
프로젝트를 위해 스케줄링 기능을 찾아보던 중 Quartz의 존재를 알게되었습니다. Quartz를 이해하고 사용하기 위해 Quartz 공식사이트 의 자료를 공부하였습니다. 이 포스팅에서는 공부했던 내용을 공유하고자 합니다.
Quartz란?
Quartz는 오픈소스로 Java 스케줄링 라이브러리입니다. Spring과 함께 사용될 수도 있으며, Spring과 별개로 사용될 수도 있습니다.
몇몇 정보글에서는 Quartz를 프레임워크고 소개하고 있지만, Quartz UserGuide 에 따르면 라이브러리로 소개하고 있습니다. (Quartz is a richly featured, open source job scheduling library)
Quartz의 기본 구성
Quartz 스케줄러를 시행하기 위해서는 적어도 아래와 같은 개념을 알아야합니다.
- Job : 스케줄링할 실제 작업을 가지는 객체이다.
- JobDetail : Job의 정보를 구성하는 객체이다.
- Trigger : Job이 언제 시행될지를 구성하는 객체이다.
- JobData : Job에서 사용할 데이터를 전달하는 역할을 하는 객체이다.
- Scheduler : JobDetail과 Trigger 정보를 이용해서 Job을 시스템에 등록하고, Trigger가 동작하면 지정된 Job을 실행시키는 역할을 하는 객체이다.
- SchedulerFactory : Scheduler 인스턴스를 생성하는 역할을 하는 객체이다.
- quartz.properties : Quartz 스케줄러를 위한 configuration 을 담당하는 파일이다. src/resources/ 에 위치하며 세부적인 사항은 Quartz Configuration Reference 문서를 참조하는 것을 추천한다.
- JobStore : 스케줄러에 등록된 Job의 정보와 실행이력이 저장되는 공간이다. 기본적으로 RAM에 저장되어 JVM 메모리공간에서 관리되지만, 원한다면 다른 RDB에서 관리할 수 있다.
이상의 구성만으로 대략적인 Quartz의 Flow를 추정해보자면 다음과 같을 것입니다.
(1) quartz.properties 의 구성 사항을 적용
(2) SchedulerFactory를 이용해 Scheduler를 만듦
(3) Scheduler에 JobDetail과 Trigger를 이용해 Job을 스케줄링
(4) 정해진 시간마다 Scheduler가 Job을 호출하여 시행
Quartz 기본 구성 구현
대략적인 구성을 알았으니 직접 코드로 구현해보겠습니다. Spring 없이 순수 Java 코드를 통해 구현한 예시입니다.
의존성 관리는 gradle을 이용하였습니다.
의존성
// gradle 의존성 추가
implementation group: 'org.quartz-scheduler', name: 'quartz', version: '2.3.2'
quartz.properties
quartz.properties 에서는 scheduler 인스턴스의 이름, Job을 실행한 스레드 풀의 스레드 수, 그리고 스케줄링된 JobStore을 지정하겠습니다.
// quartz.properties 구성하기
org.quartz.scheduler.instanceName = MyScheduler
org.quartz.threadPool.threadCount = 3
org.quartz.jobStore.class = org.quartz.simpl.RAMJobStore
Job 구현체
Job은 Job이라는 인터페이스의 구현체입니다. 오버라이드된 excute 메서드가 scheduler에 의해 Job이 호출될때 실행되는 부분입니다.
Job 구현체는 scheduler에 의해 호출될때마다 새로 생성됩니다. 그러한 점은 HelloJob생성자와 execute 메서드이 err print를 통해 손쉽게 확인할 수 있습니다.
// Job구성하기
public class HelloJob implements Job {
public HelloJob() {
System.err.println("HelloJob created");
}
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
System.err.println("Hello");
}
}- JobExecutionContext
execute 메서드의 파라미터로 넘어가는 인자이다. JobDetail 인스턴스가 Scheduler에 의해 실행될때 넘어오고, 실행이 완료된 뒤에는 Trigger로 넘어간다.
JobDetail 생성
JobDetail을 생성하기 위해서는 JobBuilder 클래스를 이용해야하는데, 순수하게 JobBuilder를 반환하는 생성자는 private로 선언되어 있기 때문에 다른 메서드들을 이용하기 위해서는 static import가 필요하다.
import static org.quartz.JobBuilder.*;
public class DetailMaker {
public JobDetail getJob() {
JobDetail job = newJob(HelloJob.class)
.withIdentity("HelloJob", "HelloGroup")
.withDescription("simple hello job")
.usingJobData("num", 0)
.build();
return job;
}
}-
newJob(Class <? extends Job> jobClass)
JobBuilder내부에 선언된 JobBuilder를 반환하는 메서드이다.
위와 같이 Job 구현체의 class 지정해서 넘겨주는 방식과 공란으로 넘겨주는 방식이 있다.
만약 공란으로 넘겨준다면 내부에서 ofType 메서드를 호출해 Job의 class를 넘겨줘야한다. -
withIdentiy(name, group)
Job의 이름과 gorup을 지정하는 메서드이다. group명은 중복될 수 없으며, name은 group안에서 유니크해야한다. -
usingJobData(key, value)
Job에 넘겨줄 JobData 를 설정하는 메서드이다. key는 오직 String만 가능하며, value는
String, Integer, Long, Float, Double, Boolean 형태가 가능하다. 객체 자체를 넘겨줄순 없다. -
build()
JobDetail을 반환하는 메서드이다. 이저까지 설정했던 identity, Job.class, JobData 정보들을 JobDetail 구현체에 설정한뒤 반환한다.
JobData가 왜 필요한거지?
(1) 단순히 Job 외부에서 Job 내부로 데이터를 전달해주기 위함입니다. Job 내부에서 객체를 구현해야하는 수고를 덜 수 있습니다.
(2) Job 객체는 스케줄러에 의해 호출될때마다 새로운 객체가 생성됩니다. 따라서 이전 Job과 현재의 Job이 데이터를 공유할 수 있는 방법이 따로 필요합니다. 이때는 @PersistJobDataAfterExecution 에노테이션으로 JobData가 유지됨을 명시합니다.
JobTrigger 생성
Trigger 를 생성하기 위해서는 TriggerBuilder 객체가 필요한데, 이 객체 역시 JobBuilder와 똑같은 구조를 하고 있기 때문에 static import가 필요합니다.
import static org.quartz.TriggerBuilder.*;
import static org.quartz.SimpleScheduleBuilder.*;
public class TriggerMaker {
Trigger trigger = newTrigger()
.withIdentity("HelloTrigger", "HelloGroup")
.startNow()
.withSchedule(simpleSchedule()
.withIntervalInSeconds(5)
.repeatForever())
.build();
}
-
newTrigger()
TriggerBuilder를 반환하는 메서드이다. 이하에서는 모두 TriggerBuilder에 속성값을 추가하는 메서드들이고, 마지막 .build 메서드를 통해 Trigger를 반환하게 된다. -
withSchedule()
Trigger가 어떤 스케줄을 따를지 정하는 메서드이다. simpleSchedule과 cronSchedule이 있다. startNow() 혹은 startAt() 메서드를 통해 언제부터 스케줄러가 돌아갈지 정할 수 있기 때문에 단순한 인터벌 스케줄러라면 simpleSchedule를, 특정 요일, 날짜에 따라 변화가 필요하다면 cronSchedule를 사용하는 것이 적합하다.
예제에서는 scheduler에 job이 등록된 순간부터 scheduler가 멈출때까지 5초 간격으로 시행하도록 설정하였다.
scheduler 의 사용
scheduler의 인스턴스화, Job 등록하고, 실행, 중지는 다음과 같이 코드를 구성합니다.
public class QuartzMain {
public static void main(String[] args) {
try {
SchedulerFactory schedulerFactory = new StdSchedulerFactory();
Scheduler scheduler = schedulerFactory.getScheduler();
scheduler.scheduleJob(new DetailMaker().getJob(), new TriggerMaker().getTrigger());
scheduler.start();
Thread.sleep(60000);
scheduler.shutdown();
} catch (SchedulerException | InterruptedException e) {
}
}
}
-
SchedulerFactory
위에서 설명한대로 Scheduler 를 생성하는 역할을 한다. 다만 그 자체로는 인터페이스이기 때문에 구현체가 필요한데, 그 구현체로 사용되는 것이 StdSchedulerFactory 이다. -
StdSchedulerFactory.getScheduler()
SchedulerFactory의 구현체로서 quartz.properties 에 접근하여 설정한 'MyScheduler' 라는 이름으로 Scheduler 인스턴스를 생성하여 반환한다. -
scheduler.scheduleJob(/JobDetail, JobTrigger/)
JobDetail과 JobTrigger를 파라미터로 주면 Job을 스케줄에 등록할 수 있다. -
scheduler.start() ~ scheduler.shutdown()
두 메서드를 이용해서 스케줄링을 시작하고 멈출수 있다.
이렇게 코드를 구성하고 QuartzMain을 실행하면 HelloJob이 콘솔에 문자를 출력하는게 보일겁니다.
Thread.sleep(60000) 에서 의도한대로 1분동안 프로그램이 실행되고 종료되는 것을 확인할 수 있습니다.
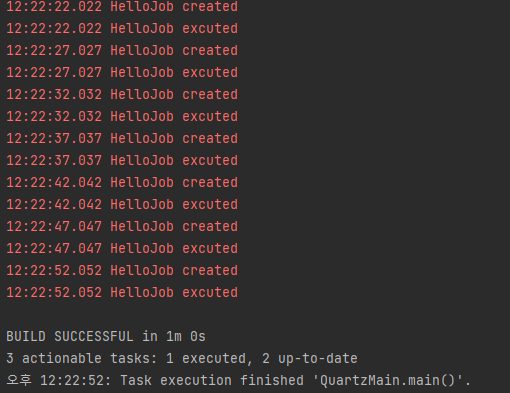
JobData 활용
위의 예제에서는 JobDetail에 JobData를 넣었지만 사용하고 있지는 않습니다. 이번에는 Job에서 JobData를 사용하는 방법을 보여드리겠습니다.
위의 예시에서 HelloJob 코드만 수정을 하겠습니다.
JobData 접근
execute 메서드에 파라미터로 넘겨주는 JobExecutionContext 객체에서 JobDataMap을 가져와서 입력한 key값으로 value를 참조할 수 있습니다.
public class HelloJob implements Job {
public HelloJob() {
}
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
JobDataMap dataMap = context.getJobDetail().getJobDataMap();
int num = dataMap.getInt("num");
System.err.println("Hello" + "[" + num + "]");
}
}이 상태로 출력하면 Hello[0]이 계속 출력되는것을 확인할 수 있습니다.
JobData 유지하기
여기에 @PersistJobDataAfterExecution 에노테이션을 활용해서 Job 이 시행될때마다 num의 숫자가 증가하도록 만들어 보겠습니다.
@PersistJobDataAfterExecution
public class HelloJob implements Job {
public HelloJob() {
}
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
JobDataMap dataMap = context.getJobDetail().getJobDataMap();
int num = dataMap.getInt("num");
System.err.println("Hello" + "[" + num + "]");
num++; // num을 증가시키고
dataMap.putAsString("num", num); // JobdataMpa 에 다시 입력
}
}Retry 로직 만들기
JobData의 특정한 값이 계속 유지되는 것을 이용해서 Job 실패시 수차례 재시도하는 로직을 만들 수 있습니다.
아래의 코드는 5번까지 재시도를 하되, 각 재시도마다 6000ms 의 텀을 두고 있습니다. 만약 5번째도 실패하면 Trigger를 멈춰서 Job이 더이상 돌아가지 않게 합니다.
@PersistJobDataAfterExecution
public class HelloJob implements Job {
public HelloJob() {
}
@SneakyThrows
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
JobDataMap dataMap = context.getJobDetail().getJobDataMap();
int num = dataMap.getInt("num");
if (num > 4) {
JobExecutionException e = new JobExecutionException("Retry Failed");
e.setUnscheduleAllTriggers(true);
throw e;
}
try {
System.err.println("Hello" + "[" + num + "]");
dataMap.putAsString("num", 0); // 성공하면 num을 0으로 초기화
} catch (Exception e) {
num++; // 실패하면 num을 1 증가시킴
dataMap.putAsString("num", num);
Thread.sleep(6000);
JobExecutionException e2 = new JobExecutionException(e);
e2.refireImmediately();
throw e2;
}
}
}
