
클러스터형 인덱스
클러스터형 인덱스는 테이블당 하나만 존재하는 인덱스로 기본키 로 설정되거나 UNIQUE NOT NULL 로 설정된 키에 자동으로 할당됩니다. 클러스터형 인덱스는 인덱스로 설정된 행을 기준으로 정렬을 하며 B-Tree라는 자료구조를 이용해 데이터를 빠르게 탐색합니다.
클러스터형 인덱스의 특징으로는 B-Tree 에서 인덱스 자체의 리프 페이지가 곧 데이터입니다. 그러므로 인덱스 자체에 데이터가 포함되어 있습니다.
하지만 클러스터형 인덱스는 검색속도가 보조 인덱스 보다 빠르지만 데이터의 수정/삭제/삽입에는 페이지 분할이 일어나기 때문에 보조 인덱스보다 성능이 떨어집니다.
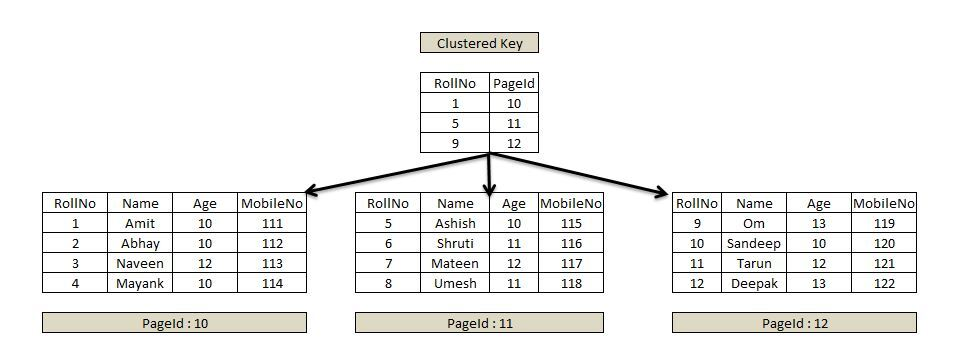
작동 방법을 보면 먼저 클러스터형 인덱스는 데이터 페이지를 모두 정렬합니다. 그리고 리프 페이지에는 데이터가 들어가 있으며, 루트 노드에서는 각각의 리프 데이터의 번호를 갖고 있습니다. 따라서 데이터를 찾고 싶을 때 루트 노드에서 값을 탐색 후 해당하는 리프 페이지로 이동합니다.
실제로 작동 방식은 다음과 같습니다.
1 . 사용자가 RollNo가 7 인 값을 찾는다.
2 . 루트 노드에서 순차적으로 탐색을 하여 7 을 넘어서는 9 의 바로 이전인 5번 인덱스의 주소를 따라 PageId : 11 로 이동한다.
3 . PageId : 11 에서 순차적으로 값을 탐색하여 결과값을 찾는다.
클러스터형 인덱스는 PRIMARY KEY 로만 생성할 수 있으며 , CREATE INDEX로는 생성할 수 없습니다.
페이지 분할
클러스터형 인덱스는 리프 데이터를 가지고 있으므로 ( 노드 자체가 데이터 ) 인덱스 자체에 데이터를 포함하고 있습니다. 검색 속도를 향상시키고자 정렬되어 있는 리프 데이터에 새로운 값이 들어오게 된다면 해당 데이터를 정렬하는 과정을 거치게 되는데 이때 페이지의 크기가 부족하다면 새로운 페이지가 할당되고, 중간 노드와 루트 노드도 해당 페이지도 재구성 됩니다. ( 하단 노드의 링크를 변경해야 함 )
리프 페이지는 리프 노드를 의미합니다.
보조 인덱스
보조 인덱스는 UNIQUE 로 설정한 컬럼에 할당됩니다. 보조 인덱스는 한 테이블에 여러개 존재할 수 있으며 인덱스가 생성되면 데이터 페이지를 둔 상태에서 ( 정렬을 하지 않습니다. ) 별도의 페이지 ( 노드 ) 에 인덱스를 구성합니다.
보조 인덱스는 리프 페이지에 데이터가 존재하는게 아니라 데이터가 위치하는 주소값 ( RID - Row ID 각 생의 고유 번호 ) 을 가지고 있습니다. 보조 인덱스는 여러개 생성할 수 있지만 너무 많이 사용하면 성능을 떨어뜨릴 수 있습니다.
그의 예로 선택도가 나쁜 데이터 는 인덱스를 사용할 때 데이터의 종류가 얼마 없는 데이터는 MySQL의 성능을 저하시킵니다.
보조 인덱스는 클러스터형 인덱스와 다르게 새로운 값이 들어오면 데이터 페이지의 맨 뒤에 추가하고 노드를 정렬하기에 탐색 속도는 클러스터형 인덱스에 비해 느리지만 삽입/삭제/수정은 클러스터형 인덱스보다 빠릅니다.
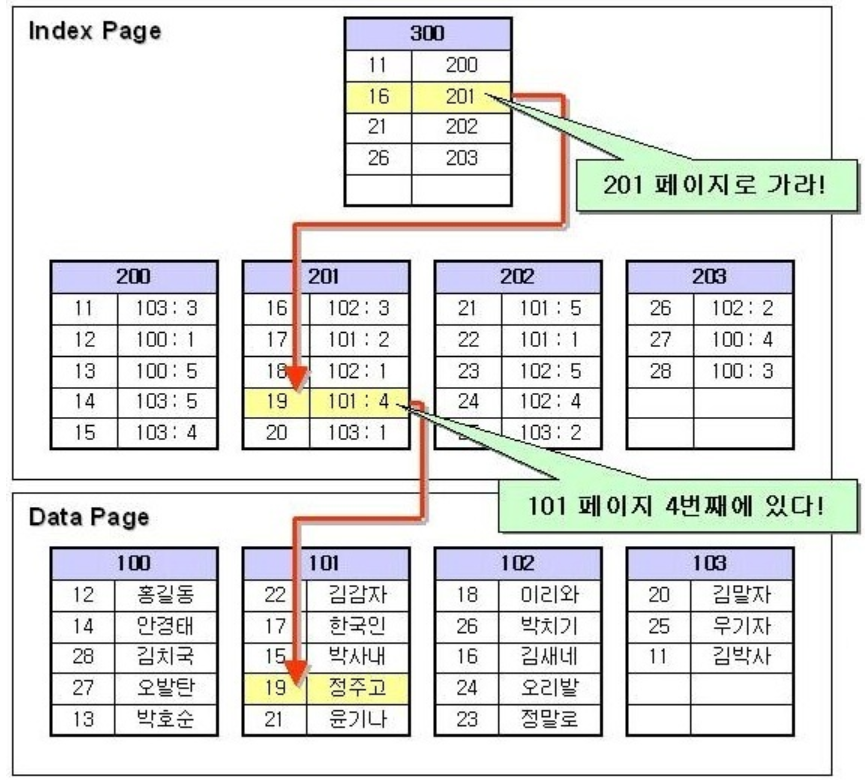
클러스터형 인덱스와 다르게 보조 인덱스는 데이터를 정렬하지 않습니다. 따라서 데이터의 값은 무작위로 섞여있고 루트 노드는 해당 페이지의 주소를 테이블 주소#오프셋 형식으로 가리키고 있습니다. 다만 데이터 페이지의 데이터만 정렬되어 있지 않지 루트 노드와 중간 노드 리프 노드의 값은 모두 정렬되어 있습니다.
보조 인덱스의 실질적인 작동 방식은 다음과 같습니다.
1 . 사용자가 19번의 값을 찾고자 한다.
2 . 루트 노드를 탐색 해 19를 넘어서는 21의 바로 이전 값 16이 가리키는 201 번지로 간다.
3 . 201 번지의 노드에서 19의 값을 탐색하고 찾았다면 해당 주소로 값을 조회한다.
RID 를 가지고 데이터 페이지에 데이터를 참조하는 것을 Key Lookup 이라고도 합니다.
보조 인덱스는 CREATE INDEX 를 통해 만들 수 있습니다.
생성된 인덱스를 적용시키려면 'ANALYZE TABLE 테이블' 을 사용해야 합니다.
클러스터형 인덱스와 보조 인덱스 혼용
보조 인덱스와 클러스터 인덱스를 사용하는데 이 두개를 혼합해서 사용할 때가 있습니다. 이때는 인덱스의 구조는 보조 인덱스는 데이터의 주소를 갖는 것이 아니라 클러스터 인덱스의 키 값을 갖고 있습니다. 따라서 우선 보조 인덱스를 통해 클러스터 인덱스를 탐색한 후에 클러스터 인덱스에서 데이터를 탐색합니다.
여기서 왜 보조 인덱스는 데이터 주소 값을 참조하지 않는가에 대한 질문이 생길 수 있는데, 클러스터 인덱스에서 새로운 값이 삽입되거나 수정될 때 페이지 분할로 인해 데이터의 주소가 대폭 변경될 수 있습니다. 이에 보조 인덱스가 주소값을 갖고 있었다면 한번의 데이터 수정으로 모든 테이블의 주소를 수정할 수 있으므로 데이터의 주소를 갖기 보단 , 클러스터 인덱스의 주소를 갖게 됩니다.
인덱스를 효율적으로 사용하기
인덱스는 절대 기준이 없기 대문에 인덱스를 잘 사용하기 위해서는 테이블의 데이터 구성 이나 어떤 열이 많이 조회되는지 에 따라 인덱스를 생성해야 합니다.
단순 조회
수많은 데이터 중에서 1개의 데이터를 조회할 때 클러스터와 보조 인덱스 모두 일반 검색 ( 전체 테이블 검색 ) 보다 속도가 훨씬 빠릅니다. 또한 클러스터와 인덱스의 차이가 크진 않습니다.
단 WHERE 문에서 인덱스를 사용하는 열에 함수나 연산을 가하면 인덱스를 사용하지 않을 수 있습니다.
전체 조회
전체 조회는 인덱스를 사용하든 제외하든 비슷한 결과가 나오거나 , 오히려 인덱스가 전체 조회보다 더 많은 데이터를 읽는 경우가 많습니다.
따라서 IGNORE INDEX( 컬럼 ) 을 이용해서 해당 쿼리에서 인덱스를 무시할 수 있습니다.
SELECT * FROM emp_c IGNORE INDEX(PRIMARY) WHERE ...
범위 조회 ( x 이상 y 이하인 값 )
범위 조회를 할 경우에 성능 차이는 클러스터형 >>> 보조 인덱스 > 전체 테이블 검색 차례로 성능이 나뉩니다. 실제로 1000개의 데이터를 조회할 때 계산된 값을 보면 클러스터형 인덱스는 5번 ( Index Range Scan ) , 보조 인덱스는 700 번 ( Index Range Scan ) , 전체 테이블은 전체 탐색 ( Full Table Scan ) 을 합니다.
이처럼 범위 조회에서는 클러스터형이 압도적으로 성능이 뛰어난 것을 볼 수 있습니다. 그 이유는 클러스터형은 데이터 테이블이 정렬되어 있으니 단순히 그 범위에 대한 값을 모두 가져오면 되기 때문입니다.
이에 보조 인덱스는 데이터 테이블이 정렬되어 있지 않기 때문에 리프 노드에서 주소값을 찾아 데이터를 찾는 과정을 반복하기 때문에 성능이 뛰어나지 않습니다. 만약 전체 데이터의 15%이상을 조회한다고 하면 전체 테이블과 성능이 별 차이가 없습니다.
여기서 MySQL 은 인덱스를 사용해도 성능의 효율이 좋지 못하다고 판단할 시 인덱스를 사용하지 않고 전체 테이블을 탐색 ( Full Table Scan ) 을 합니다. 만약 범위 탐색만 하는 테이블이라면 해당 인덱스는 사용되지 않아 성능상 문제를 일으킬 수 있습니다.
데이터의 중복도
인덱스를 사용하는 열은 Cardinality ( 원소 개수 ) 가 높아야 합니다. SHOW INDEX FROM 테이블명; 를 활용해서 Cardinality를 확인할 수 있는데 만약 데이터의 중복도가 높은 상태에서 ( 데이터의 종류가 많지 않은 열 예시로 성별인 남 , 여 ) 인덱스를 사용하면 사용하지 않은 것 보다 크게 차이가 나지 않습니다.
물론 인덱스를 사용하는 것이 더 낫겠지만 인덱스 관리 비용 ( 데이터 수정 ) 을 생각하면 그렇게 효율적이지 못할 것 입니다.
클러스터형 인덱스 제거
클러스터형 인덱스는 반드시 존재해야 하는 것이 아닙니다. 만약 PRIMARY KEY 를 생성한다면 반드시 클러스터형 인덱스로 설정되는데 만약 대용량의 데이터가 끊임 없이 입력된다면 시스템 성능에 문제를 일으킬 수 있습니다.
이를 방지하기 위해 PRIMARY KEY 를 제거하고 UNIQUE NULL 키워드를 설정하는 방법을 사용할 수 있습니다.
단 , UNIQUE NOT NULL 을 설정하면 자동으로 클러스터형 인덱스가 설정이 되기 때문에 NULL 로 설정을 해주어야 하며 , 이때 반드시 값이 들어가야 하는 상황이라면 해당 값이 필수로 입력되게 프로그래밍 하는 방법을 선택할 수 있습니다.
정리
- 인덱스는 열 단위로 생성된다.
- 인덱스는 WHERE 절의 조건문에서만 사용된다.
- 성능이 뛰어나더라도 WHERE 절에서 자주 사용되어야 한다.
( 이는 성능이 뛰어나더라도 INSERT가 더 자주 일어나면 성능을 떨어뜨립니다. ) - 데이터의 중복도가 높은 경우에는 별 효과가 없다.
- 외래 키를 지정한 열에는 자동으로 외래 키 인덱스가 설정한다.
( 외래 키 인덱스가 필요할 경우에 MySQL이 알아서 사용합니다. ) - 데이터의 수정이 얼마나 자주 일어나는 지 파악한다.
( 자주 변경되는 데이터에 인덱스가 있다면 성능저하를 일으킵니다. 인덱스는 읽기 성능만 향상시키며 , 데이터 변경에는 부담을 줍니다.) - 클러스터형 인덱스는 하나만 생성된다.
- 조인 ( join ) 을 자주 사용하는 열에 추가해주자.
- 범위 , 집계 함수 , 조건 ( WHERE ) 을 사용하는 경우에는 클러스터형 인덱스를 사용하자.
( ORDER BY 를 자주 사용하는 열에는 클러스터형 인덱스를 사용하자 ) - 클러스터 형은 없는게 나을 수 있다.
- 사용되지 않는 인덱스는 제거하라.
