설계 목표
- 자동완성 검색어 표시 갯수 : 10개
- 자동완성에 사용되는 접두어 부분은 사용자가 입력
- 질의 빈도에 따라 인기 검색어 10개 추천
- 맞춤법 검사나 자동 수정 지원은 X
- 질의는 영어 + 한국어 모두 가능
설계
요구 사항
- 빠른 응답 속도
- 사용자가 입력한 검색어에 대해 자동완성 부분은 최대한 빠르게 표시되어야 한다. - 연관성
- 자동 완성 검색어는 사용자가 입력한 검색어와 연관성이 있어야 한다. - 정렬
- 자동 완성 검색어는 인기 순에 따라 정렬되어야한다.
자료 구조
관계형 데이터베이스를 통해 인기 있는 검색어 5개를 가져오는 방법은 데이터가 많아지기 때문에 병목 현상이 발생할 수 있습니다.
따라서 트라이 자료구조를 통해 구현해 보고자 합니다.
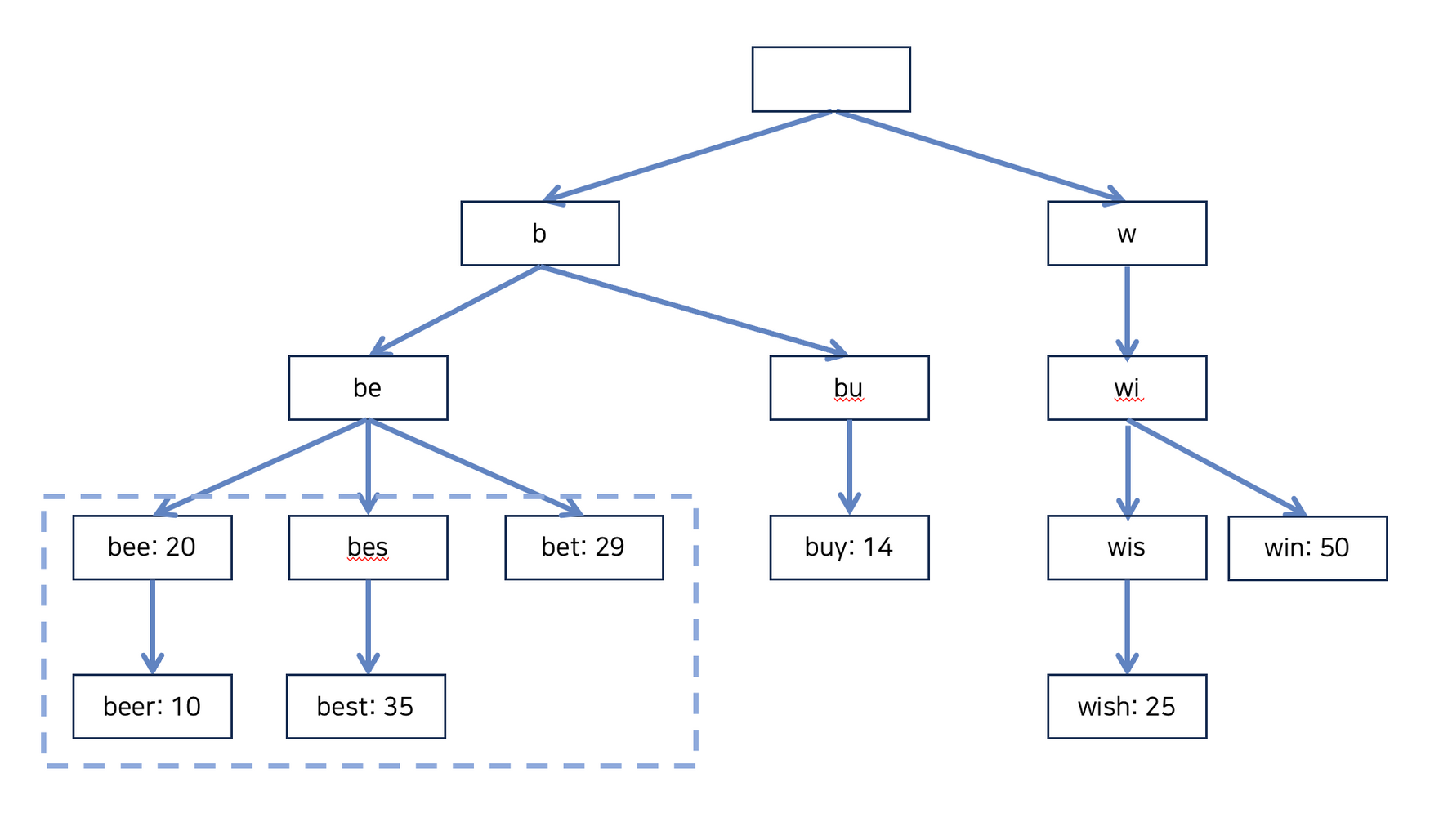
트라이 자료 구조 핵심
- 트리 형태 구조
- 루트 노드는 빈 문자열 저장
- 각 노드는 문자열을 저장하고 있으며, 하나의 단어 또는 접두어를 나타낸다.
노드 안에 다음과 같은 문자를 저장합니다.
class Node {
Map<Character, Node> childedNode = new HashMap<>();
// childedNode : 해당 Node의 하위 노드를 표현하기 위한 변수
String word;
// word : 노드의 문자열을 저장하는 변수
boolean isContainWord;
// isContainWord : 해당 노드가 문자열을 포함하고 있는지 나타내는 변수
int frequency;
// 빈도수
}여기서 isContainWord 를 자세하게 봐야하는데, 만약 위의 그림처럼 bear이 저장되어 있다고 하면 b > be > bee > beer 순으로 탐색을 하게 됩니다.
만약 단순히 노드의 끝을 기준으로 탐색한다면, beer 노드가 존재할 때 bee가 포함되어 있으면 bee는 탐색할 수 없으므로 isContainWord 변수를 통해 해당 단어가 포함되어 있는지 확인하는 코드가 필요합니다.
성능 향상을 위한 방식
노드에 인기 검색어 캐시
각 노드마다 인기 검색어를 캐시해 두는 방법입니다.
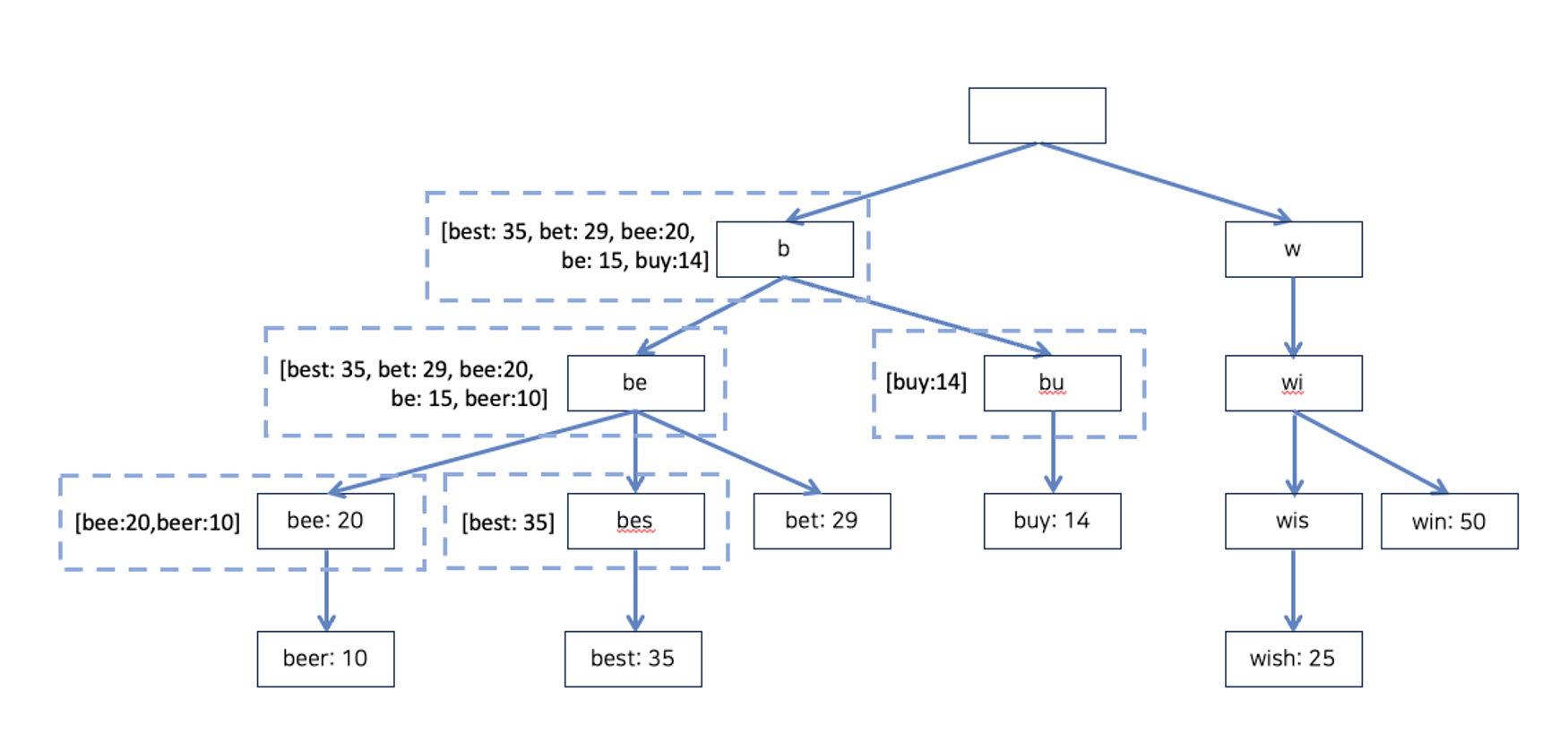
다음 그림처럼 각 노드마다 인기 검색어와 빈도수를 저장하고 있어 빠른 응답속도를 기대할 수 있지만 인기 검색어만큼 사용량이 증가하게 됩니다.
데이터 수집 서비스
데이터를 수집하는데 주의해야 할 점이 있습니다.
- 매일 수천만 건의 데이터가 입력될 경우, 각 데이터마다 트라이를 갱신한다면 질의 서비스의 속도는 현저히 느려질 수 있음.
이는 트위터 같은 실시간 어플리케이션이라면, 검색어를 항상 신선하게 유지해야하고, 만약 구글과 같은 어플리케이션이라면, 실시간으로 유지할 필요는 없습니다.

이를 반영하여 개선된 설계안은 다음과 같습니다.
-
먼저 검색창에 입력된 데이터와 시간을 수집합니다. 이때 데이터는 항상 추가만 됩니다. ( 수정, 삭제는 하지 않음 )
-
이후 1에서 모은 로그들을 취합을 합니다. 이때 빈도수와 일짜, 데이터를 구분하여 데이터를 취합합니다.
-
그 다음 취합한 로그 데이터를 기반으로 데이터베이스에 저장하고, 트라이를 갱신합니다.
이번 포스팅에서는 다음과 같은 모든 부분을 다루기에는 양이 방대해져 캐시와 데이터 수집 서비스를 뺀 나머지 부분을 구현하게 됩니다.
구현
@ToString
class Node {
Map<Character, Node> childedNode = new HashMap<>();
String word;
boolean isContainWord;
int frequency;
public Node(String word) {
this.word = word;
this.frequency = 0;
}
public Node(AutoComplete autoComplete) {
word = autoComplete.getWord();
frequency = autoComplete.getFrequency();
}
}
@Component
@RequiredArgsConstructor
public class Trie {
Node rootNode = new Node("Empty");
private final AutoCompleteRepository autoCompleteRepository;
@Transactional
public Node insert(String str) {
Node node = this.rootNode;
// 노드는 항상 헤드 노드를 가리켜야 합니다.
for(int i = 0; i < str.length(); i++) {
int finalI = i;
node = node.childedNode.computeIfAbsent(str.charAt(i), key -> new Node(str.substring(0 , finalI + 1)));
// 만약 해당되는 자식 노드가 존재하지 않으면 새로운 노드 생성, 아니면 해당 노드로 이동
}
Node currentNode = createOrLoadAutoComplete(node.word);
// 현재 선택된 노드를 DB에서 조회
node.isContainWord = true;
// 해당 노드의 글자가 포함됨을 적시
node.frequency = currentNode.frequency;
return node;
}
public void initTrie() {
// 트라이 초기 구현 ( DB에 있는 노드들을 기반으로 트리 생성 )
// 해당 부분은 위의 insert 부분과 비슷합니다.
List<AutoComplete> result = autoCompleteRepository.findAll();
// 모든 노드 데이터 조회
for(AutoComplete autoComplete : result) {
Node node = this.rootNode;
String str = autoComplete.getWord();
for(int i = 0; i < str.length(); i++) {
int finalI = i;
node = node.childedNode.computeIfAbsent(str.charAt(i), key -> new Node(str.substring(0 , finalI + 1)));
}
node.isContainWord = true;
node.frequency = autoComplete.getFrequency();
}
}
protected Node createOrLoadAutoComplete(String word) {
AutoComplete autoComplete = autoCompleteRepository.findAutoCompleteByWord(word)
.orElseGet(() -> autoCompleteRepository.save(AutoComplete.createAutoComplete(word)));
autoComplete.increaseFrequency(1);
return new Node(autoComplete);
}
public List<UtilInitDto> searchComplete(String searchWord) {
List<UtilInitDto> result = new ArrayList<>();
Node node = searchSearchWord(searchWord);
// 해당 검색어와 일치하는 노드 탐색
if(node == null) {
return result;
}
Queue<Node> queue = new LinkedList<>();
queue.offer(node);
while(!queue.isEmpty()) {
Node currentNode = queue.poll();
// 만약 해당 노드에 검색어가 포함되어 있다면 반환 클래스에 저장
if(currentNode.isContainWord) {
result.add(new UtilInitDto(currentNode.word, currentNode.frequency));
}
// 순회를 통해 자식 노드를 모두 queue 에 저장
for(char ch : currentNode.childedNode.keySet()) {
queue.offer(currentNode.childedNode.get(ch));
}
}
// 빈도수에 따라 정렬
Collections.sort(result, new Comparator<UtilInitDto>() {
@Override
public int compare(UtilInitDto o1, UtilInitDto o2) {
return o2.getFrequency() - o1.getFrequency();
}
});
// 최상위 10개 검색어를 두고 모두 삭제
if(result.size() > 10) {
result.subList(10, result.size()).clear();
}
return result;
}
private Node searchSearchWord(String str) {
Node node = this.rootNode;
for(int i = 0; i < str.length(); i++) {
node = node.childedNode.getOrDefault(str.charAt(i), null);
// 루트 노드부터 하위 노드까지 내려오면서 해당 문자열을 포함한 노드가 있는지 확인
// 만약 해당 문자열에 일치하는 노드가 없다면 null 반환
if(node == null) {
return null;
}
}
return node;
}
}참고
참고 블로그 1 : https://velog.io/@kimhalin/13%EC%9E%A5-%EA%B2%80%EC%83%89%EC%96%B4-%EC%9E%90%EB%8F%99%EC%99%84%EC%84%B1-%EC%8B%9C%EC%8A%A4%ED%85%9C#%EB%85%B8%EB%93%9C%EC%97%90-%EC%9D%B8%EA%B8%B0-%EA%B2%80%EC%83%89%EC%96%B4-%EC%BA%90%EC%8B%9C
참고 블로그 2 : https://velog.io/@hyoribogo/how-to-implement-autocomplete-feature#%EC%99%84%EC%84%B1-%EC%BD%94%EB%93%9C
참고 블로그 3 : https://codingnojam.tistory.com/40
