정규표현식(Regular Expression)의 필요성
- 정규표현식에 대한 필요성을 크게 느껴본 적이 없다. 많이 사용하지도 않았고 그만큼 익숙하지도 않았다. 그러나 이번에 웹 크롤링에 대해 공부를 하면서 필요성을 크게 느꼈다.
<li><span class="tit">이름</span>조상래</li>
<li><span class="tit">직업</span>학생</li>
<li><span class="tit">전화번호</span>010-1234-5252</li>위와 같이 태그가 중첩되어 나와 있는 경우가 있을 것이다. 이를 데이터베이스에 입력하기 위해 정리하는 과정에서 span 태그의 값, li 태그의 값을 가져와야 할 것인데 정규표현 식을 모르면 막막할 것이다. 그리고 태그의 형태는 고정되어 있지만, 값의 길이가 바뀌면 더욱더 복잡해질 것.
- Python (re 모듈 이용)
import re
temp = [
'<li><span class="tit">이름</span>조상래</li>',
'<li><span class="tit">직업</span>학생</li>',
'<li><span class="tit">전화번호</span>010-1234-5252</li>'
]
information = {}
for i in temp:
key = re.search('<span .*?>.*?</span>', i).group()
value = re.sub(key, '', i)
comp = re.compile('<.*?>')
information[re.sub(comp, '', key)] = re.sub(comp, '', value)
print(key)
print(value)
print(information)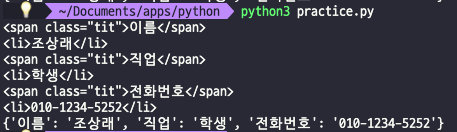
- JavaScript
const temp = ['<li><span class="tit">이름</span>조상래</li>', '<li><span class="tit">직업</span>학생</li>', '<li><span class="tit">전화번호</span>010-1234-5252</li>'];
const information = {}
for (let i = 0; i < temp.length; i += 1) {
key = temp[i].match(/<span.*?>.*?<\/span>/)[0];
value = temp[i].replace(key, '');
reg = /<.*?>/gi
information[key.replace(reg, '')] = value.replace(reg, '');
console.log(key)
console.log(value)
};
console.log(information)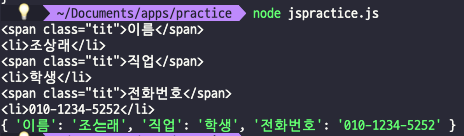
위와 같이 정규표현식은 다른 환경에서도 동일하게 작동한다. 하나의 약속이라고 생각하면 된다. 개발자라면 필수적으로 익히고 가야 할 스킬인 것 같다.
정규표현식
시작하기에 앞서 정규표현식을 테스트해 볼 수 있는 사이트를 추천한다.
(https://regexr.com)
상단에 표현식을 입력하고 하단에서 결과를 확인해 볼 수 있다. 그리고 자주 쓰는 패턴까지 저장할 수 있다.
1. 기본
- 기본적으로 문자 있는 그대로 입력하여 선택이 가능
- 띄어쓰기까지 구분
- 영어 대소문자 구분
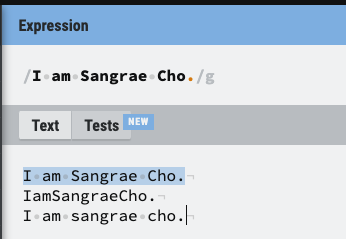
2. ^(캐럿), $
- 입력된 모든 소스(아래 사진을 기준으로 적힌 모든 문자는 하나의 소스) 내에서 찾는 것에 유의
- ^(캐럿): ^ 뒤에 나오는 문자로 시작되는 소스
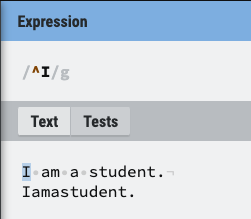
- $: $ 앞에 나오는 문자로 끝나는 소스
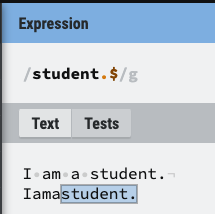
3. \(백슬래쉬) - 이스캐이핑
- ^, $ 처럼 특수한 기능을 가진 문자를 일반 문자로

4. .(포인트)
- 문자, 공백, 특수문자 등의 모든 텍스트
- .(포인트)의 개수로 여러단위 선택 가능
.png)
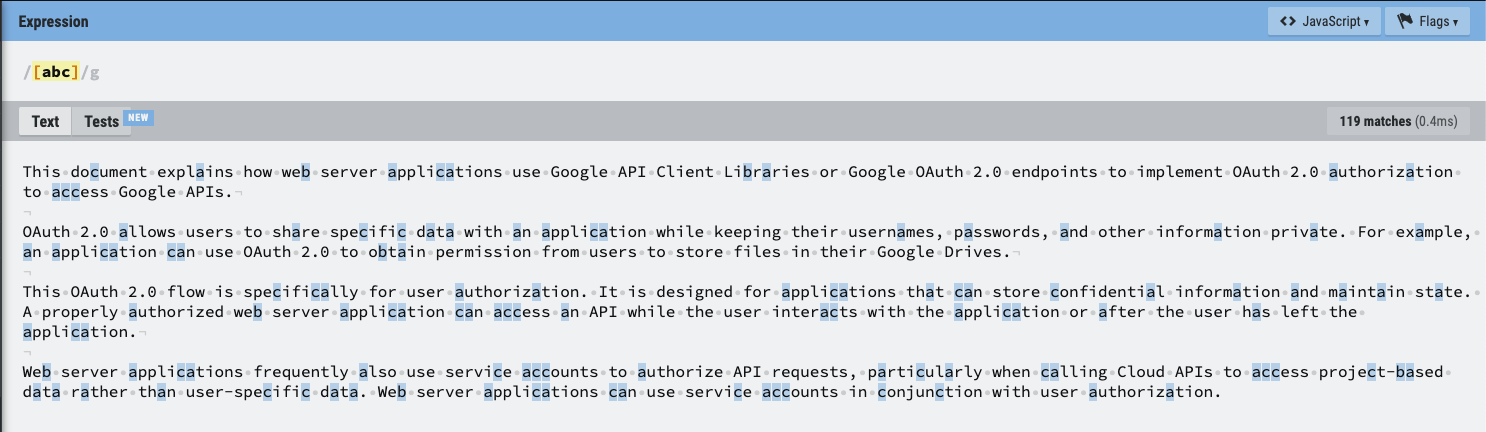
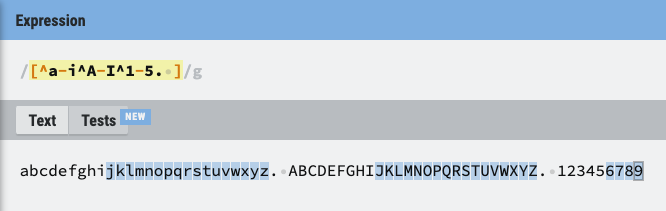
5. [] (Square Braket)
- [] 안에 들어가는 문자 단위 하나하나
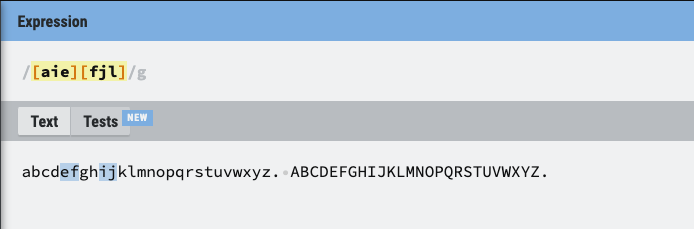
- [1-9] / [a-z] / [A-z] 와 같이 범위 설정이 가능

- [^x-z] 와 같이 ^(캐럿)을 붙여서 제외 가능
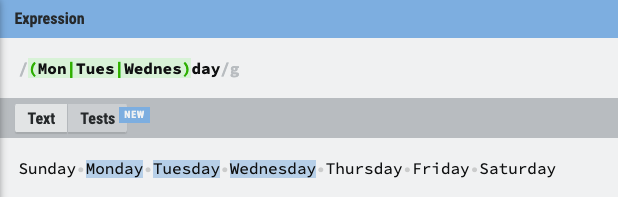
6. (문자|문자|문자)
- () 안에 들어간 문자를 선택 |(파이프라인)을 이용해 나눌 수 있다.
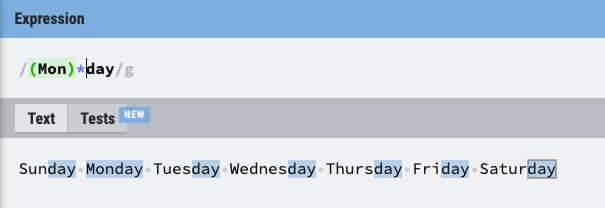
7. *, +, ? (수량자)
- *: * 앞에 입력된 문자가 있거나 없을 경우
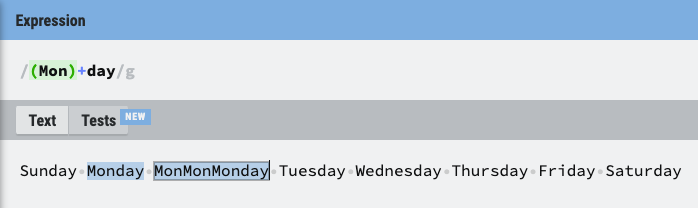
- +: +앞에 입력된 문자가 하나에서 여러개 (최소 하나)
- ?: ?앞에 입력된 문자가 없거나 하나인 경우 (최대 하나)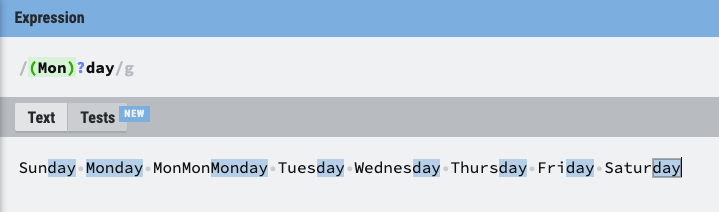
8. 수량자 심화
- 수량자에 ?를 붙여주어 수량자의 최소 숫자로 고정이 가능하다. (*? - 0개, +? - 1개)
.png)
- Greedy: 해당하는 모든 텍스트를 선택
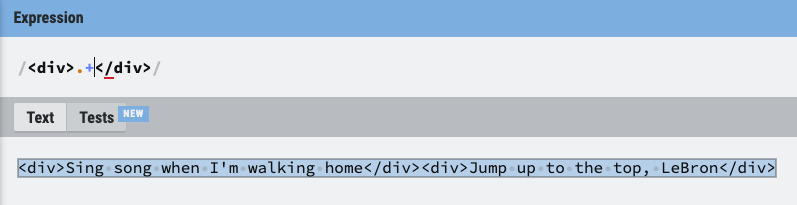
- Non-Greedy (Lazy): 해당하는 부분의 텍스트를 선택
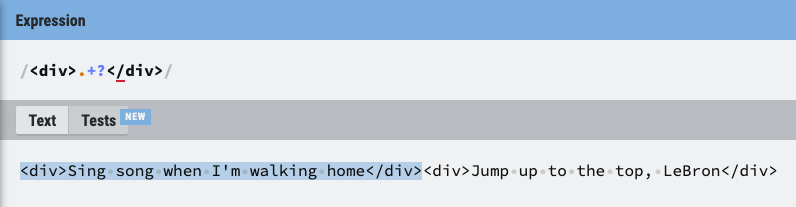
9. {}
- 숫자로 단위를 표현하여 선택
- {n, m} 앞에 입력된 문자가 n개 이상 m개 미만
- {n,} 뒤의 인자를 비워두면 n개 이상을 의미
.png)
10. \w, \W, \d, \D, \b(바운더리), \B
- \w: 모든 문자 [A-z0-9] 와 _(언더바) 까지 포함
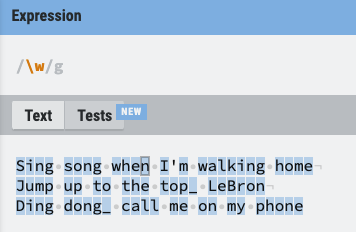
- \W: 대문자 W는 w와 정반대의 의미
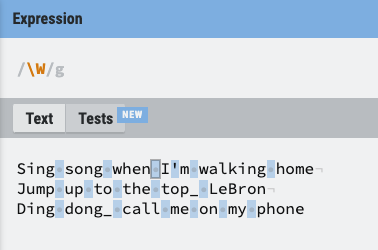
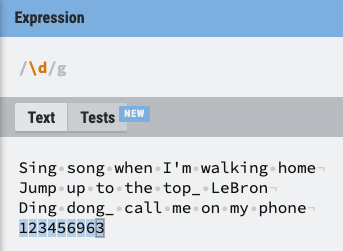
- \d: 숫자를 의미 (\D는 반대의 의미)
- \b(바운더리): 단어의 단위로 선택 (\B는 반대의 의미).png)
11. 전/후방 탐색
- (?=g)와 같이 사용하여 특정 문자 앞까지만 조회
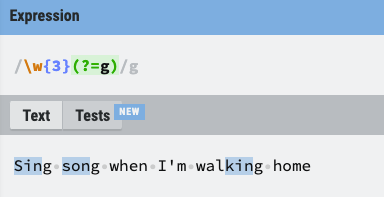
(모든 문자열 3개를 선택할 건데 g앞에 붙은 것만 조회)
