⚡ 생각대로 살지 않으면 사는대로 생각한다.
⚡ 나는 어차피 잘 될 놈이다. 이미 잘 되고 있고, 계속해서 잘 되고 있다.
영속성 컨텍스트의 이점
엔티티 조회, 1차 캐시
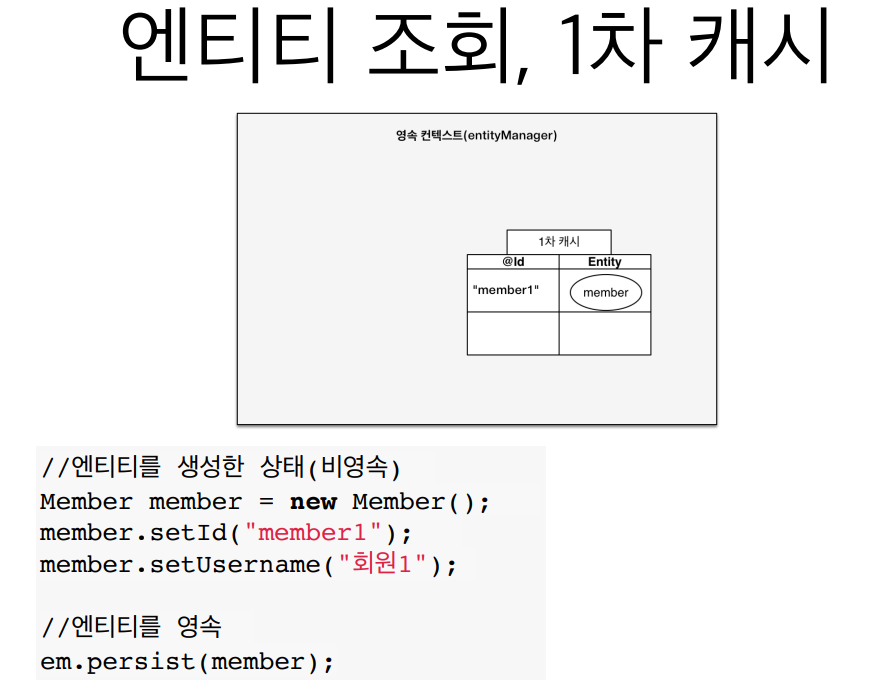
영속성 컨텍스트는 내부에 1차 캐시가 있다.
1차 캐시가 Map 형태로 있는데, PK로 둔 Id가 key가 되고, 그에 따른 Entity가 value가 된다.
1차 캐시에서 조회
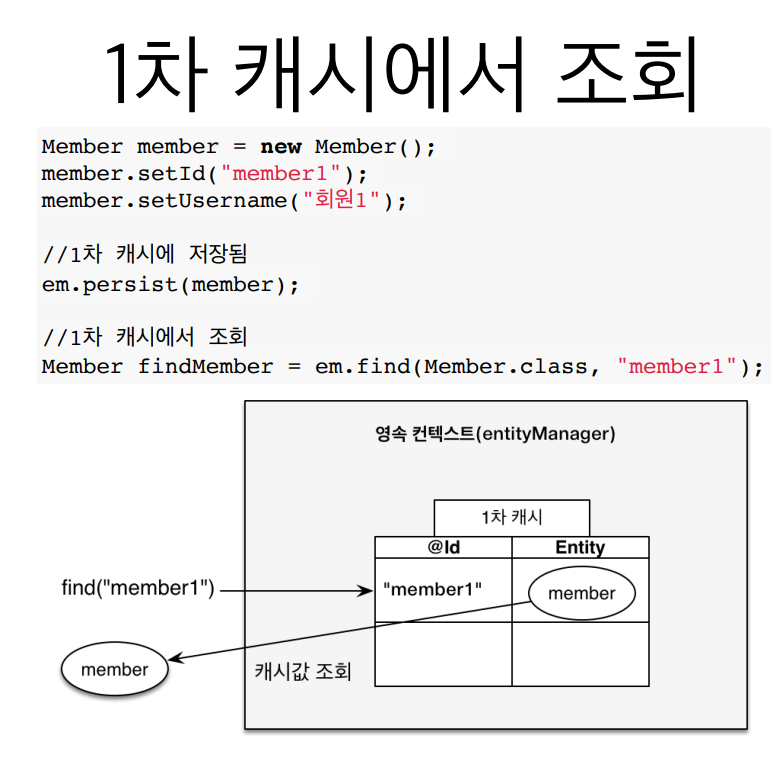
만약 persist()로 저장하고 find()로 조회하면, JPA는 먼저 1차캐시에서 조회를 한다.
- 이때 1차 캐시에 있다면, 바로 값을 반환하지만,
- 1차 캐시에 없다면, DB에 조회를 하고, 그리고 DB에서 조회에서 얻은 것을 1차 캐시에 저장한다.
- 그리고 값을 반환한다.
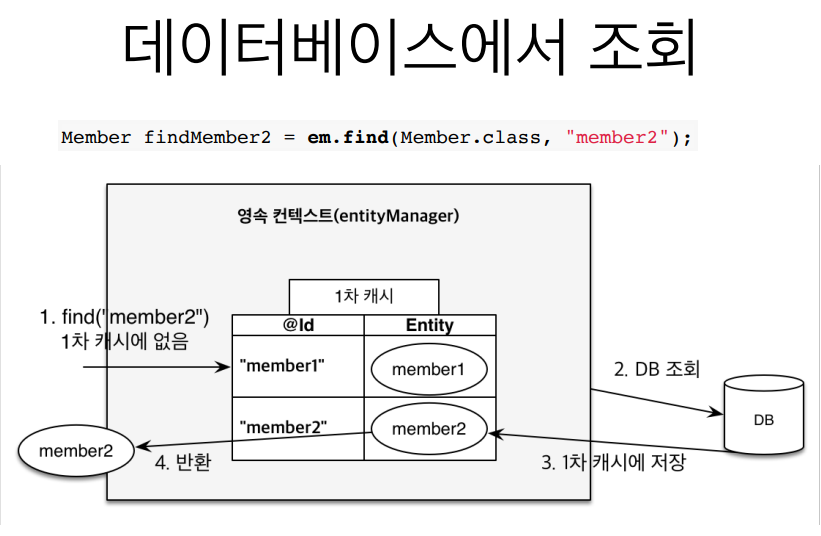
- 그리고 1차 캐시에 저장된 것을 다시 조회할 때, 1차 캐시에서 값을 반환한다.
이러한 이점들이 있지만, 큰 도움은 되지않는다. 왜냐하면,
엔티티 매니저는 데이터베이스 트랜잭션 단위로 만들어지고, 데이터베이스 트랜잭션이 끝날 때, 같이 종료하게 된다.
즉, 요청이 들어와서 비지니스가 끝나버리면, 영속성 컨텍스트가 종료된다.
찰나의 순간에만 이득이 있으므로, 성능 이점의 도움에 크게 영향을 주지는 못 한다.
아래와 같은 코드가 작성되있을 때,
try {
Member member = new Member();
member.setId(101L);
member.setName("HelloJPA");
// 영속
em.persist(member);
Member findMember = em.find(Member.class, 101L);
System.out.println("findMember.getId() = " + findMember.getId());
System.out.println("findMember.getName() = " + findMember.getName());
tx.commit();
} catch (Exception e) 여기서
Member findMember = em.find(Member.class, 101L);코드에서 SELECT쿼리를 날려서 Member를 조회하는 줄 알았지만, 실행 결과를 보면 그렇지 않다. 바로 위 em.persist(member)코드에 의해서 변경한 객체를 1차 캐시에 넣어두고, find를 하면, DB가 아니라, 1차 캐시에서 조회하여 값을 얻어온다.
그럼..
아래와 같은 코드가 있을 때, JPA는 쿼리를 몇번날릴까?
Member findMember1 = em.find(Member.class, 101L);
Member findMember2 = em.find(Member.class, 101L);정답은 한번이다.
처음한번 조회할 때, 1차 캐시에 값이 없으므로, DB에 쿼리를 날려서 값을 조회하고, 조회하여 반환된 값이 1차 캐시에 저장된다. 그리고 두번째 조회시 쿼리를 날려서 조회하는 것이 아니라, 처음 조회한 것이 1차 캐시에 저장되었고, 처음 조회한 것과 동일한 객체이므로, 1차캐시에서 값을 가져온다.
영속 엔티티의 동일성 보장

Member findMember1 = em.find(Member.class, 101L);
Member findMember2 = em.find(Member.class, 101L);
System.out.println("\"result = \"+ (findMember1==findMember2));위의 findMember1과 findMember2가 동일하다
같은 트랜잭션 안에서 조회한 객체가 동일하다.
엔티티 등록

em.persist()메서드는 영속 컨텍스트에 넣고, DB에 insert하는 것은 트랜잭션을 commit하는 순간에 넣게된다.
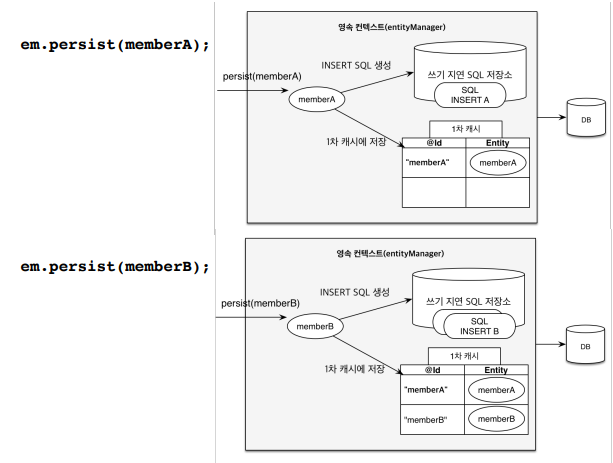
em.persist(memberA)메서드를 하게 되면, 1차캐시에 memberA를 넣고, INSERT SQL을 생성하고 쓰기 지연 SQL 저장소에 넣게 된다. memberB도 마찬가지다.
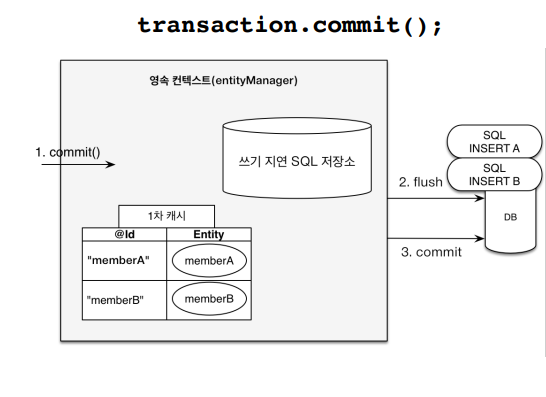
그리고, 트랜잭션을 commit을 하는 시점에, 쓰기 지연 SQL 저장소에 있는 SQL문들이 영속성 컨텍스트에서 flush되면서 DB에 쿼리를 날린다.
💡JPA는
Reflect API를 내부적으로 사용하기 떄문에, 동적으로 객체를 생성해줘야 한다. 따라서 @Entity 클래스에 기본생성자가 반드시 필요하다.
💡버퍼링 기능이있다.
<property name="hibernate.jdbc.batch_size" value="10"/>
persistance.xml에 이런 옵션을 설정하면,쓰기 지연 SQL에 value에 지정된 개수(여기선 10)가 모이면 DB에 쿼리를 한번에 날릴 수 있다.많이쓰이진 않지만, 잘 활용하면, 오히려 성능을 향상시킬 수 있다.
엔티티 수정(변경 감지)

위와 같이 Member를 entityManager.find()로 찾아서 setter를 통해 이름을 바꿔주면, 바꿔줬으니, em.persist(member)메서드로 영속성 컨텍스트에서 넣어서, 변경 및 수정 쿼리를 날려줘야 할 것 같지만,
오히려 쓰면 안 된다.
JPA의 목적은 자바 컬렉션 다루듯이 객체를 다루는 것이다.
컬렉션을 사용할 때,
컬렉션을 통해서 객체를 찾아서, 객체 값을 변경하고 다시 컬렉션에 넣지는 않는다.
JPA도 마찬가지다. 객체 찾아서 데이터를 변경하고 다시 영속성 컨텍스트에 넣지 않아도 된다.
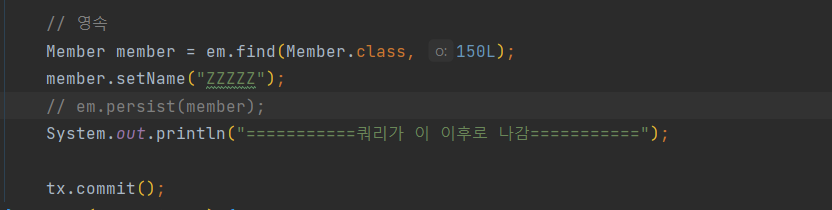
위와 같은 코드를 작성하고, 실행하게 되면, 아래와 같이 나오는데,
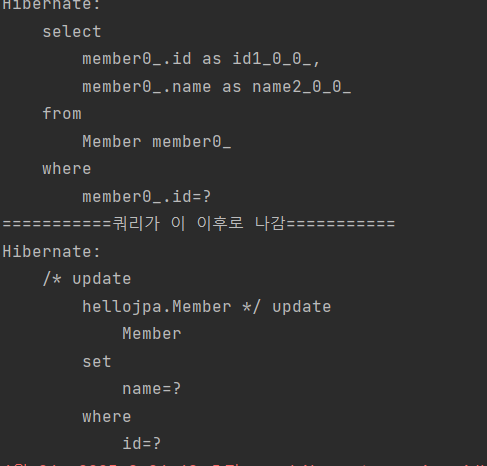
find를 할 때, SELECT 쿼리를 날리고, 값을 변경하고, persist로 영속성 컨텍스트에 넣지 않았음에도 불구하고, update쿼리를 날린다.
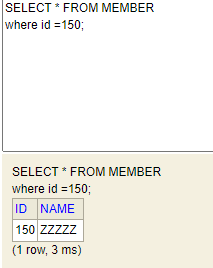
H2에서 확인한 결과.
이렇게 되는 이유
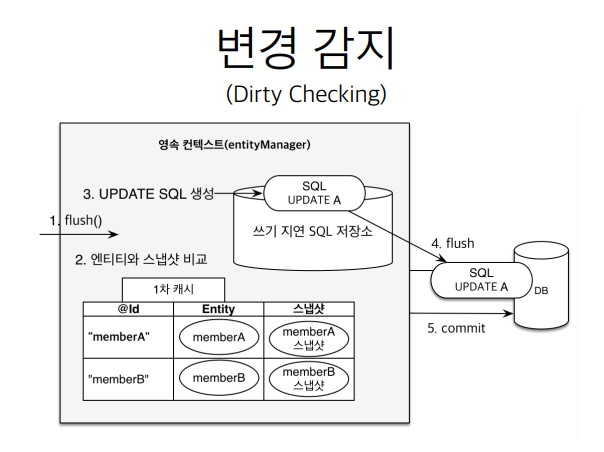
JPA는 commit하는 시점에 flush()를 하게되고, 엔티티와 스냅샷을 비교한다. 스냅샷도 1차캐시에 속해있다.
1차 캐시에
PK(@Id),Entity,스냅샷이 속해있다.
DB에서 불러온 최초시점의 상태를 스냅샷에 넣어두고, 그런 상태에서 코드를 통해서 값을 변경하면, 1차 캐시의 Entity와 스냅샷을 일일이 비교하면서 변경 사항을 감지하면, update 쿼리를 쓰기 지연 SQL 저장소에 넣고, commit시점에 SQL 쿼리를 날린다.
엔티티 삭제

엔티티를 찾아서, remove하면 트랜잭션 commit 시점에 delete쿼리를 날린다.
flush가 잘 이해되진 않지만, 바로 다음 내용이 flush다..
-끝-
