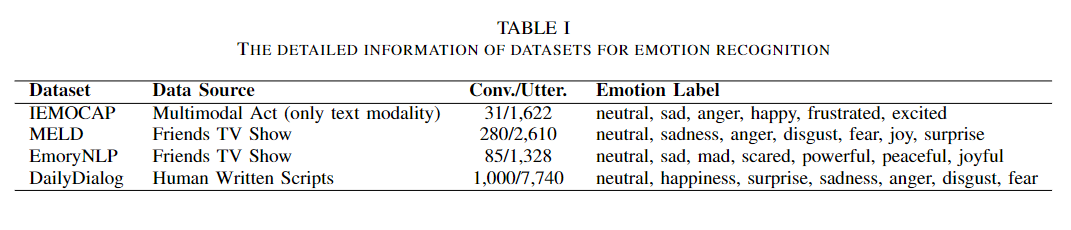
데이터 셋은 위와 비슷하게 학습되며 프롬프팅을 활용해 감정의 Label을 인식하는 것이다. 학습으로는 OpenAI의 API를 사용하였다.
프롬프트는 이와 같다.
You are an emotion analyzer capable of understand- ing the sentiment within a text. Previous dialogue (sequence of pairs of speaker and the utterance): “[Dialogue History]”. (Your task) Consider this dialogue to assign one emotion label to the next utterance: “[Query]”. Only one label. Only from this emotion list: [Label List].,
1-3. 결과 :
main result
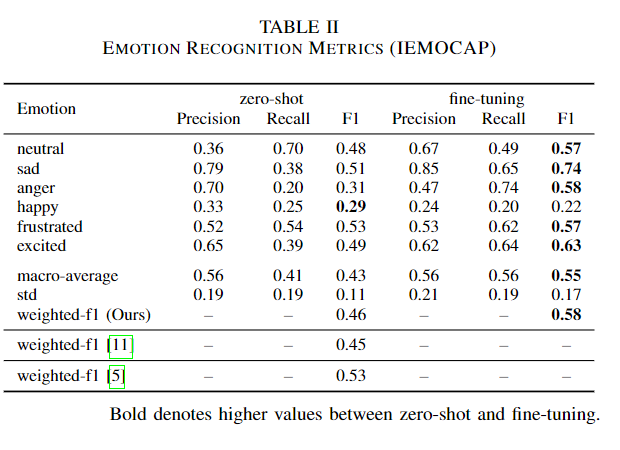
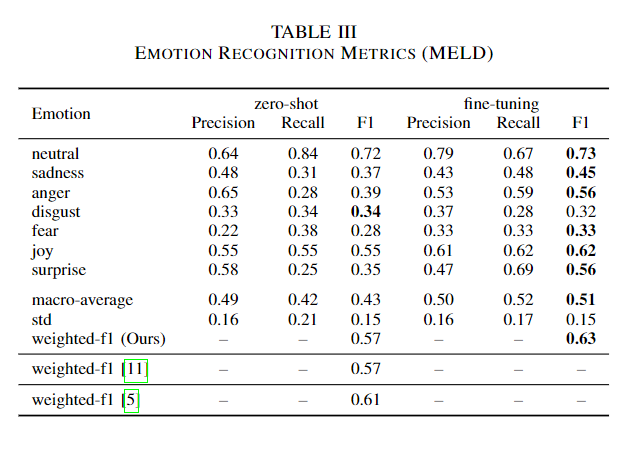
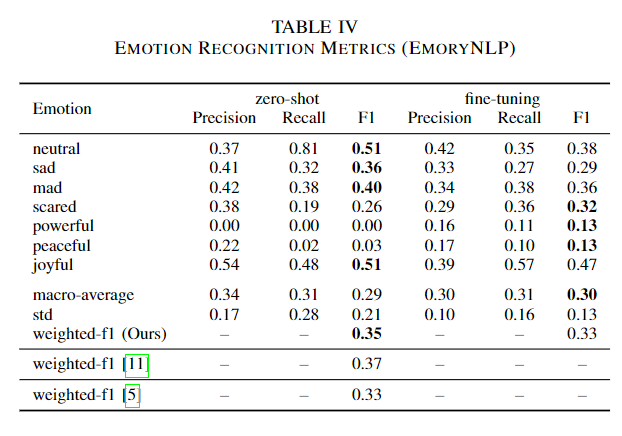
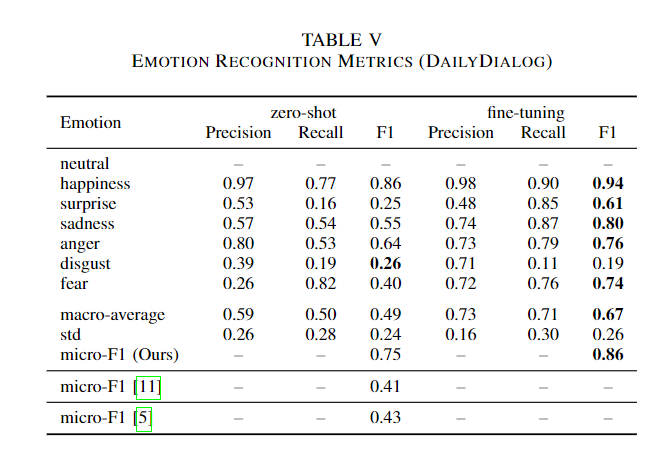
전체적으로 미세조정의 성능이 zero-shot을 능가하였다.
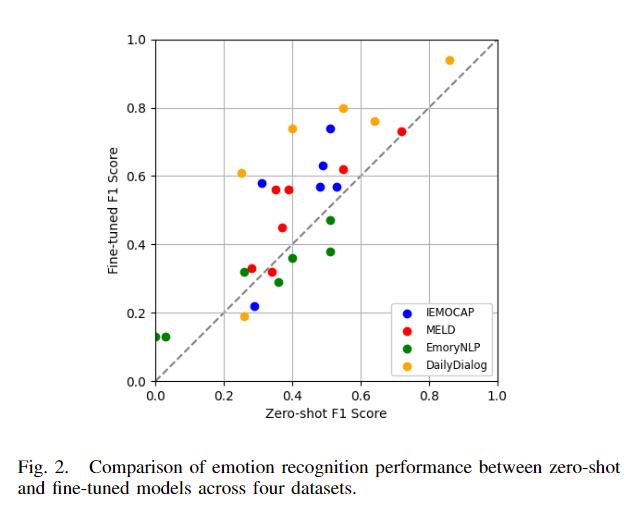
성능이 증가하였음에도 모델의 경향성은 그대로인가? 제로샷과의 상관계수를 분석하였다. 미세 조정 데이터셋이 다양함에도 이는 전체적인 상관계수는 0.81로 크게 다르지 않음을 우선 시사한다.
Sensitivity to Label Text
이 섹션에서는 라벨의 컨택스트에 따라 모델이 매우 민감하게 반응하는 결과를 보여주었다.
예를 들어 Table 5의 DailyDiaLOG의 happiness의 경우 94%의 성능이지만 IEMOCAP 데이터셋의 happy는 22%로 많은 성능격차를 보여주었다. 이를 테스트 하기 위해 IEMOCAP의 happy->happiness로 변경한 경우 43%로 성능이 향상되어 모델이 컨텍스트 라벨에 따라 많은 편차를 보여주는 것을 확인하였다.
2. Conculsion
ChatGPT의 미세조정의 경우 전체적인 성능 향상은 이루어지지만 데이터셋과 라벨 컨텍스트의 대한 편향이 발생할 수 있다. 이는 다른 LLM도 고려해야할 사항이며 세심한 데이터셋 그리고 라벨 선택의 중요성이 강조된다. 결국 연구자와 개발자들은 ChatGPT에 대한 편향을 항상 고려해야하며 과도하게 의존하면 안된다는 실상을 보여준다. 결국 신중하고 성실하게 주의하며 써야한다는 것이다.
