
인접 리스트 vs 인접 행렬
인접 리스트는 특정 노드에서 다른 노드로 이동하는 간선을 검색함에 있어 인접행렬에 비해 느리다는 단점이 있다. 반면에 인접 행렬을 사용하면 검색에서 이점을 가질 수 있지만 더 많은 메모리를 사용해야한다는 점을 고려해야한다. 하지만 무방향 그래프의 경우 서로 연결된 노드는 양방향성을 가지기 때문에 인접 행렬이 정대각선을 기준으로 대칭을 이루게 된다. 이 특징을 활용해서 정대각선 이상의 값만 저장하는 방식을 통해서 메모리 절약이 가능하다.
위상 정렬 (Topological Sorting)
방향성이 있는 그래프의 꼭짓점들(Vertex)을 변의 방향을 거스르지 않도록 나열하는 것을 의미한다.
위상 정렬이 가능하기 위한 조건 ( a.k.a DAG: Directed Acyclic Graph )
- 방향성이 있는 그래프
- 그래프에 순환(cycle)이 존재하지 않아야한다.
위상 정렬의 수행과정
- 자기 자신을 가리키는 변이 없는 꼭짓점을 찾음
- 찾은 꼭지점을 출력하고, 그 꼭짓점을 출발하는 변을 삭제
- 아직 그래프에 꼭짓점이 남아있으면 단계 1로, 없다면 종료한다.
진입 차수, 진출 차수
- 진입 차수: 꼭짓점으로 들어오는 간선의 개수
- 진출 차수: 꼭짓점에서 나가는 간선의 개수
위상 정렬의 특징
- 사이클이 없는 방향 그래프에 한해서 수행가능하다.
- 정렬 결과가 여러가지가 나올 수 있다. 한 단계에서 큐에 새롭게 들어가는 원소가 두개 이상이라면 여러가지 답이 나올 수 있다.
- 큐 또는 stack을 활용한 DFS를 통해서 구현가능하다.
Reference
https://m.blog.naver.com/ndb796/221236874984
Python 리스트 요소 한번에 출력하기
>>> arr = [ 1, 2, 3, 4 ]
>>> print(*arr)
1 2 3 4
>>> print(*rows, sep='\n')
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
[20, 21, 22, 23, 24, 25, 26, 27, 28, 29]
[30, 31, 32, 33, 34, 35, 36, 37, 38, 39]
[40, 41, 42, 43, 44, 45, 46, 47, 48, 49]
[50, 51, 52, 53, 54, 55, 56, 57, 58, 59]
[60, 61, 62, 63, 64, 65, 66, 67, 68, 69]
[70, 71, 72, 73, 74, 75, 76, 77, 78, 79]
[80, 81, 82, 83, 84, 85, 86, 87, 88, 89]
[90, 91, 92, 93, 94, 95, 96, 97, 98, 99]이진 트리
오른쪽, 왼쪽 자식만 갖는 트리를 이진 트리라고 한다. 이떄 자식의 수는 0, 1, 2 모두 가능하다.
그리고 왼쪽, 오른쪽 서브 트리는 다음과 같은 조건을 만족해야 한다.
- 왼쪽 서브트리 노드의 키값은 자신의 노드 키값보다 작아야한다.
- 오른쪽 서브트리 노드의 키값은 자신의 노드 키값보다 커야한다.
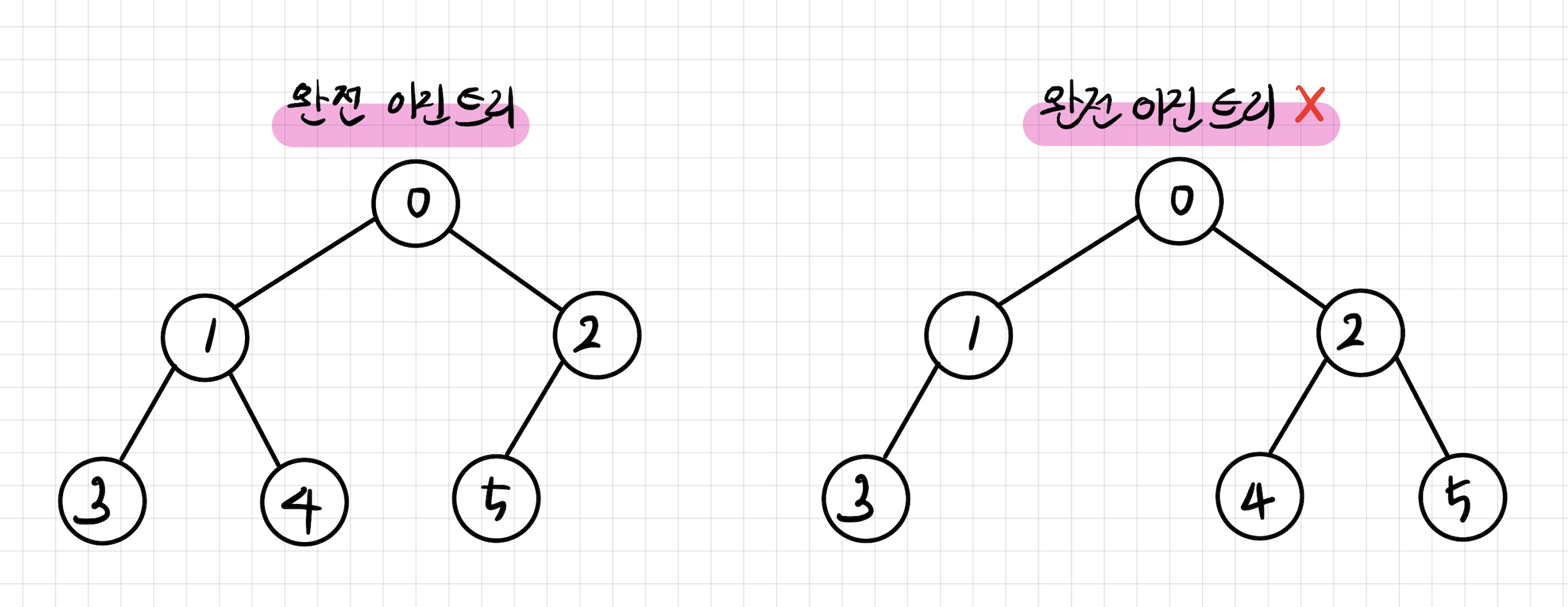
완전 이진 트리
루트부터 아래쪽 레벨로 노드가 가득 차 있고, 같은 레벨 안에서 왼쪽부터 오른쪽으로 채워져있는 트리를 완전 이진트리라고 한다.
B-Tree
데이터 베이스와 파일 시스템에서 사용되는 트리 자료구조의 일종. 이진 트리를 확장해서 하나의 노드가 가질 수 있는 자식 노드의 최대 숫자가 2보다 큰 구조를 말한다.
B-Tree는 self balanced tree 중 하나인데 이 balanced 상태를 유지하기 위한 몇가지 규칙이 존재한다.
- 노드안에 K개의 데이터가 있다면 자식 노드 수는 K + 1개가 있어야 한다.
- 노드 안에 데이터는 정렬되어야한다. (오름차순)
- 자식 노드의 데이터는 부모 노드의 데이터에 따라 배치된다.
검색
- 루트 노드에서 시작해서 key들을 순회하며 검사한다.
- k를 찾으면 검색을 종료한다.
- key와 검색 대상 값을 비교하여, 검색 대상이 key보다 작으면 왼쪽, 크면 오른쪽, 사잇값이라면 가운데 자식노드로 이동한다.
- key를 찾을 때 까지 반복하고, 만약 이동한 자식 노드의 값이 없다면 검색에 실패하게 된다.
삽입
검색 과정을 1차로 수행한 후, 노드를 삽입하고, balanced 한 상태가 될때까지 노드를 이동한다.
이때 검색 과정은 하향식이고, 삽입하는 과정에서 트리는 상향식으로 조작된다.
상향식으로 조작되는다는 말은 삽입되면서 최대 적재량을 초과했을때 Key가 이동하게 되면 아래로 내려가는 일이 없고 모두 위쪽 노드를 향해서 이동하게 된다는 뜻이다.
삭제
삭제할 키를 검색한 후, 해당 키를 삭제한다. 이때 트리의 불균형이 있는 경우 앞서 보았던 B-Tree의 규칙에 따라 균형을 조절해주어야한다.
- 삭제할 키가 리프에 있는 경우
- 삭제 후 노드의 개수가 유지되는 경우
- 키를 검색한 후 리프의 키를 삭제한다.
- 삭제 후 자식 노드의 개수가 k + 1개 이상이 되는 경우
- 최소 키의 개수를 초과하는 자식 노드에서 (왼쪽의 경우 큰값, 오른쪽 노드인 경우 작은 값) 값을 가져와 부모 키에 위치시킨다.
- 양쪽 형제 노드의 key가 최소 key의 개수이고, 부모 노드의 key 개수가 최소 개수 이상인 경우
- 부모 노드 키의 개수와 자식 노드의 수를 줄여 균형을 맞춘다.
- 형제, 부모, 자신의 키 개수가 최소 key 개수가 되는 경우
- 트리 높이가 줄어드는 경우로 전체 재구조화가 일어난다.
- 삭제 후 노드의 개수가 유지되는 경우
- 삭제하는 key가 내부 노드에 있고, 노드와 자식의 Key가 최소 key 개수 이상인 경우
- 노드 왼쪽의 가장 큰 값이나, 노드 오른쪽의 가장 작은 값과 교환한다.
- 교환 후에는 리프 노드가 삭제된 케이스와 동일하게 균형이 조정된다.
- 삭제하는 key가 내부 노드에 있고, 노드와 자식의 Key가 최소 key 개수 이하인 경우
- 전체적인 재구조화가 일어난다.
- 삭제할 키를 삭제한 후, 양쪽 자식 노드를 합친다.
- 삭제 키의 부모 키를 삭제 키의 형제 노드에 붙이고, 위에서 합친 노드를 자식 노드로 연결한다.
- 연결 시에 최대 key 수를 넘긴 노드가 발생하면 노드 분할을 통해 균형을 맞춘다.
Reference
https://velog.io/@emplam27/자료구조-그림으로-알아보는-B-Tree
https://code-lab1.tistory.com/217
다익스트라 알고리즘 (Dijkstra Algorithm)
다이나믹 프로그래밍의 방식중 하나로 최단 경로 탐색 알고리즘이다. 특정 정점에서 다른 모든 정점으로 가는 최단 경로를 알 수 있다. 이때 음의 간선에 대해서 고려하지 않아야 한다. 이러한 특징 때문에 현실 문제에서 많이 적용되고 있는 알고리즘이다.
다익스트라 알고리즘이 다이나믹 프로그래밍에 들어가는 이유는 최단 거리는 여러개의 최단 거리로 이루어져 있기 때문에 ‘큰 문제를 작은 문제로 나누어 해결하자’라는 다이나믹 프로그래밍의 형태를 띈다.
동작 과정
- 출발 노드와 도착 노드를 설정한다.
- 출발 노드와 연결된 노드 중 방문하지 않은 노드를 구분하고, 그 중 가장 짧은 노드를 선택하고 방문 처리한다.
- 해당 노드와 연결된 간선을 통해 최단 거리 테이블을 갱신한다.
도착 노드에 도달할 때 까지 1 ~ 3 과정을 반복하여 수행한다.
