- 동기화 도구
6.1. 배경
6.2. 임계구역 문제 (critical-section problem)
6.3. 피터슨의 솔루션 (peterson's solution)
6.4. 동기화를 위한 하드웨어 지원
6.5. 뮤텍스 락 (mutex lock)
6.6. 세마포어 (semaphore)
6.7. 모니터
6.8. 라이브니스 (liveness)
Chapter 6. Synchronization Tools
6.1. 배경
지금까지 협력 프로세스 (cooperating process). 즉 서로 영향을 주고받는 프로세스들의 관계에 대해 공부하였음.
이들은 주로 논리 주소 공간 (logical address space)을 공유하거나 (공유 메모리, message passing 등을 통해) 데이터를 공유함.
but, 서로 동시에 공유 데이터에 접근하게 되면 데이터 불일치 (data inconsistency)가 발생할 수 있으므로 이를 조심해야 함. 협력 프로세스들이 동시에 접근할 때 실행 순서를 명확히 해야 논리 주소 공간에서의 데이터 불일치 현상을 막을 수 있음.
여러 프로세스를 동시에, 혹은 병렬적으로 실행할 때 데이터의 무결성 (integrity of data)을 공유하면 아래와 같은 문제가 발생할 수 있음.
- 동시 실행
- 명령 스트림에 의해 어떠한 순간에라도 프로세스에는 인터럽트가 발생할 수 있고, 그때 문맥교환과 같은 작업이 수행됨.
- 이때 문맥교환에 의해 다른 프로세스가 실행될 때 공유 중인 같은 데이터에 접근하게 되면 데이터 충돌이 발생할 수 있음. - 병렬 실행
- 서로 다른 CPU에서 프로세스를 실행하는 것이므로 2개 이상의 명령 스트림을 가짐.
- 분리된 CPU 공간에서 실행할 때 여러 동기화 문제가 발생할 수 있음.
간단한 예로 생산자-소비자 문제 (producer-consumer problem)를 들 수 있음.
생산자-소비자 문제란?
: 두 프로세스, 즉 생산자 (producer)와 소비자 (consumer) 프로세스가 동시에 (concurrent) 실행될 때 두 프로세스 사이의 버퍼 (buffer)가 유한하기 때문에 발생할 수 있는 문제.
생산자 프로세스는 새로운 아이템을 버퍼에 넣고, 이때 버퍼 내부의 아이템 개수를 계산하는count변수의 값이 1 증가함. 반대로 소비자 프로세스는 버퍼 내부의 아이템을 읽어오고,count는 1 감소함.
만약 두 프로세스가 동시에 실행된다면?
- 버퍼가 비었는데 소비자 프로세스가 아이템을 읽으려고 할 때
- 버퍼가 꽉 찼는데 생산자 프로세스가 아이템을 넣으려고 할 때
문제가 발생하며 제대로 동작하지 않을 것임.
<생산자 코드> -
producer.cwhile (true) { while (count == BUFFER_SIZE) ; // 아무것도 실행하지 않음. buffer[in] = next_produced; in = (in + 1) % BUFFER_SIZE; count++; // count 1 증가 }<소비자 코드> -
consumer.cwhile (true) { while (count == 0) ; // 아무것도 실행하지 않음. next_consumed = buffer[out]; out = (out + 1) % BUFFER_SIZE; count--; // count 1 감소 }
#include <stdio.h>
#include <pthread.h>
int sum = 0;
void* run(void* param)
{
for (int i = 0; i < 10000; ++i)
{
sum++;
}
pthread_exit(0);
}
int main()
{
pthread_t tid1, tid2;
pthread_create(&tid1, NULL, run, NULL);
pthread_create(&tid2, NULL, run, NULL);
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
printf("%d\n", sum);
}위 코드의 예상 출력값은? 20000.
why? 스레드 tid1과 tid2가 생성되어 같은 전역변수인 sum을 공유하고 있으므로 값이 계속 누적되어 20000이 결과값으로 나오는 것이 이상적인 결과임.
but 실제로 코드를 실행해보면 다른 결과가 나올 것임. (심지어 실행할 때마다 다른 결과가 나옴)

문제는 count++;, count--; 구문에서 발생함.
count++;은 기계어 수준 (machine language level)에서 보면 3단계에 걸쳐 수행된다는 점을 기억하고 넘어가자.
register1 = count
register1 = register1 + 1
count = register1LOAD r1, #count
ADD r1, $1
STORE #count, r1다음과 같이 두 개의 프로세스, 혹은 스레드가 동시에 연산을 수행한다고 가정.
register1 = count
register1 = register1 + 1
count = register1register2 = count
register2 = register2 - 1
count = register2이때 문맥교환은 세 단계 중 어떤 단계에서도 발생할 수 있음. 첫 번째나 세 번째 단계에서 문맥교환이 이루어지면 연산을 수행하기 전이거나 수행한 이후이기 때문에 큰 문제는 없음.
그런데 만약 두 번째 단계, 즉 레지스터의 값을 1 증가시키는 부분에서 문맥교환이 벌어진다면? 원래 작업하고 있던 프로세스, 스레드는 준비 큐 (ready queue)에 저장되고 다른 프로세스나 스레드가 동일한 count 값에 대해 작업을 수행할 것. 이들이 연산을 끝내고 나면 count의 값이 새로 바뀐 레지스터의 값으로 변하게 되는데, 준비 큐에서 돌아온 스레드가 다시 연산을 수행하려고 하면 중간에 바뀐 count 값으로 연산을 수행해야 하므로 초기 예상과는 다른 결과가 나올 수 있음. (데이터 무결성이 깨지는 결과를 초래함)

이처럼 생산자와 소비자 사이에 임의적인 순서로 인터리빙 (interleaving)이 발생할 경우 사용자가 원하는 결과와 전혀 다른 결과가 매번 발생할 수 있으며, 이 때문에 데이터 불일치 문제가 발생할 수 있음.
인터리빙 (interleaving): '끼워넣기'. 어떤 명령의 흐름 속에 다른 명령, 혹은 프로세스가 섞여서 수행되는 현상
이러한 예시를 일반화한 상황이 경쟁 상태 (race condition).
-> 2개 이상의 프로세스 (혹은 스레드)에서 동일 (혹은 공유) 데이터에 동시에 접근해서 처리할 때, 실행의 결과는 어떤 순서에 따라 데이터에 접근하는지에 따라 달라짐.
경쟁 상태를 막기 위해서는 특정 시간에 한 프로세스만 공유 데이터를 사용하도록 해야 함.
이렇듯 경쟁 상태를 막기 위한 방법을 프로세스 동기화 (process synchronization)라고 부름.
6.2. 임계 영역 문제 (critical-section problem)
여러 프로세스가 하나의 시스템에서 동작할 때 각 프로세스는 코드 세그먼트를 가지는데, 이를 임계 영역 (critical section)이라고 부름.
프로세스가 데이터에 접근하고 업데이트하면 다른 프로세스는 이 데이터를 서로 공유하는데, 한 프로세스가 자신의 임계 영역에서 실행 중일 때 다른 프로세스는 그 임계 영역에서 실행하지 못하도록 하는 것이 임계 영역 문제 (critical-section problem)의 핵심 -> 그 결과 경쟁 상태가 발생하지 않음.
두 프로세스가 동시에 같은 임계 영역을 실행하지 못하게 되면 프로세스 동기화는 자연스레 이루어지고 데이터는 공동 공유 (cooperatively share)가 가능함.
이를 위해 코드를 4가지 영역으로 나눌 수 있음.
- 진입 영역 (entry-section): 임계 영역에 들어가는 코드 영역이며, 임계 영역에 들어가기 위해 허가를 받은 뒤 진입 가능
- 임계 영역 (critical-section): 진입 영역에서 허가를 받아 프로세스가 들어오면 실제 연산을 수행함 (앞선 예제에서의
count++;등) - 종료 영역 (exit-section): 임계 영역에서의 연산이 끝난 뒤 임계 영역 바깥으로 탈출하는 부분
- 나머지 영역 (remainder-section): non-critical section. 임계 영역과 독립적으로 연산을 수행하며, 이때의 연산은 임계 영역 내부 동작에 아무런 영향을 끼치지 않음.

임계 영역 문제를 해결하기 위해 보장되어야 하는 세 가지 조건
- 상호 배제 (mutual exclusion, mutex): 한 프로세스가 임계 영역에서 실행 중일 때, 다른 프로세스는 해당 임계 영역에서 실행할 수 없음. -> 기본적으로 지켜야 하는 조건
- 진행 (progress): 상호 배제 조건 만족 시 발생할 수 있는 문제 중 하나인 데드락 (deadlock)을 해결하기 위한 방법.
여러 프로세스가 서로 작업이 끝나기만을 기다리고 있어 어떤 프로세스도 임계 영역에 들어가지 못하는 상태를 데드락이라고 함. - 한정 대기 (bounded waiting): 상호 배제 조건 만족 시 발생할 수 있는 기아 (starvation)를 해결하기 위한 방법.
여러 프로세스가 임계 영역에 들어갔다 나오기를 반복하다 보면 우선순위가 낮은 프로세스는 무한 대기하고 있는 상황이 발생하는데, 이를 기아라고 함.
기아를 해결하기 위해 대기 시간에 제한을 걸어 무한 대기하는 상황을 피해야 함.
-> 위 세 가지 조건을 모두 만족해야 임계 영역 문제를 해결했다고 할 수 있음. (but 매우 어려움 -> 실제로는 잘 쓰지 않음. 한 번에 잡기보다는 발생하면 회피하는 정도)
싱글코어 환경에서 임계 영역 문제를 해결하는 방법 -> 인터럽트 발생을 막는다!
한 프로세스가 임계 영역에서 실행되는 동안 다른 프로세스가 접근할 수 없도록 인터럽트 발생을 막아버리는 것.
이를 위해서는 다른 프로세스가 임계 영역을 선점 (preemption)할 수 없도록 실행 순서를 명확하게 해야 함.
그 결과 공유 데이터가 마음대로 수정되어 꼬이는 현상은 막을 수 있지만, 멀티프로세서 환경에서는 제대로 동작하지 않을 확률이 크다는 단점이 있음. (모든 프로세스의 인터럽트 발생을 다 막아야 하므로 성능이 떨어짐)
보다 일반적인 두 가지 접근법 -> 선점형 & 비선점형 커널 (preemptive kernel & non-preemptive kernel)
- 비선점형 커널: 커널 모드에 진입한 뒤 스스로 종료할 때까지 외부 접근이 금지되도록 설계되었으므로 당연히 경쟁 상태가 발생하지 않음.
but 성능이 느리다는 이슈로 현대 OS에서는 잘 사용하지 않는 커널 구조. - 선점형 커널: 프로세스가 커널 모드에 진입하여 실행되는 중간에 선점되어 문맥교환이 일어날 수 있으므로 경쟁 상태가 발생하는 위험이 존재하여 설계가 까다롭지만 응답성이 좋고 성능이 좋기 때문에 현대 OS에서 많이 사용하는 구조. (장점 >>> 단점이니까 단점을 보완해서 사용하는 것)
6.3. 피터슨의 솔루션 (peterson's solution)
임계 영역 문제를 해결하기 위한 소프트웨어 측면의 해결법
- Dekker의 알고리즘: 2개의 프로세스가 공유 자원을 문제 없이 사용할 수 있도록 고안하였음.
- Eisenberg & McGuire의 알고리즘: n개의 프로세스를 사용하여 n - 1 이하의 대기 시간을 보장하는 알고리즘
- Peterson의 알고리즘
- 임계 구역 문제를 가장 완전하게 해결한 알고리즘
- butload&store와 같은 기계어 명령이 현대 컴퓨터에서 동작하는 방법 때문에 항상 제대로 동작하리라는 보장은 없음.
피터슨의 알고리즘
기본 개념
기본적으로 2개의 프로세스를 이용하며, 필요한 경우 확장할 수 있음.
int turn; boolean flag[2];두 프로세스에 각각 플래그 (깃발)를 세워 프로세스가 실행 중임을 나타냄. (각 플래그가
true인 경우 실행 중인 것)
turn변수는 다음에 실행할 프로세스를 가리킴.
한 프로세스의 플래그가true이면 다른 프로세스가 실행되지 못하도록 제한하여 두 프로세스가 동시에 데이터에 접근하는 상황을 막음.
while (true)
{
flag[i] = true;
turn = j;
while (flag[j] && turn == j) // entry section
;
/* critical section */
flag[i] = false; // exit section
/* remainder section */
}i, j라는 두 개의 프로세스가 있다고 가정함.
처음에 i 프로세스는 임계 영역 진입을 위해 우선 플래그를 true로 만들고 다음 턴을 j에게 넘김. (i 프로세스의 실행이 끝나면 자연스레 j 프로세스가 실행을 대기할 것)
이후 entry section에서 프로세스 실행이 가능한 상태가 될 때까지 대기함. (j 프로세스의 플래그가 false이거나 현재 턴이 i 프로세스인 경우 while문 탈출 가능)
임계 영역에 진입하여 프로세스를 실행하다가 작업이 끝나면 자신 프로세스의 플래그를 false로 만들어놓은 뒤 임계 영역을 빠져나감.
이 과정이 끝난 후 턴은 j 프로세스에게 넘어가며, j 프로세스 역시 같은 과정을 거쳐 작업을 수행하게 됨.
<간단 구현>
#include <stdio.h>
#include <pthread.h>
#define true 1
#define false 0
int sum = 0;
int turn;
int flag[2];
int main()
{
pthread_t tid1, tid2;
pthread_create(&tid1, NULL, producer, NULL);
pthread_create(&tid2, NULL, consumer, NULL);
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
printf("sum = %d\n", sum);
}(생산자 코드)
void* producer(void* param)
{
for (int k = 0; k < 10000; ++k)
{
/* entry section */
flag[0] = true;
turn = 1;
while (flag[1] && turn == 1)
;
/* critical section */
sum++;
/* exit section */
flag[0] = false;
/* remainder section */
}
pthread_exit(0);
}(소비자 코드)
void* consumer(void* param)
{
for (int k = 0; k < 10000; ++k)
{
/* entry section */
flag[1] = true;
turn = 0;
while (flag[0] && turn == 0)
;
/* critical section */
sum--;
/* exit section */
flag[1] = false;
/* remainder section */
}
pthread_exit(0);
}producer & consumer 2개의 스레드를 생성하고, 내부 구현을 피터슨 알고리즘으로 구현함.
그 결과 sum이라는 버퍼에 동시에 접근하여 값을 수정하는 상황이 발생하지 않음.
코드를 실행해보면 여전히 기대값 (0)이 아닌 다른 값들이 종종 나옴. (다른 값이 나오는 경우도 적고 차이 폭도 크기 않은 걸 보면 어느 정도 동기화는 된 듯함) -> 왜 그럴까?
앞서 말했듯 피터슨 솔루션은 기계어 명령의 생성 방식에 따라 제대로 동작하지 않을 수 있음. (주로 플래그를 설정하고 실행을 대기하는 entry section에서 문맥교환이 이루어짐) 이 때문에 이전보다 동기화에 실패하는 경우는 많이 줄어들었지만 완벽하게 없앨 수는 없음.
그럼에도 불구하고 피터슨 솔루션을 공부하는 이유는 개념적으로 좋은 알고리즘이기 때문임. 또한 상호 배제, 진행, 한정 대기라는 세 조건을 명확히 증명할 수 있기 때문임.
i프로세스는 오직j프로세스의 플래그가false이거나 현재 턴이i인 경우에만 임계 영역에 들어갈 수 있으므로 두 프로세스가 동시에 임계 영역에 진입하는 경우는 존재할 수 없음. 따라서 상호 배제가 보장됨.- 그 외에도 데드락 및 기아 방지, 즉 진행 & 한정 대기에 대한 증명도 가능함.
6.4. 동기화를 위한 하드웨어 지원
앞서 보았듯 소프트웨어 측면으로만 임계 영역 문제를 해결하기에는 기계어 수준에서의 예상치 못한 문맥교환 발생 등으로 어려움이 있음. 따라서 더욱 완벽한 문제 해결을 위해 하드웨어의 지원이 필요함.
하드웨어 기반 해결 방법
임계 영역 문제 해결을 위해 하드웨어 명령 (hardware instruction)을 활용할 수 있는데, 이를 통해 직접적으로 동기화를 수행할 수도, 문제 해결을 위한 간접적인 도구로 이용할 수도 있음.
3가지 처리 기법
- 메모리 배리어 (memory barrier) 혹은 메모리 펜스 (memory fence)
- 하드웨어 명령 자체를 이용하는 방법
- 원자적 변수 (atomic variable)
원자성 (atomicity)
더 이상 쪼갤 수 없는, 즉 인터럽트가 발생할 수 없는 동작을 원자적 동작 (atomic operation)이라고 함. (CPU에서 한 클럭 당 실행하는 단위 동작)
따라서 한 클럭에 해결할 수 있는 기능을 만들기 위해 하드웨어 측면에서 특수 명령으로 만들 수 있음 (회로 조작 등으로)
ex1. 위에서 봤던 a++ 동작을 LOAD, ADD, STORE의 3 클럭으로 나누는 대신 한 클럭만에 수행할 수 있도록 만듦. (test and modify)
ex2. 두 개의 변수를 swap하는 동작 (temp = i, i = j, j = temp)을 한 번의 동작으로 수행할 수 있도록 만듦. (test and swap)
-> 운영체제에서는 원자적 명령을 구현하여 test_and_set(), compare_and_swap()의 형태로 제공함. 해당 명령 수행 중에는 절대로 문맥교환이 일어나지 않음.
원자적 변수 (atomic variable)
compare_and_swap()이라는 하드웨어 명령을 사용하여 원자적 변수를 구현할 수 있음.
원자적 변수의 사용을 통해 하나의 변수에서 발생하는 경쟁 상태를 막고 상호 배제를 보장할 수 있음. (count++, count--처럼 한 변수에 동시에 접근할 때)
자바로 구현한 피터슨 솔루션
public class Peterson1
{
static int count = 0;
static int turn = 0;
static bollean[] flag = new bollean[2];
static class Producer implements Runnable
{
@Override
public void run()
{
for (int k = 0; k < 10000; k++)
{
/* entry section */
flag[0] = true;
turn = 1;
while (flag[1] && turn == 1)
;
/* critical section */
count++;
/* exit section */
flag[0] = false;
/* remainder section */
}
}
}
static class Consumer implements Runnable
{
@Override
public void run()
{
for (int k = 0; k < 10000; k++)
{
/* entry section */
flag[1] = true;
turn = 0;
while (flag[0] && turn == 0)
;
/* critical section */
count--;
/* exit section */
flag[1] = false;
/* remainder section */
}
}
}
public static void main(String[] args) throws Exception
{
Thread t1 = new Thread(new Producer());
Thread t2 = new Thread(new Consumer());
t1.start(); t2.start();
t1.join(); t2.join();
System.out.println(Peterson1.count);
}
}자바 사용 예제 - 원자적 변수 활용
이때 entry section에서 발생하는 문맥교환 및 경쟁 상태를 해결하기 위해 원자적 변수를 활용하여 코드를 재구성함. (자바에서는 atomic 라이브러리를 통해 원자적 변수를 제공함. (atomic.AtomicBoolean) C++의 경우에는 std::atomic)
import java.util.concurrent.atomic.AtomicBoolean;
public class Peterson2
{
static int count = 0;
static int turn = 0;
static AtomicBoolean[] flag; // 바뀐 부분
static
{
flag = new AtomicBoolean[2];
for (int i = 0; i < flag.length; i++)
flag[i] = new AtomicBoolean();
}
static class Producer implements Runnable
{
@Override
public void run()
{
for (int k = 0; k < 10000; k++)
{
/* entry section */
flag[0].set(true); // 값을 직접 대입하는 대신 메소드를 사용함.
turn = 1;
while (flag[1].get() && turn == 1)
;
/* critical section */
count++;
/* exit section */
flag[0].set(false);
/* remainder section */
}
}
}
static class Consumer implements Runnable
{
@Override
public void run()
{
for (int k = 0; k < 10000; k++)
{
/* entry section */
flag[1].set(true);
turn = 0;
while (flag[0].get() && turn == 0)
;
/* critical section */
count--;
/* exit section */
flag[1].set(false);
/* remainder section */
}
}
}
public static void main(String[] args) throws Exception
{
Thread t1 = new Thread(new Producer());
Thread t2 = new Thread(new Consumer());
t1.start(); t2.start();
t1.join(); t2.join();
System.out.println(Peterson1.count);
}
}변수가 원자적 변수로 사용되었기 때문에 entry section에서 문맥교환이 일어나지 않으므로 보다 정확한 해결이 가능함.
이렇듯 임계 영역 문제를 해결하기 위한 솔루션이 다양하게 있지만, 성능을 중요시하는 관점에서 너무 과한 솔루션이라는 의견이 존재함. 이 때문에 간단하게 상호 배제만 고려하는 솔루션이 등장하는데, 이러한 동기화 도구가 뮤텍스 락 (mutex lock), 세마포어 (semaphore), 모니터 (monitor)임.
6.5. 뮤텍스 락 (mutex lock)
임계 영역 문제를 해결하기 위한 고수준의 (high-level) 솔루션이 존재함.
- 뮤텍스 락: 가장 간단한 동기화 도구. 임계 영역에 진입할 때 lock을 걸어 다른 프로세스에서 접근하지 못하게 하고, 임계 영역에서 빠져나올 때 lock을 푸는 방식. (2개의 프로세스 대상)
- 세마포어: n개의 프로세스를 관리할 수 있기 때문에 보편적이고, 효율적인 방식. (6.6에서 자세히 다룰 예정)
- 모니터: 뮤텍스와 세마포어의 문제점을 극복한 방식. 자바에서는 wait notify와 같은 모니터 도구를 활용하여 동기화를 수행함. (6.7에서 자세히 다룸)
- 라이브니스: 뮤텍스뿐만 아니라 데드락 같은 문제까지도 고려한 방식. (6.8에서 자세히 다룸)
뮤텍스 락?
뮤텍스는 상호 배제 (mutual exclusion)를 뜻함.
뮤텍스 락은 간단하게 생각하면 임계 영역에 들어갈 때 열쇠 (lock)를 갖고 들어가며, 나올 때 열쇠를 반납한다고 생각하면 됨. (열쇠가 없으면 임계 영역에 들어갈 수 없음)
이때 락을 획득하는 과정을 acquire, 다시 락을 반납하는 과정을 release라고 부름.

이를 구현하기 위해서는 2개의 메소드 (acquire(), release())와 1개의 변수 (bool available)가 필요함.
acquire()
{
while (!available)
; // busy wait
available = false;
}
release()
{
available = true;
}acquire()와 release() 모두 원자적 (atomically)으로 구현되어야 한다는 점이 중요함. (그렇지 않으면 두 메소드 실행 중에 문맥교환이 일어나 원하는 결과가 나오지 않을수도 있음)
available 변수: 현재 락이 사용 가능한지 확인하기 위한 boolean형 변수. available이 true이면 현재 락을 사용하고 있는 프로세스가 없어 사용 가능하다는 뜻이고, false이면 현재 락을 사용하고 있는 프로세스가 있으므로 사용할 수 없다는 뜻임.
뮤텍스 락에는 바쁜 대기 (busy waiting)라는 문제점이 존재함.
바쁜 대기: 프로세스가 락을 얻기 위해
acquire()메소드를 수행할 때 무한 루프에서 대기하면서 CPU를 낭비하는 현상.
이 문제는 멀티프로그래밍 시스템에서 더욱 심각해짐. 준비 큐에서 실행을 기다리고 있는 프로세스가 많은데 한 프로세스가 락 획득을 기다리면서 CPU 리소스를 낭비하게 되면 생산성 및 효율이 매우 떨어짐.
바쁜 대기를 수행 중인 뮤텍스 락을 스핀락 (spinlock)이라고 함.
but 스핀락은 상황에 따라 장점으로 작용할 수 있음. -> 여러 개의 CPU 코어가 존재할 때 사용하지 않는 코어에서 스핀락을 통해 대기하고 있다가 락을 얻은 뒤 곧바로 임계 영역으로 진입할 수 있음. 바쁜 대기 수행 중에는 문맥교환이 일어나지 않기 때문에 문맥 교환에 소모되는 시간을 줄일 수 있다는 장점 존재.
뮤텍스 락은 C언어의 pthread.h 라이브러리에 포함되어있음.
사용 예제
#include <stdio.h>
#include <pthread.h>
int sum = 0;
pthread_mutex_t mutex; // 뮤텍스 선언
void* counter(void* param)
{
for (int k = 0; k < 10000; k++)
{
/* entry section */
pthread_mutex_lock(&mutex);
/* critical section */
sum++;
/* exit section */
pthread_mutex_unlock(&mutex);
/* remainder section */
}
pthread_exit(0);
}
int main()
{
pthread_t tid1, tid2;
pthread_mutex_init(&mutex, NULL); // 뮤텍스 초기화
pthread_create(&tid1, NULL, counter, NULL);
pthread_create(&tid2, NULL, counter, NULL);
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
printf("sum = %d\n", sum);
}6.6. 세마포어 (semaphore)
여러 프로세스 (n개의 프로세스)에서의 임계 영역 문제를 해결하기 위한 방법. 세마포어 (semaphore)의 영단어 뜻이 '신호기'이므로 신호기의 신호에 따라 진입 여부가 결정된다고 생각하면 편함.
엄밀히 정의하면 세마포어 (semaphore) S는 정수 변수이며, wait()와 signal() (혹은 P(), V())이라는 2가지 연산을 가짐.
왜 P(), V()라고 부르지? -> 네덜란드의 컴퓨터 과학자인 Edsger Dijkstra에 의해 소개되었으며, P(), V()는 각각 네덜란드어로 Proberen (테스트), Verhogen (증가)의 첫 글자임.
wait(S)
{
while (S <= 0)
; // busy wait
S--;
}
signal(S)
{
S++;
}열쇠가 여러 개 들어있는 열쇠 꾸러미를 생각하자. (열쇠 꾸러미에 열쇠가 있는 경우, 즉 개수가 0보다 큰 경우에는 열쇠를 꺼내서 진입할 수 있고, 열쇠가 없는 경우에는 다른 사람이 열쇠를 반납할 때까지 기다려야 함. 기다리는 것이 wait(), 열쇠를 반납하는 것이 signal())
이들 역시 원자적으로 구현되어야 함.
만약 세마포어의 범위가 0 또는 1, 즉 이진 세마포어 (binary semaphore)라면 뮤텍스 락과 동일하게 동작함. (1이면 진입하고 0이면 기다림)
그렇지 않고 S가 1보다 큰 범위 내에서 무한히 확장 가능하다면 유한한 자원을 관리하기에 좋음. 이를 계수 세마포어 (counting semaphore)라고 함. (n개의 인스턴스가 있다는 것을 전제로 함)
계수 세마포어를 사용하기 위해서는 S = n, 즉 사용 가능한 자원의 개수로 세마포어를 초기화하면 됨.
자원을 사용할 때에는 wait() (P()) 메소드를 호출함. 이때 S 카운트의 값이 1 감소함.
자원을 사용한 뒤 반납할 때에는 signal() (V()) 메소드를 호출하고, 이때 S 카운트의 값은 1 증가함.
만약 S 카운트가 0이 되면 사용 가능한 자원이 없는 것이므로 다른 프로세스는 임계 영역에 접근할 수 없음. 자원을 사용하고 있는 프로세스가 자원을 반납하면 그때서야 사용할 수 있음.
세마포어를 사용하여 동기화 문제 해결하기
세마포어를 활용하면 대부분의 동기화 문제를 해결할 수 있음.
ex) P1, P2라는 2개의 프로세스와 S1, S2라는 2개의 구문이 있다고 가정 (P1은 S1을, P2는 S2를 돌림). 이때 반드시 S1이 수행된 다음에 S2가 수행되도록 만들고 싶다면?
세마포어를 synch라는 이름으로 선언하고 0으로 초기화함. (2개의 프로세스를 다루기 때문)
S1;
signal(synch);wait(synch);
S2;S1 구문을 먼저 수행한 다음에 signal() 메소드를 통해 synch의 값을 1 증가시킴.
이후 S2 구문 수행 전에 wait() 메소드를 통해 우선 대기함.
다른 프로세스에서 signal()을 수행하지 않는 한 synch의 값은 계속 0이므로 임계 영역에 접근할 수 없음. P1 프로세스에서 작업을 마친 뒤 반납을 해 주어야만 P2 프로세스가 임계 영역으로 들어가 S2 구문을 수행할 수 있음. 따라서 S1 구문이 끝나야만 S2 구문이 실행될 수 있기 때문에 순서가 보장됨. (동기화 문제 해결)
위에서 소개한 세마포어는 여전히 무한루프를 통해 대기하는 구조를 갖고 있으므로 바쁜 대기 문제가 발생할 수 있음. 이를 해결하기 위해서는 CPU 스케쥴러를 사용할 필요가 있음.
wait()메소드가 호출되면 무한루프로 대기하는 것이 아닌, 프로세스를 대기 큐 (wait queue)로 보내 대기하게끔 함.- 이후 다른 프로세스에서
signal()메소드를 호출하면 대기 큐에 있던 프로세스를 깨우고 (wakeup) 준비 큐 (ready queue)로 보내 CPU 자원을 획득하기를 기다리도록 함.
이 과정에서 무한루프를 돌지 않기 때문에 바쁜 대기 문제가 발생하지 않음.
typedef struct
{
int value;
struct process* list; // linked list
} semaphore;
wait(semaphore* S)
{
S->value--;
if (S->value < 0)
{
// 프로세스를 S->list에 추가함.
sleep(); // 대기 큐로 이동함.
}
}
signal(semaphore* S)
{
S->value++;
if (S->value <= 0)
{
// 프로세스 P를 S->list에서 제거함.
wakeup(P); // 준비 큐로 이동함.
}
}사용 예제
이진 세마포어
#include <stdio.h>
#include <pthread.h>
#include <semaphore.h>
int sum = 0;
sem_t sem;
void* counter(void* param)
{
for (int k = 0; k < 10000; k++)
{
/* entry section */
sem_wait(&sem);
/* critical section */
sum++;
/* exit section */
sem_post(&sem); // 자바는 notify()를 씀. 이름은 다르지만 개념은 동일함.
/* remainder section */
}
pthread_exit(0);
}
int main()
{
pthread_t tid1, tid2;
sem_init(&sem, 0, 1);
pthread_create(&tid1, NULL, counter, NULL);
pthread_create(&tid2, NULL, counter, NULL);
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
printf("sum = %d\n", sum);
}세마포어는 초기화가 중요함.
int sem_init(sem_t* sem, int pshared, unsigned int value);
sem_t* sem: 세마포어를 수행할 세마포어 타입 변수int pshared: 서로 공유할 프로세스 스레드의 개수. 0인 경우 프로세스 하나의 스레드 간 공유를 의미함. (unix 계열에서는 보통 0을 사용함)unsigned int value: 초기화할 세마포어의 초기값.S = n처럼 초기화할 수 있음. 1인 경우 이진 세마포어 (== 뮤텍스 락)
계수 세마포어
int main()
{
pthread_t tid[5];
sem_init(&sem, 0, 5);
for (int i = 0; i < 5; i++)
pthread_create(&tid[i], NULL, counter, NULL);
for (int i = 0; i < 5; i++)
pthread_join(tid[i], NULL);
printf("sum = %d\n", sum);
}위 예제를 실행해보면 항상 50000이 나와야 하는데 그렇지 않음. -> 왜 그럴까?
계수 세마포어의 전제조건은 "n개의 인스턴스"였음. 그런데 이 예제에서는 sum이라는 1개의 인스턴스 (데이터)에 5개의 스레드가 접근하는 것이므로 아무리 세마포어를 통해 동기화를 한다고 해도 경쟁 상황, 임계 영역 문제가 발생할 수밖에 없음 (상호 배제가 적용되지 않음).
만약 공유 변수를 5개 선언하여 각각 할당했다면 제대로 된 결과가 나올 것.
sem_init의 value를 1로 바꿔서 이진 세마포어로 바꾼다면 다시 제대로 된 결과가 나옴. 그 이유는 1개의 세마포어를 한 프로세스 (스레드)가 차지하여 작업을 수행하는 동안 다른 프로세스 (스레드)는 접근하지 못하기 때문임. (동시에 접근할 수가 없음)
6.7. 모니터
뮤텍스와 세마포어가 편리하고 효율적인 동기화 도구이긴 하지만, 타이밍 에러 (timing error)와 같은 문제가 자주 발생하기 때문에 사용하는 데 어려움이 있음.
특정 실행 시퀀스가 발생한 경우 타이밍 에러는 항상 발생하지도 않고 발견도 쉽지 않기 때문에 굉장히 까다로운 문제임.
간단한 예를 들자면, 이진 세마포어를 사용하여 1로 초기화한 경우, wait()을 수행한 뒤 signal()을 수행해야 하는 일련의 순서를 지켜야 함. (wait() -> signal()) 이를 지키지 않으면 두 프로세스가 동시에 임계 영역에 접근하게 되어 경쟁 상태와 같은 문제가 발생함.
- 상황 1)
wait()과signal()의 순서가 뒤집힌 경우:signal()->wait()순으로 동기화를 수행하면signal()을 하는 순간 여러 프로세스가 동시에 임계 영역에 들어가게 됨. - 상황 2)
wait()을 수행한 다음 또wait()을 수행한 경우 (적절한 위치에서wait()나signal()을 수행하지 않은 경우): 동일한 문제가 발생함.
이러한 상황은 주로 동기화의 개념을 잘 모르는 채로 구현하거나, 사소한 실수로 인해 발생하는 경우가 많음.
이렇듯 세마포어나 뮤텍스를 잘못 사용함으로써 발생하는 다양한 에러들은 동기화 도구를 조금 더 사용하기 쉽게 만드는 것으로 해결할 수 있음.
즉, 보다 고수준의 (high-level) 동기화 도구를 사용하여 이러한 에러를 신경쓰지 않을 수 있도록 하는 것이 중요함. 이 때문에 모니터 (monitor)라는 동기화 도구를 사용함.
모니터 타입 (monitor type): 상호 배제와 같은 기능을 제공하는 추상 자료형 (ADT. abstract data type). 즉 클래스를 말함. 따라서 모니터 타입으로 선언된 변수의 인스턴스를 호출할 수 있음.

monitor 내부의 P1, P2, ... 메소드들은 자동으로 동기화가 되어있음. 동기화를 위해서는 초기화 코드를 통해 초기화 작업을 수행해야 함.
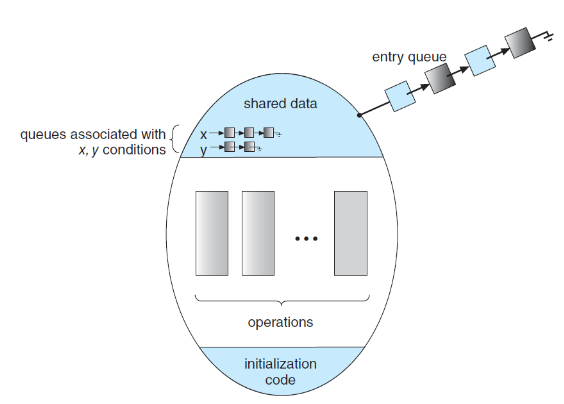
but, 모니터 타입 그 자체만으로는 동기화를 제공하기 어렵기 때문에 condition이라는 변수를 추가하여 동기화 매커니즘을 따로 제공해 주어야 함.
condition x, y;
x.wait();
x.signal();각 condition 변수에 wait(), signal() 메소드를 사용하여 모니터의 메소드들이 각 변수에 따라 각각 초기화되고 동기화될 수 있음.
자바에서의 모니터
자바에서는 주로 스레드 동기화를 위해 모니터 기능을 제공하며, 모니터 락 (monitor-lock), 또는 고유 락 (intrinsic-lock)이라고 함. 이를 이해하기 위해 synchronized 키워드와 wait(), notify() 메소드를 이해할 필요가 있음.
synchronized키워드
임계 영역에 해당하는 코드 블록을 하나로 묶을 때 사용함.
synchronized로 지정한 코드 블록, 혹은 메소드는 임계 영역이 되어 모니터 락을 획득해야만 접근하고 진입할 수 있음.
또한 객체의 인스턴스에도 임계 영역을 지정할 수 있는데, 이때this객체의 인스턴스가 모니터 락을 가지고 있음.synchronized (object) { // critical section }
object에서 모니터 락을 획득해야만 임계 영역에 진입할 수 있음.public synchronized void add() { // critical section }메소드 자체를 임계 영역으로 지정한 경우
wait()과notify()메소드
동기화를 조금 더 자유자재로 사용하기 위한 메소드 (wait()&signal()메소드와 동일함)
java.lang.Object클래스에 선언되어있음. -> 자바의 모든 객체는 이 클래스를 상속받으므로 사실상 모든 객체가wait()¬ify()메소드를 가지고 있음.
notify()는 모니터에서 대기 중인 스레드 하나를,notifyAll()은 대기 중인 스레드를 전부 깨워 준비 큐에 넣음.
자바 동기화 사용 예제
1) 동기화를 사용하지 않음
public class SynchExample1
{
static class Counter
{
public static int count = 0;
public static void increment()
{
count++;
}
}
static class MyRunnable implements Runnable
{
@Override
public void run()
{
for (int i = 0; i < 10000; i++)
Counter.increment();
}
}
public static void main(String[] args) throws Exception
{
Thread[] threads = new Thread[5];
for (int i = 0; i < threads.length; i++)
{
threads[i] = new Thread(new MyRunnable());
threads[i].start();
}
for (int i = 0; i < threads.length; i++)
threads[i].join();
System.out.println("counter = " + Counter.count);
}
}멤버 변수 count와 메소드 increment()를 갖는 Counter 클래스를 만듦. MyRunnable 인터페이스는 run() 메소드를 통해 Counter 클래스의 increment() 메소드를 10000번 수행함.
메인 함수에서는 MyRunnable 클래스의 인스턴스를 갖는 스레드를 5개 생성하여 돌림. (각 스레드는 MyRunnable.run() 메소드를 수행할 것) -> 5개의 스레드는 count 변수를 공유함.
실행해보면 12696, 13400, ... 등 예상값인 50000 근처에도 가지 못하는 것을 볼 수 있음. -> 심각한 동기화 문제 발생
2) synchronized 키워드를 통한 동기화
public class SynchExample2
{
static class Counter
{
public static int count = 0;
synchronized public static void increment()
{
count++;
}
}
static class MyRunnable implements Runnable
{
@Override
public void run()
{
for (int i = 0; i < 10000; i++)
Counter.increment();
}
}
public static void main(String[] args) throws Exception
{
Thread[] threads = new Thread[5];
for (int i = 0; i < threads.length; i++)
{
threads[i] = new Thread(new MyRunnable());
threads[i].start();
}
for (int i = 0; i < threads.length; i++)
threads[i].join();
System.out.println("counter = " + Counter.count);
}
}increment() 메소드를 synchronized로 선언하여 임계 영역으로 지정하였음. 임계 영역에 진입할 때 모니터 락을 획득(acquire())하고, 빠져나올 때 반납(release())함.
이 예제에서처럼 메소드가 count++과 같이 임계 영역의 코드만 수행하면 상관이 없지만, 메소드가 나머지 영역 (remainder section)까지 포함하는 경우 메소드 전체를 synchronized로 묶는 것은 동기화 및 멀티스레딩의 장점을 활용할 수 없는 것임.
3) 특정 코드 블록만 synchronized로 묶는 경우
public class SynchExample3
{
static class Counter
{
private static Object object = new Object();
public static int count = 0;
public static void increment()
{
synchronized (object)
{
count++;
}
}
}
static class MyRunnable implements Runnable
{
@Override
public void run()
{
for (int i = 0; i < 10000; i++)
Counter.increment();
}
}
public static void main(String[] args) throws Exception
{
Thread[] threads = new Thread[5];
for (int i = 0; i < threads.length; i++)
{
threads[i] = new Thread(new MyRunnable());
threads[i].start();
}
for (int i = 0; i < threads.length; i++)
threads[i].join();
System.out.println("counter = " + Counter.count);
}
}increment() 메소드 내부에서 synchronized 키워드를 사용하였음. 멤버 변수 object를 모니터 락으로 활용함. (this를 사용하여 자기 자신을 모니터 락으로 활용할 수도 있음)
4) 메소드를 클래스의 멤버 함수로 선언한 경우 (static을 사용하지 않음)
public class SynchExample4
{
static class Counter
{
public static int count = 0;
public void increment()
{
synchronized (this)
{
count++;
}
}
}
static class MyRunnable implements Runnable
{
Counter counter;
public MyRunnable(Counter counter)
{
this.counter = counter;
}
@Override
public void run()
{
for (int i = 0; i < 10000; i++)
Counter.increment();
}
}
public static void main(String[] args) throws Exception
{
Thread[] threads = new Thread[5];
for (int i = 0; i < threads.length; i++)
{
threads[i] = new Thread(new MyRunnable(new Counter()));
threads[i].start();
}
for (int i = 0; i < threads.length; i++)
threads[i].join();
System.out.println("counter = " + Counter.count);
}
}increment()를 정적 메소드로 선언하지 않았기 때문에 다른 클래스에서 직접 접근하는 것이 불가능하고, 클래스의 인스턴스를 따로 생성해서 참조해야 함. (counter.increment())
5개의 스레드는 각각의 인스턴스 counter를 가짐. (다만 static으로 선언되었기 때문에 값은 공유함. 인스턴스 변수가 5개로 각각 생성된 것)
각 스레드의 서로 다른 인스턴스에서 공유 변수인 count를 증가시킴.
but 이렇게 인스턴스를 따로 생성하게 되면 synchronized (this) 부분에서 각 인스턴스마다 this가 가리키는 객체가 다르기 때문에 결국 생성된 인스턴스 별로 모니터를 갖는 것과 동일함. -> 동기화 문제 발생 (서로 다른 인스턴스, 스레드 간 동기화가 되지 않음)
5) 인스턴스를 각각 생성하지 않고 한 번 생성한 인스턴스를 생성자로 넘겨주는 경우
public class SynchExample4
{
static class Counter
{
public static int count = 0;
public void increment()
{
synchronized (this)
{
count++;
}
}
}
static class MyRunnable implements Runnable
{
Counter counter;
public MyRunnable(Counter counter)
{
this.counter = counter;
}
@Override
public void run()
{
for (int i = 0; i < 10000; i++)
Counter.increment();
}
}
public static void main(String[] args) throws Exception
{
Thread[] threads = new Thread[5];
Counter counter = new Counter(); // 미리 Counter 클래스의 인스턴스를 생성함.
for (int i = 0; i < threads.length; i++)
{
threads[i] = new Thread(new MyRunnable(counter); // 미리 생성한 counter 인스턴스를 생성자에 넘김.
threads[i].start();
}
for (int i = 0; i < threads.length; i++)
threads[i].join();
System.out.println("counter = " + Counter.count);
}
}이렇게 하면 서로 다른 스레드 사이에서도 동기화가 제대로 이루어짐. (하나의 인스턴스를 여러 스레드가 공유함. 모니터 락은 1개)
6.8. 라이브니스 (liveness)
지금까지 나왔던 뮤텍스 락, 세마포어, 모니터는 상호 배제는 확실하게 보장해 주지만 진행 (데드락 방지), 한정 대기 (기아 방지)는 제공하지 않음. (오히려 세마포어는 데드락 문제를 야기함)
따라서 진행과 한정 대기까지 제공하는 기술이 라이브니스 (liveness).
데드락 (deadlock. 교착상태)
다른 프로세스에서 반납, 즉 signal()을 해주어야만 작업을 계속할 수 있는 상황에서 각 프로세스가 서로의 작업이 끝나기만을 기다리는 상황. (무한정 대기)
두 프로세스 이상이 임계 영역에 들어가기 위해 대기 큐에서 기다리는 상황. 다른 프로세스에서 종료를 해 주어야 세마포어를 받고 임계 영역에 들어갈 수 있는데, 정작 그 프로세스도 다른 프로세스가 끝나기를 기다리는 상황이라 종료를 할 수 없는 무한 대기 상황에 들어가는 것.

P0, P1의 두 프로세스가 있다고 가정.
<<< P0 >>>
wait(S);
wait(Q);
...
signal(S);
signal(Q);<<< P1 >>>
wait(Q);
wait(S);
...
signal(Q);
signal(S);이때 P0의 wait(S);가 먼저 일어나고 그 다음 P1의 wait(Q);가 수행된 상황이라면, P0 프로세스는 Q 세마포어를 얻기 위해 P1이 signal(Q)를 해 주기를 기다리고 있고, P1 프로세스는 S 세마포어를 얻기 위해 P0가 signal(S)를 해 주기를 기다리고 있음. 그런데 두 프로세스 모두 wait()을 수행 중이라 대기 큐에 있으므로 다음 작업을 수행할 수 없음. 결론? 두 프로세스 다 서로 눈치만 보면서 계속 기다리는 상황 발생.
데드락은 8장에서 더욱 자세히 다룰 예정.
우선순위 역전 (priority inversion)
프로세스 간 우선순위가 존재할 때, 높은 우선순위를 갖는 프로세스보다 낮은 우선순위를 갖는 프로세스가 먼저 실행되는 현상.
높은 우선순위를 갖는 프로세스 (A)가 커널 데이터에 접근하고자 할 때, 비교적 낮은 우선순위를 갖는 프로세스 (B)가 이미 그 데이터에 접근하여 사용중인 상황.
이때 스케쥴링 개념만 적용한다면 A가 B를 쫓아내고 선점 (preemption)할 수는 있음. but B가 공유 데이터를 사용하고 있기 때문에 A는 대기 큐에서 대기하고 있을 수밖에 없음. (중간에 A > C > B의 우선순위를 갖는 C 프로세스가 접근하는데 접근만 하고 공유 데이터를 사용하지 않는다면 A보다 먼저 B를 밀어내고 접근할 수 있음. 우선순위 개념이 매우 꼬이는 상황)
이를 해결하기 위해서는 우선순위 상속 (priority inheritance)을 사용해야 함. 낮은 우선순위를 갖는 프로세스가 CPU를 점유하는 동안에는 잠시동안 높은 우선순위를 갖는 프로세스를 상속하여 우선순위를 높임.
