⚡ 생각대로 살지 않으면 사는대로 생각한다.
⚡ 나는 어차피 잘 될 놈이다. 이미 잘 되고 있고, 계속해서 잘 되고 있다.
목차
- SQL 파싱과 최적화
- SQL 공유 및 재사용
- 데이터 저장 구조 및 I/O 메커니즘
해당 포스팅은 내가 1장을 적고, 요약 및 정리한 것이다.
SQL(Structured Query Language)
- 특징
- 구조적(structured)
- 집합적(set-based)
- 선언적(declarative)
- 결과집합을 구조적, 집합적으로 선언하지만, 절차((Procedure)적.
Optimizer(옵티마이저)
- SQL의 절차(Procedure)를 만들어주는 DBMS 내부 엔진
SQL 최적화
: SQL 파싱 + SQL 최적화
- 프로시저 작성 : 절차 작성
- 컴파일 : 실행 가능한 상태로 만듬.
- SQL 파싱
SQL 파서(Parser)가 파싱을 진행- 파싱 트리 생성 : SQL문의 구성요소를 분석해서 생성
- Syntax 체크 : 문법적 오류 확인
- Semantic 체크 : 문법이 맞아도, 논리적으로 의미상 오류가 없는지 확인.
- SQL 최적화
SQL 옵티마이저가 해당 역할을 함.- 실행 경로를 생성/비교 후 가장 효율적인 것 선택
- DB 성능을 결정하는 가장 핵심적인 엔진
- 로우 소스 생성
SQL 옵티마이저가 선택한 실행경로를 실행 가능한 코드 또는 프로시저 형태로 포맷팅하는 단계- 로우 소스 생성기(Row-Source Generator)가 해당 역할 함.
SQL 옵티마이저
-
사용자가 원하는 작업을 가장 효율적으로 수행할 수 있는 최적의 데이터 액세스 경로를 선택해주는 DBMS의 핵심 엔진
-
옵티마이저의 최적화 단계
- 사용자가 날린 쿼리를 수행하는 실행계획들을 찾아낸다.
- 데이터 사전(Data Dictionary)에 미리 수집해 둔 통계정보들을 이용하여
Decision Tree(의사 결정 트리)를 통해 각 실행계획의 예상비용을 산정.
- 데이터 사전(Data Dictionary)에 미리 수집해 둔 통계정보들을 이용하여
- 최저 비용 실행계획 선택.
❗단 실행계획에서 표시되는 비용들은 언제나 예상치다❗ 실수치가 아니다❗
옵티마이저 힌트
- 옵티마이저 힌트를 이용해서 데이터 액세스 경로를 바꿀 수 있다.
- 힌트 사용법 : 주석 기호에
+를 붙이면 된다.Select /*+ INDEX(A 고객_PK) */
주의 사항
- 힌트 안에 인자 나열시
,(콤마)를 사용할 수 있지만, 힌트와 힌트 사이에 사용 ❌ - 테이블 지정시 스키마명 명시 ❌
- FROM 절 테이블명 옆에 ALIAS를 지정했다면, 힌트에도 반드시 ALIAS 사용해야함!
- FROM 절에 ALIAS를 지정했는데, 힌트에는 테이블명을 사용하면, 해당 힌트는 무시된다.
소프트 파싱 vs 하드 파싱
라이브러리 캐시(Library Cache)
- SQL 파싱, 최적화, 로우 소스 생성과정을 거쳐 생성한 내부 프로시저를 반복 재사용할 수 있도록 캐싱해 두는 메모리 공간.
- 쉽게 보면, SQL 라이브러리다.
SGA(System Global Area)
- 서버 프로세스와 백그라운드 프로세스가 공통으로 액세스하는 데이터와 제어 구조를 캐싱하는 메모리 공간.
사용자가 SQL 명령을 하면,
사용자가 SQL문을 전달하면, DBMS는 SQL을 파싱한 후 해당 SQL이 라이브러리 캐시에 존재하는지 확인한다.
이 과정에서 캐시에서 찾아서 실행단계로 넘어가는 것을소프트 파싱
실패해서 최적화 및 로우 소스 생성 단계까지 모두 거치는 것을하드 파싱
이름없는 SQL 문제
사용자 정의 함수/프로시저, 트리거, 패키지 등은 생성할 때부터 이름을 갖는다.
컴파일한 상태로 딕셔너리에 저장되며, 사용자가 삭제하지 않는 한 영구적으로 보관된다.
실행할 때 라이브러리 캐시에 적재함으로써 여러 사용자가 공유하면서 재사용함.
!반면에 SQL은 이름이 따로 없다. 전체 SQL 텍스트가 이름 역할을 한다. 딕셔너리에 저장하지도 않는다.
처음 실행할 때 최적화 과정을 거쳐 동적으로 생성한 내부 프로시저를 라이브러리 캐시에 적재함으로써 여러 사용자가 공유하면서 재사용한다.
즉, 예를 들어 SELECT * FROM STUDENT 라는 쿼리를 날리면 SELECT * FROM STUDENT 이 자체가 라이브러리 캐시에 적재된다.
SELECT * FROM STUDENT WHERE NAME = SsangSu;
select * from STUDENT where NAME = SsangSu;
select * form student where name = SsangSu;
select * from student where name = SsangSu;
select * from student where name = SsangSu ;
select * from school.student where name = SsangSu;위의 select 문은 의미상 같은 내용이고, 결과도 똑같이 나온다.(그렇다고 치자...)
그런데 자바에서도 문자열이 "ab".euqals("AB")의 결과가 false이듯, 해당 명령문들은 다 다르게 인식하여 라이브러리 캐시에는 다 다르게 저장되어있다. 그래서 매번 하드 파싱이 일어나 성능적으로 문제가 생긴다.
그리고, SELECT * FROM STUDENT WHERE NAME = SsangSu; 해당 명령어에 NAME값에 늘 다른 값을 주는 방식으로 하더라도,
라이브러리 캐시에는 아래와 같이 저장된다.
SELECT * FROM STUDENT WHERE NAME = SsangSu;
SELECT * FROM STUDENT WHERE NAME = oraking;
SELECT * FROM STUDENT WHERE NAME = javaking;
SELECT * FROM STUDENT WHERE NAME = tommy;
SELECT * FROM STUDENT WHERE NAME = karajan;
SELECT * FROM STUDENT WHERE NAME = Darren꼰;매번 다른 SQL로 인식하여 하드파싱이 매번 일어나 성능에 문제가 생기는 것이다.
하지만 바인드변수(?)를 사용하여 파라미터 Driven 방식으로 SQL을 작성하여 아래와 같이 SQL문을 작성하면,
SELECT * FROM STUDENT WHERE NAME = ? ;한 번의 하드 파싱이 일어나고 그 이후엔 소프트 파싱이 되어 캐시 라이브러리에만 거치게 되어 SQL을 재사용하게 되어 성능이 좋아진다.
그리고 라이브 러리 캐시에는 이름이 매번 달라지더라도
SELECT * FROM STUDENT WHERE NAME = :1`위와 같이 저장되어 있다. 즉, 하드파싱은 한 번 그 이후엔 계속해서 소프트파싱이 일어나게 되는 것이다.
SQL 튜닝은 곧 I/O 튜닝.
SQL튜닝이 I/O튜닝이고, I/O튜닝이 곧 SQL 튜닝이다. 정확히는 디스크 I/O...
데이터베이스 저장구조
- 테이블 스페이스
세그먼트를 담는 콘테이너
- 세그먼트
- 데이터 저장공간이 필요한 오브젝트(테이블, 인덱스, 파티션, LOB 등)
- 익스텐트
- 공간을 확장하는 단위
- 연속된 블록의 집합
- 블록
- DBMS가 데이터를 읽고 쓰는 단위
- 오라클은 기본적으로 8KB크기의 블록을 사용.
- 데이터파일
- 디스크 상의 물리적인 OS파일
세그먼트 공간이 부족하면 익스텐트를 추가로 할당받긴하지만, 세그먼트에 할당된 모든 익스텐트가 같은 데이터파일에 위치하지 않을 수 있다.
서로 다른 데이터파일에 위치할 가능성이 더 높다.
하나의 테이플스페이스를 여러 데이터파일로 구성하면, 파일 경합을 줄이기 위해 DBMS가 데이터를 가능한 한 여러 데이터파일로 분산해서 저장하기 때문이다.
- DBA(Data Block Address)
- 모든 데이터 블록은 디스크 상에서 몇 번 데이터파일의 몇 번째 블록인지를 나타내는 자신만의 고유 주소값을 가지는데, 이 주소값을
DBA라고 부른다. - 데이터를 읽고 쓰는 단위가 블록이므로 데이터를 읽으려면 먼저 DBA부터 확인해야 한다.
- 인덱스를 이용해 테이블 레코드를 읽을 때는 인덱스
ROWID를 이용한다.ROWID는 DBA + 로우 번호(블록 내 순번)로 구성되므로, 이를 분석하면 읽어야 할 테이블 레코드가 저장된 DBA를 알 수 있다.
- 모든 데이터 블록은 디스크 상에서 몇 번 데이터파일의 몇 번째 블록인지를 나타내는 자신만의 고유 주소값을 가지는데, 이 주소값을
테이블 또는 인덱스 블록을 액세스(=읽는)하는 방식
시퀀셜(Sequential) 액세스
- 논리적 또는 물리적으로 연결된 순서에 따라 차례대로 블록을 읽는 방식
랜덤(Random) 액세스
- 논리적, 물리적인 순서를 따르지 않고, 레코드 하나를 읽기 위해 한 블록씩 접근(=touch)하는 방식
DB 버퍼캐시
- 위에서 언급했던 라이브러리 캐시가
코드 캐시라고 한다면, DB 버퍼캐시는데이터 캐시라고 할 수 있다. - 디스크에서 수고롭게 읽은 데이터 블록을 캐싱해 둠으로써 같은 블록에 대한 반복적인 I/O 호출을 줄이는 데 목적이 있다.
- 데이터 블록을 읽을 땐 항상 버퍼캐시부터 탐핵한다.
- 버퍼 캐시에서 데이터를 찾지 못하면, 디스크로부터 데이터를 찾는다.
- 버퍼캐시는 공유메모리 영역이므로 같은 블록을 읽는 다른 프로세스도 득을 본다.
논리적 I/O vs 물리적 I/O
논리적 블록 I/O
- 블록 읽기 요청
- 메모리 I/O
- 전기적 신호
- SQL을 수행하면서 읽은 총 블록 I/O가 논리적 I/O
물리적 블록 I/O
- 버퍼 캐시 Miss
- 디스크 I/O
- 액세스 Arm
- DB 버퍼캐시에서 블록을 찾지 못해 디스크에서 읽은 블록 I/O
※참고 메모리 I/O(전기적 신호)에 비해 1,000배 이상 느림.
실제 SQL 성능을 향상하려면 물리적 I/O가 아닌 논리적 I/O를 줄여야함!
논리적 I/O는 통제가 가능하지만, 물리적 I/O는 통제가 불가능하다.
결국 통제 가능한 논리적 I/O를 줄여서 성능을 향상시킬 수 있다.
논리적 I/O를 줄이려면, 읽은 총 블록 개수를 줄인다.
Single Block I/O vs Multiblock I/O
Single Block I/O
- 한 번에 한 블록씩 요청하여 메모리에 적재하는 방식
- 인덱스를 이용할 때 기본적으로 사용하는 방식
- 인덱스는 주로 소량 데이터를 읽을 때 사용
Multiblock I/O
- 한 번에 여러 블록씩 요청해서 메모리에 적재하는 방식.
- 인덱스를 이용하지 않고, 테이블 전체를 스캔할 때 이 방식을 사용.
Table Full Scan vs Index Range Scan
Table Full Scan
- 테이블 전체를 스캔해서 읽는 방식
- 시퀀셜 액세스 + Multiblock I/O 방식으로 디스크 블록을 읽음.
Index Range Scan
- 인덱스를 이용한 테이블 액세스
- 랜덤 액세스 + Single Block I/O 방식으로 디스크 블록을 읽음.
ROWID
- 테이블 레코드가 디스크 상에 어디 저장됐는지를 가리키는 위치 정보.
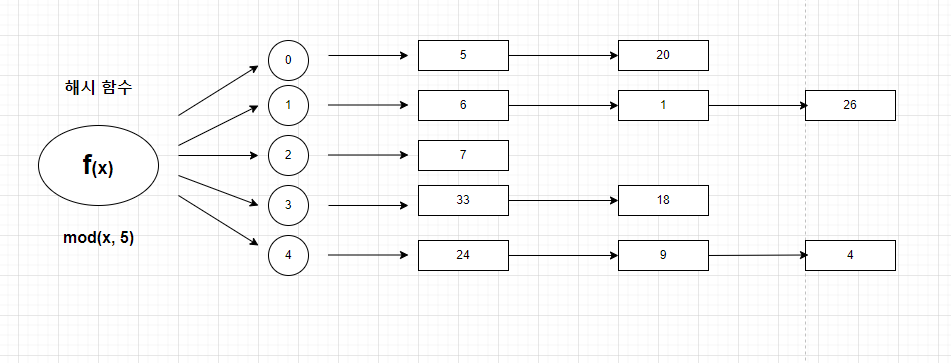
캐시 탐색 메커니즘
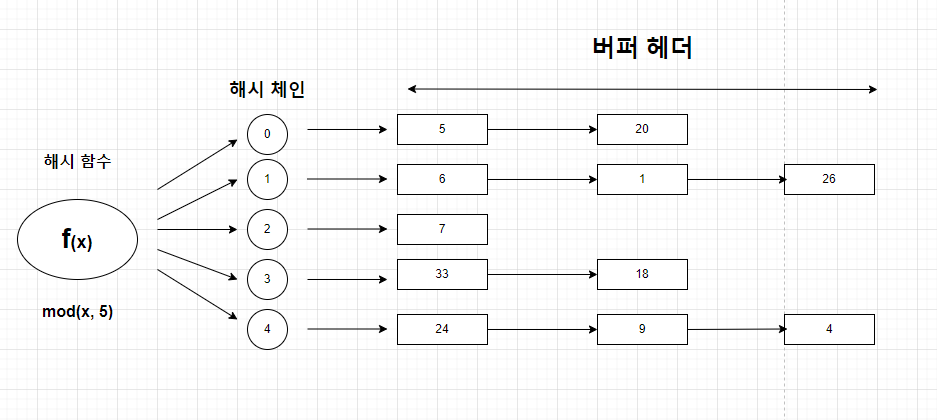
Direct Path I/O를 제외한 모든 블록 I/O는 메모리 버퍼캐시를 경유한다.
버퍼캐시
- SGA 구성요소로써 버퍼캐시에 캐싱된 버퍼블록은 모두 공유자원.
캐시버퍼 체인 래치
위의 그림을 예시로 보면,
- DBA(Data Block Address)를 해시 함수에 입력하고 거기서 반환된 값으로 스캔해야 할 해시 체인을 찾는다.
해시 체인을 스캔하는 동안 다른 프로세스가 체인 구조를 변경하는 일이 생기면 곤란하기 때문에,해시 체인 래치가 존재하는데,해시 체인에서 버퍼를 찾는동안 체인 구조를 변경하지 못 하도록해시 체인에 Lock을 건다.- 이
해시 체인에 Lock을 거는 것을캐시버퍼 채인 래치라고 한다.
버퍼 Lock
읽고자 하는 블록을 찾았으면, 캐시버퍼 체인 래치(해시 체인에 Lock)를 곧바로 해체해야, 다른 프로세스들이 해시 체인을 통해 작업을 재개할 수 있는데,
이를 바로 해체하면, 후행 프로세스가 같은 블록에 접근해서 데이터가 조작될 수 있으므로, 데이터 정합성에 문제가 생김.
이를 방지 하기 위해 오라클에서 버퍼 Lock을 사용하고,
캐시버퍼 체인 래치를 해제하기 전에 버퍼 Lock을 설정하여 데이터 정합성 문제를 방지한다.
작업 순서
캐시 버퍼 체인 래치 => 블록 찾음 => 버퍼 Lock => 캐시 버퍼 체인 래치 해체 => 후행 프로세스 해시 체인 접근.
-끝-
