전처리 순서
1. 정보 확인
• info 함수로 각 라벨들의 자료형과 결측치 확인하자
data.info()• 범주형 칼럼 판별법
수치형 칼럼은 스케일링을 하기 때문에 범주형과 수치형 칼럼으로 나눔.
data.dtypes[0] == 'O'cat_columns = [c for (c, t) in zip(data.dtypes.index, data.dtypes) if t == 'O']
num_columns = [c for c in data.columns if c not in cat_columns]
이 방법이ㄹ 안맞을 때가 있는데 범주형 칼럼이지만 숫자로 이루어져 있는 경우에 그렇다.
따라서 데이터타입만 보고 범주형 칼럼인지 수치형 칼럼인지 바로 판단하기 보다는 데이터를 한번 진득하게 봐야한다.
ex) 건물 완공시기 : 202201, 202112, 202009
해석상으로는 범주형 칼럼이지만 형태 자체는 숫자형 칼럼이다.
ex2) 측정값 : 1,601
해석상으로는 수치형 칼럼이지만 중간에 쉼표가 있어 형태 자체는 범주형 칼럼이다.
x_test['측정값'] = x_test['측정값'].map(lambda x: x.replace(',', '') if isinstance(x, str) else x) # 쉼표를 공백으로 바꿈
x_test['측정값'] = x_test['측정값'].astype(np.float64) # 실수형으로 바꿈
tip : 예를 들어 건물 완공시기같은 경우 20220108, 20211224 같이 너무 세세하게 데이터가 나뉘어져 있으면 결과도 복잡해지고 추상성이 올라가므로 적당한 선에서 자르는 것이 좋다.
20220108 -> 202201, 20211224 -> 202112
일반적으로 년월일은 1년 단위 또는 10년 단위로 범주형 변수로 만들어 전처리한다.
2. 목표하는 라벨값 확인
• train data에는 있고 test data에는 없는 라벨이 목표값일 가능성 큼
for x in train_data.columns:
if x not in test_data.columns:
print(x)• 헷갈리면 대회측에 문의 가능
3. 쓸데없는 라벨 삭제
• train data와 test data에 둘 다 없거나 의미가 없는 칼럼이라고 판단 되면
삭제하는 것이 좋다.
• 범주가 너무 많은 칼럼도 삭제하는 것이 좋다.
ex) 주소, 지번, 아파트 이름
• 칼럼을 삭제하기 전에 불필요한 칼럼인지 해석을 먼저 해야한다.
data.drop(columns=['삭제할 칼럼명'], inplace=True)
4. 이상치 확인
• describe 함수를 사용하면 각 변수별 평균, 표준편차, 최대, 최소, 사분위수 등 기초 통계량을 확인할 수 있는데 이때 특이하게 값이 낮거나 높은 변수들을 확인하자.
data.describe()
5. 데이터 쪼개기
• train data로 훈련을 시키면 올바르게 훈련 했는지 검증이 필요한데 test data는 절대로 사용하면 안되는 data이다. 따라서 train data의 일부를 떼서 만든
valid data를 검증용 데이터로 사용한다.
• test data는 사용할 수 없는 미래의 데이터라고 생각하자.
• training set(과거) , testing set(미래) -> training set(과거), validation set(과거), testing set(미래)
• split함수 파라미터 :
test_size (float): Valid(test)의 크기의 비율을 지정
random_state (int): 데이터를 쪼갤 때 내부적으로 사용되는 난수 값 (해당 값을 지정하지 않으면 매번 달라진다.)
shuffle (bool): 데이터를 쪼갤 때 섞을지 유무
stratify (array): Stratify란, 쪼개기 이전의 클래스 비율을 쪼개고 나서도 유지하기 위해 설정해야하는 값. 클래스 라벨을 넣어주면 된다.
from sklearn.model_selection import train_test_split
x_train, x_valid, y_train, y_valid = train_test_split(data, label,
test_size=0.2, # train : valid의 비율이 8:2
random_state=20220220, # 난수값 지정 안하면 매번 달라짐
shuffle=True,)
x_train.reset_index(inplace=True, drop=True)
x_valid.reset_index(inplace=True, drop=True)
# train data, valid data 나누고 reset_index(drop=True, inplace=True)에서 drop=True를 하지 않으면 이전 인덱스가 새로운 변수로 생성되고 원래 인덱스 값들이 날라간다.
# drop=False: 인덱스에 날짜같은 시계열 데이터나 어떤 피쳐형태로 있는 경우 새로운 칼럼으로 올려야 하므로 False로 둔다
6. 결측치 처리(Imputation)
• 결측치를 확인하는 방법으로 Pandas의 isna() + sum() 메소드를
사용할 수 있다
pd.isna(train_data).sum() # 각 칼럼마다 결측치 개수 확인
pd.isna(train_data).sum().sum() # 모든 데이터 테이블의 결측치 개수 확인
• 데이터를 보면 값이 NaN이라고 나와있는 값들이 있는데 이러한 값을 결측치라 하며 가장 간단한 방법으로 평균이나 중간값 또는 최빈값 같은 변수의 대표값을
이용해 채울 수 있다.
Mean Imputation
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='mean') # 모델 생성
imputer.fit(train_data[num_columns]) # 평균으로 결측치 채우기
train_data[num_columns] = imputer.transform(train_data[num_columns]) # 업데이트
Median Imputation
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='median') # 모델 생성
imputer.fit(train_data[num_columns]) # 중간값으로 결측치 채우기
train_data[num_columns] = imputer.transform(train_data[num_columns]) # 업데이트
Iterative Imputation(MICE)
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
train_data_mean = IterativeImputer(random_state=0) # 모델 생성, MICE 결측치 채우기
train_data[num_columns] = train_data_mean.fit_transform(impute_df[num_columns]) # 업데이트
Mode Imputation
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='most_frequent') # 모델 생성
imputer.fit(train_data[cat_columns]) # 최빈값으로 결측치 채우기
train_data[cat_columns] = imputer.transform(train_data[cat_columns])최빈값 결측치 채우기는 주로 범주형 칼럼에서 사용된다.
7. 스케일링
• 변수의 크기가 너무 크거나 작으면 해당 변수가 타겟값에 미치는 영향력이 제대로 표현되지 않을 수 있다. 따라서 스케일링을 통해 변수의 크기를 적절히 조절하는 것이 필요하다. 스케일링에는 특정 변수의 최대 최소 값으로 크기를 조절하는 Min-Max 스케일링과 z-정규화를 이용한 Standard 스케일링이 있다.
★ 스케일링은 수치형 칼럼만 한다.
Min-Max 스케일링
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler() # 모델 불러오기
scaler.fit(numeric_data) # 데이터에서 특징 추출
scaled_data = scaler.transform(numeric_data)
scaled_data = pd.DataFrame(scaled_data, columns=num_columns) # 데이터 변환scaled_data는 이제 train data의 수치형 칼럼을 Min-Max 스케일링한 결과값이다.
Standard 스케일링
(1)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler() # 모델 불러오기
scaler.fit(numeric_data) # 데이터에서 특징 추출
scaled_data = sdscaler.transform(numeric_data)
scaled_data = pd.DataFrame(scaled_data, columns=num_columns) # 데이터 변환(2)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(x_train[num_columns]) # train으로만 fit을 한다.
x_train[num_columns] = scaler.transform(x_train[num_columns]) #train을 transform한다.
x_valid[num_columns] = scaler.transform(x_valid[num_columns]) #valid를 transform한다.
x_test[num_columns] = scaler.transform(x_test[num_columns]) #test를 transform한다.scaled_data는 이제 train data의 수치형 칼럼을 Standard 스케일링한 결과값이다.
만약에 스케일링을 먼저하고 결측치를 채우는 경우,
Standard 스케일링을 한 후 평균이 0 표준편차가 1로 되어있다고 하자.
이때 Mean으로 결측치를 채우면 모든 결측치에 0이 들어가기 때문에 문제가 생긴다. 그러니까 결측치를 먼저 채우고 스케일링 하자
8. 인코딩(Encoding)
• 범주형 변수를 수치형 변수로 나타내는 방법을 인코딩이라고 한다.
• 여기에서 범주형 변수란, 차의 등급을 나타내는 [소형, 중형, 대형] 처럼 표현되는 변수를 뜻한다.
• 범주형 변수는 주로 데이터 상에서 문자열로 표현되는 경우가 많으며, 문자와 숫자가 매핑되는 형태로 표현되기도 합니다.
Label Encoding
라벨 인코딩은 n개의 범주형 데이터를 0 ~ n-1개의 연속적인 수치로 나타내는 방법이다. 예를 들어 위의 등급 변수를 수치형 데이터로 표현하면
소형 : 0
중형 : 1
대형 : 2
이런 식으로 나타낼 수 있다. 이때, 범주형 데이터의 차이가 수치형 데이터의 차이와 관계가 없음에 주의해야 한다.
병원데이터의 병원의 개/폐업을 나타내는 변수인 "OC"를 수치형 데이터로 바꾸어 보겠다. "OC"는 변수의 범주가 "open" 또는 "close"다.
label = pd.DataFrame(data['OC'])from sklearn.preprocessing import LabelEncoder
le = LabelEncoder() # 모델 생성
le.fit(label) # 데이터 특징 찾기
label_encoded = le.transform(label) + 1 # 데이터 변환(범주형 변수 -> 수치형 변수)
One-hot Encoding
원핫 인코딩은 n개의 범주형 데이터를 n개의 비트 (0,1)로 표현한다.
소형, 중형, 대형으로 이루어진 범주형 데이터를 원핫 인코딩을 통해 변환하면 다음과 같이 변환된다.
소형 : [1, 0, 0]
중형 : [0, 1, 0]
대형 : [0, 0, 1]
원핫 인코딩으로 범주형 데이터를 변환하면, 서로 다른 범주형 데이터에 대해서 벡터 내적을 취했을 때 내적 값이 0이 나온다.
이는 서로 다른 범주 데이터는 아무런 관계가 없는 독립적인 관계라는 것을 의미한다.
(1)
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(sparse=False) # 모델 생성
ohe.fit(label) # 데이터 특징 찾기
one_hot_encoded = ohe.transform(label) # 데이터 변환(범주형 변수 -> 수치형 변수)(2)
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(sparse=False)
ohe.fit(x_train[cat_columns])
new_x_train_cat = pd.DataFrame(ohe.transform(x_train[cat_columns]))
new_x_valid_cat = pd.DataFrame(ohe.transform(x_valid[cat_columns]))
new_x_test_cat = pd.DataFrame(ohe.transform(x_test[cat_columns]))
x_train = pd.concat([x_train[num_columns], new_x_train_cat], axis=1)
x_valid = pd.concat([x_valid[num_columns], new_x_valid_cat], axis=1)
x_test = pd.concat([x_test[num_columns], new_x_test_cat], axis=1)
9. 선형회귀
• 선형 회귀는 종속 변수와 한개 이상의 독립 변수와의 선형 상관 관계를 모델링하는 회귀 분석 기법이다.
• 선형 회귀는 데이터가 분포되어 있는 공간에서 데이터를 가장 잘 표현하는 선을 하나 긋는다고 생각하자.
• 실제 참값 y(i) 와 회귀 모델이 출력한 y^ 사이의 잔차의 제곱의 합을 최소화하는 w(계수)를 구하는 것이 목적이다. -> Least Square, 최소 제곱법
Linear Regression
하나의 연속 변수를 예측하는 선형 회귀에는 "단순" 선형 회귀(Simple Linear Regression), "다중" 선형 회귀(Multiple Linear Regression)가 있다.
"단순" 선형 회귀는 입력 데이터의 변수가 1개인 경우이고, "다중" 선형 회귀는 입력 데이터의 변수가 2개 이상인 경우 이다. 일반적인 경우에는 여러 변수를 사용하는 "다중" 회귀 분석을 더 사용한다.
• Linear Regression 파라미터 :
fit_intercept (bool) : 회귀 수식에서 y 절편을 포함할지 유무
from sklearn.linear_model import LinearRegression
lr = LinearRegression() # 모델 생성
lr.fit(x_train, y_train) # 모델 학습
y_pred = lr.predict(x_valid) # 결과 예측하기(검증 데이터)
from sklearn.metrics import r2_score # 결과 확인하기
print('선형 회귀, R2 : {:.4f}'.format(r2_score(y_valid, y_pred))) # 일반적으로 R2의 값이 1에 가까울수록 회귀 모델이 데이터를 잘 표현했다고 한다.
print('다중 선형 회귀, 계수(w) : {}, 절편(b) : {:.4f}'.format(lr.coef_, lr.intercept_)) # 회귀 모델의 계수 W, 절편 b 보기
Lasso Linear Regression
선형 회귀 모델의 가중치 크기에 규제를 적용하는 라쏘 선형 회귀 모델을 알아보자.
라쏘 선형 회귀 모델과 기존 선형 회귀 모델의 차이점으로는 손실 함수에 L1 정규화 항(W)을 추가하는 것이다.
W는 선형 회귀 모델이 가지는 가중치 값으로, 학습을 통해 손실 함수를 최소화하면 각 가중치의 값도 작아지는 효과를 얻을 수 있다.
이는 선형 회귀 모델의 과적합을 방지하는 요소로써 사용되는데, 가중치의 값이 클 경우 모델의 복잡도가 높아져서 과적합되는 경향이 있기 때문이다.
라쏘 선형 회귀는 몇몇 가중치의 값을 0으로 만드는 특징이 있다.
• Lasso Linear Regression 파라미터 :
alpha (float) : L1 규제를 얼마나 많이 적용할지에 대한 수치
fit_intercept (bool) : 회귀 수식에서 y 절편을 포함할지 유무
random_state (int) : 내부적으로 사용되는 난수값
from sklearn.linear_model import Lasso
lasso_lr = Lasso(alpha=0.1) # alpha : 규제를 얼마나 할지에 대한 수치
lasso_lr.fit(x_train, y_train) # 모델 학습
y_pred = lasso_lr.predict(x_valid) # 결과 예측하기
print('라쏘 선형 회귀, R2 : {:.4f}'.format(r2_score(y_valid, y_pred))) # 결과 확인
print('라쏘 선형 회귀, 계수(w) : {}, 절편(b) : {:.4f}'.format(lasso_lr.coef_, lasso_lr.intercept_)) # 회귀 모델의 계수 W, 절편 b 보기
Ridge Linear Regression(L2)
선형 회귀 모델의 가중치 크기에 규제를 적용하는 릿지 선형 선형 회귀 모델을 알아보자. 릿지 선형 회귀 모델과 기존 선형 회귀 모델의 차이점으로는 손실 함수에 L2 정규화 항을 추가하는 것이다.
리소 선형 회귀 모델과 마찬가지로 W는 선형 회귀 모델이 가진 가중치 값으로, 학습을 통해 손실 함수를 최소화하면 각 가중치의 값도 작아지는 효과를 얻을 수 있다.
라쏘 선형 회귀와는 다르게 각 가중치의 값이 0이 아닌 0에 가까운 작은 수로 수렴한다.
• Lasso Linear Regression 파라미터 :
alpha (float) : L2 규제를 얼마나 많이 적용할지에 대한 수치
fit_intercept (bool) : 회귀 수식에서 y 절편을 포함할지 유무
random_state (int) : 내부적으로 사용되는 난수값
from sklearn.linear_model import Ridge
ridge_lr = Ridge(alpha=0.01) # alpha : 규제를 얼마나 할지에 대한 수치
ridge_lr.fit(x_train, y_train) # 모델 학습
y_pred = ridge_lr.predict(x_valid) # 결과 예측하기
print('릿지 선형 회귀, R2 : {:.4f}'.format(r2_score(y_valid, y_pred))) # 결과 확인
print('릿지 선형 회귀, 계수(w) : {}, 절편(b) : {:.4f}'.format(ridge_lr.coef_, ridge_lr.intercept_)) # 회귀 모델의 계수 W, 절편 b 보기
10. Machine Learning Algorithm Based Regression
• 회귀 모델 중 머신러닝 알고리즘을 기반으로한 회귀 모델도 있다.
• Sklearn이 지원하는 머신러닝 기반 회귀 모델로는 결정 트리, 랜덤 포레스트, 서포트 벡터 머신, MLP, AdaBoost, Gradient Boosting 등이 있다.
Multi Layer Perceptron Regressor
딥러닝의 기본 모델인 뉴럴 네트워크를 기반으로 한 회귀 모델이다.
기본적으로 MLP라 하면, 입력층-은닉층-출력층 3개로 이루어진 뉴럴 네트워크를 의미한다.
• Multi Layer Perceptron Regression 파라미터 :
hidden_layer_sizes (list) : 은닉층의 구성을 결정
activation (str) : 활성화 함수의 종류
alpha (float): L2 규제를 얼마나 많이 적용할지에 대한 수치
batch_size (int) : 미니 배치의 크기
learning_rate (str) : 훈련량의 형태 (상수형, 감소형, 적응형)
learning_rate_init (float): 훈련량, 학습 시 모델을 얼마나 업데이트할지 결정하는 값
solver (str) : 옵티마이저를 결정
random_state (int) : 내부적으로 사용되는 난수값
from sklearn.neural_network import MLPRegressor
mlp_regr = MLPRegressor(hidden_layer_sizes=(50,)) # 모델 생성
mlp_regr.fit(x_train[:100000], y_train[:100000]) # 모델 학습하기
y_pred = mlp_regr.predict(x_valid) # 결과 예측하기
print('단순 MLP 회귀, R2 : {:.4f}'.format(r2_score(y_valid, y_pred))) # 결과 확인
print('MLP, 계수 및 절편(w, b) : {}'.format(mlp_regr.coefs_)) # 회귀 모델의 계수 w, 절편 b 살펴보기
Support Vector Machine Regressor
서포트 벡터 머신의 기본 개념은 결정 경계와 가장 가까운 데이터 샘플의 거리(Margin)을 최대화 하는 방식으로 모델을 조정하는 것이다.
from sklearn.svm import SVR
svm_regr = SVR() # 모델 생성
svm_regr.fit(x_train[:20000], y_train[:20000]) # 모델 학습하기
y_pred = svm_regr.predict(x_valid) # 결과 예측하기
print('단순 서포트 벡터 머신 회귀, R2 : {:.4f}'.format(r2_score(y_valid, y_pred))) # 결과 살펴보기
Random Forest Regressor
트리 모델은 데이터의 불순도(impurity, Entropy)를 최소화 하는 방향으로
트리를 분기하여 모델을 생성하는데, 이러한 트리를 모아 숲을 만든 모델이
랜덤 포레스트다.
• RandomForest 파라미터 :
n_estimators (int) : 내부에서 생성할 결정 트리의 개수
crierion (str) : 분산 계산 시 사용할 수식("squared_error", "absolute_error", "poisson")
max_depth (int) : 생성할 트리의 높이
min_samples_split (int) : 분기를 수행하는 최소한의 데이터 수
max_leaf_nodes (int) : 리프 노드에서 가지고 있을 수 있는 최대 데이터 수
random_state (int) : 내부적으로 사용되는 난수값
n_jobs (int) : 병렬처리에 사용할 CPU 수
import multiprocessing
multiprocessing.cpu_count() # cpu 개수 확인
from sklearn.ensemble import RandomForestRegressor
rf_regr = RandomForestRegressor(n_jobs=multiprocessing.cpu_count()) # 모델 생성
rf_regr.fit(x_train, y_train) # 모델 학습하기
y_pred = rf_regr.predict(x_valid) # 결과 예측하기
print('랜덤 포레스트 회귀, R2 : {:.4f}'.format(r2_score(y_valid, y_pred))) # 결과 살펴보기
XGBoost Regressor
XGBoost는 이름에서도 알 수 있듯 각 이터레이션에서 맞추지 못한 샘플에 대해 가중치를 부여하여 모델을 학습시키는 부스팅(Boosting) 계열의 트리 모델이다.
부스팅 알고리즘 자체도 강력하지만, XGBoost는 강력한 병렬 처리 성능과 자동 가지치기(Pruning) 알고리즘이 적용되어 기존 부스팅 알고리즘보다 과적합 방지에 이점이 있다.
• XGBoost 파라미터
n_estimators (int) : 내부에서 생성할 결정 트리의 개수
max_depth (int) : 생성할 결정 트리의 높이
learning_rate (float): 훈련량, 학습 시 모델을 얼마나 업데이트할지 결정하는 값
colsample_bytree (float): 열 샘플링에 사용하는 비율
subsample (float): 행 샘플링에 사용하는 비율
reg_alpha (float): L1 정규화 계수
reg_lambda (float): L2 정규화 계수
booster (str) : 부스팅 방법 (gblinear / gbtree / dart)
random_state (int) : 내부적으로 사용되는 난수값
n_jobs (int) : 병렬처리에 사용할 CPU 수
!pip install xgboost # 설치
from xgboost import XGBRegressor
xgb_reg = XGBRegressor(tree_method='gpu_hist') # 모델 생성
xgb_reg.fit(x_train, y_train) # 모델 학습
y_pred = xgb_reg.predict(x_valid) # 결과 예측하기
print('XGBoost 회귀, R2 : {:.4f}'.format(r2_score(y_valid, y_pred))) # 결과 살펴보기
LightGBM Regressor
XGBoost가 기존의 부스팅 트리 모델보다는 학습이 빠르다는 장점이 있지만, 여전히 속도가 느린 알고리즘이다. 그래서 나온 LightGBM은 XGBoost보다 가볍고 더 나은 학습 성능을 제공하고, 더 적은 메모리를 사용한다.
예측 성능 자체는 XGBoost와 비슷하지만 학습 속도 및 메모리 사용량에서 이점을 갖는다.
• LightGBM 파라미터 :
n_estimators (int) : 내부에서 생성할 결정 트리의 개수
max_depth (int) : 생성할 결정 트리의 높이
learning_rate (float): 훈련량, 학습 시 모델을 얼마나 업데이트할지 결정하는 값
colsample_bytree (float): 열 샘플링에 사용하는 비율
subsample (float): 행 샘플링에 사용하는 비율
reg_alpha (float): L1 정규화 계수
reg_lambda (float): L2 정규화 계수
boosting_type (str) : 부스팅 방법 (gbdt / rf / dart / goss)
random_state (int) : 내부적으로 사용되는 난수값
n_jobs (int) : 병렬처리에 사용할 CPU 수
!pip install lightgbm # 설치하기
from lightgbm import LGBMRegressor
lgb_regr = LGBMRegressor(tree_method='gpu_hist') # 모델 생성
lgb_regr.fit(x_train, y_train) # 모델 학습하기
y_pred = lgb_regr.predict(x_valid) # 결과 예측하기
print('LightGBM 회귀, R2 : {:.4f}'.format(r2_score(y_valid, y_pred))) # 결과 살펴보기
11. Evaluation
Accuracy
모든 데이터에 대해 클래스 라벨을 얼마나 잘 맞췄는지를 계산
Confusion Matrix
정확도로는 분류 모델의 평가가 충분하지 않을 수 있다.
예를 들어, 병이 있는 사람을 병이 없다고 판단하는 경우 Risk가 높기 때문에 모델의 목적에 맞게 분류 모델을 평가하여야 하는데, 이때 사용되는 것이 Confusion Matrix
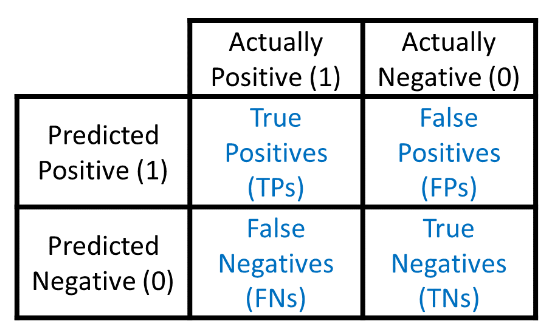
Precision(정확도) : TP/(FP+TP), 1이라고 예측한 것 중 실제로 1인 것
Recall(재현율) : TP/(TP+FN), 실제로 1인 것 중에 1이라고 예측한 것
질병 예측에서 가장 중요한 척도 중 하나, 예측을 잘못하면 사람이 죽을 수도 있기 때문
False Alarm(오탐) : FP/(FP+TN), 실제로 0인 것 중에 1이라고 예측한 것
코로나 검사에서 안걸렸는데 걸렸다고 하는 경우.
F1 Score(정밀도와 재현율의 조화 평균) : 클래스 불균형한 문제에서 주로 사용되는 평가지표
ROC Curve, AUC
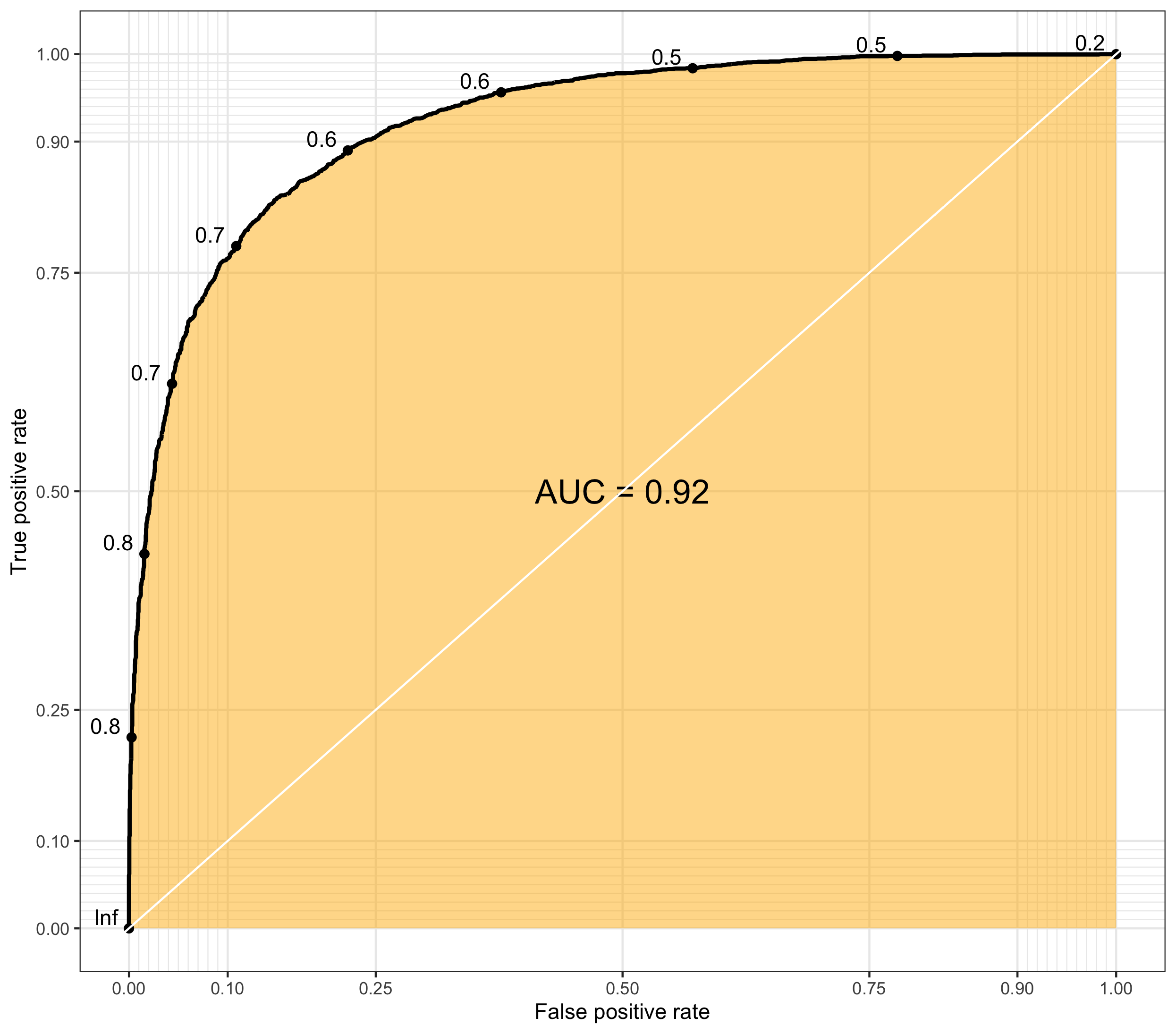
ROC Curve(Receiver-Operating Characteristic curve)는 민감도와 특이도가 서로 어떤 관계를 가지며 변하는지를 2차원 평면상에 표현한 것이다.
ROC Curve가 그려지는 곡선을 의미하고, AUC(Area Under Curve)는 ROC Curve의 면적을 의미하는데 AUC의 값이 1에 가까울 수록 좋은 모델을 의미한다.
from sklearn.metrics import accuracy_score, precision_score, recall_score, roc_auc_score, f1_score, log_loss # 모델 정의
print('Accuracy : {:.3f}'.format(accuracy_score(y_valid, y_pred)))
print('Precision : {:.3f}'.format(precision_score(y_valid, y_pred)))
print('Recall : {:.3f}'.format(recall_score(y_valid, y_pred)))
print('F1 Score: {:.3f}'.format(f1_score(y_valid, y_pred)))
print('AUC : {:.3f}'.format(roc_auc_score(y_valid, y_pred_proba[:, 1])))
print('Log Loss : {:.3f}'.format(log_loss(y_valid,y_pred_proba[:, 1])))